
[python] 安裝numpy+scipy+matlotlib+scikit-learn及問題解決
這篇文章主要講述Python如何安裝Numpy、Scipy、Matlotlib、Scikit-learn等庫的過程及遇到的問題解決方法。最近安裝這個真是一把淚啊,各種不相容問題和報錯,希望文章對你有所幫助吧!你可能遇到的問題包括:
ImportError: No module named sklearn 未安裝sklearn包
ImportError: DLL load failed: 找不到指定的模組
ImportError: DLL load failed: The specified module could not be found
Microsoft Visual C++ 9.0 is required Unable to find vcvarsall.bat
Numpy Install RuntimeError: Broken toolchain: cannot link a simple C program
ImportError: numpy.core.multiarray failed to import
ImportError: cannot import name __check_build
ImportError: No module named matplotlib.pyplot
一. 安裝過程
最早我是使用"pip install scikit-learn"命令安裝的Scikit-Learn程式,並沒有注意需要安裝Numpy、Scipy、Matlotlib,然後在報錯"No module named Numpy"後,我接著使用PIP或者下載exe程式安裝相應的包,同時也不理解安裝順序和版本的重要性。其中最終都會報錯" ImportError: DLL load failed: 找不到指定的模組",此時我的解決方法是:
錯誤:sklearn ImportError: DLL load failed: 找不到指定的模組
重點:安裝python第三方庫時總會出現各種相容問題,應該是版本問題,版本需要一致。
下載:
第一步:解除安裝原始版本,包括Numpy、Scipy、Matlotlib、Scikit-Learn
pip uninstall scikit-learn
pip uninstall numpy
pip uninstall scipy
pip uninstall matplotlib
第二步:不使用"pip install package"或"easy_install package"安裝,或者去百度\CSDN下載exe檔案,而是去到官網下載相應版本。
安裝過程中最重要的地方就是版本需要相容。其中作業系統為64位,Python為2.7.8 64位,下載的四個whl檔案如下,其中cp27表示CPython 2.7版本,cp34表示CPython 3.4,win_arm64指的是64位版本。
numpy-1.10.2-cp27-none-win_amd64.whl
scipy-0.16.1-cp27-none-win_amd64.whl
matplotlib-1.5.0-cp27-none-win_amd64.whl
scikit_learn-0.17-cp27-none-win_amd64.whl
PS:不推薦使用"pip install numpy"安裝或下載如"numpy-MKL-1.8.0.win-amd64-py2.7.exe"類似檔案,地址如:
第三步:去到Python安裝Scripts目錄下,再使用pip install xxx.whl安裝,先裝Numpy\Scipy\Matlotlib包,再安裝Scikit-Learn。
其中我的python安裝路徑"G:\software\Program software\Python\python insert\Scripts",同時四個whl檔案安裝核心程式碼:
pip install G:\numpy+scipy+matplotlib\numpy-1.10.2-cp27-none-win_amd64.whl
pip install G:\numpy+scipy+matplotlib\scikit_learn-0.17-cp27-none-win_amd64.whl

C:\>G: G:\>cd G:\software\Program software\Python\python insert\Scripts G:\software\Program software\Python\python insert\Scripts>pip install G:\numpy+s cipy+matplotlib\numpy-1.10.2-cp27-none-win_amd64.whl Processing g:\numpy+scipy+matplotlib\numpy-1.10.2-cp27-none-win_amd64.whl Installing collected packages: numpy Successfully installed numpy-1.10.2 G:\software\Program software\Python\python insert\Scripts>pip install G:\numpy+s cipy+matplotlib\matplotlib-1.5.0-cp27-none-win_amd64.whl Installing collected packages: matplotlib Successfully installed matplotlib-1.5.0 G:\software\Program software\Python\python insert\Scripts>pip install G:\numpy+s cipy+matplotlib\scipy-0.16.1-cp27-none-win_amd64.whl Processing g:\numpy+scipy+matplotlib\scipy-0.16.1-cp27-none-win_amd64.whl Installing collected packages: scipy Successfully installed scipy-0.16.1 G:\software\Program software\Python\python insert\Scripts>pip install G:\numpy+s cipy+matplotlib\scikit_learn-0.17-cp27-none-win_amd64.whl Processing g:\numpy+scipy+matplotlib\scikit_learn-0.17-cp27-none-win_amd64.whl Installing collected packages: scikit-learn Successfully installed scikit-learn-0.17
第四步:此時配置完成,關鍵是Python64位版本相容問題和Scripts目錄。最後用北郵論壇一個神人的回覆結束這個安裝過程:“傻孩子,用套件啊,給你介紹一個Anaconda或winpython。只能幫你到這裡了! ”
二. 測試執行環境
搞了這麼半天,為什麼要裝這些呢?給幾個用例驗證它的正確安裝和強大吧!
