
cs231n 卷積神經網路與計算機視覺 2 SVM softmax
linear classification
上節中簡單介紹了影象分類的概念,並且學習了費時費記憶體但是精度不高的knn法,本節我們將會進一步學習一種更好的方法,以後的章節中會慢慢引入神經網路和convolutional neural network。這種新的演算法有兩部分組成:
1. 評價函式score function,用於將原始資料對映到分類結果(預測值);
2. 損失函式loss function, 用於定量分析預測值與真實值的相似程度,損失函式越小,預測值越接近真實值。
我們將兩者結合,損失函式中的引數也是評價函式中的引數,找到將loss function最小化的引數。
線性分類的引數化對映
這裡首先討論前面講的score function, 最簡單的實現使用引數將原始資料對映到輸出分類的方法就是線性分類,他的方程如下:
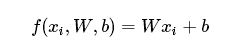
(公式的含義可以直接看後面的一節)
其中的x就是圖片的中的數值,上一章節我們提到過一個rgb的圖片包含三維資料,這裡是將所的所有的資料都展開為1維資料,其中我們需要知道w和b的術語名稱:
W:權重 weight ;b 偏差bias vector或者截距intercept
以下是我們需要知道的事情:
1. 多分類中,若有k類結果,那麼w就有k行,上面的矩陣方程能很好的同時表達k類的得分;
2. 我們的目標是控制w和b使我們的分類在全域性範圍內得分儘可能的與真實值相同,我們希望通過最後的函式得到的結果中,真實的類別會得到更大的score;
3. 當我們通過訓練資料得到w和b之後,就可以用這些引數方便快捷的對新圖片進行預測;
4. 最後,上面的公式在計算大量資料時會比knn等比較的方法更加迅速
線性影象分類的解釋
如何才能根據上面提到的線性分類的方程進行分類呢?
主要到其中x是三個顏色通道rgb的展開,其中是各個畫素的值,如果我們想根據上面的公式判斷一個物體是大海還是草地,按照經驗我們希望在藍色通道代表的值中計算海水分數的權重要大一點,計算草地時,綠色通道的權重要大一些,也就是說可以通過調整引數來使得輸出值儘量的與我們想要的分類近似。
下面的例子中,我們要判斷一張圖片是屬於cat、dog、還是ship,假設我們最後的引數如下,得到了三種分類的不同的分數:

可見計算結果更傾向於認為圖片是一隻狗。
幾何解釋
上面我們提到過需要把圖片展開為一維的資料,如在32x32的資料中,我們每一張圖片一共有3072個數值,換一種思路,一張圖片=3072個數,那麼我們可以認為這張圖片是3072維中的一個點,我們要做的分類也成了對點進行分類,為了便於展現,我們在二維空間中用下圖表現:
![]()
我們需要做個就是建立上面的線性矩陣方程代入之後得到的結果用於分類。
按照上圖中所展現的,w控制斜率,b控制截距,如果沒有b,那麼所有類別分界線都會經過0點。
模板解釋
另外一種理解w的方法是將w理解為每一個類別的模板template或者prototype,模板的匹配程度就是利用內積的結果來衡量。下圖是通過學習cifar-10得到的template:

上圖可以看出我們學到的horse彷彿有兩隻頭,兩隻頭的原因是在資料集中訓練集包含向左和向右兩種馬,也就是說線性分類器將多個形狀集合到了一張圖片(template)中,而且上面的模板似乎每個物體的顏色都已經確定了,如果是一種白色馬則可能與模板相差多一些,也就是說線性分類器不能很好的解釋不同的物體的顏色資訊。後面我們學習的神經網路會幫我們解決這個問題。
其他
- 我們可以將b與w合併,如下圖:
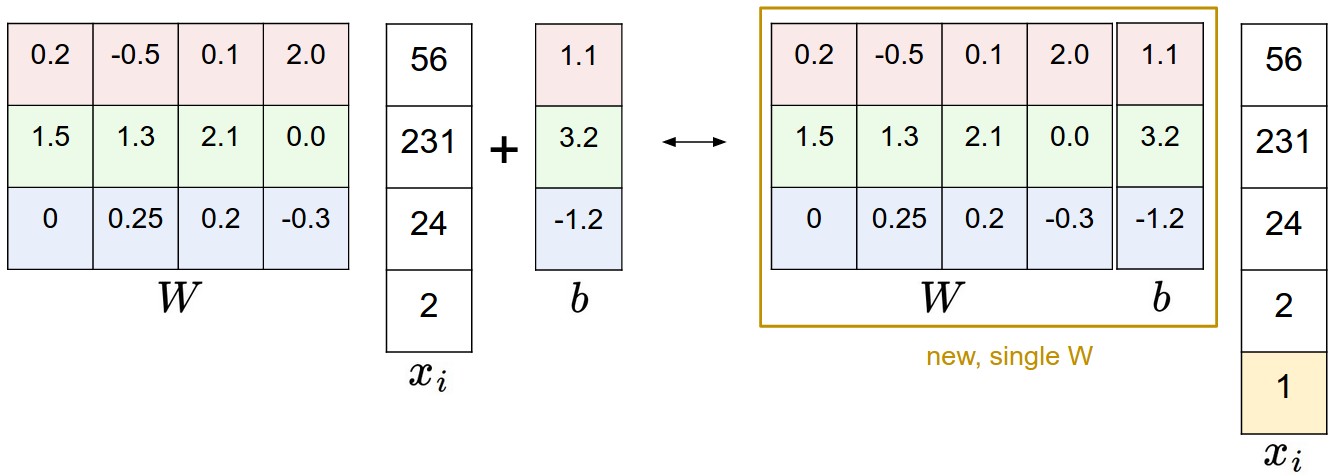
- 影象預處理,上面我們一直使用的是0-255之間的原始數值計算,然而在機器學習中,我們一般會對影象進行規範化,例如可以將各個畫素的值減去所有畫素的平均值得到範圍近似於[-127,127]的新值,更常見的是將他們對映到 [-1, 1]中去. 將資料規範為0均值是非常重要的只不過現在我們暫時不證.
