
Pandas庫之DataFrame
1 簡介
DataFrame是Python中Pandas庫中的一種資料結構,它類似excel,是一種二維表。
或許說它可能有點像matlab的矩陣,但是matlab的矩陣只能放數值型值(當然matlab也可以用cell存放多型別資料),DataFrame的單元格可以存放數值、字串等,這和excel表很像。
同時DataFrame可以設定列名columns與行名index,可以通過像matlab一樣通過位置獲取資料也可以通過列名和行名定位,具體方法在後面細說。
2 建立DataFrame
首先宣告一下,以下都是使用的Python 3.6.5版本為例,Python2應該也差不多吧(大概
在所有操作之前當然要先import必要的pandas庫,因為pandas常與numpy一起配合使用,所以也一起import吧。
import pandas as pd
import numpy as np如果還沒安裝直接在cmd裡pip安裝吧,如果有版本選擇問題,參看之前的帖子。
pip install pandas
pip install numpy2.1 直接建立
可以直接使用pandas的DataFrame函式建立,比如接下來我們隨機建立一個4*4的DataFrame。
df1=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD'))
其中第一個引數是存放在DataFrame裡的資料,第二個引數index就是之前說的行名(或者應該叫索引?),第三個引數columns是之前說的列名。
後兩個引數可以使用list輸入,但是注意,這個list的長度要和DataFrame的大小匹配,不然會報錯。當然,這兩個引數是可選的,你可以選擇不設定。
而且發現,這兩個list是可以一樣的,但是每行每列的名字在index或columns裡要是唯一的。
使用python自己的shell展示建立的結果是這樣的:

或者在jupyter裡面更酷點的樣子,接下來都使用jupyter輸出展示吧。
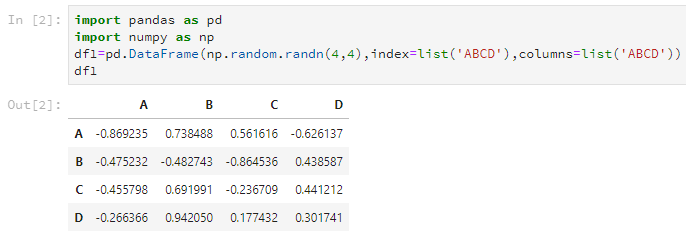
當然,如果你的資料量賊小,也可以自己輸入建立,類似這樣。
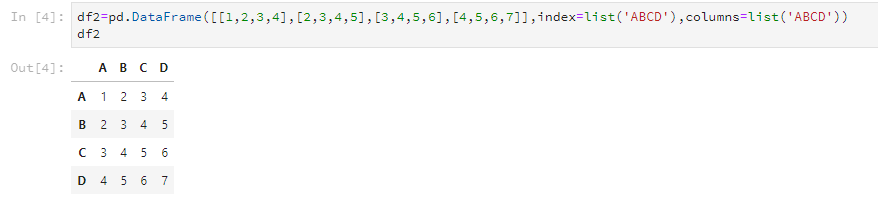
df2=pd.DataFrame([[1,2,3,4],[2,3,4,5],
[3,4,5,6],[4,5,6,7]],
index=list('ABCD'),columns=list('ABCD'))這樣也可以得到這樣子的DataFrame:
2.2 使用字典建立
仍然是使用DataFrame這個函式,但是字典的每個key的value代表一列,而key是這一列的列名。比如這樣。
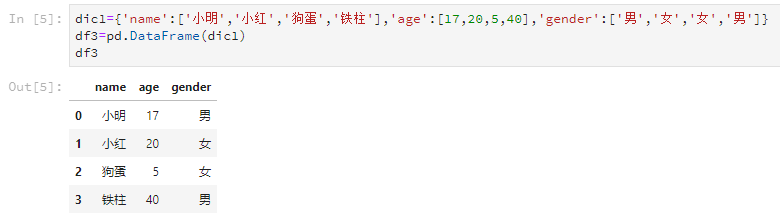
dic1={'name':['小明','小紅','狗蛋','鐵柱'],'age':[17,20,5,40],'gender':['男','女','女','男']}
df3=pd.DataFrame(dic1)輸出結果是這樣的
3 檢視與篩選資料
python沒有matlab的工作區直接檢視變數與內容,這大概是python科學計算的一個缺點。所以需要格外的程式碼來檢視,最基本的直接寫變數名與print就不說了。
