
機器學習H2O AI框架簡介
1. H2O框架
優勢:自己實現分散式計算框架,演算法種類全,有深度學習演算法,同時可以通過Sparkling-water將 h2o 和spark 進行完美整合
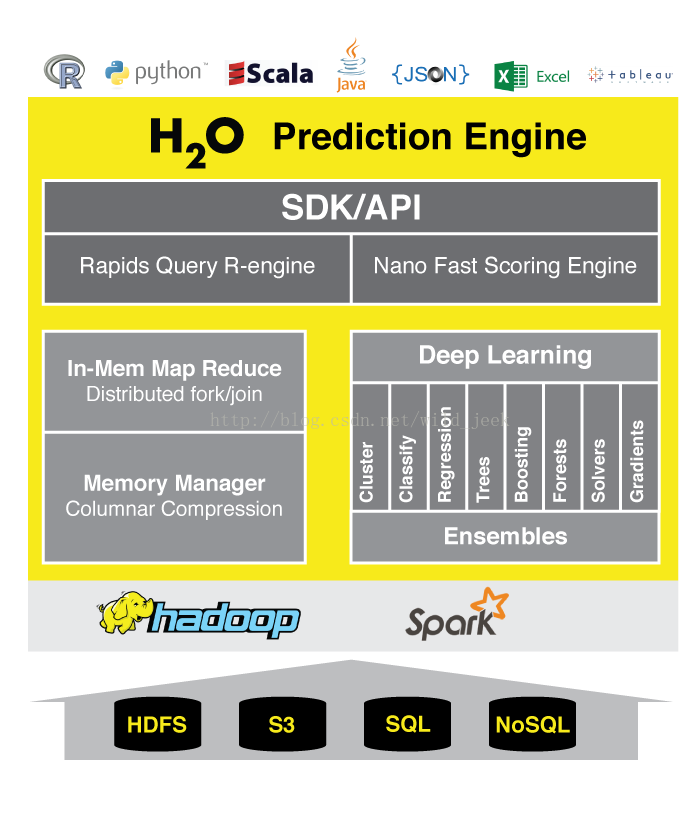
a.底層資料層
底層資料讀取Hdfs資料 s3資料 SQL 資料 noSQL資料
s3Amazon Simple Storage Service 亞馬遜的雲端儲存結構
Hive其實就是讀取HDFS
noSQL:HBase
HQL是一種類SQL語言,這種語言最終被轉化為Map/Reduce.雖然Hive提供了SQL查詢功能,但是Hive不能夠進行互動查詢--因為它只能夠在Haoop上批量的執行Hadoop 便利全部資料速度慢 老版本不支援更新操作
Hbase的能夠在它的資料庫上實時執行,而不是執行MapReduce任務在Hbase中,行是key/value對映的集合,這個對映通過row-key來唯一標識。Hbase利用Hadoop的基礎設施,可以利用通用的裝置進行水平的擴充套件。
Hive可以用來進行統計查詢,HBase可以用來進行實時查詢
b. 計算引擎層
hadoop spark
在hadoop中使用mapreduce 所起的任務只是Map任務
使用sparkling-water將H2O和Spark進行整合
c. 核心運算層
演算法引擎:深度學習
計算引擎:基於記憶體的MapReduce 使用分散式的fork/join框架(java並行框架) 記憶體管理引擎 :採用列式壓縮ColumnarCompression
d.介面層
SDK和 REST API
快速查詢R引擎 毫秒級評分引擎
h2o-3/h2o-docs/src/dev/lifecycle.md
H2OApp vs. H2OClientApp
The main class for Standalone H2O isH2OApp.(class)
H2OApp uses a helper class calledH2OStarter(class)
H2O.configureLogging();
H2O.registerExtensions();
// Fire up the H2O Cluster
H2O.main(args);
H2O.registerRestApis(relativeResourcePath);
H2O.finalizeRegistration();
water is from h2o-core and hex is fromh2o-algos.
e 核心元件
MRTask :Map/Reduce styledistributed computation
裡邊有各種mapreduce方法
(Dtask–TAICountedCompleted – countedCompleted – fork/jointask)
Chunk : ChunkType ChunkName
2. H2O中的資料結構
Frame Frame are only composed of Vecs of the sameVectorGroup
Vec 是由多個Chunck組成 可以平行計算mapreduce MRtask
newMRTask{} { final double _mean = vec.mean();
publicvoid map( Chunk chk ) {
for(int row=0; row < chk._len; row++ )
if(chk.isNA(row) ) chk.set(row,_mean);
}
}.doAll(vec);
Chunck 1000 –100 0000個element one cpu
Key
DKV 分散式Key/values儲存
AST : AbstractSyntax Tree