
AutoML資料增廣
DeepAugment是一個專注於資料擴充的自動化工具。 它利用貝葉斯優化來發現針對您的影象資料集定製的資料增強策略。 DeepAugment的主要優點和特點是:
- 降低CNN模型的錯誤率(WRN-28-10顯示CIFAR10的錯誤率降低了60%)
- 通過自動化流程可以節省時間
- 比谷歌之前的解決方案——AutoAugment——快50倍
完成的包在PyPI上。你可以通過執行以下命令來在終端上安裝它:
$ pip install deepaugment你也可以訪問專案的自述檔案或執行谷歌Colab筆記本教程。要想了解更多關於我是如何構建這個的,請繼續閱讀!
引言
資料是人工智慧應用中最關鍵的部分。沒有足夠的標記資料常常導致過度擬合,這意味著模型將無法歸納為未發現的示例。這可以通過資料擴充來緩解,資料擴充可以有效地增加網路所看到的資料的數量和多樣性。它是通過對原始資料集(如旋轉、裁剪、遮擋等)應用轉換,人為地生成新資料來實現的。然而,確定哪種增強對手頭的資料集最有效並不是一項簡單的任務。為了解決這個問題,谷歌去年釋出了
由於強化學習模組的存在,使用谷歌的AutoAugment需要強大的計算資源。由於獲得所需的計算能力代價高昂,因此我開發了一種新的方法——DeepAugment,它使用貝葉斯優化而不是強化學習。
如何獲得更好的資料
努力改進資料質量通常比努力改進模型獲得更高的投資回報。改進資料有三種主要方法:收集更多的資料、合成新資料或擴充套件現有資料。收集額外的資料並不總是可行的,而且可能很昂貴。GANs所做的資料合成是很有前途的,但也很複雜,可能與實際的例子有所不同。

另一方面,資料擴充簡單且影響很大。它適用於大多數資料集,並通過簡單的影象轉換完成。然而,問題是確定哪種增強技術最適合當前的資料集。發現正確的方法需要耗時的實驗。即使經過多次實驗,機器學習(ML)工程師仍然可能找不到最佳選擇。
對於每個影象資料集,有效的增強策略是不同的,一些增強技術甚至可能對模型有害。例如,如果使用
DeepAugment:閃電般迅速的autoML
DeepAugment旨在作為一種快速靈活的autoML資料擴充解決方案。更具體地說,它被設計為AutoAugment的更快和更靈活的替代品。(2018年Cubuk等人的部落格)AutoAugment是2018年最令人興奮的釋出之一,也是第一種使用強化學習來解決這一特定問題的方法。在本文發表時,AutoAugment的開源版本
deepaugmented通過以下設計目標來解決這些問題:
1.在保證結果質量的前提下,最小化資料擴充優化的計算複雜度。
2.模組化和人性化。
為了實現第一個目標,與AutoAugment相比,DeepAugment的設計具有以下差異:
- 使用貝葉斯優化代替強化學習(需要更少的迭代)(~100x加速)
- 最小化子模型大小(降低每次訓練的計算複雜度)(~20x加速)
- 減少隨機擴充搜尋空間設計(減少所需的迭代次數)
為了實現第二個目標,即使DeepAugment模組化和人性化,使用者介面的設計方式為使用者提供了廣泛的可能性配置和模型選擇(例如,選擇子模型或輸入自設計的子模型,請參閱配置選項)。
設計擴充策略
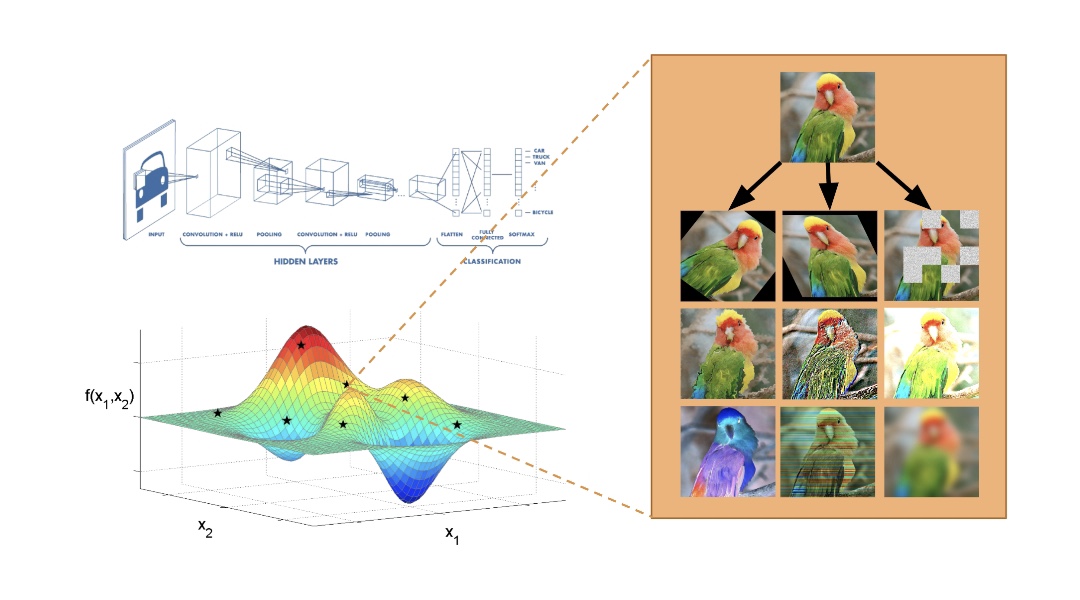
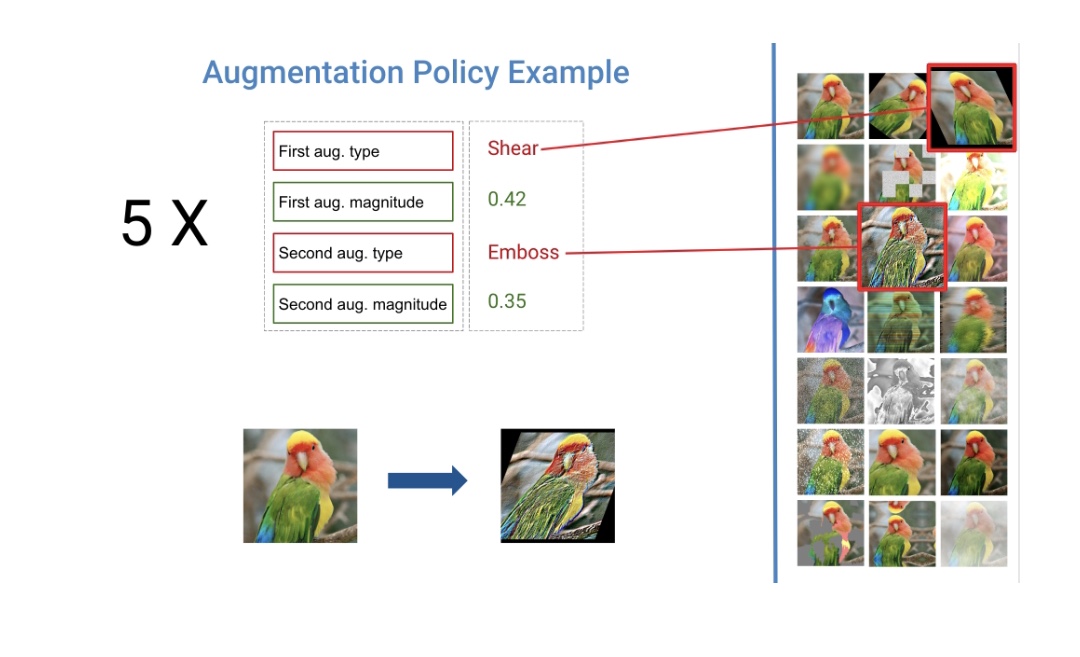
DeepAugment旨在為給定的影象資料集找到最佳的擴充策略。增強策略被定義為五個子策略的總和,這兩個子策略由兩種型別的增強技術和兩個實值[0,1]組成,決定了每種增強技術的應用能力。我使用imgaug包實現了增強技術,imgaug包以其大量的增強技術(見下文)而聞名。

當多樣化和隨機應用時,增強是最有效的。例如,與其旋轉每個影象,不如旋轉影象的某些部分,剪下另一部分,然後對另一部分應用顏色反轉。基於這一觀察,Deepaugment對影象隨機應用五個子策略之一(包括兩個增強)。優化過程中,每個影象被五個子策略之一增強的概率(16%)相等,而完全不被增強的概率為20%。
雖然這個策略設計受到了autoaugmented的啟發,但有一個主要的區別:我沒有使用任何引數來應用子策略的概率,以便使策略的隨機性更低,並允許在更少的迭代中進行優化。
