
HDFS 和 YARN 的 HA 故障切換
一. 非 HDFS HA 叢集轉換成 HA 叢集
1. 分別啟動所有的 journalnode 程序,在其中一臺 NameNode 上完成即可(比如 NameNode1)
$HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode2. 在 NameNode1上對 journalnode 的共享資料進行初始化,然後啟動 namenode 程序
$HADOOP_HOME/bin/hdfs namenode -initializeSharedEdits
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode 3. 在 NameNode2 上同步 journalnode 的共享資料,和 NameNode 上存放的元資料,然後啟動 namenode 程序
$HADOOP_HOME/bin/hdfs namenode -bootstrapStandby
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode4. 在其中一臺 NameNode 上啟動所有的 datanode 程序
$HADOOP_HOME/sbin/hadoop-daemon.sh start datanode二. HDFS 的 HA 自動切換命令
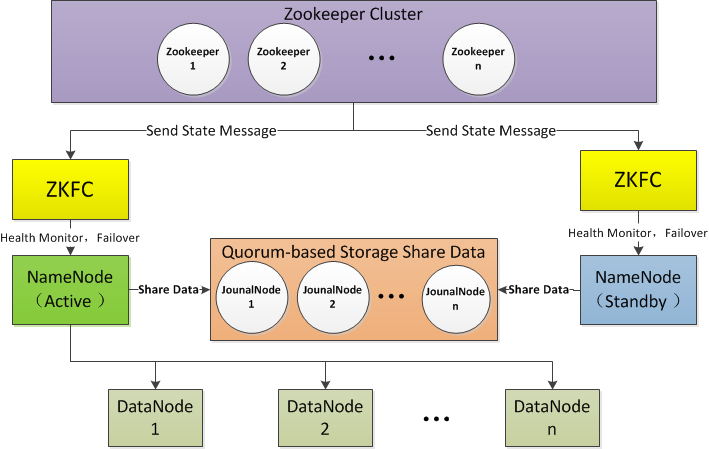
說明: 為了更加通俗的說明,筆者將兩臺執行 namenode 程序的主機名抽象為 NameNode1 和 NameNode2,筆者更傾向 NameNode1 上的執行的是 active 狀態的 namenode 程序,NameNode2 上的執行的是 standby狀態的 namenode 程序,而實際操作中,master5 就是這個 NameNode1 ,master52 就是這個 NameNode2。
| 抽象主機名 | 實際操作主機名 | 初始狀態 | 理想穩定狀態 |
|---|---|---|---|
| NameNode1 | master5 | standby | active |
| NameNode2 | master52 | standby | standby |
2.1 獲得當前 NameNode 的 active 和 standby 狀態
當未啟動 ZK 服務時,發現兩個 NameNode 都是 standby 的狀態,通過以下命令可以查得:
hdfs haadmin -getServiceState master5
hdfs haadmin -getServiceState 2.2 NameNode 的 active 和 standby 狀態切換
根據叢集是否已經在 hdfs-site.xml 中設定了 dfs.ha.automatic-failover.enabled 為 true (即自動故障狀態切換)來分兩種情況
1. 未設定自動故障切換 (false)
確定要轉為 active 狀態的主機名,這裡將 NameNode1 設為 active,使用命令列工具進行狀態切換:
hdfs haadmin -failover --forcefence --forceactive NameNode2 NameNode1此處 “NameNode2 NameNode1” 的順序表示 active 狀態由 NameNode2 轉換到 NameNode1 上(雖然 NameNode2 在轉化前也是 standby 狀態)。
有時候,當我們系統中 NameNode2 出現故障了,就可以利用上一步中把 NameNode1 的狀態切換為active 後,系統自動把 NameNode2 上的 namenode 程序關閉,再把錯誤原因排除後重啟該 namenode程序,啟動後該 namenode 狀態為 standby,等待下一次 NameNode1 出現故障時即可將 NameNode2 狀態切換為 active。
亦或者使用以下命令將 NameNode1 主機上的 namenode 狀態切換到 active 或 standby 狀態
hdfs haadmin -transitionToActive NameNode1
hdfs haadmin -transitionToStandby NameNode1 但是需要注意的是這兩個命令不會嘗試執行任何的 fence,因此不應該經常使用。應該更傾向於用 hdfs haadmin -failover 命令。
2. 設定自動故障切換 (true)
如果執行下面命令,則會報錯
hdfs haadmin -failover --forcefence --forceactive NameNode2 NameNode1錯誤資訊:
forcefence and forceactive flags not supported with auto-failover enabled.
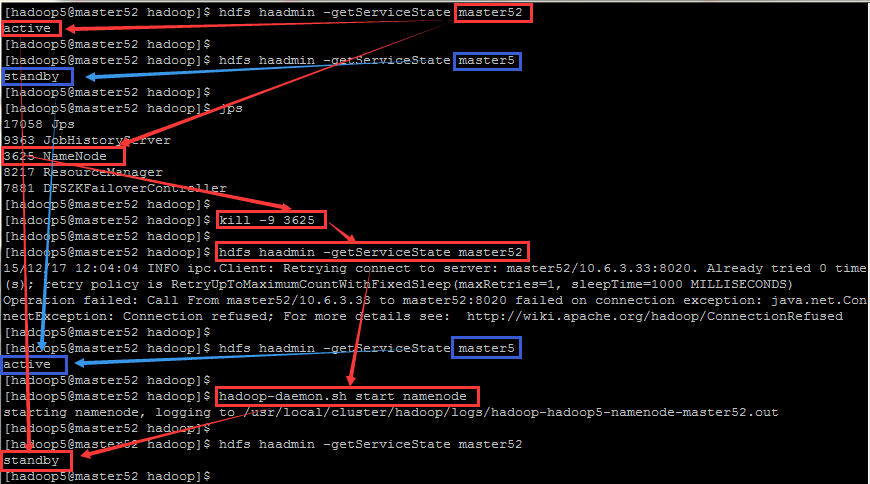
若要手工切換其中一個 NameNode 節點的 Active 狀態改變為 Standby 狀態,將另一個 NameNode 節點的 Standby 狀態改變為 Active 狀態,則可以 kill -9 <pid of NN> 來殺死當前 Active 狀態的 NameNode 上的 namenode 程序號,此時發現另一個 NameNode 節點就由 Standby 狀態改變為 Active 狀態,這個時候在重啟被殺死程序的 NameNode 上的 namenode 程序,此時就成為了 Standby 狀態,切換成功!
假設此時 master52 上 namedode 是 active 狀態,而 master5 上 namenode 是 standby 狀態,下圖呈現了該過程:
另外一種方法就是,關閉當前為 active namenode 狀態的上的 DFSZKFailoverController 程序(這個方法可靠性有待考察…)
hadoop-daemon.sh stop zkfc此時,active 狀態的 namenode 立刻更變為 standby 狀態,另一個 standby 狀態的 nameNode 立刻更變為 active 狀態,如下圖所示:
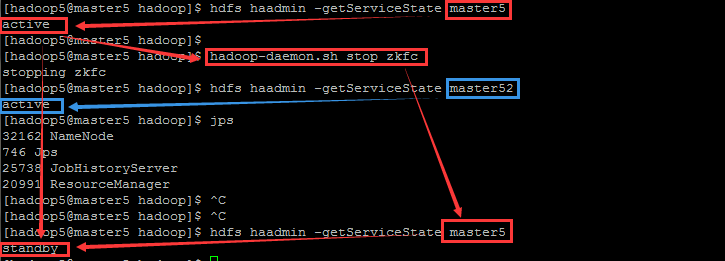
當繼續關閉了另一個 namenode 的 zkfc 服務之後,它依舊是 active 狀態,且兩個 namenode 仍然正常工作!
在經過上述之後,master5 的 namenode 變為了 standby ,如果通過它提供的命令轉化為 active 會怎樣?失敗了唄,看英文解釋吧…
hdfs haadmin -transitionToActive master5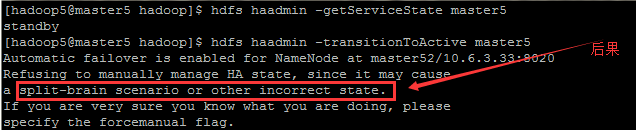
更多命令可以通過 help 檢視,更多詳細解釋請看 管理員命令
hdfs haadmin -help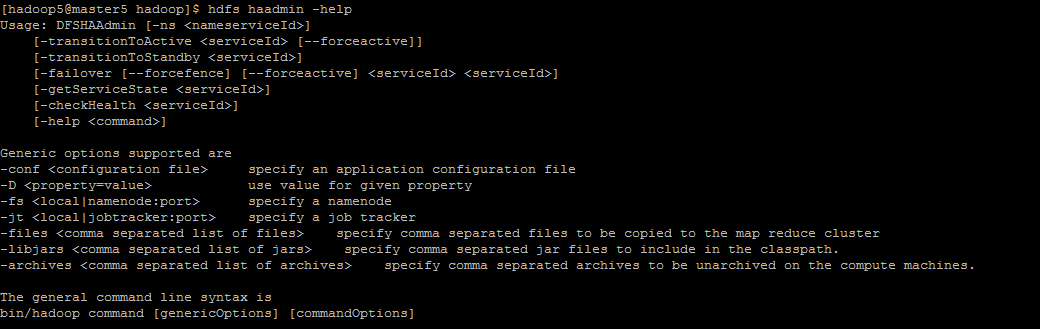
其中 checkHealth 檢查 NameNode1 的狀態。正常就返回 0,否則返回非 0 值。
hdfs haadmin -checkHealth NameNode1關鍵人家官網也說了,這個功能還沒有實現,現在將總是返回 success,除非給定的 NameNode 完全關閉。
2.3 HDFS HA自動切換比手工切換多出來的步驟
配置檔案 core-site.xml 增加了配置項
ha.zookeeper.quorum(zk叢集的配置)配置檔案 hdfs-site.xml 中把
dfs.ha.automatic-failover.enabled改為true操作上格式化 zk,執行命令
bin/hdfs zkfc -formatZK在兩個 NameNode 上啟動 zkfc,執行命令
sbin/hadoop-daemon.sh start zkfc
三. ResourceManager 的 HA 自動切換命令
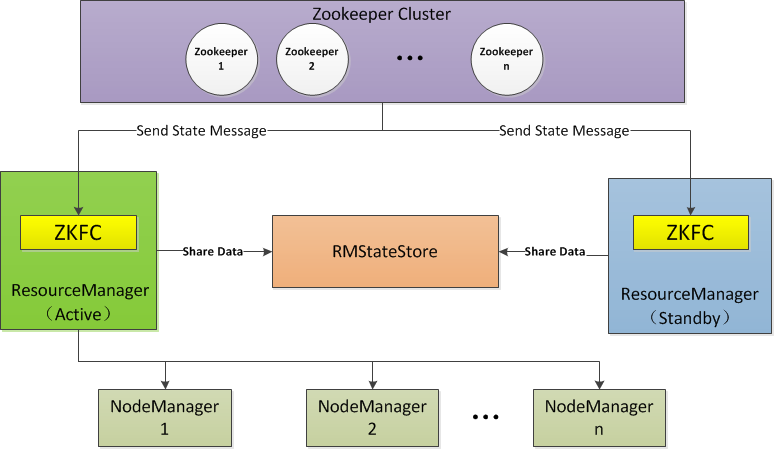
說明: 為了更加通俗的說明,筆者將兩臺執行 resourcemanager 程序的主機名抽象為 RM1 和 RM2,筆者更傾向 RM1 上的執行的是 active 狀態的 resourcemanager 程序,RM2 上的執行的是 standby 狀態的 resourcemanager 程序,而實際操作中,master5 就是這個 RM1 ,master52 就是這個 RM2。
| 抽象主機名 | 實際操作主機名 | 初始狀態 | 理想穩定狀態 | ha-id |
|---|---|---|---|---|
| RM1 | master5 | active | active | rm1 |
| RM2 | master52 | standby | standby | rm2 |
其中關於 ha-id 是在 yarn-site.xml 配置檔案中設定的。

hadoop也為管理員提供了 CLI 的方式管理 RM HA,但在沒有啟用 HA 的情況下,也就是在 yarn-site.xml 配置檔案中沒有設定 yarn.resourcemanager.ha.enabled 為 true 時 (預設為false,不啟用),下面的命令是不可用的。
3.1 獲得當前 RM 的 active 和 standby 狀態
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm23.2 RM 的 active 和 standby 狀態切換
根據叢集是否已經在 yarn-site.xml 中設定了 yarn.resourcemanager.ha.automatic-failover.enabled 為 true (即自動故障狀態切換)來分兩種情況
1. 未設定自動故障切換 (false)
yarn rmadmin -transitionToStandby rm1
yarn rmadmin -transitionToActive rm22. 設定自動故障切換 (true)
yarn rmadmin -transitionToStandby rm1
yarn rmadmin -transitionToActive rm2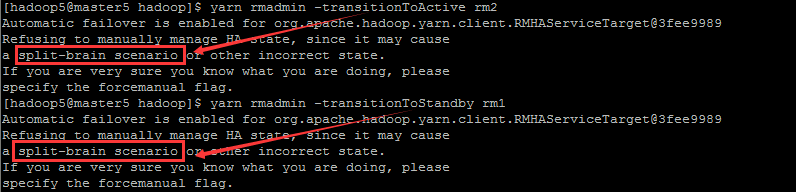
顯而易見,失敗了。如果需要手工切換,這時候可以
kill -9 <pid of RM>殺掉 active 狀態的 RM 的 resourcemanager 程序- 或關閉 active 狀態的 RM 的 resourcemanager 程序
yarn-daemon.sh stop resourcemanager然後再重啟 RM 的 resourcemanager 程序
yarn-daemon.sh start resourcemanager此時就可以成功切換狀態了…
3.3 yarn rmadmin 所支援的命令
更多命令可以通過 help 檢視
yarn rmadmin -help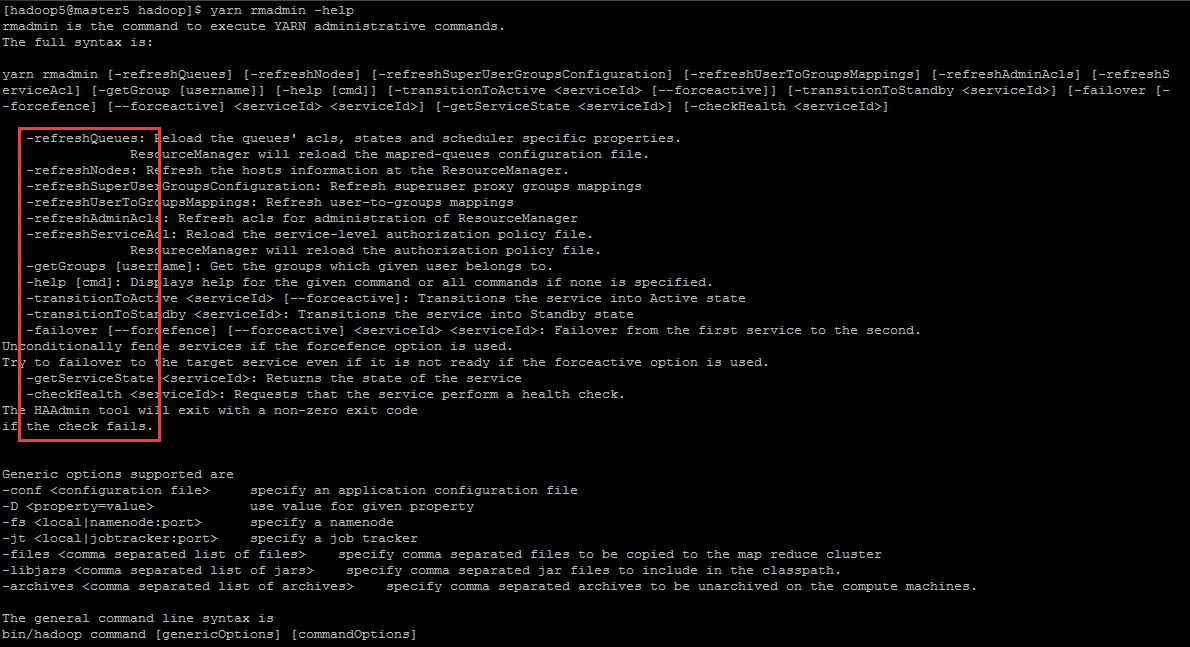
3.4 YARN HA自動切換比手工切換多出來的步驟
- 配置檔案 yarn-site.xml 中把
yarn.resourcemanager.ha.automatic-failover.enabled改為 true。該屬性的含義是:是否啟用自動故障轉移。預設情況下,在啟用 HA 時,啟用自動故障轉移 - 配置檔案 yarn-site.xml 中把
yarn.resourcemanager.ha.automatic-failover.embedded改為 true。啟用內建的自動故障轉移。預設情況下,在啟用 HA 時,啟用內建的自動故障轉移
四. HDFS HA 故障切換後欲恢復原 active NameNode 步驟
假設原本是 active NameNode 的 master5 的主機因為某種突發情況而失效了,此時之前處於 standby 的 master52 變為了 active 繼續承擔 namenode 的責任。 一段時間後, master5 恢復正常了,但只能是 standby 的狀態。這時若想將 master5 恢復成 active ,該如何做呢?以下是筆者自己總結的,準確性有待商榷…
在 Journal 和 QuorumPeerMain 程序正常啟動的情況下
- 將所有的 datanode 程序關閉,將 master5 上的 namenode 程序也關閉
- 在 master5 上執行
hdfs namenode -bootstrapStandby - 再將 master52 上重啟 namenode 程序, OK 了