
機器學習入門之單變數線性迴歸(上)——梯度下降法
在統計學中,線性迴歸(英語:linear regression)是利用稱為線性迴歸方程的最小二乘函式對一個或多個自變數和因變數之間關係進行建模的一種迴歸分析。這種函式是一個或多個稱為迴歸係數的模型引數的線性組合。只有一個自變數的情況稱為簡單迴歸,大於一個自變數情況的叫做多元迴歸(multivariate linear regression)。——————維基百科
長久以來,這部分內容都是ML的敲門磚,吳恩達教授在他的課程中也以此為第一個例子,同時,本篇也參考了許多吳教授的內容。
在這裡,我簡單把自變數稱為x,因變數稱為y。在單變數線性迴歸中,x是一個一維的連續值。
單變數線性迴歸即是為所給資料,擬合一個最優方程,也就是劃出一條最符合原始資料的線(通常要求資料為連續值)。
在本篇,我們將用梯度下降的方法,擬合出一條與原始資料最接近的直線,換言之,找到擬合效果最好的直線方程。
假設設直線方程如下:
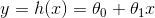 (θ0即是常數項,或者說是一個常數偏移值)
(θ0即是常數項,或者說是一個常數偏移值)
在學習梯度下降法之前,我們還需要了解一些字首知識,包括但不限於:
-
歸一化(資料預處理)
歸一化公式:

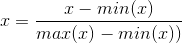
歸一化是一種把資料對映到[0, 1]區間內的預處理,在本例中,這樣處理主要是為了提高梯度下降收斂的速度。
-
cost 函式
cost函式(function)是一個評估迴歸模型是否擬合得好的函式,cost越低的函式,說明模型擬合數據集越好。
在本例中,採用了比較常用的方差,即
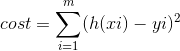
-
梯度 (gradient)以及迭代項的推導
梯度是函式在變化最快的方向上的方向導數,它是偏導的一種應用(這部分知識可參考微積分或高等數學內容,雖然即使不瞭解也可直接使用推論,但如果想深入學習的話還是吃透為好)。按梯度的定義可知:
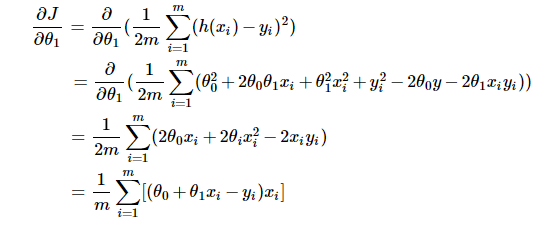
這部分是對θ1的偏導,對θ0的偏導可自行推導,與以上差別不大。若有疑惑(為什麼對cost 函式求偏導?),請往下看。
瞭解完以上內容後,我們知道,對於給定的θ1和θ0,我們憑藉cost 函式就能評估出他們的好壞(cost越小,擬合越好)。同時,我們知道不論對於θ1/0來說,必然存在某個最準確、擬合效果最好的值,一旦偏離這個值,偏離得越遠,擬合效果就越差,cost 函式的值也就越大。
假設θ0恆為0,那麼cost關於θ1的函式的影象應當為一個類似山谷的形狀,如下圖:

最低點即使擬合最好的θ1(cost最小)。
同理,假設θ0不恆定,那麼影象將有兩個自變數,形狀大致像一個碗,如下圖:
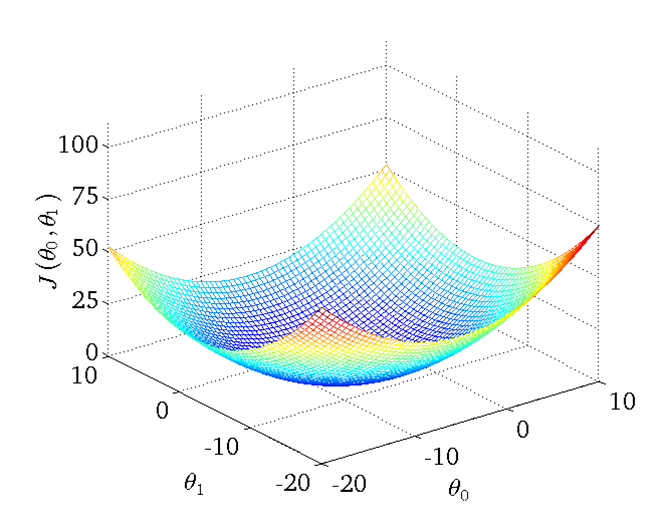 (圖源吳教授課程)
(圖源吳教授課程)
易得,在‘碗’的最低點(θ0', θ1')即是擬合效果最好的θ0與θ1,那麼如何找到這個最低點呢?
梯度下降是這麼認為的,首先隨機取一個點,然後按梯度方向去迭代點,讓點越來越趨近、直至收斂於最低點。
原理很簡單,但是這個迭代公式該如何求呢?
