
擬合多項式演示overfitting
阿新 • • 發佈:2019-07-24
# 預先匯入庫
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
from scipy import interpolate
在本例中,輸入變數\(x\)為一維,然後對應的輸出\(y=sin(x)+ \epsilon\),其中\(\epsilon\)為噪聲。那麼生成資料的程式碼為:
def make_data(): """生成一維資料並且返回,y=sin(4x) + noise""" np.random.seed(1) X = np.sort(np.random.rand(30)) y = np.sin(4 * X) + np.random.randn(30) * 0.3 return X, y
一維線性迴歸
一開始,我們先用直接用線性迴歸擬合曲線。眾所周知,擬合出來應該是一條直線。實際跑出來結果如下:
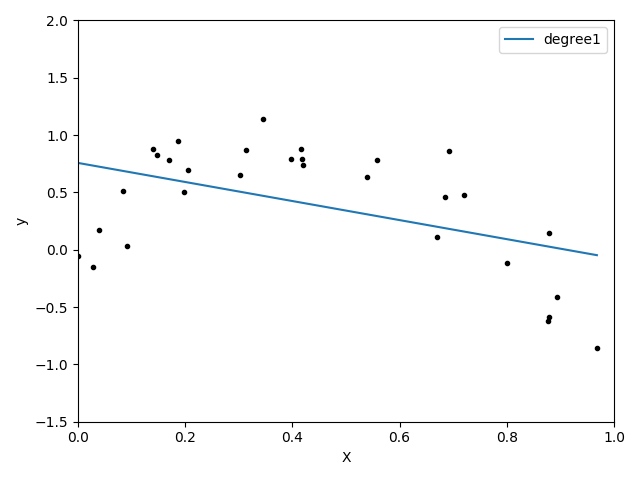 

多元線性迴歸
要使得擬合結果更好,就需要增加輸入變數的維度。要如何增加維度比較科學?大學我們有學過正弦函式的級數表達,也就是說:
\[sin(x) = a_0 * x + a_1 * x^2 + a_2 * x^3 + ...\]
所以接下來的目標是給輸入變數\(x\)新增多項式維度,並分析隨著維度的增加,擬合曲線會怎麼變化。
給輸入變數增加維度可以使用sklearn.preprocessing.PolynomialFeatures處理,具體程式碼如下:
def get_polynomial_feature(origin_features, deg): """ 用於新增多項式維度,最後以np.array形式返回 :param origin_features: 多維陣列,本例中shape為(n,1),即類似於np.array([[1],[2]]) :param deg: 需要擴充套件的維度.比如deg=3,那就是x, x^2, x^3 :return: 擴充套件後的np.array """ polynomial = PolynomialFeatures( degree=deg, include_bias=False # 不生成常數項 ) polynomial_features = polynomial.fit_transform(origin_features) return polynomial_features
然後,根據\(degree\)的不同,生成不同的輸入變數\(H_{degree}(x)\),使用sklearn的LinearRegression來擬合即可。
if __name__ == '__main__': # 生成資料 features, target = make_data() features = features.reshape(-1, 1) # 在圖上畫出點 plot_data(features, target) for i in [1]: poly_data = get_polynomial_feature(features, i) model = LinearRegression() model.fit(poly_data, target) # print(f"degree - {i}:", model.coef_) # 檢視模型訓練得到的引數 # 插值處理畫圖平滑曲線 x = features.squeeze() # 生成插值的資料只能是一維 pred_y = model.predict(poly_data) new_x = np.arange(x.min(), x.max(), 0.0002) # 插值範圍不能超過原資料的最小最大值 func = interpolate.interp1d(x, pred_y, kind='cubic') # kind方法:zero、slinear、quadratic、cubic new_y = func(new_x) # 畫圖 plt.plot(new_x, new_y, label='degree' + str(i)) plt.legend() plt.axis([0, 1, -1.5, 2]) # 設定橫軸縱軸長度 plt.show()
最後得到擬合曲線如下所示:
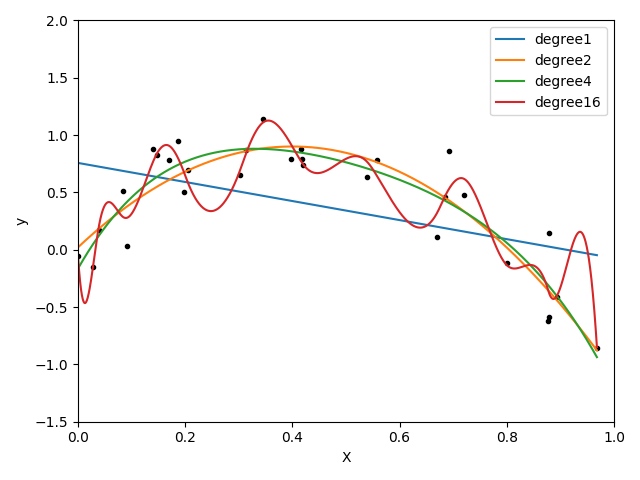 

為了畫圖好看,我用插值方法畫出了更平滑的曲線,使用方法在程式碼中都有註釋,完整程式碼可以訪問我的github。
最後總結一下,隨著多項式維度的增加,對於這些點的擬合情況逐漸變好,甚至趨於“變形”。這種模型的泛化能力不會太好。憑心而論,我覺得在\(deg=6\)左右的情況下,擬合效果可能會比較好。有興趣試驗的小夥伴可以在make_data生成更多的資料,然後使用交叉驗證測試一下