這個策略設計為貝葉斯優化器建立了一個20維的搜尋空間,其中10個維度是分類(增強技術的型別),其他10個維度是實值(大小)。由於涉及到分類值,我將貝葉斯優化器配置為使用隨機森林估計器。
DeepAugment如何找到最佳策略
DeepAugment的三個主要元件是控制器(貝葉斯優化器),增強器和子模型,整個工作流程如下:控制器取樣新的增強策略,增強器按新策略轉換影象,子模型是通過增強影象從頭開始訓練。
根據子模型的訓練歷史計算獎勵。獎勵返回給控制器,控制器使用此獎勵和相關的增強策略更新代理模型(請參閱下面的“貝葉斯優化如何工作”一節)。然後控制器再次取樣新策略,並重復相同的步驟。此過程迴圈,直到達到使用者確定的最大迭代次數。
控制器(貝葉斯優化器)是使用scikit- optimization庫的ask-and-tell方法實現的。它被配置為使用一個隨機森林估計器作為其基本估計器,並期望改進作為其獲取函式。
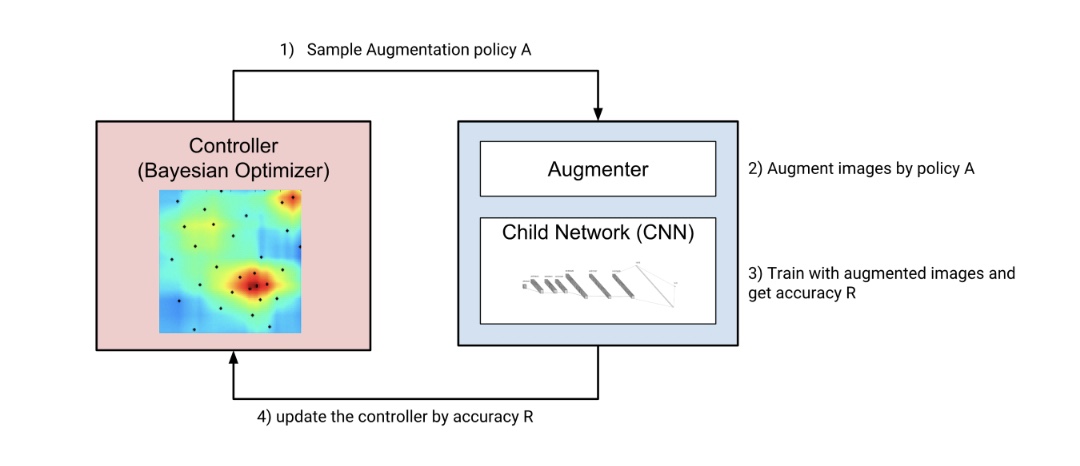
DeepAugment的基本工作流程
貝葉斯優化是如何工作的
貝葉斯優化的目的是找到一組最大化目標函式值的引數。 貝葉斯優化的工作迴圈可以概括為:
1.建立目標函式的代理模型
2.查詢代理上執行得最好的引數
3.使用這些引數執行目標函式
4.使用這些引數和目標函式的得分更新代理模型
5.重複步驟2-4,直到達到最大迭代次數
有關貝葉斯優化的更多資訊,請閱讀高階的這篇解釋的部落格,或者看一下這篇綜述文章。
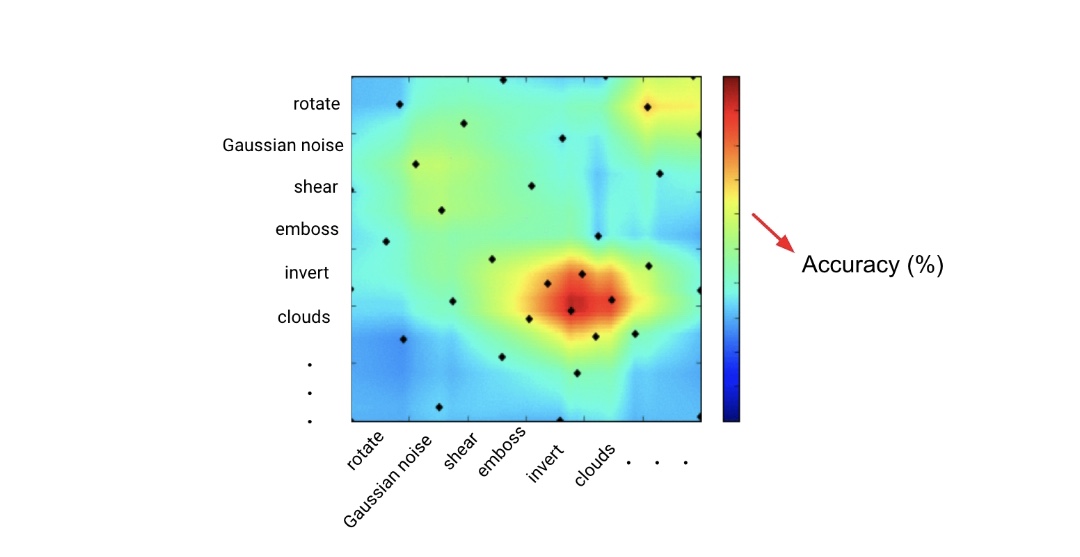
貝葉斯優化的二維描述,其中x和y軸表示增強型別,點(i,j)處的顏色表示用增強i和j所增強的資料進行訓練時CNN模型的精度。
貝葉斯優化的權衡
目前用於超引數優化的標準方法有隨機搜尋、網格搜尋、貝葉斯優化、進化演算法和強化學習,按方法複雜度排序。在超引數優化的精度、成本和計算時間方面,貝葉斯優化優於網格搜尋和隨機搜尋(參見這裡的經驗比較)。這是因為貝葉斯優化從先前引數的執行中學習,與網格搜尋和隨機搜尋相反。
