大資料(hadoop分散式搭建和yarn)
分散式搭建步驟
1:克隆一臺機器完成後,按以下步驟進行修改(作為源克隆主機)
1)修改網絡卡資訊,路徑/etc/sysconfig/network-scripts
2)刪除70-persistent-net.rules這個檔案,路徑在:/etc/udev/rules.d
3)修改hosts檔案,設定ip和主機名對映關係
如:
127.0.0.1 localhost
192.168.153.115 hm02
192.168.153.116 hs0201
192.168.153.117 hs0202
4)重啟
5)刪除hadoop和jdk的安裝包(可選)
6)刪除hadoop2.7.3下面的tmp目錄
2:克隆從節點後,修改步驟
比上面的主節點的步驟,少3,5,6這幾步
3:免密登陸設定
1)重新生成私鑰和公鑰(主從節點)
2)將公鑰寫入authorized_keys這個檔案(主節點)
三臺機器的免密設定
3)將2臺從節點上面的公鑰遠端拷貝到主節點
4)在主節點上面將從節點的公鑰合併到authorized_keys這個檔案
5)把這已經合併了三臺機器公鑰的authorized_keys檔案分發到兩個從節點上面
cat id_rsa.pub_from_hs0201 >> authorized_keys
scp authorized_keys hadoop@hs0202:~/.ssh/authorized_keys
4:hadoop分散式搭建
hm02是主節點:namenode,resourcemanager
hs0201和hs0202是從節點:datanode,nodemanager
1):主從節點配置檔案修改:
(如果配置檔案多且修改的內容較多,最好是在一臺機器上設定好,再克隆)
修改檔案:
(1)core-site.xml
<value>hdfs://hm02:9000</value>
