
機器學習實戰:車牌識別系統
在本教程中,我將帶你使用Python來開發一個利用機器學習技術的車牌識別系統(License Plate Recognition)。
我們要做什麼?
車牌識別系統使用光學字元識別(OCR)技術來讀取車牌上的字元。 換句話說,車牌識別系統以車輛影象作為輸入並輸出車牌中的字元。 如果你是一個臥底或偵探,就能想象這會對你的工作有多寶貴了: 你可以利用車輛拍照來提取一輛汽車的幾乎所有必要資訊。
機器學習和車牌識別有什麼關係?
實際上,開發車牌識別系統不一定要使用機器學習技術。 例如,你也可以使用模板匹配、特徵提取等非機器學習專有的技術。 但是,機器學習使我們可以通過訓練來提高識別系統的準確性。 我們將使用機器學習來進行字元識別,即將字元的影象對映到其實際字元,例如A
B等。
這個教程適合我嗎?
如果你想用電影裡摩根·弗里曼的聲音來構建你自己的JARVIS,那就適合你。 好的,這太誇張了。 實際上,這個教程只是向你展示如何將影象處理和機器學習應用於解決現實生活中的問題。 你將會了解到Python、影象處理、機器學習的一些概念。 我會盡可能地解釋這些概念,你也可以進一步研究以更好地理解它們。 如果想馬上練習,我推薦你使用匯智網的python機器學習線上執行環境。
現在開始吧
LPR有時也被稱為自動車牌識別(ALPR),主要包括三個處理階段:
- 牌照檢測:這是第一個、可能也是最重要的階段。 這個階段的任務是確定車牌的位置,輸入是車輛影象,輸出是車牌區域的影象。
- 字元分割:這個階段的任務是將車牌區域影象上的字元分割成單獨的影象。
- 字元識別:這個階段的任務是將之前分割的字元影象識別為具體的字元。 在這個階段我們將使用機器學習。
理論夠多了,現在可以開始編碼了嗎?
當然,讓我們先準備下工作環境。 首先需要建立一個虛擬工作環境。 這可以簡化專案依賴和包的管理。 你可以使用virtualenv包建立一個虛擬環境:
# install virtualenv if you don’t have the package already
pip install virtualenv
mkdir license-plate-recognition
cd 現在,在你的專案目錄下,應該有一個名為lpr的檔案夾了。
然後我們來安裝第一個軟體包scikit-image 。 這是一個用於影象處理的Python包。 要安裝它,只需執行如下命令:
pip install scikit-image這個軟體包的關鍵依賴項包括:scipy (科學計算), numpy (多維陣列操作)和matplotlib (繪製圖形和顯示影象)。 另一個重要的軟體包是Pillow, 一個python影象庫。
車牌檢測(牌照定位)
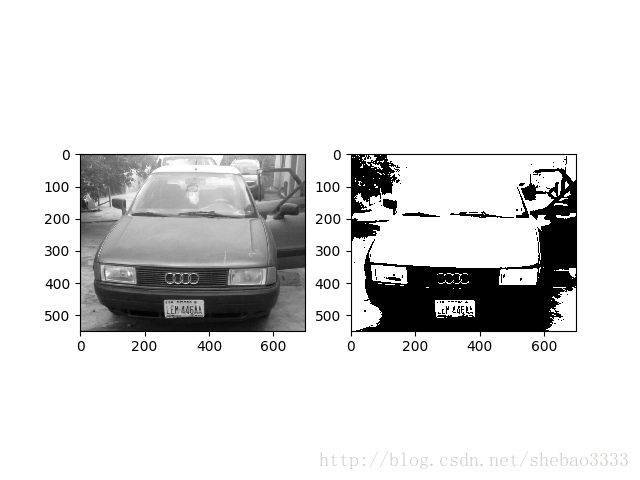
這是第一階段,目標是確定車輛影象中的車牌位置。 為了做到這一點,首先需要讀取影象檔案並將其轉換為灰度影象。 在灰度影象中,每個畫素的值都在0和255之間。然後,我們需要將其轉換為二值影象,即畫素值要麼黑要麼白,只有兩種可能的值。
執行下面的程式碼,將顯示兩個影象:一個灰度、一個黑白:
from skimage.io import imread
from skimage.filters import threshold_otsu
import matplotlib.pyplot as plt
car_image = imread("car.jpg", as_grey=True)
# it should be a 2 dimensional array
print(car_image.shape)
# the next line is not compulsory however, a grey scale pixel
# in skimage ranges between 0 & 1. multiplying it with 255
# will make it range between 0 & 255 (something we can relate better with
gray_car_image = car_image * 255
fig, (ax1, ax2) = plt.subplots(1, 2)
ax1.imshow(gray_car_image, cmap="gray")
threshold_value = threshold_otsu(gray_car_image)
binary_car_image = gray_car_image > threshold_value
ax2.imshow(binary_car_image, cmap="gray")
plt.show()執行結果:
我們使用連通分量分析 (Connected Component Analysis)演算法來識別影象中的所有連通區域。 你也可以嘗試其他方法如邊緣檢測和形態學處理。 CCA幫助我們對前景中的連通區域進行分組和標註。 如果兩個畫素具有相同的值並且彼此相鄰,則認為它們是連通的:
from skimage import measure
from skimage.measure import regionprops
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import localization
# this gets all the connected regions and groups them together
label_image = measure.label(localization.binary_car_image)
fig, (ax1) = plt.subplots(1)
ax1.imshow(localization.gray_car_image, cmap="gray");
# regionprops creates a list of properties of all the labelled regions
for region in regionprops(label_image):
if region.area < 50:
#if the region is so small then it's likely not a license plate
continue
# the bounding box coordinates
minRow, minCol, maxRow, maxCol = region.bbox
rectBorder = patches.Rectangle((minCol, minRow), maxCol-minCol, maxRow-minRow, edgecolor="red", linewidth=2, fill=False)
