
Knative 基本功能深入剖析:Knative Serving 自動擴縮容 Autoscaler
Knative Serving 預設情況下,提供了開箱即用的快速、基於請求的自動擴縮容功能 - Knative Pod Autoscaler(KPA)。下面帶你體驗如何在 Knative 中玩轉 Autoscaler。
Autoscaler 機制
Knative Serving 為每個 POD 注入 QUEUE 代理容器 (queue-proxy),該容器負責向 Autoscaler 報告使用者容器併發指標。Autoscaler 接收到這些指標之後,會根據併發請求數及相應的演算法,調整 Deployment 的 POD 數量,從而實現自動擴縮容。
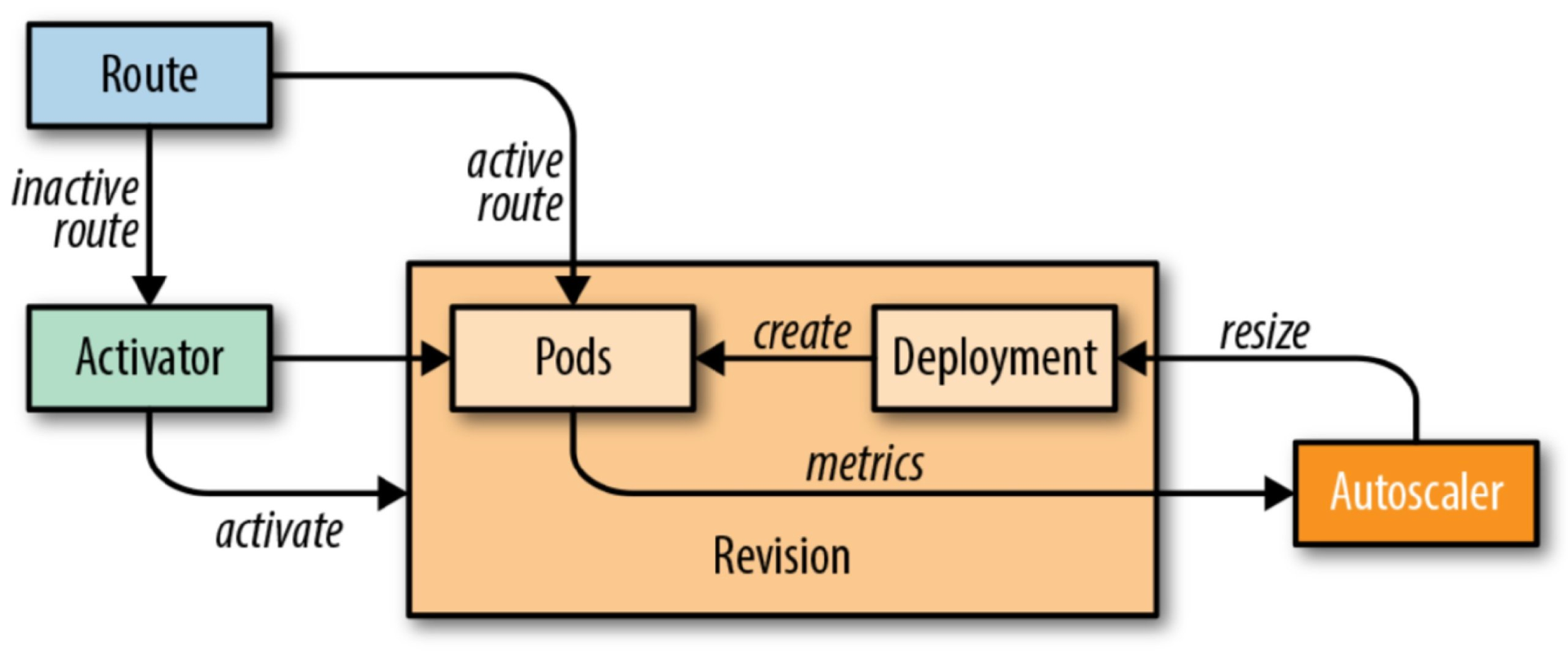
演算法
Autoscaler 基於每個 POD 的平均請求數(併發數)進行擴所容處理。預設併發數為 100。<br />POD 數=併發請求總數/容器併發數
如果服務中併發數設定了 10,這時候如果載入了 50 個併發請求的服務,Autoscaler 就會建立了 5 個 POD (50 個併發請求/10=POD)。
Autoscaler 實現了兩種操作模式的縮放演算法:Stable(穩定模式)和 Panic(恐慌模式)。
穩定模式
在穩定模式下,Autoscaler 調整 Deployment 的大小,以實現每個 POD 所需的平均併發數。 POD 的併發數是根據 60 秒視窗內接收所有資料請求的平均數來計算得出。
恐慌模式
Autoscaler 計算 60 秒視窗內的平均併發數,系統需要 1 分鐘穩定在所需的併發級別。但是,Autoscaler 也會計算 6 秒的恐慌視窗,如果該視窗達到目標併發的 2 倍,則會進入恐慌模式。在恐慌模式下,Autoscaler 在更短、更敏感的緊急視窗上工作。一旦緊急情況持續 60 秒後,Autoscaler 將返回初始的 60 秒穩定視窗。
