
TFIDF演算法及應用
TFIDF的主要思想是:如果某個詞或短語在一篇文章中出現的頻率TF高,並且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。TFIDF實際上是:TF * IDF,TF詞頻(Term Frequency),IDF逆向檔案頻率(Inverse Document Frequency)。TF表示詞條在文件d中出現的頻率。IDF的主要思想是:如果包含詞條t的文件越少,也就是n越小,IDF越大,則說明詞條t具有很好的類別區分能力。如果某一類文件C中包含詞條t的文件數為m,而其它類包含t的文件總數為k,顯然所有包含t的文件數n=m+k,當m大的時候,n也大,按照IDF公式得到的IDF的值會小,就說明該詞條t類別區分能力不強。但是實際上,如果一個詞條在一個類的文件中頻繁出現,則說明該詞條能夠很好代表這個類的文字的特徵,這樣的詞條應該給它們賦予較高的權重,並選來作為該類文字的特徵詞以區別與其它類文件。這就是IDF的不足之處. 在一份給定的檔案裡,詞頻
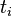 來說,它的重要性可表示為:
來說,它的重要性可表示為:
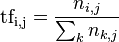
以上式子中  是該詞在檔案
是該詞在檔案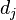 中的出現次數,而分母則是在檔案中所有字詞的出現次數之和。
中的出現次數,而分母則是在檔案中所有字詞的出現次數之和。
逆向檔案頻率(inverse document frequency,IDF)是一個詞語普遍重要性的度量。某一特定詞語的IDF,可以由總檔案數目除以包含該詞語之檔案的數目,再將得到的商取對數得到:
其中
- |D|:語料庫中的檔案總數
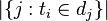 :包含詞語的檔案數目(即
:包含詞語的檔案數目(即 的檔案數目)如果該詞語不在語料庫中,就會導致被除數為零,因此一般情況下使用
的檔案數目)如果該詞語不在語料庫中,就會導致被除數為零,因此一般情況下使用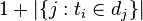
然後

某一特定檔案內的高詞語頻率,以及該詞語在整個檔案集合中的低檔案頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。
TF:詞頻
IDF:逆向檔案頻率
其實也等價於權重模型,可以把IDF看成是一個權重,TF是質量。
比如要計算使用者對app1的興趣,TF是使用者對app1的使用時長/使用者總使用時長,IDF是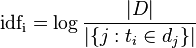 ,即總使用者數量/app1的使用者數,然後取對數。另外,TF還可以用啟動次數,平均每次啟動使用時間等。如果需要標準化TFIDF值,則只需把不是app1的看成一類,計算出他們的TFIDF。最後得到一個總和,使用TFIDF1/總和即可得到一個(0,1)之間的值,擴充套件演算法有bm25演算法等
,即總使用者數量/app1的使用者數,然後取對數。另外,TF還可以用啟動次數,平均每次啟動使用時間等。如果需要標準化TFIDF值,則只需把不是app1的看成一類,計算出他們的TFIDF。最後得到一個總和,使用TFIDF1/總和即可得到一個(0,1)之間的值,擴充套件演算法有bm25演算法等