3.1 檢視列的資料型別
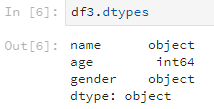
使用dtypes方法可以檢視各列的資料型別,比如說剛剛的df3。
df3.dtypes輸出的結果是這樣:
3.2 檢視DataFrame的頭尾
使用head可以檢視前幾行的資料,預設的是前5行,不過也可以自己設定。
使用tail可以檢視後幾行的資料,預設也是5行,引數可以自己設定。
比如隨意設定一個6*6的資料,只看前5行。
df4=pd.DataFrame(np.random.randn(6,6))
df4.head()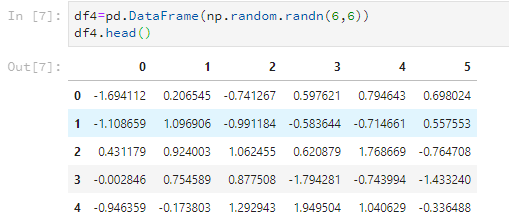
比如只看前3行。
df4.head(3)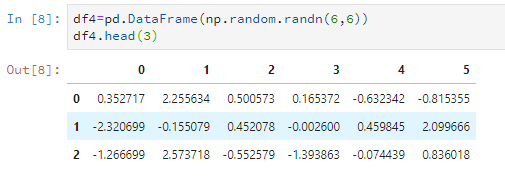
比如看後5行。
df4.tail()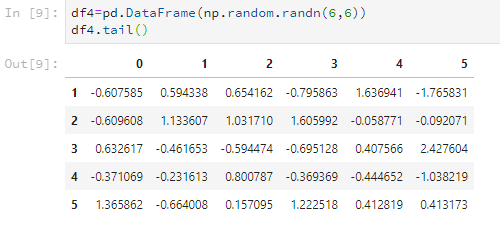
比如只看後2行。
df4.tail(2)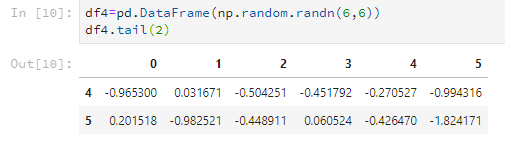
3.3 檢視行名與列名
使用index檢視行名,columns檢視列名。具體由例子感受吧。
檢視行名。
df1.index
檢視列名。
df3.columns
3.4 檢視資料值
使用values可以檢視DataFrame裡的資料值,返回的是一個數組。
比如說檢視所有的資料值。
df3.values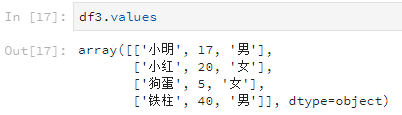
比如說檢視某一列所有的資料值。
df3['name'].values
還有另一種操作,使用loc或者iloc檢視資料值(但是好像只能根據行來檢視?)。區別是loc是根據行名,iloc是根據數字索引(也就是行號)。
比如說這樣。
df1.loc['A']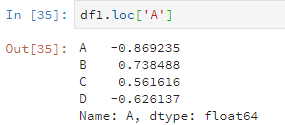
或者這樣。
df1.iloc[0]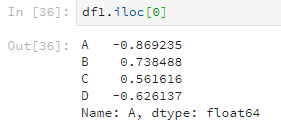
按列進行索引檢視資料還能直接使用列名,但這種方法對行索引不適用。
df3['name']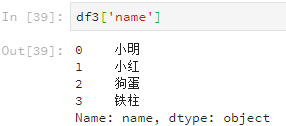
3.5 檢視行列數
使用shape檢視行列數,引數為0表示檢視行數,引數為1表示檢視列數。
df3.shape[0]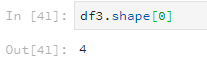
df3.shape[1]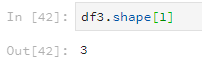
4 基本操作
DataFrame有些方法可以直接進行資料統計,矩陣計算之類的基本操作。
4.1 轉置
直接字母T,線性代數上線。
比如說把之前的df2轉置一下。
df3.T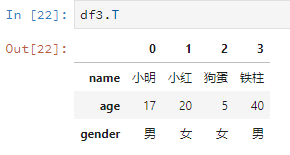
4.2 描述性統計
使用describe可以對資料根據列進行描述性統計。
比如說對df1進行描述性統計。
df1.describe()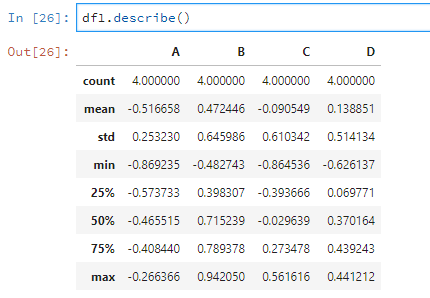
如果有的列是非數值型的,那麼就不會進行統計。
