
機器學習中常見的幾種優化方法
我們每個人都會在我們的生活或者工作中遇到各種各樣的最優化問題,比如每個企業和個人都要考慮的一個問題“在一定成本下,如何使利潤最大化”等。最優化方法是一種數學方法,它是研究在給定約束之下如何尋求某些因素(的量),以使某一(或某些)指標達到最優的一些學科的總稱。隨著學習的深入,博主越來越發現最優化方法的重要性,學習和工作中遇到的大多問題都可以建模成一種最優化模型進行求解,比如我們現在學習的機器學習演算法,大部分的機器學習演算法的本質都是建立優化模型,通過最優化方法對目標函式(或損失函式)進行優化,從而訓練出最好的模型。常見的最優化方法有梯度下降法、牛頓法和擬牛頓法、共軛梯度法等等。
回到頂部
1. 梯度下降法(Gradient Descent)
梯度下降法是最早最簡單,也是最為常用的最優化方法。梯度下降法實現簡單,當目標函式是凸函式時,梯度下降法的解是全域性解。一般情況下,其解不保證是全域性最優解,梯度下降法的速度也未必是最快的。梯度下降法的優化思想是用當前位置負梯度方向作為搜尋方向,因為該方向為當前位置的最快下降方向,所以也被稱為是”最速下降法“。最速下降法越接近目標值,步長越小,前進越慢。梯度下降法的搜尋迭代示意圖如下圖所示:

牛頓法的缺點:
(1)靠近極小值時收斂速度減慢,如下圖所示;
(2)直線搜尋時可能會產生一些問題;
(3)可能會“之字形”地下降。

從上圖可以看出,梯度下降法在接近最優解的區域收斂速度明顯變慢,利用梯度下降法求解需要很多次的迭代。
在機器學習中,基於基本的梯度下降法發展了兩種梯度下降方法,分別為隨機梯度下降法和批量梯度下降法。
比如對一個線性迴歸(Linear Logistics)模型,假設下面的h(x)是要擬合的函式,J(theta)為損失函式,theta是引數,要迭代求解的值,theta求解出來了那最終要擬合的函式h(theta)就出來了。其中m是訓練集的樣本個數,n是特徵的個數。
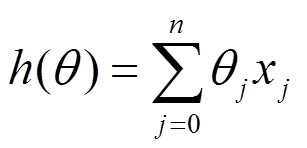
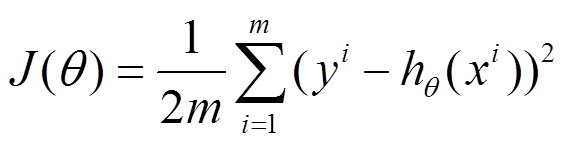
1)批量梯度下降法(Batch Gradient Descent,BGD)
(1)將J(theta)對theta求偏導,得到每個theta對應的的梯度:
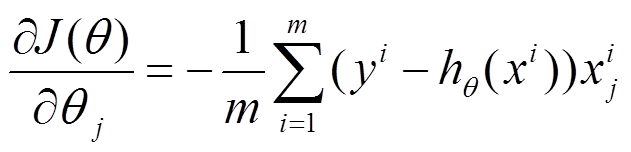
(2)由於是要最小化風險函式,所以按每個引數theta的梯度負方向,來更新每個theta:
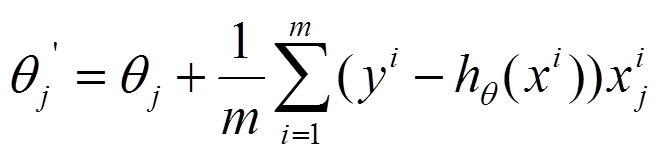
(3)從上面公式可以注意到,它得到的是一個全域性最優解,但是每迭代一步,都要用到訓練集所有的資料,如果m很大,那麼可想而知這種方法的迭代速度會相當的慢。所以,這就引入了另外一種方法——隨機梯度下降。
對於批量梯度下降法,樣本個數m,x為n維向量,一次迭代需要把m個樣本全部帶入計算,迭代一次計算量為m*n2。
2)隨機梯度下降(Random Gradient Descent,RGD)
(1)上面的風險函式可以寫成如下這種形式,損失函式對應的是訓練集中每個樣本的粒度,而上面批量梯度下降對應的是所有的訓練樣本:
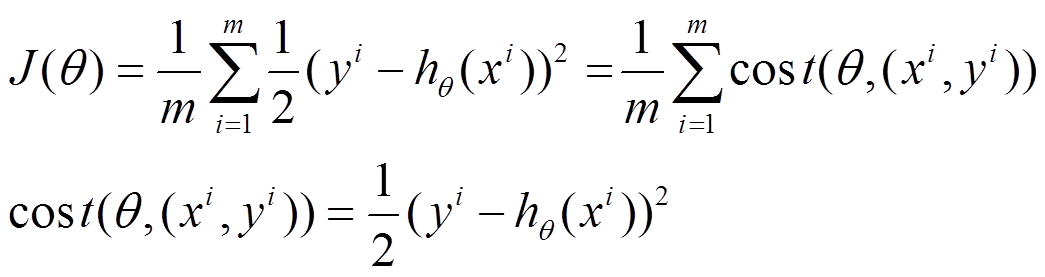
(2)每個樣本的損失函式,對theta求偏導得到對應梯度,來更新theta:
(3)隨機梯度下降是通過每個樣本來迭代更新一次,如果樣本量很大的情況(例如幾十萬),那麼可能只用其中幾萬條或者幾千條的樣本,就已經將theta迭代到最優解了,對比上面的批量梯度下降,迭代一次需要用到十幾萬訓練樣本,一次迭代不可能最優,如果迭代10次的話就需要遍歷訓練樣本10次。但是,SGD伴隨的一個問題是噪音較BGD要多,使得SGD並不是每次迭代都向著整體最優化方向。
隨機梯度下降每次迭代只使用一個樣本,迭代一次計算量為n2,當樣本個數m很大的時候,隨機梯度下降迭代一次的速度要遠高於批量梯度下降方法。兩者的關係可以這樣理解:隨機梯度下降方法以損失很小的一部分精確度和增加一定數量的迭代次數為代價,換取了總體的優化效率的提升。增加的迭代次數遠遠小於樣本的數量。
對批量梯度下降法和隨機梯度下降法的總結:
批量梯度下降---最小化所有訓練樣本的損失函式,使得最終求解的是全域性的最優解,即求解的引數是使得風險函式最小,但是對於大規模樣本問題效率低下。
隨機梯度下降---最小化每條樣本的損失函式,雖然不是每次迭代得到的損失函式都向著全域性最優方向, 但是大的整體的方向是向全域性最優解的,最終的結果往往是在全域性最優解附近,適用於大規模訓練樣本情況。
回到頂部2. 牛頓法和擬牛頓法(Newton's method & Quasi-Newton Methods)
1)牛頓法(Newton's method)
牛頓法是一種在實數域和複數域上近似求解方程的方法。方法使用函式f (x)的泰勒級數的前面幾項來尋找方程f (x) = 0的根。牛頓法最大的特點就在於它的收斂速度很快。
具體步驟:
首先,選擇一個接近函式 f (x)零點的 x0,計算相應的 f (x0) 和切線斜率f ' (x0)(這裡f ' 表示函式 f 的導數)。然後我們計算穿過點(x0, f (x0)) 並且斜率為f '(x0)的直線和 x 軸的交點的x座標,也就是求如下方程的解:

我們將新求得的點的 x 座標命名為x1,通常x1會比x0更接近方程f (x) = 0的解。因此我們現在可以利用x1開始下一輪迭代。迭代公式可化簡為如下所示:
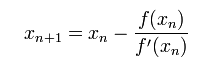
已經證明,如果f ' 是連續的,並且待求的零點x是孤立的,那麼在零點x周圍存在一個區域,只要初始值x0位於這個鄰近區域內,那麼牛頓法必定收斂。 並且,如果f ' (x)不為0, 那麼牛頓法將具有平方收斂的效能. 粗略的說,這意味著每迭代一次,牛頓法結果的有效數字將增加一倍。下圖為一個牛頓法執行過程的例子。

由於牛頓法是基於當前位置的切線來確定下一次的位置,所以牛頓法又被很形象地稱為是"切線法"。牛頓法的搜尋路徑(二維情況)如下圖所示:
牛頓法搜尋動態示例圖:

關於牛頓法和梯度下降法的效率對比:
從本質上去看,牛頓法是二階收斂,梯度下降是一階收斂,所以牛頓法就更快。如果更通俗地說的話,比如你想找一條最短的路徑走到一個盆地的最底部,梯度下降法每次只從你當前所處位置選一個坡度最大的方向走一步,牛頓法在選擇方向時,不僅會考慮坡度是否夠大,還會考慮你走了一步之後,坡度是否會變得更大。所以,可以說牛頓法比梯度下降法看得更遠一點,能更快地走到最底部。(牛頓法目光更加長遠,所以少走彎路;相對而言,梯度下降法只考慮了局部的最優,沒有全域性思想。)
根據wiki上的解釋,從幾何上說,牛頓法就是用一個二次曲面去擬合你當前所處位置的局部曲面,而梯度下降法是用一個平面去擬合當前的局部曲面,通常情況下,二次曲面的擬合會比平面更好,所以牛頓法選擇的下降路徑會更符合真實的最優下降路徑。