(2)slaves
新增從節點資訊
hs0201
hs0202
(3)yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hm02</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2)格式化主節點上的hdfs
./hdfs namenode -format
3)啟動叢集進行測試
./sbin/start-all.sh
4)自帶的mapreduce程式進行測試
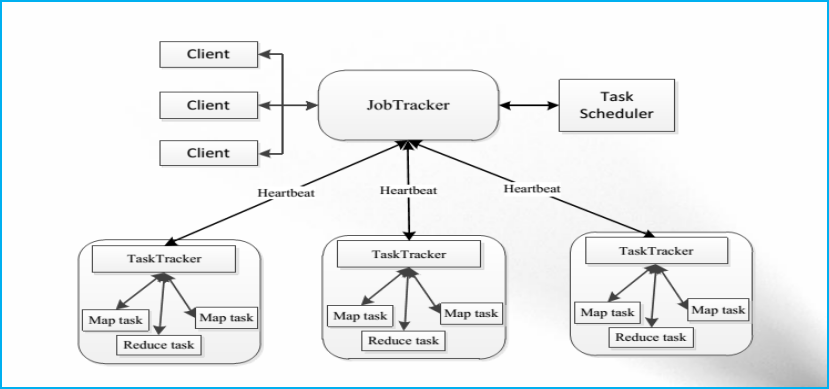
Hadoop YARN產生背景
YARN產生背景—MapReduce 1.0固有問題
YARN產生背景—資源利用率
YARN產生背景—運維成本與資料共享
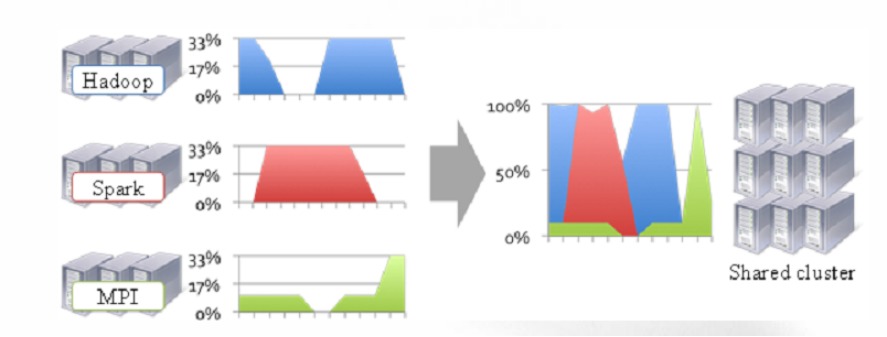
運維成本 如果採用“一個框架一個叢集”的模式,則可能需要多個管理員管理這些叢集,進而增加運維成本,而共享模式通常需要少數管理員即可完成多個框架的統一管理。
資料共享 隨著資料量的暴增,跨叢集間的資料移動不僅需花費更長的時間,且硬體成本也會大大增加,而共享叢集模式可讓多種框架共享資料和硬體資源,將大大減小資料移動帶來的成本。
YARN產生背景—總結
直接源於MRv1在幾個方面的缺陷
擴充套件性受限
單點故障
難以支援MR之外的計算
多計算框架各自為戰,資料共享困難
MR:離線計算框架
Storm:實時計算框架
Spark:記憶體計算框架 。
YARN基本架構
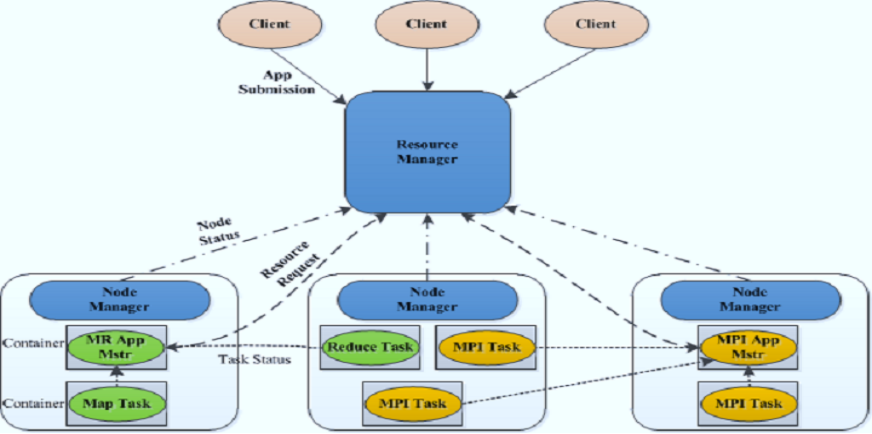
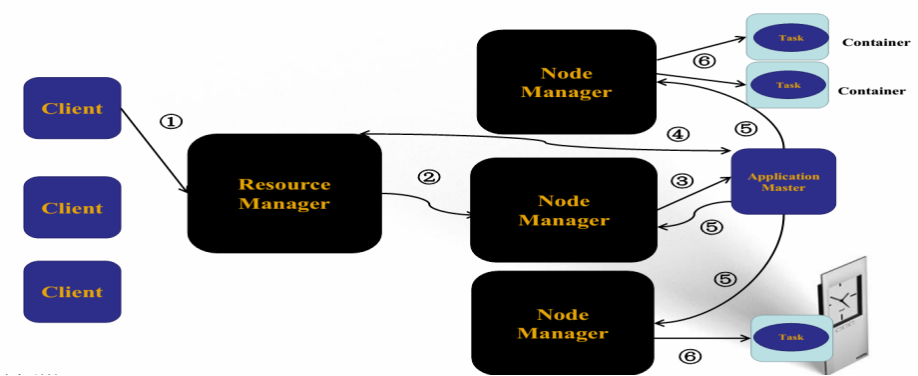
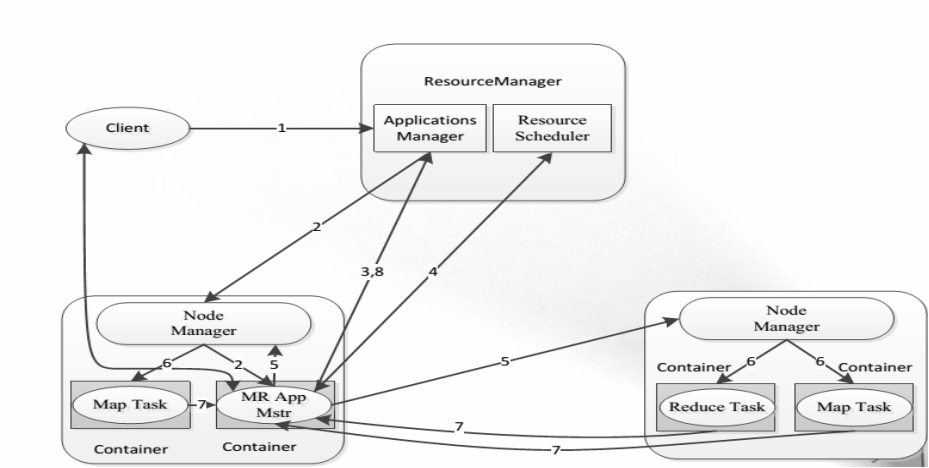
