
【深度學習】使用tensorflow實現VGG19網路
接上一篇AlexNet,本文講述使用tensorflow實現VGG19網路。
VGG網路與AlexNet類似,也是一種CNN,VGG在2014年的 ILSVRC localization and classification 兩個問題上分別取得了第一名和第二名。VGG網路非常深,通常有16-19層,卷積核大小為 3 x 3,16和19層的區別主要在於後面三個卷積部分卷積層的數量。第二個用tensorflow獨立完成的小玩意兒......
如果想執行程式碼,詳細的配置要求都在上面連結的readme檔案中了。本文建立在一定的tensorflow基礎上,不會對太細的點進行說明。
模型結構
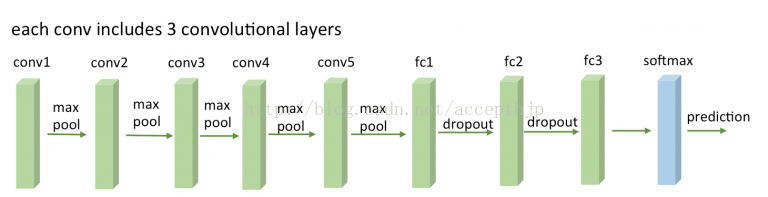
可以看到VGG的前幾層為卷積和maxpool的交替,每個卷積包含多個卷積層,後面緊跟三個全連線層。啟用函式採用Relu,訓練採用了dropout,但並沒有像AlexNet一樣採用LRN(論文給出的理由是加LRN實驗效果不好)。
模型定義
def maxPoolLayer(x, kHeight, kWidth, strideX, strideY, name, padding = "SAME"): """max-pooling""" return tf.nn.max_pool(x, ksize = [1, kHeight, kWidth, 1], strides = [1, strideX, strideY, 1], padding = padding, name = name) def dropout(x, keepPro, name = None): """dropout""" return tf.nn.dropout(x, keepPro, name) def fcLayer(x, inputD, outputD, reluFlag, name): """fully-connect""" with tf.variable_scope(name) as scope: w = tf.get_variable("w", shape = [inputD, outputD], dtype = "float") b = tf.get_variable("b", [outputD], dtype = "float") out = tf.nn.xw_plus_b(x, w, b, name = scope.name) if reluFlag: return tf.nn.relu(out) else: return out def convLayer(x, kHeight, kWidth, strideX, strideY, featureNum, name, padding = "SAME"): """convlutional""" channel = int(x.get_shape()[-1]) #獲取channel數 with tf.variable_scope(name) as scope: w = tf.get_variable("w", shape = [kHeight, kWidth, channel, featureNum]) b = tf.get_variable("b", shape = [featureNum]) featureMap = tf.nn.conv2d(x, w, strides = [1, strideY, strideX, 1], padding = padding) out = tf.nn.bias_add(featureMap, b) return tf.nn.relu(tf.reshape(out, featureMap.get_shape().as_list()), name = scope.name)
定義了卷積、pooling、dropout、全連線五個模組,使用了上一篇AlexNet中的程式碼,其中卷積模組去除了group引數,因為網路沒有像AlexNet一樣分成兩部分。接下來定義VGG19。
class VGG19(object): """VGG model""" def __init__(self, x, keepPro, classNum, skip, modelPath = "vgg19.npy"): self.X = x self.KEEPPRO = keepPro self.CLASSNUM = classNum self.SKIP = skip self.MODELPATH = modelPath #build CNN self.buildCNN() def buildCNN(self): """build model""" conv1_1 = convLayer(self.X, 3, 3, 1, 1, 64, "conv1_1" ) conv1_2 = convLayer(conv1_1, 3, 3, 1, 1, 64, "conv1_2") pool1 = maxPoolLayer(conv1_2, 2, 2, 2, 2, "pool1") conv2_1 = convLayer(pool1, 3, 3, 1, 1, 128, "conv2_1") conv2_2 = convLayer(conv2_1, 3, 3, 1, 1, 128, "conv2_2") pool2 = maxPoolLayer(conv2_2, 2, 2, 2, 2, "pool2") conv3_1 = convLayer(pool2, 3, 3, 1, 1, 256, "conv3_1") conv3_2 = convLayer(conv3_1, 3, 3, 1, 1, 256, "conv3_2") conv3_3 = convLayer(conv3_2, 3, 3, 1, 1, 256, "conv3_3") conv3_4 = convLayer(conv3_3, 3, 3, 1, 1, 256, "conv3_4") pool3 = maxPoolLayer(conv3_4, 2, 2, 2, 2, "pool3") conv4_1 = convLayer(pool3, 3, 3, 1, 1, 512, "conv4_1") conv4_2 = convLayer(conv4_1, 3, 3, 1, 1, 512, "conv4_2") conv4_3 = convLayer(conv4_2, 3, 3, 1, 1, 512, "conv4_3") conv4_4 = convLayer(conv4_3, 3, 3, 1, 1, 