ax1.add_patch(rectBorder)
# let's draw a red rectangle over those regions
plt.show()我們需要匯入之前的檔案,以便訪問其中的值。 measure.label方法用於對映並標註二值影象中所有的連通區域。 在標註好的影象上呼叫regionprops方法將返回所有連通區域(及其屬性,如面積、邊界框、標籤等)的列表。我們使用patches.Rectangle方法在所有被對映的區域上繪製矩形。
從結果影象中,我們可以看到有一些不包含車牌的連通區域也被圈出來了。 為了消除這些區域,我們需要使用車牌的一些典型特徵來進行過濾:
- 車牌是矩形的。
- 車牌的寬度大於高度。
- 車牌區域的寬度與整個影象的比例在15%和40%之間。
- 車牌區域的高度與整個影象的比例在8%和20%之間。
如果這些特徵與你要處理的車牌不匹配,那你就調整這些特徵,不要猶豫,不要手軟!
程式碼如下:
from skimage import measure
from skimage.measure import regionprops
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import localization
# this gets all the connected regions and groups them together
label_image = measure.label(localization.binary_car_image)
# getting the maximum width, height and minimum width and height that a license plate can be
plate_dimensions = (0.08*label_image.shape[0], 0.2*label_image.shape[0], 0.15*label_image.shape[1], 0.4*label_image.shape[1])
min_height, max_height, min_width, max_width = plate_dimensions
plate_objects_cordinates = []
plate_like_objects = []
fig, (ax1) = plt.subplots(1)
ax1.imshow(localization.gray_car_image, cmap="gray");
# regionprops creates a list of properties of all the labelled regions
for region in regionprops(label_image):
if region.area < 50:
#if the region is so small then it's likely not a license plate
continue
# the bounding box coordinates
min_row, min_col, max_row, max_col = region.bbox
region_height = max_row - min_row
region_width = max_col - min_col
# ensuring that the region identified satisfies the condition of a typical license plate
if region_height >= min_height and region_height <= max_height and region_width >= min_width and region_width <= max_width and region_width > region_height:
plate_like_objects.append(localization.binary_car_image[min_row:max_row,
min_col:max_col])
plate_objects_cordinates.append((min_row, min_col,
max_row, max_col))
rectBorder = patches.Rectangle((min_col, min_row), max_col-min_col, max_row-min_row, edgecolor="red", linewidth=2, fill=False)
ax1.add_patch(rectBorder)
# let's draw a red rectangle over those regions
plt.show()在上述程式碼中,根據給出的車牌特徵剔除了那些不大可能是牌照的區域。 但是,依然還有一些區域(例如車頭燈等)的外觀與車牌完全一樣,也有可能被標記為車牌。 為了消除這些區域,我們需要進行垂直投影:即累加每一列的全部畫素。 由於車牌區域存在著字元影象,因此我們預期在車牌區域會得到很高的列畫素累加值。。
字元分割
在這個階段,我們將提取車牌上的所有字元影象。 我們繼續使用連通分量分析(CGA)。
import numpy as np
from skimage.transform import resize
from skimage import measure
from skimage.measure import regionprops
import matplotlib.patches as patches
import matplotlib.pyplot as plt
import cca2
# on the image I'm using, the headlamps were categorized as a license plate
# because their shapes were similar
# for now I'll just use the plate_like_objects[2] since I know that's the
# license plate. We'll fix this later
# The invert was done so as to convert the black pixel to white pixel and vice versa
license_plate = np.invert(cca2.plate_like_objects[2])
labelled_plate = measure.label(license_plate)