ResourceManager
負責叢集資源的統一管理和排程
詳細功能
處理客戶端請求
啟動/監控ApplicationMaster
監控NodeManager
資源分配與排程
NodeManager
負責單節點資源管理和使用
詳細功能
單個節點上的資源管理和任務管理
處理來自ResourceManager的命令
處理來自ApplicationMaster的請求
ApplicationMaster
每個應用有一個,負責應用程式的管理
詳細功能
與RM排程器協商以獲取資源;
將得到的任務進一步分配給內部的任務(資源的二次分配);
與NM通訊以啟動/停止任務;
監控所有任務執行狀態,並在任務執行失敗時重新為任務申請資源以重啟任務。
Container
對任務執行環境的抽象
描述一系列資訊
任務執行資源(節點、記憶體、CPU)
任務啟動命令
任務執行環境
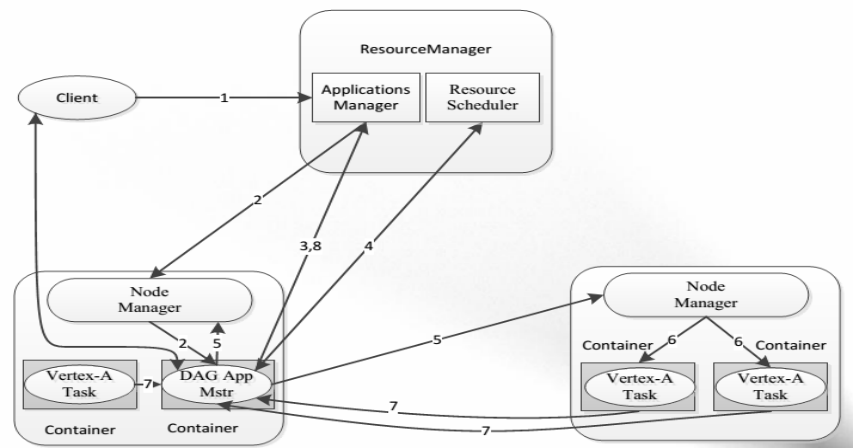
YARN執行過程剖析
YARN容錯性
ResourceManager
存在單點故障;
正在基於ZooKeeper實現HA
NodeManager
失敗後,RM將失敗任務告訴對應的AM;
AM決定如何處理失敗的任務
ApplicationMaster
失敗後,由RM負責重啟;
AM需處理內部任務的容錯問題
RMAppMaster會儲存已經執行完成的Task,重啟後無需重新執行。
YARN排程框架
雙層排程框架
RM將資源分配給AM
AM將資源進一步分配給各個Task
基於資源預留的排程策略
資源不夠時,會為Task預留,直到資源充足
與“ all or nothing”策略不同( Apache Mesos)
YARN資源排程器
多型別資源排程
目前支援CPU和記憶體兩種資源
提供多種資源排程器
FIFO
Fair Scheduler
Capacity Scheduler
多租戶資源排程器