注:紅色的牛頓法的迭代路徑,綠色的是梯度下降法的迭代路徑。
牛頓法的優缺點總結:
優點:二階收斂,收斂速度快;
缺點:牛頓法是一種迭代演算法,每一步都需要求解目標函式的Hessian矩陣的逆矩陣,計算比較複雜。
2)擬牛頓法(Quasi-Newton Methods)
擬牛頓法是求解非線性優化問題最有效的方法之一,於20世紀50年代由美國Argonne國家實驗室的物理學家W.C.Davidon所提出來。Davidon設計的這種演算法在當時看來是非線性優化領域最具創造性的發明之一。不久R. Fletcher和M. J. D. Powell證實了這種新的演算法遠比其他方法快速和可靠,使得非線性優化這門學科在一夜之間突飛猛進。
擬牛頓法的本質思想是改善牛頓法每次需要求解複雜的Hessian矩陣的逆矩陣的缺陷,它使用正定矩陣來近似Hessian矩陣的逆,從而簡化了運算的複雜度。擬牛頓法和最速下降法一樣只要求每一步迭代時知道目標函式的梯度。通過測量梯度的變化,構造一個目標函式的模型使之足以產生超線性收斂性。這類方法大大優於最速下降法,尤其對於困難的問題。另外,因為擬牛頓法不需要二階導數的資訊,所以有時比牛頓法更為有效。如今,優化軟體中包含了大量的擬牛頓演算法用來解決無約束,約束,和大規模的優化問題。
具體步驟:
擬牛頓法的基本思想如下。首先構造目標函式在當前迭代xk的二次模型:
 這裡Bk是一個對稱正定矩陣,於是我們取這個二次模型的最優解作為搜尋方向,並且得到新的迭代點:
這裡Bk是一個對稱正定矩陣,於是我們取這個二次模型的最優解作為搜尋方向,並且得到新的迭代點:
 其中我們要求步長ak
滿足Wolfe條件。這樣的迭代與牛頓法類似,區別就在於用近似的Hesse矩陣Bk
代替真實的Hesse矩陣。所以擬牛頓法最關鍵的地方就是每一步迭代中矩陣Bk
的更新。現在假設得到一個新的迭代xk+1,並得到一個新的二次模型:
其中我們要求步長ak
滿足Wolfe條件。這樣的迭代與牛頓法類似,區別就在於用近似的Hesse矩陣Bk
代替真實的Hesse矩陣。所以擬牛頓法最關鍵的地方就是每一步迭代中矩陣Bk
的更新。現在假設得到一個新的迭代xk+1,並得到一個新的二次模型:
 我們儘可能地利用上一步的資訊來選取Bk。具體地,我們要求
我們儘可能地利用上一步的資訊來選取Bk。具體地,我們要求
 從而得到
從而得到
 這個公式被稱為割線方程。常用的擬牛頓法有DFP演算法和BFGS演算法。
回到頂部
這個公式被稱為割線方程。常用的擬牛頓法有DFP演算法和BFGS演算法。
回到頂部
3. 共軛梯度法(Conjugate Gradient)
共軛梯度法是介於最速下降法與牛頓法之間的一個方法,它僅需利用一階導數資訊,但克服了最速下降法收斂慢的缺點,又避免了牛頓法需要儲存和計算Hesse矩陣並求逆的缺點,共軛梯度法不僅是解決大型線性方程組最有用的方法之一,也是解大型非線性最優化最有效的演算法之一。 在各種優化演算法中,共軛梯度法是非常重要的一種。其優點是所需儲存量小,具有步收斂性,穩定性高,而且不需要任何外來引數。 下圖為共軛梯度法和梯度下降法搜尋最優解的路徑對比示意圖: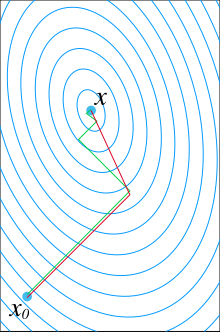 注:綠色為梯度下降法,紅色代表共軛梯度法
MATLAB程式碼:
注:綠色為梯度下降法,紅色代表共軛梯度法
MATLAB程式碼:

function [x] = conjgrad(A,b,x) r=b-A*x; p=r; rsold=r'*r; for i=1:length(b) Ap=A*p; alpha=rsold/(p'*Ap); x=x+alpha*p; r=r-alpha*Ap; rsnew=r'*r; if sqrt(rsnew)<1e-10 break; end p=r+(rsnew/rsold)*p; rsold=rsnew; end end
回到頂部
4. 啟發式優化方法
啟發式方法指人在解決問題時所採取的一種根據經驗規則進行發現的方法。其特點是在解決問題時,利用過去的經驗,選擇已經行之有效的方法,而不是系統地、以確定的步驟去尋求答案。啟發式優化方法種類繁多,包括經典的模擬退火方法、遺傳演算法、蟻群演算法以及粒子群演算法等等。
還有一種特殊的優化演算法被稱之多目標優化演算法,它主要針對同時優化多個目標(兩個及兩個以上)的優化問題,這方面比較經典的演算法有NSGAII演算法、MOEA/D演算法以及人工免疫演算法等。
這部分的內容會在之後的博文中進行詳細總結,敬請期待。這部分內容的介紹已經在部落格
回到頂部