| Panic Target---> +--| 20 | | | <------Panic Window | | Stable Target---> +-------------------------|--| 10 CONCURRENCY | | | | <-----------Stable Window | | | --------------------------+-------------------------+--+ 0 120 60 0 TIME
配置 KPA
通過上面的介紹,我們對 Knative Pod Autoscaler 工作機制有了初步的瞭解,那麼接下來介紹如何配置 KPA。在 Knative 中配置 KPA 資訊,需要修改 k8s 中的 ConfigMap:config-autoscaler,該 ConfigMap 在 knative-serving 名稱空間下。檢視 config-autoscaler 使用如下命令:
kubectl -n knative-serving get cm config-autoscaler
預設的 ConfigMap 如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: 100
container-concurrency-target-percentage: 1.0
enable-scale-to-zero: true
enable-vertical-pod-autoscaling: false
max-scale-up-rate: 10
panic-window: 6s
scale-to-zero-grace-period: 30s
stable-window: 60s
tick-interval: 2s
為 KPA 配置縮容至 0
為了正確配置使 Revision 縮容為 0,需要修改 ConfigMap 中的如下引數。
scale-to-zero-grace-period
scale-to-zero-grace-period 表示在縮為 0 之前,inactive revison 保留的執行時間(最小是3 0s)。