如果想對行進行描述性統計,請參看4.1(轉置後進行describe呀!)
4.3 計算
使用sum預設對每列求和,sum(1)為對每行求和。比如
df3.sum()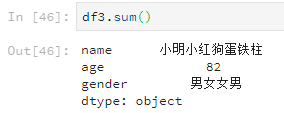
可以發現就算元素是字串,使用sum也會加起來。
df3.sum(1)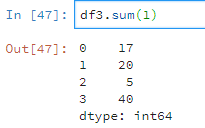
而一行中,有字串有數值則只計算數值。
數乘運算使用apply,比如。
df2.apply(lambda x:x*2)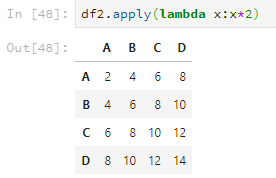
如果元素是字串,則會把字串再重複一遍。
乘方運算跟matlab類似,直接使用兩個*,比如。
df2**2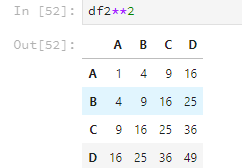
乘方運算如果有元素是字串的話,就會報錯。
4.4 新增
擴充列可以直接像字典一樣,列名對應一個list,但是注意list的長度要跟index的長度一致。
df2['E']=['999','999','999','999']
df2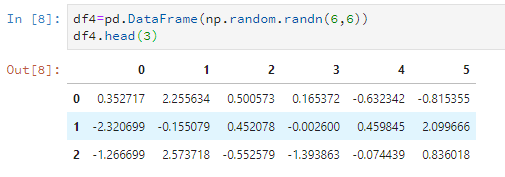
還可以使用insert,使用這個方法可以指定把列插入到第幾列,其他的列順延。
df2.insert(0,'F',[888,888,888,888])
df2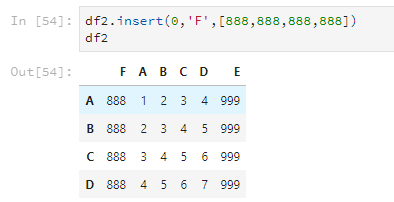
4.5 合併
使用join可以將兩個DataFrame合併,但只根據行列名合併,並且以作用的那個DataFrame的為基準。如下所示,新的df7是以df2的行號index為基準的。
df6=pd.DataFrame(['my','name','is','a'],index=list('ACDH'),columns=list('G'))
df6
df7=df2.join(df6)
df7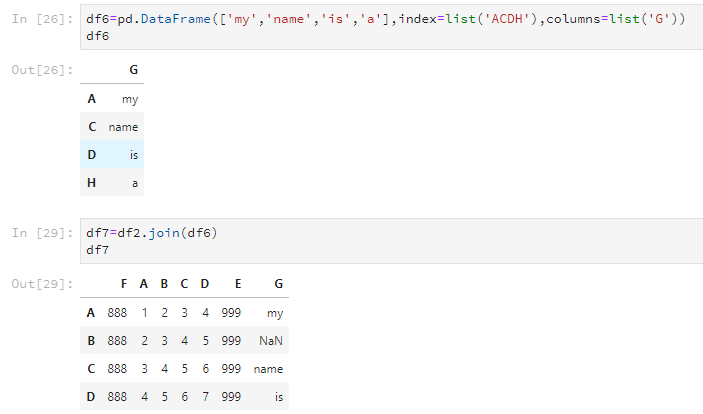
但是,join這個方法還有how這個引數可以設定,合併兩個DataFrame的交集或並集。引數為'inner'表示交集,'outer'表示並集。
df8=df2.join(df6,how='inner')
df8
df9=df2.join(df6,how='outer')
df9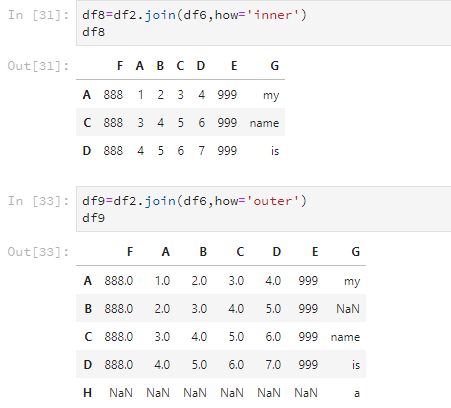
如果要合併多個Dataframe,可以用list把幾個Dataframe裝起來,然後使用concat轉化為一個新的Dataframe。
df10=pd.DataFrame([1,2,3,4],index=list('ABCD'),columns=['a'])
df11=pd.DataFrame([10,20,30,40],index=list('ABCD'),columns=['b'])
df12=pd.DataFrame([100,200,300,400],index=list('ABCD'),columns=['c'])
list1=[df10.T, df11.T, df12.T]
df13=pd.concat(list1)
df13
相關推薦
pandas庫之DataFrame基本操作