當貝葉斯優化與強化學習和進化演算法進行比較時,它提供了具有競爭力的準確性,同時需要更少的迭代。例如,為了學習好的策略,谷歌的AutoAugment迭代15,000次(這意味著訓練子CNN模型15,000次)。另一方面,貝葉斯優化在100-300次迭代中學習良好的策略。貝葉斯優化的經驗法則是使迭代次數等於優化引數的次數乘以10。

超引數優化方法的直觀比較。通過比較類別,加號(+)的數量表示該方法有多好。
挑戰及對策
挑戰1:優化增強需要大量的計算資源,因為子模型應該從頭開始反覆訓練。大大減慢了我的工具的開發過程。 儘管使用貝葉斯優化使其更快,但優化過程仍然不夠快,無法使開發變得可行。
對策:我開發了兩種解決方案。首先,我優化了子CNN模型(見下圖),這是該過程的計算瓶頸。其次,我以更確定的方式設計了增強策略,使貝葉斯優化器需要更少的迭代。

設計子CNN模型。它在AWS p3.2x大型例項(帶有112 TensorFLOPS的Tesla V100 GPU)上以32x32影象在約30秒(120個週期)的時間內完成培訓。
挑戰2:我在DeepAugment的開發過程中遇到了一個有趣的問題。在通過一遍又一遍地訓練子模型來優化增強期間,它們開始過度擬合驗證集。當我更改驗證集時,我發現的最佳策略表現不佳。這是一個有趣的例子,因為它不同於一般意義上的過度擬合,即模型權重過度擬合數據中的噪聲。
對策:我沒有使用相同的驗證集,而是將剩餘的資料和訓練資料保留為“種子驗證集”,並在每次子CNN模型訓練時對1000個影象的驗證集進行取樣(參見下面的資料管道)。這解決了增強過度擬合問題。
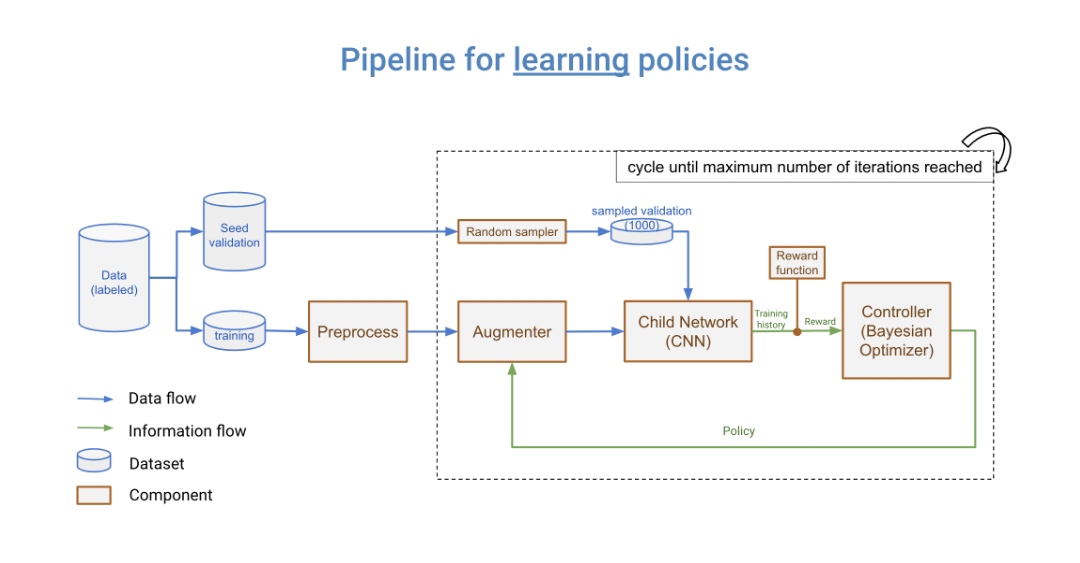
如何整合到ML pipeline中
DeepAugment釋出在PyPI上。你可以通過執行以下命令來在終端安裝它:
$ pip install deepaugment並且使用方便:
from deepaugment.deepaugment import DeepAugment
deepaug = DeepAugment(my_images, my_labels)
