
XGBoost演算法原理小結
在兩年半之前作過梯度提升樹(GBDT)原理小結,但是對GBDT的演算法庫XGBoost沒有單獨拿出來分析。雖然XGBoost是GBDT的一種高效實現,但是裡面也加入了很多獨有的思路和方法,值得單獨講一講。因此討論的時候,我會重點分析和GBDT不同的地方。
本文主要參考了XGBoost的論文和陳天奇的PPT。
1. 從GBDT到XGBoost
作為GBDT的高效實現,XGBoost是一個上限特別高的演算法,因此在演算法競賽中比較受歡迎。簡單來說,對比原演算法GBDT,XGBoost主要從下面三個方面做了優化:
一是演算法本身的優化:在演算法的弱學習器模型選擇上,對比GBDT只支援決策樹,還可以直接很多其他的弱學習器。在演算法的損失函式上,除了本身的損失,還加上了正則化部分。在演算法的優化方式上,GBDT的損失函式只對誤差部分做負梯度(一階泰勒)展開,而XGBoost損失函式對誤差部分做二階泰勒展開,更加準確。演算法本身的優化是我們後面討論的重點。
二是演算法執行效率的優化:對每個弱學習器,比如決策樹建立的過程做並行選擇,找到合適的子樹分裂特徵和特徵值。在並行選擇之前,先對所有的特徵的值進行排序分組,方便前面說的並行選擇。對分組的特徵,選擇合適的分組大小,使用CPU快取進行讀取加速。將各個分組儲存到多個硬碟以提高IO速度。
三是演算法健壯性的優化:對於缺失值的特徵,通過列舉所有缺失值在當前節點是進入左子樹還是右子樹來決定缺失值的處理方式。演算法本身加入了L1和L2正則化項,可以防止過擬合,泛化能力更強。
在上面三方面的優化中,第一部分演算法本身的優化是重點也是難點。現在我們就來看看演算法本身的優化內容。
2. XGBoost損失函式
在看XGBoost本身的優化內容前,我們先回顧下GBDT的迴歸演算法迭代的流程,詳細演算法流程見梯度提升樹(GBDT)原理小結第三節,對於GBDT的第t顆決策樹,主要是走下面4步:
1)對樣本i=1,2,...m,計算負梯度$$r_{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]_{f(x) = f_{t-1}\;\; (x)}$$
2)利用$(x_i,r_{ti})\;\; (i=1,2,..m)$, 擬合一顆CART迴歸樹,得到第t顆迴歸樹,其對應的葉子節點區域為$R_{tj}, j =1,2,..., J$。其中J為迴歸樹t的葉子節點的個數。
3) 對葉子區域j =1,2,..J,計算最佳擬合值$$c_{tj} = \underbrace{arg\; min}_{c}\sum\limits_{x_i \in R_{tj}} L(y_i,f_{t-1}(x_i) +c)$$
4) 更新強學習器$$f_{t}(x) = f_{t-1}(x) + \sum\limits_{j=1}^{J}c_{tj}I(x \in R_{tj}) $$
上面第一步是得到負梯度,或者是泰勒展開式的一階導數。第二步是第一個優化求解,即基於殘差擬合一顆CART迴歸樹,得到J個葉子節點區域。第三步是第二個優化求解,在第二步優化求解的結果上,對每個節點區域再做一次線性搜尋,得到每個葉子節點區域的最優取值。最終得到當前輪的強學習器。
從上面可以看出,我們要求解這個問題,需要求解當前決策樹最優的所有J個葉子節點區域和每個葉子節點區域的最優解$c_{tj}$。GBDT取樣的方法是分兩步走,先求出最優的所有J個葉子節點區域,再求出每個葉子節點區域的最優解。
對於XGBoost,它期望把第2步和第3步合併在一起做,即一次求解出決策樹最優的所有J個葉子節點區域和每個葉子節點區域的最優解$c_{tj}$。在討論如何求解前,我們先看看XGBoost的損失函式的形式。
在GBDT損失函式$L(y, f_{t-1}(x)+ h_t(x))$的基礎上,我們加入正則化項如下:$$\Omega(h_t) = \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2$$
這裡的$J$是葉子節點的個數,而$w_{tj}$是第j個葉子節點的最優值。這裡的$w_{tj}$和我們GBDT裡使用的$c_{tj}$是一個意思,只是XGBoost的論文裡用的是$w$表示葉子區域的值,因此這裡和論文保持一致。
最終XGBoost的損失函式可以表達為:$$L_t=\sum\limits_{i=1}^mL(y_i, f_{t-1}(x_i)+ h_t(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 $$