轉自:http://www.jianshu.com/p/75f915cc5147 這一部分主要學習pandas中Series和DataFrame基本操作。
【Python學習筆記】Pandas庫之DataFrame
數字 .sh image sum() 新增 選擇 輸出 上線 工作區 1 簡介 DataFrame是Python中Pandas庫中的一種數據結構,它類似excel,是一種二維表。 或許說它可能有點像matlab的矩陣,但是matlab的矩陣只能放數值型值(當然ma
Pandas庫之DataFrame
1 簡介 DataFrame是Python中Pandas庫中的一種資料結構,它
Python資料分析Pandas庫之熊貓(10分鐘二)
pandas 10分鐘教程(二) 重點發法 分組 groupby('列名') groupby(['列名1','列名2',.........]) 分組的步驟 (Splitting) 按照一些規則將資料分為不同的組,拆分 (Applying) 對於每組資料分別
python中pandas庫中DataFrame對行和列的操作使用方法
用pandas中的DataFrame時選取行或列:import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data =
pandas系列之 DataFrame 行列資料篩選
一、對DataFrame的認知 DataFrame的本質是行(index)列(column)索引+多列資料。 為了簡化理解,我們不妨換個思路… 現實中,為了簡化對一件事物的描述,我們會選擇幾個特徵。 例如,從(性別、身高、學歷、職業、愛好..)等角度去刻
pandas庫介紹之DataFrame基本操作
讀取excel 操作 pyplot 分組 寫入 pos ner 結構 此外 怎樣刪除list中空字符? 最簡單的方法:new_list = [ x for x in li if x != ‘‘ ] 今天是5.1號。 這一部分主要學習pandas中基於前面兩種數據結構的基
Python 數值計算庫之-[Pandas](六)
9.png blank das png ref log 3-9 alt ges Python 數值計算庫之-[Pandas](六)
Pandas庫DataFrame的排序
index font images .com imp afr mar 降序排序 Coding df1為dataframe結構的測試數據:df1數據是從test.xlsx文檔中讀取的,使用示例代碼如下:# -*- coding:utf-8 -*- import tushar
python之pandas庫
numpy 混合 column query 大於 ace col outer 相關性 一、生成數據表 1、首先導入pandas庫,一般都會用到numpy庫,所以我們先導入備用: import pandas as pd 2、導入CSV或者xlsx文件: df = pd.Dat
pandas資料結構之Dataframe
Dataframe DataFrame是一個【表格型】的資料結構,可以看做是【由Series組成的字典】(多個series共用同一個索引)。DataFrame由按一定順序排列的多列資料組成。設計初衷是將Series的使用場景從一維拓展到多維。DataFrame既有行索引,也有列索引。 行索引:ind
