
13.深入k8s:Pod 水平自動擴縮HPA及其原始碼分析
阿新 • • 發佈:2020-10-04

> 轉載請宣告出處哦~,本篇文章釋出於luozhiyun的部落格:https://www.luozhiyun.com
>
> 原始碼版本是[1.19](https://github.com/kubernetes/kubernetes/tree/release-1.19)
## Pod 水平自動擴縮
### Pod 水平自動擴縮工作原理
Pod 水平自動擴縮全名是Horizontal Pod Autoscaler簡稱HPA。它可以基於 CPU 利用率或其他指標自動擴縮 ReplicationController、Deployment 和 ReplicaSet 中的 Pod 數量。
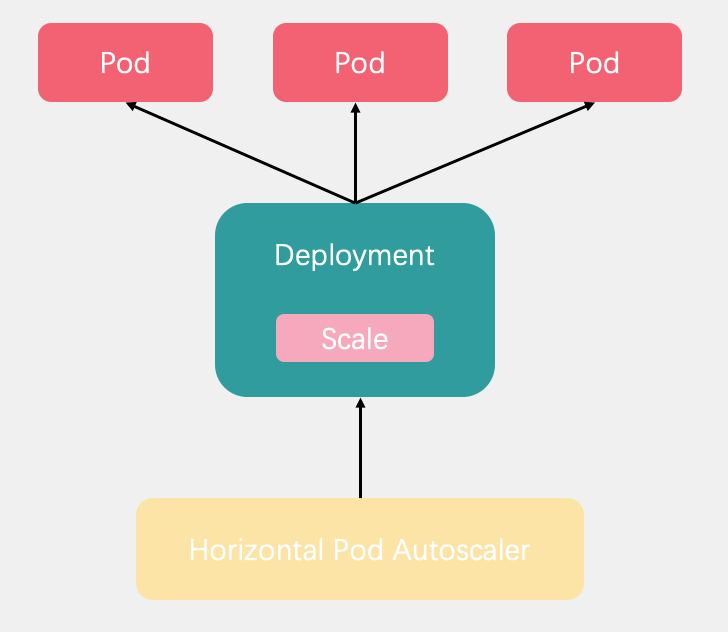
Pod 水平自動擴縮器由--horizontal-pod-autoscaler-sync-period 引數指定週期(預設值為 15 秒)。每個週期內,控制器管理器根據每個 HorizontalPodAutoscaler 定義中指定的指標查詢資源利用率。
Pod 水平自動擴縮控制器跟據當前指標和期望指標來計算擴縮比例,公式為:
```
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
```
currentReplicas表示當前度量值,desiredMetricValue表示期望度量值,desiredReplicas表示期望副本數。例如,當前度量值為 200m,目標設定值為 100m,那麼由於 200.0/100.0 == 2.0, 副本數量將會翻倍。 如果當前指標為 50m,副本數量將會減半,因為50.0/100.0 == 0.5。
我們可以通過使用kubectl來建立HPA。如通過 kubectl create 命令建立一個 HPA 物件, 通過 kubectl get hpa 命令來獲取所有 HPA 物件, 通過 kubectl describe hpa 命令來檢視 HPA 物件的詳細資訊。 最後,可以使用 kubectl delete hpa 命令刪除物件。
也可以通過kubectl autoscale來建立 HPA 物件。 例如,命令 kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80 將會為名 為 foo 的 ReplicationSet 建立一個 HPA 物件, 目標 CPU 使用率為 80%,副本數量配置為 2 到 5 之間。
如果指標變化太頻繁,我們也可以使用`--horizontal-pod-autoscaler-downscale-stabilization`指令設定擴縮容延遲時間,表示的是自從上次縮容執行結束後,多久可以再次執行縮容,預設是5m。
### Pod 水平自動擴縮示例
編寫用於測試的Deployment:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpatest
spec:
replicas: 1
selector:
matchLabels:
app: hpatest
template:
metadata:
labels:
app: hpatest
spec:
containers:
- name: hpatest
image: nginx
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args: ["-c","/usr/sbin/nginx; while true;do echo `hostname -I` > /usr/share/nginx/html/index.html; sleep 120;done"]
ports:
- containerPort: 80
resources:
requests:
cpu: 1m
memory: 100Mi
limits:
cpu: 3m
memory: 400Mi
---
apiVersion: v1
kind: Service
metadata:
name: hpatest-svc
spec:
selector:
app: hpatest
ports:
- port: 80
targetPort: 80
protocol: TCP
```
編寫HPA,用於水平擴充套件,當cpu達到50%的利用率的時候開始擴充套件:
```yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: haptest-nginx
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpatest
minReplicas: 2
maxReplicas: 6
targetCPUUtilizationPercentage: 50
```
寫一個簡單的壓測指令碼:
```sh
[root@localhost HPA]# vim hpatest.sh
while true
do
wget -q -O- http://10.68.50.65
done
```
觀察一下hpa的TARGETS情況:
```sh
[root@localhost ~]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpatest Deployment/hpatest 0%/50% 1 5 1 5m47s