Scikit-Learn是基於python的機器學習模組,基於BSD開源許可。Scikit-learn的基本功能主要被分為六個部分,分類,迴歸,聚類,資料降維,模型選擇,資料預處理,具體可以參考官方網站上的文件。
NumPy(Numeric Python)系統是Python的一種開源的數值計算擴充套件,一個用python實現的科學計算包。它提供了許多高階的數值程式設計工具,如:矩陣資料型別、向量處理,以及精密的運算庫。專為進行嚴格的數字處理而產生。
內容包括:1、一個強大的N維陣列物件Array;2、比較成熟的(廣播)函式庫;3、用於整合C/C++和Fortran程式碼的工具包;4、實用的線性代數、傅立葉變換和隨機數生成函式。numpy和稀疏矩陣運算包scipy配合使用更加方便。
SciPy (pronounced "Sigh Pie") 是一個開源的數學、科學和工程計算包。它是一款方便、易於使用、專為科學和工程設計的Python工具包,包括統計、優化、整合、線性代數模組、傅立葉變換、訊號和影象處理、常微分方程求解器等等。
Matplotlib是一個Python的圖形框架,類似於MATLAB和R語言。它是python最著名的繪相簿,它提供了一整套和matlab相似的命令API,十分適合互動式地進行製圖。而且也可以方便地將它作為繪圖控制元件,嵌入GUI應用程式中。
第一個程式碼:斜線座標,測試matplotlib
import matplotlib import numpy import scipy import matplotlib.pyplot as plt plt.plot([1,2,3]) plt.ylabel('some numbers') plt.show()
執行結果:
import numpy as np import matplotlib.pyplot as plt X = np.arange(-5.0, 5.0, 0.1) Y = np.arange(-5.0, 5.0, 0.1) x, y = np.meshgrid(X, Y) f = 17 * x ** 2 - 16 * np.abs(x) * y + 17 * y ** 2 - 225 fig = plt.figure() cs = plt.contour(x, y, f, 0, colors = 'r') plt.show()
執行結果:
import numpy as np import matplotlib.pyplot as plt N = 5 menMeans = (20, 35, 30, 35, 27) menStd = (2, 3, 4, 1, 2) ind = np.arange(N) # the x locations for the groups width = 0.35 # the width of the bars fig, ax = plt.subplots() rects1 = ax.bar(ind, menMeans, width, color='r', yerr=menStd) womenMeans = (25, 32, 34, 20, 25) womenStd = (3, 5, 2, 3, 3) rects2 = ax.bar(ind+width, womenMeans, width, color='y', yerr=womenStd) # add some ax.set_ylabel('Scores') ax.set_title('Scores by group and gender') ax.set_xticks(ind+width) ax.set_xticklabels( ('G1', 'G2', 'G3', 'G4', 'G5') ) ax.legend( (rects1[0], rects2[0]), ('Men', 'Women') ) def autolabel(rects): # attach some text labels for rect in rects: height = rect.get_height() ax.text(rect.get_x()+rect.get_width()/2., 1.05*height, '%d'%int(height), ha='center', va='bottom') autolabel(rects1) autolabel(rects2) plt.show()
執行結果:
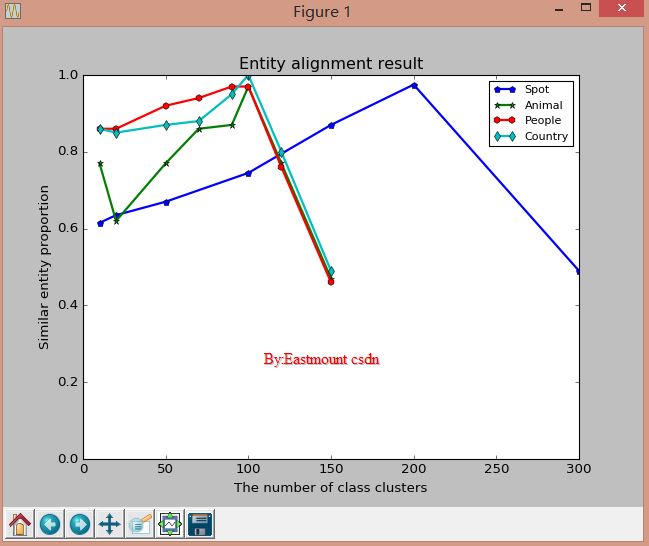
PS:如果設定legend沒有顯示比例圖示,則參考下面程式碼:
# coding=utf-8
import numpy as np
import matplotlib
import scipy
import matplotlib.pyplot as plt
#設定legend: http://bbs.byr.cn/#!article/Python/7705
#mark樣式: http://www.360doc.com/content/14/1026/02/9482_419859060.shtml
#國家 融合特徵值
x1 = [10, 20, 50, 100, 150, 200, 300]
y1 = [0.615, 0.635, 0.67, 0.745, 0.87, 0.975, 0.49]
#動物
x2 = [10, 20, 50, 70, 90, 100, 120, 150]
y2 = [0.77, 0.62, 0.77, 0.86, 0.87, 0.97, 0.77, 0.47]
#人物
x3 = [10, 20, 50, 70, 90, 100, 120, 150]
y3 = [0.86, 0.86, 0.92, 0.94, 0.97, 0.97, 0.76, 0.46]
#國家
x4 = [10, 20, 50, 70, 90, 100, 120, 150]
y4 = [0.86, 0.85, 0.87, 0.88, 0.95, 1.0, 0.8, 0.49]
plt.title('Entity alignment result')
