
OpenCL之矩陣乘法實現
阿新 • • 發佈:2019-02-17
kernel
在opencl中,一般最優價值的就是kernel,前面寫的配置檔案基本沒有很大的差別,主要是kernel寫法上。其中矩陣運算又是最能體現opencl價值的地方。先上寫的kernel:
__kernel void matrix_mult(
const int Ndim,
const int Mdim,
const int Pdim,
__global const float* A,
__global const float* B,
__global float* C)
{
int i = get_global_id(0);
int 上面的配置檔案看起來簡單其實已經包含了兩方面的並行,首先是裡面的乘法,這裡是對所有的乘法可以進行並行。如果是M×P,P×N的矩陣,那麼最多可以進行:M×N×P次乘法,如果沒有超過GPU裡面流媒體的處理器個數的話那麼就可以同時執行,否者也只能滿負荷執行。接著計算完這個之後就是加法的並行操作。用if是防止越界。
配置
在這裡要特別說明的就是我們在傳資料給從機的時候我們是傳的一維陣列,再通過傳矩陣的維度來還原回二維陣列。
配置檔案的說明可以參考我之前的部落格:請點選!
直接貼程式碼:
#include <CL/cl.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
#include <fstream>
using namespace std;
#define NWITEMS 6
#pragma comment (lib,"OpenCL.lib") 效果
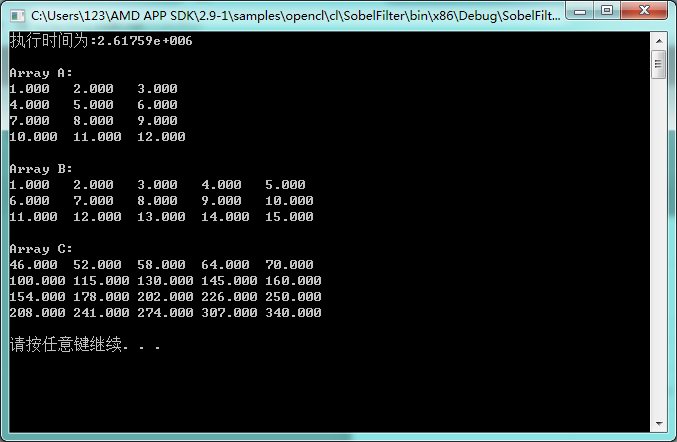
我演示一個4×5與5×6的矩陣的乘法:
請點選:參考文件
另外可以免積分下載AMD OpenCL教程:點選進入下載