
cs231n 卷積神經網路與計算機視覺 1 基礎梳理與KNN影象分類
本導論主要介紹了影象分類問題及資料驅動方法。
影象分類問題 image classification
影象的分類問題簡單來說就是對選擇一個給定label的過程。如下圖:
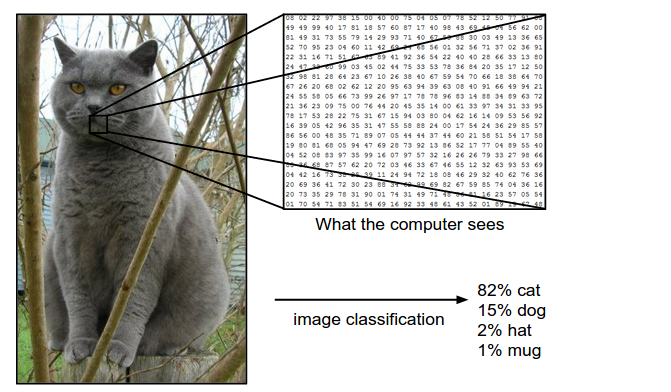
此圖片為248×400畫素的圖片,對電腦來說他是一個248 x 400 x 3的3維陣列,其中的3代表紅綠藍三色通道(這裡文中預設是使用RGB格式),假設我們設定,這幅圖片的label有四種可能,cat、dog、hat、mug,對他的分類就是通過這248 x 400 x 3=297,600個數字得出其中的一個標籤比如cat。這與其他分類過程是相似的。
分類的挑戰性
但是與機器學習中其他的分類問題不同是,影象分類還有許多的挑戰,主要表現在以下幾部分:
1. 視角的變化viewpoint variation,同一個物體在不同的視角下會有不同的表現,而視角的變化可以說是無窮多的。
2. 比例的變化scale variation ,比如同樣是一個字,四號字型,和一號字型他們對應的比例是不同的。
3. 變形deformation,很多物體並非剛性,往往在不同時刻有不一樣的展現形式,比如站著的人與坐著的人都是一個人,但是形狀已經變了。
4. 遮擋occulsion,現實中的圖片往往不是以此排列展開的,彼此遮擋的時候很多.
5. 光照變化 illumination condations,光照的角度不同往往會造成圖片中物體的數值形式的差異。
6. 背景的影響 background clutter. 有時候圖片的背景與目標物體很接近不易分辨,比如變色龍.
7. 概念的複雜性 intra-class variation,一個概念下往往會對應不同的物體,比如label為car的圖片可能包含各種各樣的汽車。
下圖是上面概念的展示:
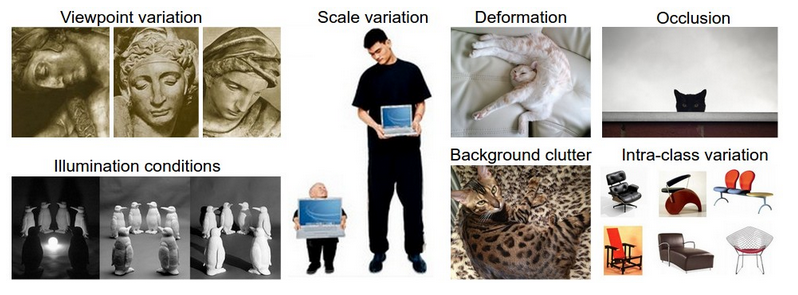
顯示中這些不定的變化往往會同時出現,造成了識別的困難,一個比較好的分類法方法應該對上面面臨的變化有一定的魯棒性。
資料驅動方法
學過機器學習的對於這個概念應該比較容易理解,我們不會直接告訴電腦如何去分類,(其實我們也不知道如何寫一段程式直接告訴電腦該如何對圖片進行分類)我們要做的就是給電腦一些包含標籤與圖片的樣例,讓電腦自己學習如何分類,這裡成這種依靠訓練資料的方法為data-driven approach,如下圖,我們給電腦數以千計的圖片,每類圖片都包含數以萬計張不同的圖片,讓電腦學習:

影象分類流程
完整的影象分類流程如下:
1. 輸入 input :輸入n張包含一類標籤的圖片,這也是訓練資料集。
2. 學習Learning:使用上面的訓練資料,進行學習,得到這類標籤對應的模型,這也叫訓練一個分類器。
3. 評估 evaluation: 最後我們用其他的新圖片和測試評估得到的分類器的效果,當讓我們希望它的預測結果中有大多數與與真實結果(ground truth)相同。