plt.xlabel('The number of class clusters')
plt.ylabel('Similar entity proportion')
plot1, = plt.plot(x1, y1, '-p', linewidth=2)
plot2, = plt.plot(x2, y2, '-*', linewidth=2)
plot3, = plt.plot(x3, y3, '-h', linewidth=2)
plot4, = plt.plot(x4, y4, '-d', linewidth=2)
plt.xlim(0, 300)
plt.ylim(0.4, 1.0)
#plot返回的不是matplotlib物件本身,而是一個列表,加個逗號之後就把matplotlib物件從列表裡面提取出來
plt.legend( (plot1,plot2,plot3,plot4), ('Spot', 'Animal', 'People', 'Country'), fontsize=10)
plt.show()
第四個程式碼:矩陣資料集,測試sklearn
from sklearn import datasets iris = datasets.load_iris() digits = datasets.load_digits() print digits.data
執行結果:
# coding:utf-8 __author__ = "liuxuejiang" import jieba import jieba.posseg as pseg import os import sys from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer if __name__ == "__main__": corpus=["我 來到 北京 清華大學", #第一類文字切詞後的結果 詞之間以空格隔開 "他 來到 了 網易 杭研 大廈", #第二類文字的切詞結果 "小明 碩士 畢業 與 中國 科學院", #第三類文字的切詞結果 "我 愛 北京 天安門"] #第四類文字的切詞結果 #該類會將文字中的詞語轉換為詞頻矩陣,矩陣元素a[i][j] 表示j詞在i類文字下的詞頻 vectorizer=CountVectorizer() #該類會統計每個詞語的tf-idf權值 transformer=TfidfTransformer() #第一個fit_transform是計算tf-idf,第二個fit_transform是將文字轉為詞頻矩陣 tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus)) #獲取詞袋模型中的所有詞語 word=vectorizer.get_feature_names() #將tf-idf矩陣抽取出來,元素a[i][j]表示j詞在i類文字中的tf-idf權重 weight=tfidf.toarray() #列印每類文字的tf-idf詞語權重,第一個for遍歷所有文字,第二個for便利某一類文字下的詞語權重 for i in range(len(weight)): print u"-------這裡輸出第",i,u"類文字的詞語tf-idf權重------" for j in range(len(word)): print word[j],weight[i][j]
執行結果:
三. 其他錯誤解決方法
這裡雖然講解幾個安裝時遇到的其他錯誤及解決方法,但作者更推薦上面的安裝步驟。
在這之前,我反覆的安裝、解除安裝、升級包,其中遇到了各種錯誤,改了又改,百度了又谷歌。常見PIP用法如下:
* pip install numpy --安裝包numpy * pip uninstall numpy --解除安裝包numpy * pip show --files PackageName --檢視已安裝包 * pip list outdated --檢視待更新包資訊 * pip install --upgrade numpy --升級包 * pip install -U PackageName --升級包 * pip search PackageName --搜尋包 * pip help --顯示幫助資訊
ImportError: numpy.core.multiarray failed to import
python安裝numpy時出現的錯誤,這個通過stackoverflow和百度也是需要python版本與numpy版本一致,解決的方法包括"pip install -U numpy"升級或下載指定版本"pip install numpy==1.8"。但這顯然還涉及到更多的包,沒有前面的解除安裝下載安裝統一版本的whl靠譜。
Microsoft Visual C++ 9.0 is required(unable to find vcvarsall.bat)
因為Numpy內部矩陣運算是用C語言實現的,所以需要安裝編譯工具,這和電腦安裝的VC++或VS2012有關,解決方法:如果已安裝Visual Studio則新增環境變數VS90COMNTOOLS即可,不同的VS版本對應不同的環境變數值:
Visual Studio 2010 (VS10)設定 VS90COMNTOOLS=%VS100COMNTOOLS%
Visual Studio 2012 (VS11)設定 VS90COMNTOOLS=%VS110COMNTOOLS%
Visual Studio 2013 (VS12)設定 VS90COMNTOOLS=%VS120COMNTOOLS%
但是這並沒有解決,另一種方法是下載Micorsoft Visual C++ Compiler for Python 2.7的包。
下載地址:
參考文章:
PS:這些問題基本解決方法使用pip升級、版本一致、重新下載相關版本exe檔案再安裝。
總之,最後希望文章對你有所幫助!尤其是剛學習Python和機器學習的同學。
寫文不易,且看且珍惜!
(By:Eastmount 2015-12-17 晚上10點 )