best_policies = deepaug.optimize()通過配置DeepAugment,可以獲得更高階的用法:
from keras.datasets import cifar10
# my configuration
my_config = {
"model": "basiccnn",
"method": "bayesian_optimization",
"train_set_size": 2000,
"opt_samples": 3,
"opt_last_n_epochs": 3,
"opt_initial_points": 10,
"child_epochs": 50,
"child_first_train_epochs": 0,
"child_batch_size": 64
}
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# X_train.shape -> (N, M, M, 3)
# y_train.shape -> (N)
deepaug = DeepAugment(x_train, y_train, config=my_config)
best_policies = deepaug.optimize(300)有關更詳細的安裝/使用資訊,請訪問專案的自述檔案或執行Google Colab筆記本教程。
結論
據我們所知,DeepAugment是第一種利用貝葉斯優化來尋找最佳資料增強的方法。 資料增強的優化是最近的一個研究領域,AutoAugment是解決這一問題的首批方法之一。
Deepaugment對開源社群的主要貢獻在於它使程序具有可擴充套件性,允許使用者在不需要大量計算資源的情況下優化擴充策略*。它是非常模組化的,比以前的解決方案AutoAugment快50倍以上。
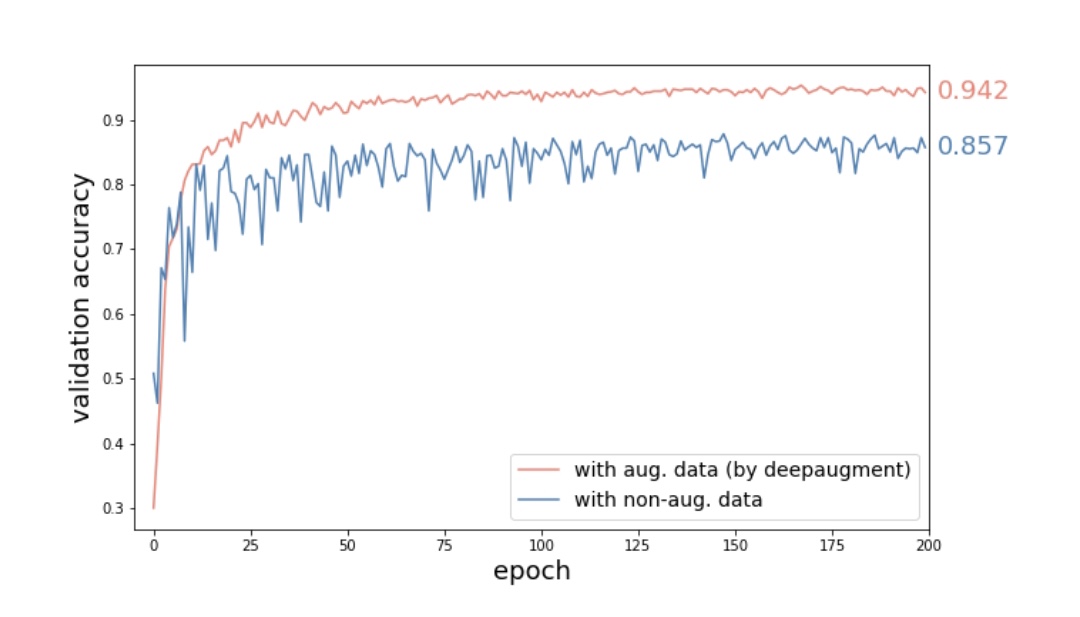
WideResNet-28-10 CNN模型與CIFAR10影象在被Deepaugment發現的策略增強和不增強時的驗證精度比較驗證精度提高8.5%,相當於減少了60%的誤差。
結果表明,使用CIFAR-10小影象資料集的WideResNet-28-10模型與不使用增強的模型和資料集相比,Deepaugment可以減少60%的誤差。
Deepaugment目前只優化影象分類任務的增強。它可以擴充套件到優化物件檢測或分割任務,如果你願意,我歡迎你的貢獻。但是,我認為最好的增強策略非常依賴於資料集的型別,而不是任務(例如分類或物件檢測)。這意味著無論任務是什麼,AutoAugment都應該找到類似的策略,但如果這些策略最終變得非常不同,那將是非常有趣的!
雖然DeepAugment目前適用於影象資料集,但將其擴充套件到文字、音訊或視訊資料集將非常有趣。同樣的概念也適用於其他型別的資料集。
*使用AWS P3.X2Large例項,DeepAugment在CIFAR-10資料集上花費4.2小時(500次迭代),成本約為13美元。
感謝
我在Insight人工智慧研究員計劃期間的三個星期內完成了這個專案。我感謝程式總監Matt Rubashkin和Amber Roberts的非常有用的指導,感謝我的技術顧問Melissa Runfeldt幫助我解決問題。我感謝Amber Roberts,Emmanuel Ameisen,Holly Szafarek和Andrew Forrester在這篇部落格文章中提出的建議和編輯工作。
想要提升你在資料科學和人工智慧領域的職業生涯?申請SV和NYC的截止日期是4月1日!在Insight瞭解更多關於人工智慧程式的資訊!
資源
GitHub:github.com/barisozmen/deepaugment
演示幻燈片:bit.ly/deepaugmentslides
Colab教程:bit.ly/deepaugmentusage
感謝Holly Szafarek和Amber Roberts。
本文由阿里云云棲社群組織翻譯。
文章原標題《AutoML for Data Augmentation》作者:Barış Özmen
譯者:Viola 審校:麼凹
原文連結
本文為雲棲社群原創內容,未經