支援資源按比例分配
支援層級佇列劃分方式
支援資源搶佔。
YARN資源隔離方案
支援記憶體和CPU兩種資源隔離
記憶體是一種“決定生死”的資源
CPU是一種“影響快慢”的資源
記憶體隔離
基於執行緒監控的方案
CPU隔離
預設不對CPU資源進行隔離
應用程式種類繁多
YARN設計目標
通用的統一資源管理系統
同時執行長應用程式和短應用程式
長應用程式
通常情況下,永不停止執行的程式
Service、HTTP Server等
短應用程式
短時間(秒級、分鐘級、小時級)內會執行結束的程式
MR job、Spark Job等
以YARN為核心的生態系統
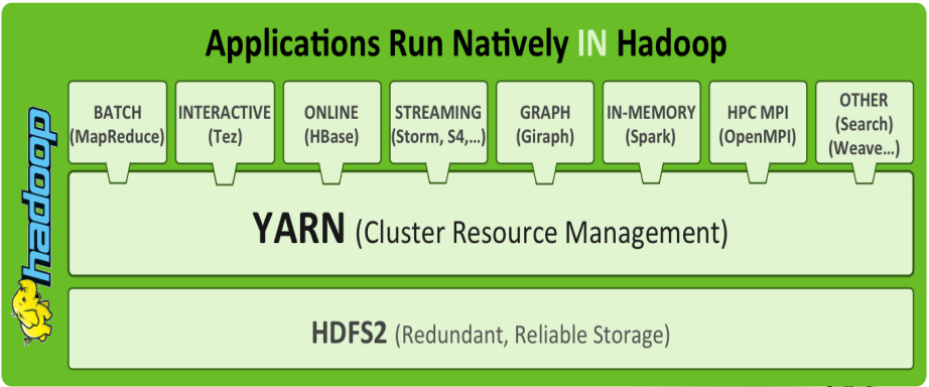
執行在YARN上的計算框架
離線計算框架:MapReduce
DAG計算框架:TEZ
流式計算框架:Storm
記憶體計算框架:Spark
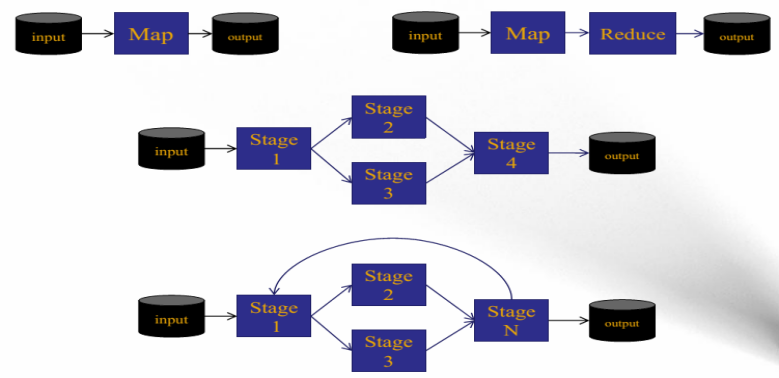
離線計算框架MapReduce
將計算過程分為兩個階段,Map和Reduce
Map階段並行處理輸入資料
Reduce階段對Map結果進行彙總
Shuffle連線Map和Reduce兩個階段
Map Task將資料寫到本地磁碟
Reduce Task從每個Map Task上讀取一份資料
僅適合離線批處理
具有很好的容錯性和擴充套件性
適合簡單的批處理任務
缺點明顯
啟動開銷大、過多使用磁碟導致效率低下等
MapReduce On YARN
DAG計算框架Tez
多個作業之間存在資料依賴關係,並形成一個依賴關係有向圖(Directed Acyclic Graph ),該圖的計算稱為“ DAG計算”
Apache Tez:基於YARN的DAG計算框架
執行在YARN之上,充分利用YARN的資源管理和容錯等功能;
提供了豐富的資料流(dataflow)API;