損失函式
上面的論述中我們已經初步明白如何利用w和b建立一個score function,但是還是沒有利用我們標定的label值,我們將通過score function得到的值與ground truth相比較,分類結果與真實值越相似越好,我們稱這個相似的程度的衡量函式為loss function,預測結果越準確,損失函式值越小。下面我們將學習如何建立一個loss function。
Multiclass Support Vector Machine loss 多分類支援向量機損失函式
SVM loss 的中心思想是,如果正確分類的得分應該比錯誤分類的得分高,而且至少應該高
Let’s now get more precise.上面我們用 f(xi,W)表示第i個圖的得分函式,yi表示正確的類別,j表示第j類,這裡我們用
上式可以看出如果正確類別的得分比其他類值大
代入上文中線性分類的得分函式,上式變為:
上面的 max(0,−)函式經常被稱作 hinge loss(合頁損失). 有時候我們也可以用 squared hinge loss SVM (or L2-SVM)來代替它,他的表示式是
規則化
上面的公式其實還有一個bug:按照這個公式得到的值不唯一。假設我們已經得到了一組w可以正確的份額裡而且可以使損失函式為0,那麼如果我們將w都擴大
但是我們往往希望得到一個確切的最好的引數來是我們快速有效的進行分類工作. 我們可以通過新增一個 regularization penalty來實現. 最常見的是新增二範數。新增懲罰項(規則化)之後的表示式為:
其中的lambda往往可以用交叉驗證來選擇。
規則化有很多好處,例如在svm中二範數規則化可以得到最大裕量(max margin)可以看Andrew Ng 老師的講義http://cs229.stanford.edu/notes/cs229-notes3.pdf。
對引數進行懲罰的一大好處就是可以避免過擬合,避免因為某一個因素或者較大的權重,因為在l2時單個大權重往往得到的懲罰比幾個小的加起來都多,(上節中也提到了l1和l2 的區別http://blog.csdn.net/bea_tree/article/details/51472839#t4)。
另外注意到的是偏差項b,不會對輸入的特徵的影響力產生作用,所以並沒有對b進行規則懲罰。
現在我們已經有了如果評價分類結果的loss function ,那麼剩下 的就是如何利用他來求解上面所有的引數了。
其他
Δ 的選擇。上文中我們一直沒有討論Δ 的取值,實際應用中我們一般取1即可。這是因為Δ 和λ 有著同樣的功能:平衡data loss 與regulation loss.試想,如果Δ 很大,那麼我們為了得到較小的loss值,就要取得較大的w值來彌補,而λ 又可以調整w的值,反之亦然。也就是說不論Δ 變大或者變小都以用w來彌補,也就是最終的loss function的平衡是w的平衡,λ 可以用來控制它。- 二分類是多分類的特殊情況
- 實際應用中神經網路往往不可微,這個時候的優化依然可以使用subgradient方法
Softmax classifier
softmax是另外一個比較常用的多分類方法,與svm類似,他是將svm的hinge loss變成了cross-entropy loss:
fj代表第j類的得分。下式稱作softmax function
可見cross-entropy loss 包含softmax function。下面從兩個角度來理解這個loss function
1. 資訊理論角度。資訊理論中有個重要的概念叫做交叉熵cross-entropy, 具體這篇論文中有講解http://eprints.eemcs.utwente.nl/7716/01/fulltext.pdf。他的公式是:
(這裡順帶著寫下夏農熵的公式:
 )
) 為了便於發現交叉熵與 loss的聯絡,這裡再貼一下損失函式的公式:
相關推薦
cs231n 卷積神經網路與計算機視覺 2 SVM softmax
linear classification 上節中簡單介紹了影象分類的概念,並且學習了費時費記憶體但是精度不高的knn法,本節我們將會進一步學習一種更好的方法,以後的章節中會慢慢引入神經網路和convolutional neural network。這種新的演
cs231n 卷積神經網路與計算機視覺 2 SVM softmax
linear classification 上節中簡單介紹了影象分類的概念,並且學習了費時費記憶體但是精度不高的knn法,本節我們將會進一步學習一種更好的方法,以後的章節中會慢慢引入神經網路和convolutional neural network。這種新的演算法有兩
cs231n 卷積神經網路與計算機視覺 1 基礎梳理與KNN影象分類
本導論主要介紹了影象分類問題及資料驅動方法。 影象分類問題 image classification 影象的分類問題簡單來說就是對選擇一個給定label的過程。如下圖: 此圖片為248×400畫素的圖片,對電腦來說他是一個248 x 400 x 3的3維陣列,其中的
CS231n 卷積神經網路與計算機視覺 6 資料預處理 權重初始化 規則化 損失函式 等常用方法總結
1 資料處理 首先註明我們要處理的資料是矩陣X,其shape為[N x D] (N =number of data, D =dimensionality). 1.1 Mean subtraction 去均值 去均值是一種常用的資料處理方式.它是將各個特徵值減去其均
CS231n 卷積神經網路與計算機視覺 10 卷積神經網路學了些什麼?
本章是Stanford cs231n正在草擬的一章,主要將ConvNets視覺化,進一步理解卷積神經網路。 1 視覺化啟用值和第一層權重 啟用值 最直接的視覺化就是展示網路在向前傳播時的啟用值,ReLU 為啟用函式的網路中開始時啟用值一般是點狀物比較多比較分散,但是
cs231n 卷積神經網路與計算機視覺 1 基礎梳理與KNN影象分類
本導論主要介紹了影象分類問題及資料驅動方法。 影象分類問題 image classification 影象的分類問題簡單來說就是對選擇一個給定label的過程。如下圖: 此圖片為248×400畫素的圖片,對電腦來說他是一個248 x 400 x 3
吳恩達deeplearning.ai第四課學習心得:卷積神經網路與計算機視覺
不久前,Coursera 上放出了吳恩達 deeplearning.ai 的第四門課程《卷積神經網路》。本文是加拿大國家銀行首席分析師 Ryan Shrott 在完成該課程後所寫的學習心得,有助於大家直觀地瞭解、學習計算機視覺。 我最近在 Coursera 上完成了吳恩達教授的計算機視覺課程。吳恩達
【深度學習】8:CNN卷積神經網路與sklearn資料集實現數字識別
前言:這個程式碼是自己閒暇無事時候寫的。 因為CNN卷積神經網路用MNIST資料集、sklearn資料集程式碼很多部分都很相似,這一篇就不附詳細說明,原始碼最下。CNN卷積神經網路的工作原理,請詳情參考——【深度學習】5:CNN卷積神經網路原理、MNIST資料
深度學習:卷積神經網路與影象識別基本概念
一 卷積神經網路的組成 影象分類可以認為是給定一副測試圖片作為輸入 IϵRW×H×CIϵRW×H×C,輸出該圖片 屬於哪一類。引數 W 是影象的寬度,H 是高度,C 是通道的個數;彩色影象中 C = 3,灰度影象 中 C = 1。一般的會設定總共類別的個數,
深度學習進階(五)--卷積神經網路與深度置信網路以及自動編碼初識(補昨天部落格更新)