scale-to-zero-grace-period: 30s
stable-window
當在 stable mode 模式執行中,autoscaler 在穩定視窗期下平均併發數下的操作。
stable-window: 60s
stable-window 同樣可以配置在 Revision 註釋中。
autoscaling.knative.dev/window: 60s
enable-scale-to-zero
保證 enable-scale-to-zero 引數設定為 true<br />
Termination period
Termination period(終止時間)是 POD 在最後一個請求完成後關閉的時間。POD 的終止週期等於穩定視窗值和縮放至零寬限期引數的總和。在本例中,Termination period 為 90 秒。<br />
配置併發數
可以使用以下方法配置 Autoscaler 的併發數:
target
target 定義在給定時間(軟限制)需要多少併發請求,是 Knative 中 Autoscaler 的推薦配置。
在 ConfigMap 中預設配置的併發 target 為 100。
`container-concurrency-target-default: 100`
這個值可以通過 Revision 中的 autoscaling.knative.dev/target 註釋進行修改:
autoscaling.knative.dev/target: 50
containerConcurrency
注意:只有在明確需要限制在給定時間有多少請求到達應用程式時,才應該使用 containerConcurrency (容器併發)。只有當應用程式需要強制的併發約束時,才建議使用 containerConcurrency。
containerConcurrency 限制在給定時間允許併發請求的數量(硬限制),並在 Revision 模板中配置。
containerConcurrency: 0 | 1 | 2-N