fig, ax1 = plt.subplots(1)
ax1.imshow(license_plate, cmap="gray")
# the next two lines is based on the assumptions that the width of
# a license plate should be between 5% and 15% of the license plate,
# and height should be between 35% and 60%
# this will eliminate some
character_dimensions = (0.35*license_plate.shape[0], 0.60*license_plate.shape[0], 0.05*license_plate.shape[1], 0.15*license_plate.shape[1])
min_height, max_height, min_width, max_width = character_dimensions
characters = []
counter=0
column_list = []
for regions in regionprops(labelled_plate):
y0, x0, y1, x1 = regions.bbox
region_height = y1 - y0
region_width = x1 - x0
if region_height > min_height and region_height < max_height and region_width > min_width and region_width < max_width:
roi = license_plate[y0:y1, x0:x1]
# draw a red bordered rectangle over the character.
rect_border = patches.Rectangle((x0, y0), x1 - x0, y1 - y0, edgecolor="red", linewidth=2, fill=False)
ax1.add_patch(rect_border)
# resize the characters to 20X20 and then append each character into the characters list
resized_char = resize(roi, (20, 20))
characters.append(resized_char)
# this is just to keep track of the arrangement of the characters
column_list.append(x0)
plt.show()列表 plate_like_objects中存有車輛影象中所有的候選車牌區域。 在我使用的示例影象中,有三個區域被選中為車牌的候選區域。 在這個教程中,為了節省時間,我手工指定了第二個區域(真正包含車牌的區域)。 在下面分享的最終程式碼中會包含一個牌照區域的驗證功能,可以自動剔除那些實際上不包含車牌的區域。
接下來我們在牌照上做一個連通分量分析,將每個字元的大小調整為20px,20px。 這是因為字元的大小與下一個階段的識別有關。
為了跟蹤牌照中字元的順序,引入了column_list變數來記錄每個字元區域的x軸起始座標。 這樣就可以通過排序來確定多個字元間的先後順序了。
字元識別
這是車牌識別的最後一個階段,我們首先介紹下機器學習。 機器學習可以簡單地定義為人工智慧(AI)的一個發展分支,它對資料進行處理以期從資料中發現可用於預測的模式。 機器學習可以分為監督學習、無監督學習和強化學習。 監督學習使用標註過的資料集(稱為訓練資料集)進行預測。 我們將採用監督學習,因為我們已經知道A、B等字母的樣子。 監督學習又可以分為兩類: 分類和迴歸。 字元識別則屬於分類。
我們現在需要做的:
- 獲取訓練資料集
- 選擇監督學習分類器
- 訓練模型
- 測試模型的準確率
- 使用模型進行預測。
讓我們開始訓練模型吧。 我有兩個不同的資料集 ,一個是10px,20px,另一個是20px,20px。 我們將使用20px,20px的資料集,因為之前已經按這個大小調整過每個字元。 除O和I(由於它們分別與0和1相似,因此奈及利亞牌照中不使用這些字母)以外的每個字母都有10個不同的影象。
你可以嘗試不同的分類器 ,每種分類器都有其優點和缺點。 在這個任務中,我們將使用支援向量分類器(SVC)。 之所以選擇SVC,是因為它在這個任務中的的效能表現最好。 但是,這並不是說SVC是最好的分類器。
我們需要首先安裝scikit-learn軟體包:
pip install scikit-learn這部分的程式碼如下:
import os
import numpy as np
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.externals import joblib
from skimage.io import imread
from skimage.filters import threshold_otsu
letters = [
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D',
'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z'
]
def read_training_data(training_directory):
image_data = []
target_data = []
for each_letter in letters:
for each in range(10):
image_path = os.path.join(training_directory, each_letter, each_letter + '_' + str(each) + '.jpg')
# read each image of each character
img_details = imread(image_path, as_grey=True)
# converts each character image to binary image
binary_image = img_details < threshold_otsu(img_details)