總結一下昨天的學習過程 (注:這幾天老不在狀態,貌似進入了學習激情的瓶頸期,動力以及平靜心嚴重失控,Python3.X與Python2.X之間的程式碼除錯,尤其是環境配置搞得頭昏腦脹) 昨天瞭解接觸的內容 CNN卷積神經網路的基本原理以及在CPU中測試以及程式碼除錯(又是失
卷積神經網路特徵圖視覺化(自定義網路和VGG網路)
藉助Keras和Opencv實現的神經網路中間層特徵圖的視覺化功能,方便我們研究CNN這個黑盒子裡到發生了什麼。 自定義網路特徵視覺化 程式碼: # coding: utf-8 from keras.models import Model import c
王小草【深度學習】筆記第四彈--卷積神經網路與遷移學習
標籤(空格分隔): 王小草深度學習筆記 1. 影象識別與定位 影象的相關任務可以分成以下兩大類和四小類: 影象識別,影象識別+定位,物體檢測,影象分割。 影象的定位就是指在這個圖片中不但識別出有只貓,還把貓在圖片中的位置給精確地摳出來今天我們來講
簡單卷積神經網路的tensorboard視覺化
tensorboard是tensorflow官方提供的視覺化工具。可以將模型訓練中的資料彙總、顯示出來。本文是基於tensorflow1.2版本的。這個版本的tensorboard的介面如圖: image.png tensorboard支援8種視覺化,也就是上圖中的8個選項卡,它們分別是
卷積神經網路實戰(視覺化部分)——使用keras識別貓咪
更多深度文章,請關注雲端計算頻道:https://yq.aliyun.com/cloud 作者介紹:Erik Reppel,coinbase公司程式設計師 作者部落格:https://hackernoon.com/@erikreppel 作者twitter:http
【TensorFlow】第三課 卷積神經網路與影象應用
一,Image classification popeline 一般來說想要使用純程式設計的方式來讓機器識別一張圖片中的東西是非常困難的,常用的方法就是使用一些運算元來獲取影象中的很多的特徵,然後使用
使用卷積神經網路進行圖片分類 2
使用caffe構建卷積神經網路一、實驗介紹1.1 實驗內容上一次實驗我們介紹了卷積神經網路的基本原理,本次實驗我們將學習如何使用深度學習框架caffe構建卷積神經網路,你將看到在深度學習框架上搭建和訓練模型是一件非常簡單快捷的事情(當然,是在你已經理解了基本原理的前提下)。如果上一次實驗中的一些知識點你還理解
卷積神經網路(CNN)學習筆記2:舉例理解
下圖是一個經典的CNN結構,稱為LeNet-5網路 可以看出,CNN中主要有兩種型別的網路層,分別是卷積層和池化(Pooling)/取樣層(Subsampling)。卷積層的作用是提取影象的各種特徵;池化層的作用是對原始特徵訊號進行抽象,從而大幅度減少訓練引數,另外還可以
吳恩達深度學習第四課:卷積神經網路(學習筆記2)
前言 1.之所以堅持記錄,是因為看到其他人寫的優秀部落格,內容準確詳實,思路清晰流暢,這也說明了作者對知識的深入思考。我也希望能儘量將筆記寫的準確、簡潔,方便自己回憶也方便別人參考; 2.昨天看到兩篇關於計算機視覺的發展介紹的文章:[觀點|朱鬆純:初探計算機
卷積神經網路提取特徵並用於SVM
目標是對UCI的手寫數字資料集進行識別,樣本數量大約是1600個。圖片大小為16x16。要求必須使用SVM作為二分類的分類器。 本文重點是如何使用卷積神經網路(CNN)來提取手寫數字圖片特徵,主要想看如何提取特徵的請直接看原始碼部分的94行左右,只要對tensorflow有一點了解就可以看懂。在最後會有完整的
CNN卷積神經網路--反向傳播(2,前向傳播)
卷積層:卷積層的輸入要麼來源於輸入層,要麼來源於取樣層,如上圖紅色部分。卷積層的每一個map都有一個大小相同的卷積核,Toolbox裡面是5*5的卷積核。下面是一個示例,為了簡單起見,卷積核大小為2*2,上一層的特徵map大小為4*4,用這個卷積在圖片上滾一遍,得到一個一個(4-2+1)*(4-2+1)=3