- 1: 將確保一次只有一個請求由 Revision 給定的容器例項處理;
- 2-N: 請求的併發值限制為2或更多;
- 0: 表示不作限制,有系統自身決定。
配置擴縮容邊界(minScale 和 maxScale)
通過 minScale 和 maxScale 可以配置應用程式提供服務的最小和最大 Pod 數量。通過這兩個引數配置可以控制服務冷啟動或者控制計算成本。
minScale 和 maxScale 可以在 Revision 模板中按照以下方式進行配置:
spec:
template:
metadata:
autoscaling.knative.dev/minScale: "2"
autoscaling.knative.dev/maxScale: "10"
通過在 Revision 模板中修改這些引數,將會影響到 PodAutoscaler 物件,這也表明在無需修改 Knative Serving 系統配置的情況下,PodAutoscaler 物件是可被修改的。
edit podautoscaler <revision-name>
注意:這些註釋適用於 Revision 的整個生命週期。即使 Revision 沒有被任何 route 引用,minscale 指定的最小 POD 計數仍將提供。請記住,不可路由的 Revision 可能被垃圾收集掉。
預設情況
如果未設定 minscale 註釋,pods 將縮放為零(如果根據上面提到的 configmap,enable-scale-to-zero 為 false,則縮放為 1)。
如果未設定 maxscale 註釋,則建立的 Pod 數量將沒有上限。
基於 KPA 配置的示例
Knative 0.7 版本部署安裝可以參考:阿里雲部署 Knative
我們使用官方提供的 autoscale-go 示例來進行演示,示例 service.yaml 如下:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: autoscale-go