# the 2D array of each image is flattened because the machine learning
# classifier requires that each sample is a 1D array
# therefore the 20*20 image becomes 1*400
# in machine learning terms that's 400 features with each pixel
# representing a feature
flat_bin_image = binary_image.reshape(-1)
image_data.append(flat_bin_image)
target_data.append(each_letter)
return (np.array(image_data), np.array(target_data))
def cross_validation(model, num_of_fold, train_data, train_label):
# this uses the concept of cross validation to measure the accuracy
# of a model, the num_of_fold determines the type of validation
# e.g if num_of_fold is 4, then we are performing a 4-fold cross validation
# it will divide the dataset into 4 and use 1/4 of it for testing
# and the remaining 3/4 for the training
accuracy_result = cross_val_score(model, train_data, train_label,
cv=num_of_fold)
print("Cross Validation Result for ", str(num_of_fold), " -fold")
print(accuracy_result * 100)
current_dir = os.path.dirname(os.path.realpath(__file__))
training_dataset_dir = os.path.join(current_dir, 'train')
image_data, target_data = read_training_data(training_dataset_dir)
# the kernel can be 'linear', 'poly' or 'rbf'
# the probability was set to True so as to show
# how sure the model is of it's prediction
svc_model = SVC(kernel='linear', probability=True)
cross_validation(svc_model, 4, image_data, target_data)
# let's train the model with all the input data
svc_model.fit(image_data, target_data)
# we will use the joblib module to persist the model
# into files. This means that the next time we need to
# predict, we don't need to train the model again
save_directory = os.path.join(current_dir, 'models/svc/')
if not os.path.exists(save_directory):
os.makedirs(save_directory)
joblib.dump(svc_model, save_directory+'/svc.pkl')在上面的程式碼中,使用訓練資料集中的每個字元來訓練svc模型。 我們通過4折交叉驗證來確定模型的精確度,然後將模型儲存到模型檔案中,以便後續進行預測。
現在我們有了一個訓練好的模型,可以試著來預測一下我們之前分割出的字元影象:
import os
import segmentation
from sklearn.externals import joblib
# load the model
current_dir = os.path.dirname(os.path.realpath(__file__))
model_dir = os.path.join(current_dir, 'models/svc/svc.pkl')
model = joblib.load(model_dir)
classification_result = []
for each_character in segmentation.characters:
# converts it to a 1D array
each_character = each_character.reshape(1, -1);
result = model.predict(each_character)
classification_result.append(result)
print(classification_result)
plate_string = ''
for eachPredict in classification_result:
plate_string += eachPredict[0]
print(plate_string)
# it's possible the characters are wrongly arranged
# since that's a possibility, the column_list will be
# used to sort the letters in the right order
column_list_copy = segmentation.column_list[:]
segmentation.column_list.sort()
rightplate_string = ''
for each in segmentation.column_list:
rightplate_string += plate_string[column_list_copy.index(each)]
print(rightplate_string)注意
讓這個系統正常工作最重要的一點,是儘量保證輸入的車輛影象清晰。 此外,影象不要太大,600px寬就夠了。
如果你喜歡這篇文章,記得關注我:新缸中之腦!
完整的程式碼請訪問這裡。