最終我們要極小化上面這個損失函式,得到第t個決策樹最優的所有J個葉子節點區域和每個葉子節點區域的最優解$w_{tj}$。XGBoost沒有和GBDT一樣去擬合泰勒展開式的一階導數,而是期望直接基於損失函式的二階泰勒展開式來求解。現在我們來看看這個損失函式的二階泰勒展開式:
$$\begin{align} L_t & = \sum\limits_{i=1}^mL(y_i, f_{t-1}(x_i)+ h_t(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 \\ & \approx \sum\limits_{i=1}^m( L(y_i, f_{t-1}(x_i)) + \frac{\partial L(y_i, f_{t-1}(x_i) }{\partial f_{t-1}(x_i)}h_t(x_i) + \frac{1}{2}\frac{\partial^2 L(y_i, f_{t-1}(x_i) }{\partial f_{t-1}^2(x_i)} h_t^2(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 \end{align}$$
為了方便,我們把第i個樣本在第t個弱學習器的一階和二階導數分別記為$$g_{ti} = \frac{\partial L(y_i, f_{t-1}(x_i) }{\partial f_{t-1}(x_i)}, \; h_{ti} = \frac{\partial^2 L(y_i, f_{t-1}(x_i) }{\partial f_{t-1}^2(x_i)}$$
則我們的損失函式現在可以表達為:$$L_t \approx \sum\limits_{i=1}^m( L(y_i, f_{t-1}(x_i)) + g_{ti}h_t(x_i) + \frac{1}{2} h_{ti} h_t^2(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2$$
損失函式裡面$L(y_i, f_{t-1}(x_i))$是常數,對最小化無影響,可以去掉,同時由於每個決策樹的第j個葉子節點的取值最終會是同一個值$w_{tj}$,因此我們的損失函式可以繼續化簡。
$$\begin{align} L_t & \approx \sum\limits_{i=1}^m g_{ti}h_t(x_i) + \frac{1}{2} h_{ti} h_t^2(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 \\ & = \sum\limits_{j=1}^J (\sum\limits_{x_i \in R_{tj}}g_{ti}w_{tj} + \frac{1}{2} \sum\limits_{x_i \in R_{tj}}h_{ti} w_{tj}^2) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 \\ & = \sum\limits_{j=1}^J [(\sum\limits_{x_i \in R_{tj}}g_{ti})w_{tj} + \frac{1}{2}( \sum\limits_{x_i \in R_{tj}}h_{ti}+ \lambda) w_{tj}^2] + \gamma J \end{align}$$
我們把每個葉子節點區域樣本的一階和二階導數的和單獨表示如下:$$G_{tj} = \sum\limits_{x_i \in R_{tj}}g_{ti},\; H_{tj} = \sum\limits_{x_i \in R_{tj}}h_{ti}$$
最終損失函式的形式可以表示為:$$L_t = \sum\limits_{j=1}^J [G_{tj}w_{tj} + \frac{1}{2}(H_{tj}+\lambda)w_{tj}^2] + \gamma J $$
現在我們得到了最終的損失函式,那麼回到前面講到的問題,我們如何一次求解出決策樹最優的所有J個葉子節點區域和每個葉子節點區域的最優解$w_{tj}$呢?
3. XGBoost損失函式的優化求解
關於如何一次求解出決策樹最優的所有J個葉子節點區域和每個葉子節點區域的最優解$w_{tj}$,我們可以把它拆分成2個問題:
1) 如果我們已經求出了第t個決策樹的J個最優的葉子節點區域,如何求出每個葉子節點區域的最優解$w_{tj}$?
2) 對當前決策樹做子樹分裂決策時,應該如何選擇哪個特徵和特徵值進行分裂,使最終我們的損失函式$L_t$最小?