動態生成物理資料流關係。

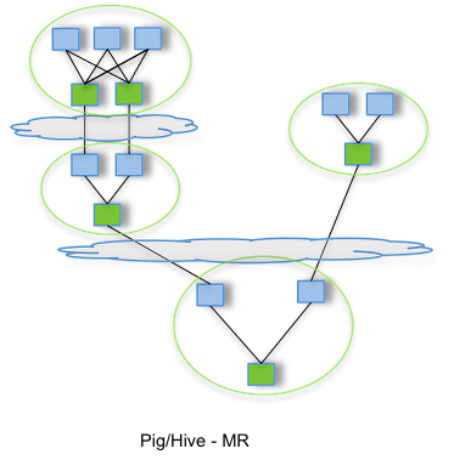

Tez On YARN
Tez優化技術
ApplicationMaster緩衝池
作業提交到AMPoolServer服務上
預啟動若干個ApplicationMaster,形成一個ApplicationMaster緩衝池
預先啟動Container
ApplicationMaster啟動時可以預先啟動若干個Container
Container重用
任務執行完成後,ApplicationMaster不會馬上登出它使用的Container,
而是將它重新分配給其他未執行的任務
Tez應用場景
直接編寫應用程式
Tez提供了一套通用程式設計介面
適合編寫有依賴關係的作業
優化Pig、Hive等引擎
下一代Hive:Stinger
好處1:避免查詢語句轉換成過多的MapReduce作業後產生大量不必要
的網路和磁碟IO
好處2:更加智慧的任務處理引擎
流式計算框架Storm
流式( Streaming) 計算,是指被處理的資料像流水一樣不斷流入系統,而系統需要針對每條資料進行實時處理和計算,並永不停止(直到使用者顯式殺死程序) ;
傳統做法: 由訊息佇列和訊息處理者組成的實時處理網路進行實時計算;
缺乏自動化
缺乏健壯性
伸縮性差
Storm出現

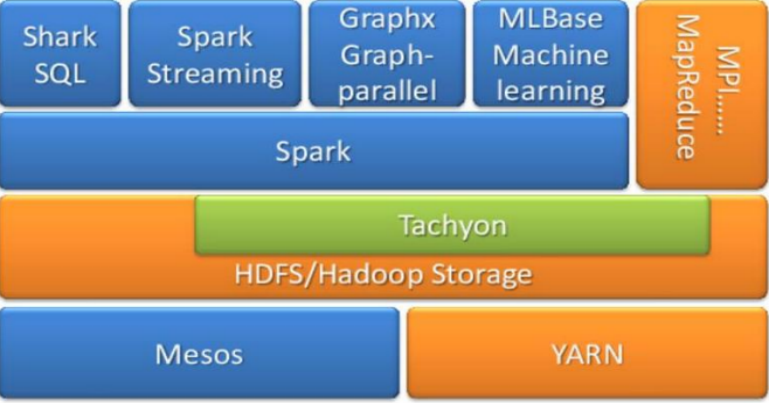
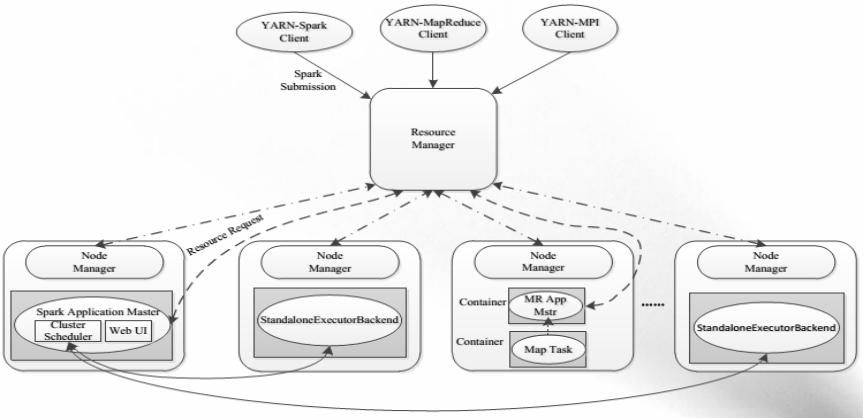
記憶體計算框架Spark
克服MapReduce在迭代式計算和互動式計算方面的不足
引入RDD( Resilient Distributed Datasets)資料表示模型;
RDD是一個有容錯機制,可以被並行操作的資料集合,能夠被快取到記憶體或磁碟上
Spark On YARN
Spark生態系統