namespace: default
spec:
template:
metadata:
labels:
app: autoscale-go
annotations:
autoscaling.knative.dev/target: "10"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1
獲取訪問閘道器:
$ kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"
121.199.194.150
Knative 0.7 版本中獲取域名資訊:
$ kubectl get route autoscale-go --output jsonpath="{.status.url}"| awk -F/ '{print $3}'
autoscale-go.default.example.com
場景1:併發請求示例
如上配置,當前最大併發請求數 10。 我們執行 30s 內保持 50 個併發請求,看一下執行情況:
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.194.150?sleep=100&prime=10000&bloat=5"
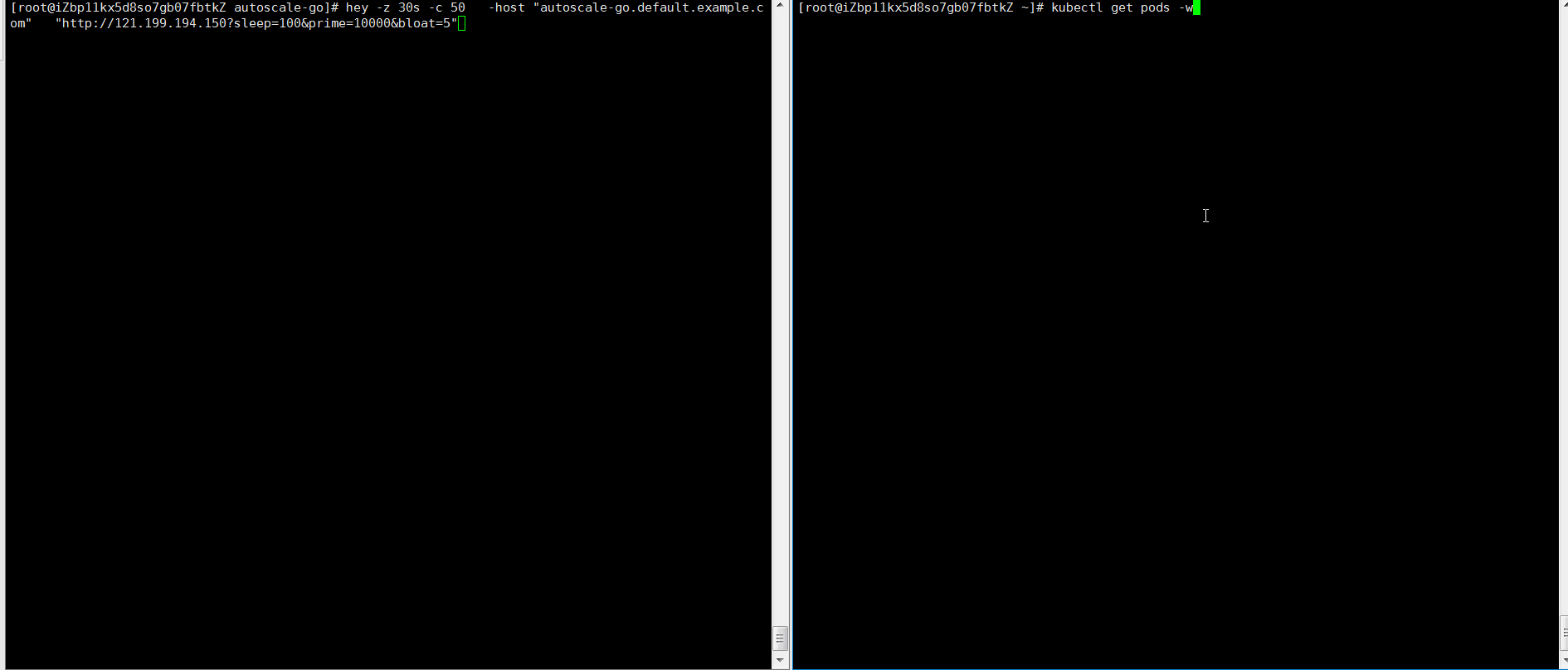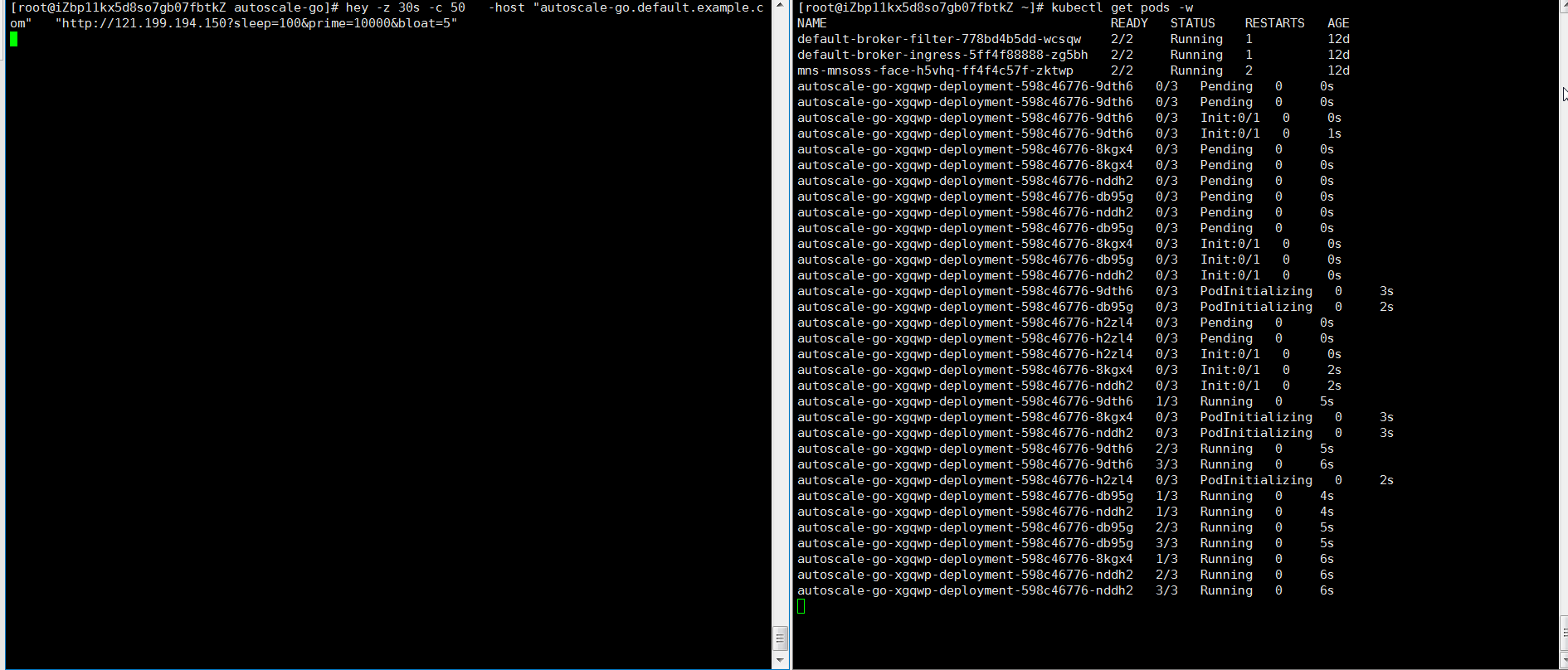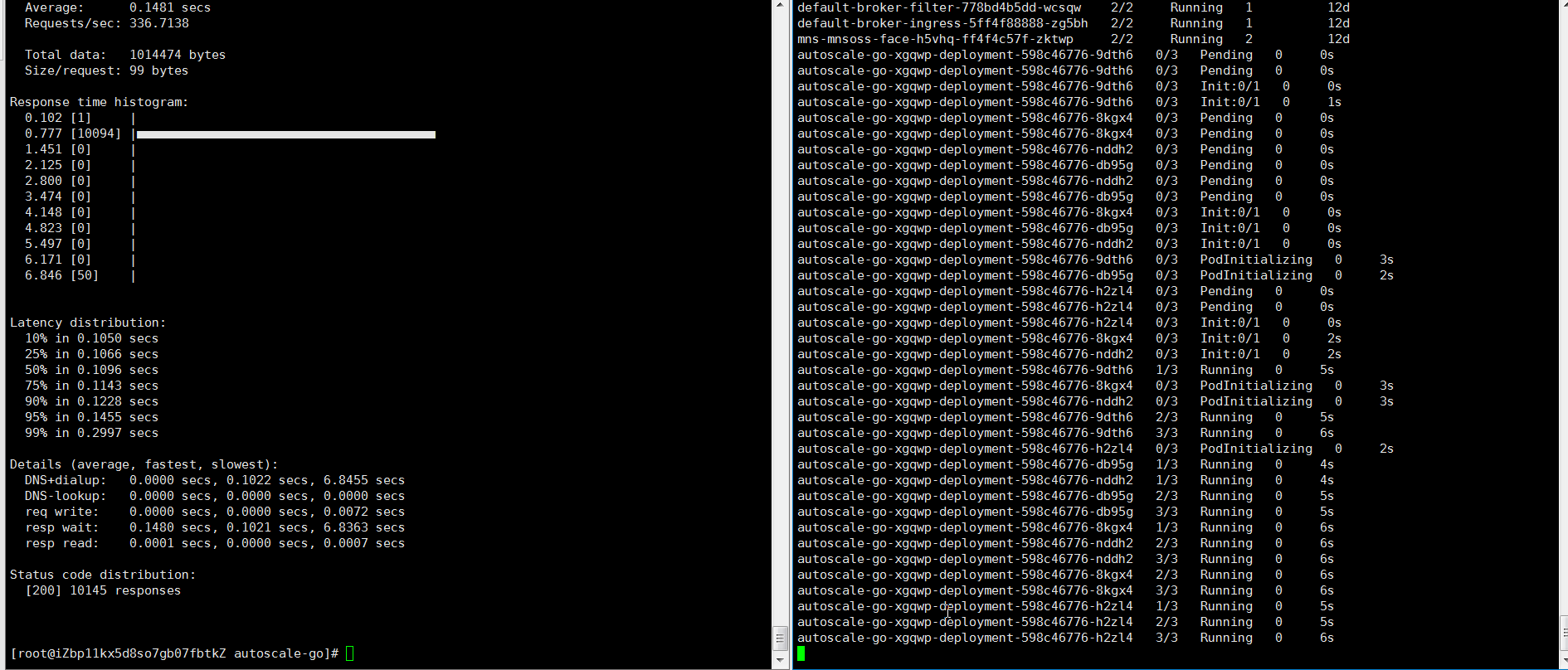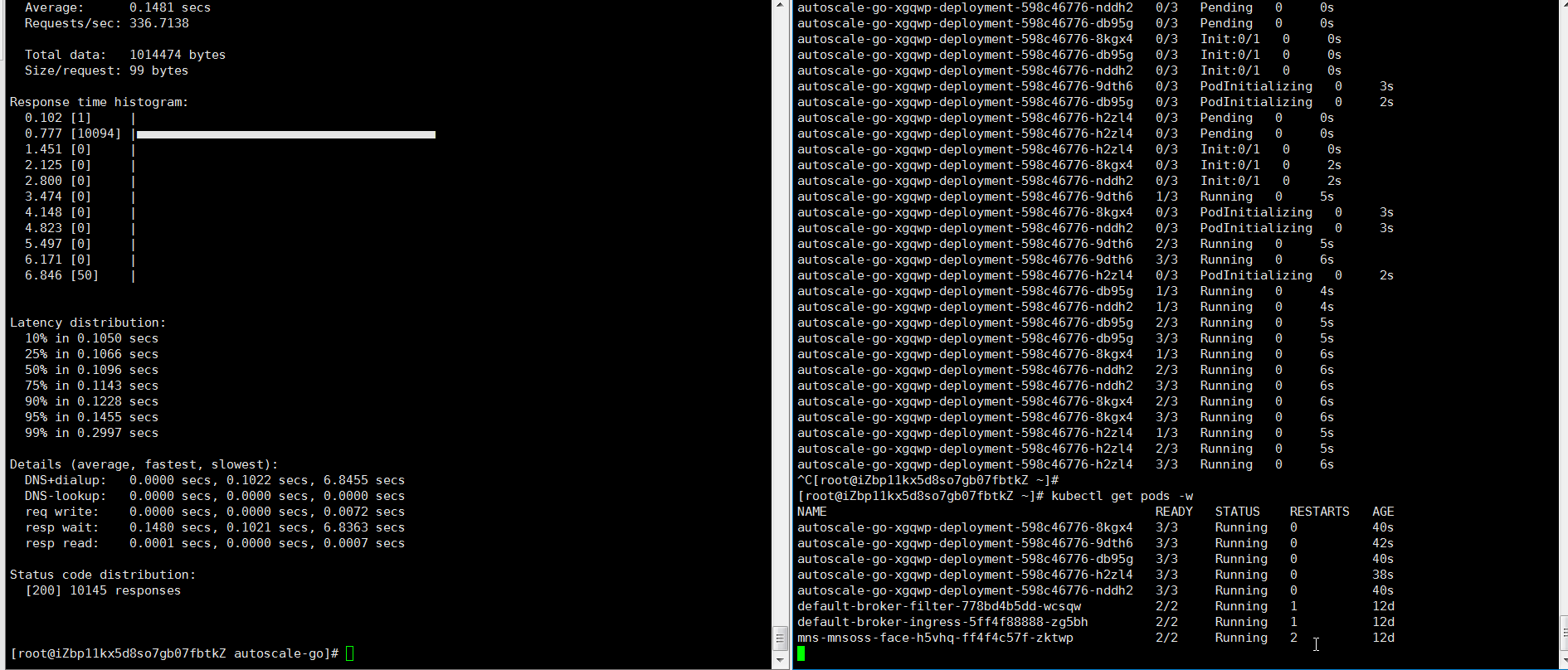
結果正如我們所預期的:擴容出來了 5 個 POD。
場景2:擴縮容邊界示例
修改一下 servcie.yaml 配置如下:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: autoscale-go
namespace: default
spec:
template:
metadata:
labels:
app: autoscale-go
annotations:
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/minScale: "1"
autoscaling.knative.dev/maxScale: "3"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1
當前最大併發請求數 10,minScale 最小保留例項數為 1,maxScale 最大擴容例項數為 3。
我們依然執行 30s 內保持 50 個併發請求,看一下執行情況:
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.194.150?sleep=100&prime=10000&bloat=5"

結果如我們所預期:最多擴容出來了 3 個POD,並且即使在無訪問請求流量的情況下,保持了 1 個執行的 POD。
結論
看了上面的介紹,是不是感覺在 Knative 中配置應用擴縮容是如此簡單?其實 Knative 中除了支援 KPA 之外,也支援K8s HPA。你可以通過如下配置基於 CPU 的 Horizontal POD Autoscaler(HPA)。
通過在修訂模板中新增或修改 autoscaling.knative.dev/class 和 autoscaling.knative.dev/metric 值作為註釋,可以將Knative 配置為使用基於 CPU 的自動縮放,而不是預設的基於請求的度量。配置如下:
spec:
template:
metadata:
autoscaling.knative.dev/metric: concurrency
autoscaling.knative.dev/class: hpa.autoscaling.knative.dev
你可以自由的將 Knative Autoscaling 配置為使用預設的 KPA 或 Horizontal POD A