機器學習之Pandas庫
1.1 pandas庫總體說明 Pandas基於NumPy、SciPy補充的大量資料操作功能,能實現統計、分組、排序、透視表,可以代替Excel的絕大部分功能 Pandas主要有2種重要資料結構:Series、DataFrame(一維序列,二維表)。資料型別的轉換需要用到pd.Series/
pandas之DataFrame資料框
DataFrame資料框 1.建立資料框 df = DataFrame({ 'age':[21,22,23], 'name':['zhangYafei','LiuGeliang','KangYue'] },index=['fir
pandas之DataFrame繪圖
我們知道Pandas庫中有兩種資料結構一種是Series結構型別的資料,還有一個種就是DataFrame型別的資料,那麼今天我們就來聊一聊DataFrame結構型別的資料繪圖。 我們先來看一個最簡單的例子。試試我們的小心臟會不會跳動,哈哈。直接上乾貨,程式碼如下: 如果您對DataFra
python pandas 之 Dataframe 資料結構
DataFrame 是 pandas 中兩個主要資料結構之一,另一個是 Series。DataFrame 的文件在這裡:傳送門。 因為這幾天需要使用這個資料結構來完成一個小作業,在這裡總結一下 Dataframe 的一些基本用法。 文章目錄 建立
Pandas詳解十八之DataFrame物件的-Join合併
約定: import pandas as pd 物件的例項方法-Join DataFrame物件有個df.join()方法也能進行pd.merge()的合併,它能更加方便地按照物件df的索引進行合併,且能同時合併多個DataFr
pandas之DataFrame常用方法
1 簡介 DataFrame是Python中Pandas庫中的一種資料結構,它類似excel,是一種二維表。 或許說它可能有點像matlab的矩陣,但是matlab的矩陣只能放數值型值(當然matlab也可以用cell存放多型別資料),DataFrame的單元格可以存放數值、字串等,這和ex
Python:pandas之DataFrame常用操作
定義一個df: dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) p
pandas學習筆記之Dataframe索引
# DataFra是一個表格, 有行索引和列索引,可以被看做由Series組成的字典(共用一個索引) import numpy as np import pandas as pd df = pd.DataFrame(np.random.rand(12
在pandas中, DataFrame的 ix(loc, iloc)屬性的設定誤區,以及reindex可以找到兩個df不同之處
1.ix[ ]如果想用.ix選取df中某一行某一列的值時,返回的結果是什麼?data = DataFrame([{'t':'2018-01-08 14:12:26', 'name':'yang'},{'t':'2017-01-08 14:12:26', 'name':'jia