對於第一個問題,其實是比較簡單的,我們直接基於損失函式對$w_{tj}$求導並令導數為0即可。這樣我們得到葉子節點區域的最優解$w_{tj}$表示式為:$$w_{tj} = - \frac{G_{tj}}{H_{tj} + \lambda}$$
這個葉子節點的表示式不是XGBoost首創,實際上在GBDT的分類演算法裡,已經在使用了。大家在梯度提升樹(GBDT)原理小結第4.1節中葉子節點區域值的近似解表示式為:$$c_{tj} = \sum\limits_{x_i \in R_{tj}}r_{ti}\bigg / \sum\limits_{x_i \in R_{tj}}|r_{ti}|(1-|r_{ti}|)$$
它其實就是使用了上式來計算最終的$c_{tj}$。注意到二元分類的損失函式是:$$L(y, f(x)) = log(1+ exp(-yf(x)))$$
其每個樣本的一階導數為:$$g_i=-r_i= -y_i/(1+exp(y_if(x_i)))$$
其每個樣本的二階導數為:$$h_i =\frac{exp(y_if(x_i)}{(1+exp(y_if(x_i))^2} = |g_i|(1-|g_i|) $$
由於沒有正則化項,則$c_{tj} = -\frac{g_i}{h_i} $,即可得到GBDT二分類葉子節點區域的近似值。
現在我們回到XGBoost,我們已經解決了第一個問題。現在來看XGBoost優化拆分出的第二個問題:如何選擇哪個特徵和特徵值進行分裂,使最終我們的損失函式$L_t$最小?
在GBDT裡面,我們是直接擬合的CART迴歸樹,所以樹節點分裂使用的是均方誤差。XGBoost這裡不使用均方誤差,而是使用貪心法,即每次分裂都期望最小化我們的損失函式的誤差。
注意到在我們$w_{tj}$取最優解的時候,原損失函式對應的表示式為:$$L_t = -\frac{1}{2}\sum\limits_{j=1}^J\frac{G_{tj}^2}{H_{tj} + \lambda} +\gamma J$$
如果我們每次做左右子樹分裂時,可以最大程度的減少損失函式的損失就最好了。也就是說,假設當前節點左右子樹的一階二階導數和為$G_L,H_L,G_R,H_L$, 則我們期望最大化下式:$$-\frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+ \lambda} +\gamma J -( -\frac{1}{2}\frac{G_L^2}{H_L + \lambda} -\frac{1}{2}\frac{G_{tj}^2}{H_{tj+\lambda} + \lambda}+ \gamma (J+1) ) $$
整理下上式後,我們期望最大化的是:$$\max \frac{1}{2}\frac{G_L^2}{H_L + \lambda} + \frac{1}{2}\frac{G_R^2}{H_R+\lambda} - \frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+ \lambda} + \gamma$$
也就是說,我們的決策樹分裂標準不再使用CART迴歸樹的均方誤差,而是上式了。
具體如何分裂呢?舉個簡單的年齡特徵的例子如下,假設我們選擇年齡這個 特徵的值a作為決策樹的分裂標準,則可以得到左子樹2個人,右子樹三個人,這樣可以分別計算出左右子樹的一階和二階導數和,進而求出最終的上式的值。

然後我們使用其他的不是值a的劃分標準,可以得到其他組合的一階和二階導數和,進而求出上式的值。最終我們找出可以使上式最大的組合,以它對應的特徵值來分裂子樹。
至此,我們解決了XGBoost的2個優化子問題的求解方法。
4. XGBoost演算法主流程
這裡我們總結下XGBoost的演算法主流程,基於決策樹弱分類器。不涉及執行效率的優化和健壯性優化的內容。
輸入是訓練集樣本$I=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\}$, 最大迭代次數T, 損失函式L, 正則化係數$\lambda,\gamma$。
輸出是強學習器f(x)
對迭代輪數t=1,2,...T有:
1) 計算第i個樣本(i-1,2,..m)在當前輪損失函式L基於$f_{t-1}(x_i)$的一階導數$g_{ti}$,二階導數$h_{ti}$,計算所有樣本的一階導數和$G_t = \sum\limits_{i=1}^mg_{ti}$,二階導數和$H_t = \sum\limits_{i=1}^mh_{ti}$
2) 基於當前節點嘗試分裂決策樹,預設分數score=0
對特徵序號 k=1,2...K:
a) $G_L=0, H_L=0$
b.1) 將樣本按特徵k從小到大排列,依次取出第i個樣本,依次計算當前樣本放入左子樹後,左右子樹一階和二階導數和:$$G_L = G_L+ g_{ti}, G_R=G-G_L$$$$H_L = H_L+ h_{ti}, H_R=H-H_L$$
b.2) 嘗試更新最大的分數:$$score = max(score, \frac{1}{2}\frac{G_L^2}{H_L + \lambda} + \frac{1}{2}\frac{G_R^2}{H_R+\lambda} - \frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+ \lambda} )$$
3) 基於最大score對應的劃分特徵和特徵值分裂子樹。
4) 如果最大score為0,則當前決策樹建立完畢,計算所有葉子區域的$w_{tj}$, 得到弱學習器$h_t(x)$,更新強學習器$f_t(x)$,進入下一輪弱學習器迭代.如果最大score不是0,則轉到第2)步繼續嘗試分裂決策樹。
5.XGBoost演算法執行效率的優化
在第2,3,4節我們重點討論了XGBoost演算法本身的優化,在這裡我們再來看看XGBoost演算法執行效率的優化。
大家知道,Boosting演算法的弱學習器是沒法並行迭代的,但是單個弱學習器裡面最耗時的是決策樹的分裂過程,XGBoost針對這個分裂做了比較大的並行優化。對於不同的特徵的特徵劃分點,XGBoost分別在不同的執行緒中並行選擇分裂的最大增益。
同時,對訓練的每個特徵排序並且以塊的的結構儲存在記憶體中,方便後面迭代重複使用,減少計算量。計算量的減少參見上面第4節的演算法流程,首先預設所有的樣本都在右子樹,然後從小到大迭代,依次放入左子樹,並尋找最優的分裂點。這樣做可以減少很多不必要的比較。
具體的過程如下圖所示:
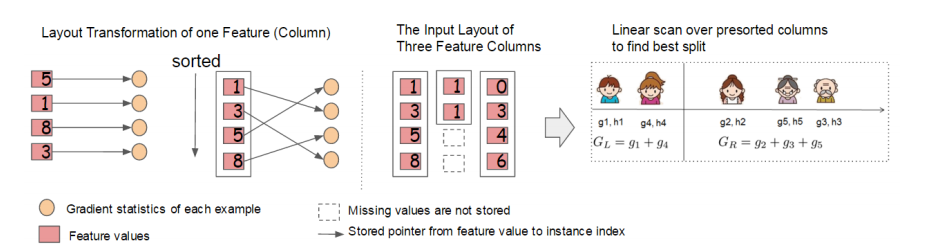
此外,通過設定合理的分塊的大小,充分利用了CPU快取進行讀取加速(cache-aware access)。使得資料讀取的速度更快。另外,通過將分塊進行壓縮(block compressoin)並存儲到硬碟上,並且通過將分塊分割槽到多個硬碟上實現了更大的IO。
6.XGBoost演算法健壯性的優化
最後我們再來看看XGBoost在演算法健壯性的優化,除了上面講到的正則化項提高演算法的泛化能力外,XGBoost還對特徵的缺失值做了處理。
XGBoost沒有假設缺失值一定進入左子樹還是右子樹,則是嘗試通過列舉所有缺失值在當前節點是進入左子樹,還是進入右子樹更優來決定一個處理缺失值預設的方向,這樣處理起來更加的靈活和合理。
也就是說,上面第4節的演算法的步驟a),b.1)和b.2)會執行2次,第一次假設特徵k所有有缺失值的樣本都走左子樹,第二次假設特徵k所有缺失值的樣本都走右子樹。然後每次都是針對沒有缺失值的特徵k的樣本走上述流程,而不是所有的的樣本。
如果是所有的缺失值走左子樹,使用上面第4節的a),b.1)和b.2)即可。如果是所有的樣本走右子樹,則上面第4節的a)步要變成:$$G_R=0, H_R=0$$
b.1)步要更新為:$$G_R = G_R+g_{ti}, G_L=G-G_R$$$$H_R = H_R+h_{ti}, H_L=H-H_R$$
7. XGBoost小結
不考慮深度學習,則XGBoost是演算法競賽中最熱門的演算法,它將GBDT的優化走向了一個極致。當然,後續微軟又出了LightGBM,在記憶體佔用和執行速度上又做了不少優化,但是從演算法本身來說,優化點則並沒有XGBoost多。
何時使用XGBoost,何時使用LightGBM呢?個人建議是優先選擇XGBoost,畢竟調優經驗比較多一些,可以參考的資料也多一些。如果你使用XGBoost遇到的記憶體佔用或者執行速度問題,那麼嘗試LightGBM是個不錯的選擇。
(歡迎轉載,轉載請註明出處。歡迎溝通交流: [email protected])&n