答案也不難,就是按照梯度的概念來:
 (偏導部分在字首知識部分有說明)
(偏導部分在字首知識部分有說明)
幾何意義大抵是點(θ0,θ1)以α為速率,梯度為步長,按梯度方向(函式變化最快的方向)向最低點移動。
虛擬碼:
① 隨機初始化點
② 按照一定的比例/步伐(學習率),往梯度向下的方向迭代
③ 收斂或精度足夠時停止
可能有的人不太懂收斂的原因,這部分涉及到微積分的知識,大致是這樣:
當點越趨近最低點時,偏導會越來越小,直至為0,此時收斂。可以認為在接近最低點的過程中,切向量的值逐漸減小(碗狀曲面逐漸平緩),抵達最低點時,切平面平行於xoy面,切向量為0,此時不論如何迭代,θ的值都不再變化。
我們知道,前面的原理部分並沒有涉及到α學習率(learning rate)這個概念,那麼這個東西是要幹什麼呢?
看過吳教授課程的同學可能知道,在下降的過程中,如果步伐太大的話,是無法收斂到最低點的,如果不加上α來控制步伐大小,在很多情況下,都可能導致無法找到最低點。
為了解決這個問題,梯度下降引入了α來控制下降的步伐大小,確保能夠收斂。但同時,α太小的話,也會導致收斂過慢。
需要著重說明的是θ1和θ2應該嚴格同步更新,按我的理解來,這是因為梯度是基於當前點的最大變化值,如果非同步更新的話,比方說我們先更新θ1,然後再遍歷更新θ0,此時更新θ0是基於新的θ1,所以不滿足梯度的要求。
順帶一提,梯度下降總會收斂於區域性最小值。不過在單變數線性迴歸中,區域性最小值即是全域性最小值。
以上就是單變數線性迴歸的內容,接下來我們將嘗試應用於資料集:
給出一個數據集(工作經驗與年薪)如下:
YearsExperience |
Salary |
1.1 |
39343.00 |
1.3 |
46205.00 |
1.5 |
37731.00 |
| .... | .... |
文末將給出下載地址。
首先對資料進行歸一化,提高收斂速度。然後我們簡單地設定θ初始值為(0,0),α為0.01,精度為1e-4,最大迭代次數為1e4。
擬合效果如下:
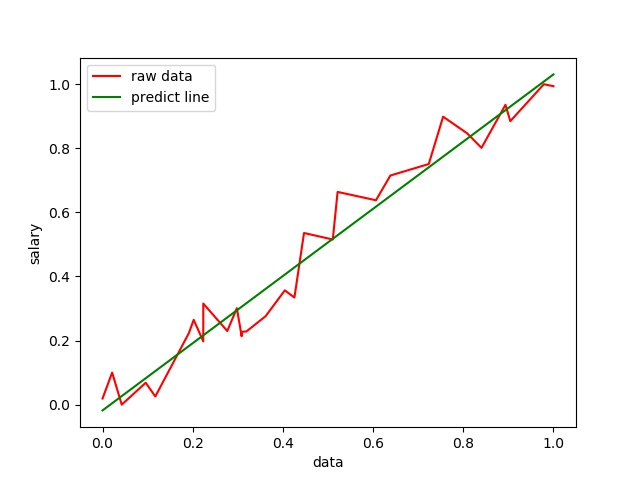
可以看到效果還是比較理想的,接下來是cost的變化影象:
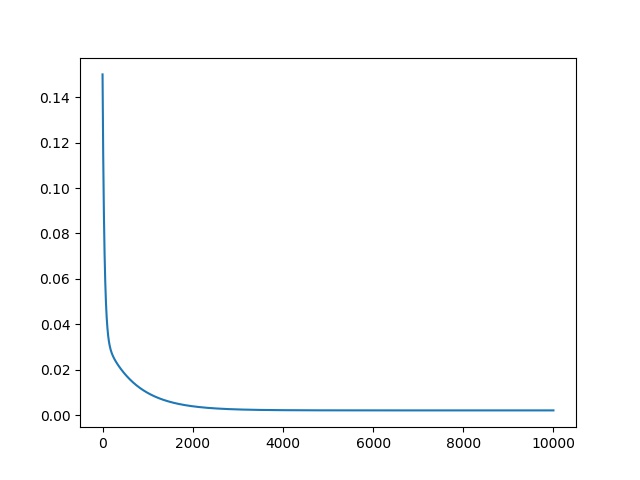
可以看到大致迭代3000次的時候基本收斂了,由於收斂值大於精度,所以迭代次數為設定的最大次數。
總結:
這部分內容應該說相當好上手,主要把握好梯度這個概念,理解好迭代(逐漸趨於cost區域性最小),之後就都不難了。並且梯度下降在機器學習中有比較廣泛的應用,所以對它的學習必不可少。
資料集和程式碼我都推到github上了,有需要請點選:https://github.com/foolishkylin/workspace/tree/master/machine_learning/getting_started/gradient_descent/liner_regression_single
&n