最近鄰分類器 nearest neighbor classifier
我們首先使用的方法是nearest neighbor,他與convolutional neural network沒有啥關係,只是用來讓我們明白什麼叫做圖片分類。
我們使用資料集是CIFAR-10,他是由5w張訓練圖片和1w張測試圖片組成,一共6w張10類玩具圖片。
所謂nearest neighbor就是比較圖片之間的差別大小,認為差別小的就是一類,其中一種簡單的方法就是計算每個畫素之間的差別然後將所有的差別相加,可以用l1距離或者l2距離來衡量畫素之間的差別,設輸入資料為向量I1,待測試資料為向量I2。L1距離公式為:

它的含義是計算每個畫素間的l1範數然後相加,形象化如下:
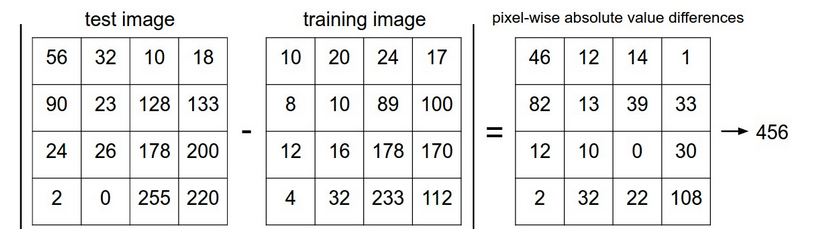
上面圖片的差別是456,如果該待測試資料與所有的已知資料中的距離最小就是456,那麼我們就認為他是與該已知的訓練數圖片最相似。
這種分類方法並不理想,文中說其測試結果為38.6%的測試結果正確,這與人類的識別能力(94%左右)相差甚遠,而卷積神經網路能達到95%左右的精確度,而如果我們採取l2範數的方法來測試,得到的結果僅僅是35.4%,更低一點點,l2方法的公式是:
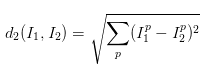
其他步驟與l1相同。
L2對大差距更為敏感如下例:
如三個向量分別為【2、3、4、1】【2、3、4、9】 【6、7、4、1】,測試第一個向量與另外兩個的差距
l1結果為9-1=8 和6-2+7-3=8
l2結果為
說明如果用l1範數來計算兩者差距時認為後面的兩個向量與第一個差不多,但是l2認為雖然第二個與第一個僅有一個值不同但是其值差距較大,所以認為第三個比第二個更像第一個。
KNN分類器
knn叫作k-nearest neighbor,他與nearest neighbor的區別就是不僅僅一看最接近的一個,而是取前k個最接近的,投票,比如與待測試圖片想四的前5個圖片的label分別是cat cat dog cat dog,那麼我們就認為他是cat。
但是k到底選幾好呢?我們可以使用驗證(validation)的方法
Validation sets for Hyperparameter tuning 驗證集引數調優
使用knn時我們需要知道k等於幾的時候得到的值最好,或者使用l1還l2的效果比較好,如何得到我們想要的這些引數的值呢?首先要注意的是我們不能使用測試集來比較各個值的好處,因為現實生活中測試集是我們無法得到的,另外如果使用測試集得到的引數在應用的時候並不好,這也許就是造成了過擬合,過度的與測試集的資料擬合了。應該記住,測試集只能夠作為最後的測試用,不能用來調整引數。
我們常使用調整引數的方法之一就是使用驗證集validation sets來調優,以CIFAR-10為例:我們可以將50000個訓練集人為劃分為49000個訓練集和1000個驗證集,使用49000個訓練集來訓練模型用這1000個來檢視不同引數時模型的表現,選擇表現最好的模型。