512, "conv4_4") pool4 = maxPoolLayer(conv4_4, 2, 2, 2, 2, "pool4") conv5_1 = convLayer(pool4, 3, 3, 1, 1, 512, "conv5_1") conv5_2 = convLayer(conv5_1, 3, 3, 1, 1, 512, "conv5_2") conv5_3 = convLayer(conv5_2, 3, 3, 1, 1, 512, "conv5_3") conv5_4 = convLayer(conv5_3, 3, 3, 1, 1, 512, "conv5_4") pool5 = maxPoolLayer(conv5_4, 2, 2, 2, 2, "pool5") fcIn = tf.reshape(pool5, [-1, 7*7*512]) fc6 = fcLayer(fcIn, 7*7*512, 4096, True, "fc6") dropout1 = dropout(fc6, self.KEEPPRO) fc7 = fcLayer(dropout1, 4096, 4096, True, "fc7") dropout2 = dropout(fc7, self.KEEPPRO) self.fc8 = fcLayer(dropout2, 4096, self.CLASSNUM, True, "fc8") def loadModel(self, sess): """load model""" wDict = np.load(self.MODELPATH, encoding = "bytes").item() #for layers in model for name in wDict: if name not in self.SKIP: with tf.variable_scope(name, reuse = True): for p in wDict[name]: if len(p.shape) == 1: #bias 只有一維 sess.run(tf.get_variable('b', trainable = False).assign(p)) else: #weights sess.run(tf.get_variable('w', trainable = False).assign(p))
buildCNN函式完全按照VGG的結構搭建網路。
loadModel函式從模型檔案中讀取引數,採用的模型檔案見github上的readme說明。
至此,我們定義了完整的模型,下面開始測試模型。
模型測試
ImageNet訓練的VGG有很多類,幾乎包含所有常見的物體,因此我們隨便從網上找幾張圖片測試。比如我直接用了之前做專案的圖片,為了避免審美疲勞,我們不只用渣土車,還要用挖掘機、採沙船:



然後編寫測試程式碼:
parser = argparse.ArgumentParser(description='Classify some images.')
parser.add_argument('mode', choices=['folder', 'url'], default='folder')
parser.add_argument('path', help='Specify a path [e.g. testModel]')
args = parser.parse_args(sys.argv[1:])
if args.mode == 'folder': #測試方式為本地資料夾
#get testImage
withPath = lambda f: '{}/{}'.format(args.path,f)
testImg = dict((f,cv2.imread(withPath(f))) for f in os.listdir(args.path) if os.path.isfile(withPath(f)))
elif args.mode == 'url': #測試方式為URL
def url2img(url): #獲取URL影象
'''url to image'''
resp = urllib.request.urlopen(url)
image = np.asarray(bytearray(resp.read()), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
return image
testImg = {args.path:url2img(args.path)}
if testImg.values():
#some params
dropoutPro = 1
classNum = 1000
skip = []
imgMean = np.array([104, 117, 124], np.float)
x = tf.placeholder("float", [1, 224, 224, 3])
model = vgg19.VGG19(x, dropoutPro, classNum, skip)
score = model.fc8
softmax = tf.nn.softmax(score)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
model.loadModel(sess) #載入模型
for key,img in testImg.items():
#img preprocess
resized = cv2.resize(img.astype(np.float), (224, 224)) - imgMean #去均值
maxx = np.argmax(sess.run(softmax, feed_dict = {x: resized.reshape((1, 224, 224, 3))})) #網路輸入為224*224
res = caffe_classes.class_names[maxx]
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, res, (int(img.shape[0]/3), int(img.shape[1]/3)), font, 1, (0, 255, 0), 2) #在影象上繪製結果
print("{}: {}\n----".format(key,res)) #輸出測試結果
cv2.imshow("demo", img)
cv2.waitKey(0)如果你看完了我AlexNet的部落格,那麼一定會發現我這裡的測試程式碼做了一些小的修改,增加了URL測試的功能,可以測試網上的影象 ,測試結果如下:


