
Netty基礎系列(3) --徹底理解NIO
前言
上一節中我們提到了同步非同步與阻塞非阻塞的區別,知道了同步並不等於阻塞。而本節的主角NIO是一種同步非阻塞的I/O模型,並且是I/O多路複用模型。NIO在java中被稱為 New I/O。它並不能提高I/O處理的效率,注意我這裡說的是效率,而從根本上解決的是I/O處理的併發問題。
那麼NIO的本質是什麼樣的呢?它是怎樣與事件模型結合來解放執行緒、提高系統吞吐的呢?
回顧五種I/O模型
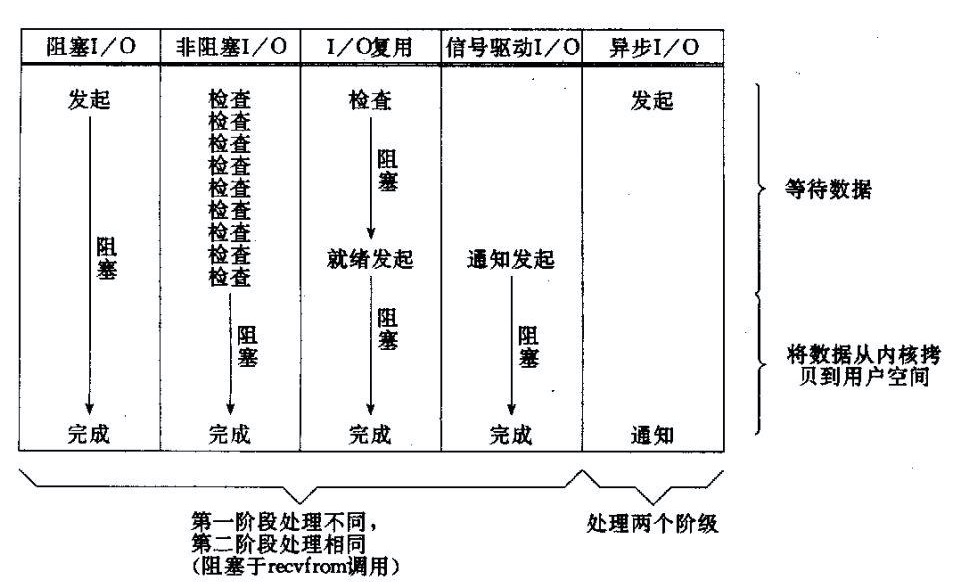
由上圖可知,所有的系統I/O都分為兩個階段:等待就緒和操作。
舉一個例子,當我們要讀某塊網絡卡的時候,分為等待系統可讀和真正讀操作;同理,當我們要output資料的時候,分為等待某個檔案/網絡卡 可寫和真正的寫操作。
理解I/O的這兩個階段實際意義尤其的重要。下面講NIO之前,我們先來深入剖析一下傳統同步阻塞式BIO。
同步阻塞式BIO
下面這個虛擬碼是一個傳統BIO模型,它的作用是列印客戶端發來的資料並返回資料。
public class SocketServer { public static void main(String args[]) { ExecutorService executor = Executors.newFixedThreadPool(100);//執行緒池 try { ServerSocket ss = new ServerSocket(8888); System.out.println("啟動伺服器...."); while (true) { //阻塞等待接受客戶端連線。 Socket socket = ss.accept(); System.out.println("客戶端:" + socket.getInetAddress().getLocalHost() + "已連線到伺服器"); executor.submit(new DataHandler(socket)); } } catch (IOException e) { e.printStackTrace(); } } static class DataHandler implements Runnable { Socket socket; public DataHandler(Socket socket) { this.socket = socket; } @Override public void run() { //阻塞操作 try { BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream())); String mess = br.readLine(); System.out.println("客戶端發來的資料:" + mess); //返回資料 BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream())); bw.write("伺服器成功列印日誌\n"); bw.flush(); } catch (IOException e) { e.printStackTrace(); } } } }
上訴程式碼中,總共有三處地方發生了阻塞,第一處是等待客戶端連線,第二處是input操作,第三處是output操作。所以該模型必須使用多執行緒來操作,如果是單執行緒,系統必將掛死在那裡。
對應上述圖片,readLine()操作又有如下兩個階段(等待可讀和實際讀操作):
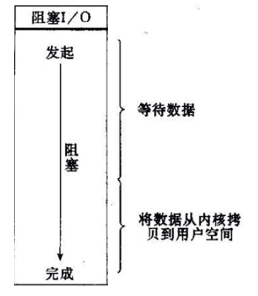
這個模型嚴格的來說效率是最快的,注意,我說的是效率。但是這種模型有一個缺點就是每當一個客戶端傳送請求的時候,伺服器就會為其建立一個執行緒,在活動連線數不是特別高(小於1000)的情況下,這種模型是比較不錯的,可以讓每一個連線專注於自己的I/O並且程式設計模型簡單,也不用過多考慮系統的過載、限流等問題。執行緒池本身就是一個天然的漏斗,可以緩衝一些系統處理不了的連線或請求。
但是這個方式的缺點就是,一旦有客戶端訪問,都建立一個專屬的執行緒去處理,即便有執行緒池的存在,當併發訪問量上來以後,CPU使用率會迅速上升,導致系統幾乎陷入不可用的狀態。
NIO
接下來我們進入今天的主題:NIO。
如果是你在開發一個基於BIO模型的伺服器,發現哪一天系統無法抗住龐大的併發,那麼你有什麼手段去優化你的伺服器呢?
沒錯,如果你看了之前的章節,那麼你的腦海一定會出現多路複用模型,在傳統BIO模型中,併發量上限的根本原因就是啟動了過多的執行緒。
對於BIO模型,之所以需要多執行緒,是因為在進行I/O操作的時候,一是沒有辦法知道到底能不能寫、能不能讀,只能”傻等”,即使通過各種估算,算出來作業系統沒有能力進行讀寫,readLine()和write()函式中返回,這兩個函式無法進行有效的中斷。所以除了多開執行緒另起爐灶,沒有好的辦法利用CPU。
NIO的讀寫函式則可以立刻返回,這就給了我們不開執行緒利用CPU的最好機會:如果一個連線不能讀寫(readLine()返回0或者write()返回0),我們可以把這件事記下來,記錄的方式通常是在Selector上註冊標記位,然後切換到其它就緒的連線(channel)繼續進行讀寫。
多路複用器Selector
當一個客戶端請求到來的時候,我們會將其(Channel)註冊到Selector上,然後Selector會不斷的輪詢註冊在其上的Channel,如果某個Channel上面發生了讀或者寫事件,這個Channel就會處於就緒狀態,會被Selector輪詢出來,然後通過呼叫方法獲取所有就緒Channel的集合,進行後續的操作。
一個多路複用器Selector可以同時輪詢多個Channel,由於JDK使用了epoll()(Netty基礎系列(1)中有介紹)代替傳統的select,所以沒有數量1024/2048的上限限制。這也就意味著每一個執行緒負責Seletor的輪詢,就可以接入成千上萬個客戶端,這確實是非常巨大的進步。
通道Channel
可以將其想象成一個水管,一個客戶端的連線成功,可以想象成這根水管一頭插入了伺服器,一頭插入了客戶端,它們之間的通訊就靠的這根水管。
與傳統的流不同,流只能在一個方向是移動(如上述程式碼,input只能寫入,output只能寫出)。但是Channel是全雙工的,意思是能同時支援讀寫操作。
快取區Buffer
在NIO庫類中加入了一個Buffer物件。它區別於傳統的流,能寫入或者將資料直接讀到Stream物件中。NIO所有資料都是基於Buffer處理的,在讀取資料的時候直接讀取Buffer裡的資料,寫資料的時候直接往Buffer裡寫資料。任何時候訪問NIO中的資料,都是通過緩衝區進行操作的。
通常情況下,作業系統的一次寫操作分為兩步: 1. 將資料從使用者空間拷貝到系統空間。 2. 從系統空間往網絡卡寫。同理,讀操作也分為兩步: ① 將資料從網絡卡拷貝到系統空間; ② 將資料從系統空間拷貝到使用者空間。
但是值得注意的是,如果使用了DirectByteBuffer(繼承Buffer),一般來說可以減少一次系統空間到使用者空間的拷貝。但Buffer建立和銷燬的成本更高,更不宜維護,通常會用記憶體池來提高效能。
如果資料量比較小的中小應用情況下,可以考慮使用heapBuffer;反之可以用directBuffer。
總結
本章多個角度的解釋了NIO,以及NIO的基本元件。
NIO程式設計的程式碼博主沒有過多的解釋,因為對於NIO程式設計博主也是個小菜雞。但是!Netty將NIO進行了進一步的封裝,讓我們能使用更簡單,更高效的API來完成我們NIO操作。比直接寫NIO更輕鬆,也不必在意作業系統之間的區別。但是有興趣的小夥伴可以自行學習NIO程式設計,然後再體會對比一下與Netty程式設計實現相同功能的難度與程式碼量。你就會深深感嘆,Netty真他麼的強大。
最後再提醒各位一點,使用NIO != 高效能,當連線數<1000,併發程度不高或者區域網環境下NIO並沒有顯著的效能優勢。