如果你認為一個驗證集數量太小可能不具有代表性,那麼可以使用更科學的交叉驗證的方法,交叉驗證是將訓練集分為n部分,然後每一部分都以此作為驗證集來觀察結果,例如將50000化為10fold,每次用一部分得到不同k值時的結果,最後對於每一個k值都可以得到10個準確度,可以使用其平均值最為最中的衡量標準,選擇最好的k值。下圖是將資料分為5部分後得到的不同k值的結果:
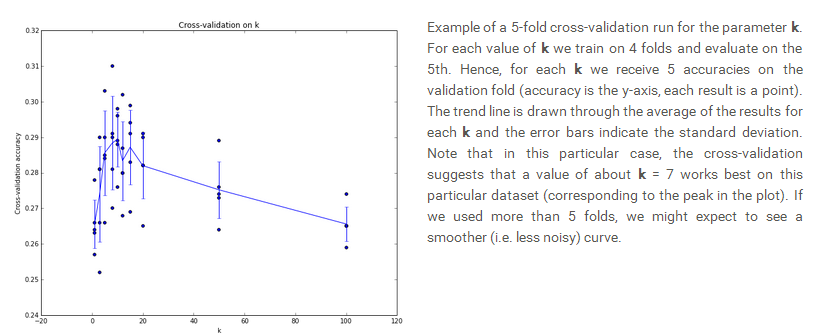
可以看出在k=7左右時精確度最高因此選擇k等於7.
Pros and Cons of nearest neighbor nn方法的優缺點分析
由上面的介紹可以看到nearest neighbor的優點就是容易理解,容易實施,不用訓練,但是在計算測試結果的時候需要將每一個結果與訓練資料分別匹配計算,非常耗時但是我們一般在應用時需要較快的對目標圖片進行判斷分類,而我們後面將學到的深度神經網路雖然訓練時間很長但是其應用時可以非常快的進行分類操作。
As an aside, 順便說一句,很多人也在對nearest neighbor 的計算複雜度進行研究, 一些 Approximate Nearest Neighbor (ANN) 演算法和資料庫可以用來加速計算比如 FLANN).這些演算法會對計算的精確度和檢索的複雜度做一些權衡,通常會用些預處理比如建立 kdtree, 或者先進行聚類等(如 k-means algorithm)。
Nearest Neighbor Classifier 有時候在低緯度的一些資料集中表現較好,但是一般不適用於與影象的分類 ,他只對影象的顏色或者背景的值比較感興趣,並不關注影象中的內容,比如下圖的人像,在變換之後人還是一樣的人可是用nearest neighbor得到的結果卻相差很多:

為了更加突出表現使用畫素間的差異不能用於很好的表現圖片之間的差異,文中用t-SNE來將不同圖片使用畫素差異(l2)表現在下圖中:

可見相似的圖片主要是主色調和背景的相似,而不是圖片中內容的相似。比如紅色的車和在紅色背景下的馬被判斷為相似。
由此看見利用畫素間的區別來區分圖片的類別的效果並不好。下節中我們會學習到一個準確度為90%左右,分類迅速的分類器。
Applying kNN in practice
knn的運用流程:
1. 預處理: 將特徵標準化為均值為0,標準差為1的資料.
2. 降維,例如使用pca
3. 隨機劃分驗證集
4. 保證訓練資料在70%-90%左右. 使用交叉驗證的時候越多folds 越好, 但是越 expensive.
5. 使用驗證集選擇引數和distance types (L1 and L2 are good candidates)
6. 如果knn花費時間比較長嘗試使用FLANN等工具箱加速運算,但是可能會犧牲精確度。
7. 使用最佳引數在全部的資料集上訓練,在test set上測試。
