大資料(hadoop-flume的原理架構)
阿新 • • 發佈:2019-06-14
背景介紹
Hadoop提供了一箇中央化的儲存系統
有利於進行集中式的資料分析與資料共享
Hadoop對儲存格式沒有要求:
使用者訪問日誌
產品資訊
網頁資料等
如何將資料存入Hadoop:
資料分散在各個離散的裝置上
資料儲存在傳統的儲存裝置和系統中
常見的兩種資料來源
分散的資料來源:
機器產生的資料;
使用者訪問日誌;
使用者購買日誌。
傳統系統中的資料:
傳統關係型資料庫:Mysql、Oracle等;
Hadoop收集和入庫基本要求
分散式
資料來源多樣化
資料來源分散
可靠性
保證不丟資料
允許丟部分資料
可擴充套件
資料來源可能會不斷增加
通過並行提高效能
資料收集
Flume
Kafka
Scribe
傳統資料庫與Hadoop同步
Sqoop
Flume
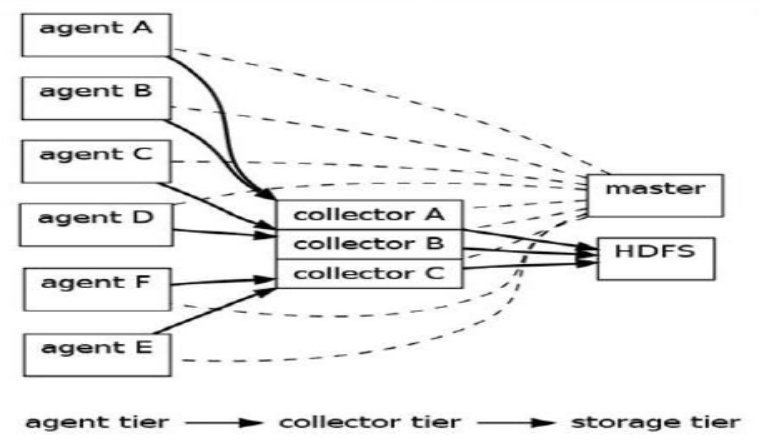
Flume OG
OG:“Original Genaration”
0.9.x或cdh3以及更早版本
由agent、collector、master等元件構成
Flume NG
NG:“Next/New Generation”
1.x或cdh4以及之後的版本
由Agent、Client等元件構成
為什麼要推出NG版本
精簡程式碼
架構簡化
Flume OG基本架構
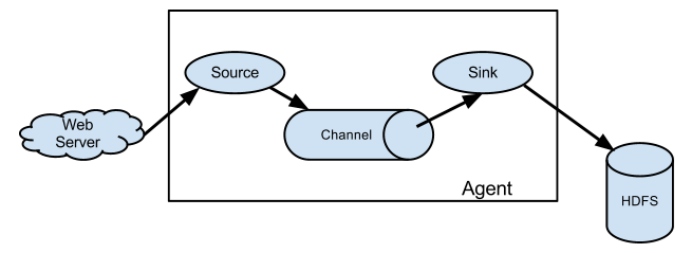
Flume NG基本架構