hpatest Deployment/hpatest 400%/50% 1 5 1 5m49s
hpatest Deployment/hpatest 400%/50% 1 5 4 6m4s
hpatest Deployment/hpatest 400%/50% 1 5 5 6m19s
hpatest Deployment/hpatest 500%/50% 1 5 5 6m49s
```
觀察是否會自動擴容:
```sh
[root@localhost ~]# kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hpatest-bbb44c476-jv8zr 0/1 ContainerCreating 0 0s 192.168.13.130
hpatest-bbb44c476-sk6qb 0/1 ContainerCreating 0 0s 192.168.13.130
hpatest-bbb44c476-7s5qn 0/1 ContainerCreating 0 0s 192.168.13.130
hpatest-bbb44c476-7s5qn 1/1 Running 0 6s 172.20.0.23 192.168.13.130
hpatest-bbb44c476-sk6qb 1/1 Running 0 6s 172.20.0.22 192.168.13.130
hpatest-bbb44c476-jv8zr 1/1 Running 0 6s 172.20.0.21 192.168.13.130
hpatest-bbb44c476-dstnf 0/1 Pending 0 0s
hpatest-bbb44c476-dstnf 0/1 Pending 0 0s 192.168.13.130
hpatest-bbb44c476-dstnf 0/1 ContainerCreating 0 0s 192.168.13.130
hpatest-bbb44c476-dstnf 1/1 Running 0 6s 172.20.0.24 192.168.13.130
```
停止壓測之後,HPA開始自動縮容:
```sh
[root@localhost HPA]# kubectl get pod -w
hpatest-bbb44c476-dstnf 0/1 Terminating 0 9m52s
hpatest-bbb44c476-jv8zr 0/1 Terminating 0 10m
hpatest-bbb44c476-7s5qn 0/1 Terminating 0 10m
hpatest-bbb44c476-sk6qb 0/1 Terminating 0 10m
hpatest-bbb44c476-sk6qb 0/1 Terminating 0 10m
hpatest-bbb44c476-dstnf 0/1 Terminating 0 10m
hpatest-bbb44c476-dstnf 0/1 Terminating 0 10m
hpatest-bbb44c476-7s5qn 0/1 Terminating 0 10m
hpatest-bbb44c476-7s5qn 0/1 Terminating 0 10m
hpatest-bbb44c476-jv8zr 0/1 Terminating 0 10m
hpatest-bbb44c476-jv8zr 0/1 Terminating 0 10m
```
## 原始碼分析
### 初始化
檔案位置:cmd/kube-controller-manager/app/controllermanager.go
```go
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {
...
controllers["horizontalpodautoscaling"] = startHPAController
...
}
```
HPA Controller和其他的Controller一樣,都在NewControllerInitializers方法中進行註冊,然後通過startHPAController來啟動。
#### startHPAController
檔案位置:cmd/kube-controller-manager/app/autoscaling.go
```go
func startHPAController(ctx ControllerContext) (http.Handler, bool, error) {
...
return startHPAControllerWithLegacyClient(ctx)
}
func startHPAControllerWithLegacyClient(ctx ControllerContext) (http.Handler, bool, error) {
hpaClient := ctx.ClientBuilder.ClientOrDie("horizontal-pod-autoscaler")
metricsClient := metrics.NewHeapsterMetricsClient(
hpaClient,
metrics.DefaultHeapsterNamespace,
metrics.DefaultHeapsterScheme,
metrics.DefaultHeapsterService,
metrics.DefaultHeapsterPort,
)
return startHPAControllerWithMetricsClient(ctx, metricsClient)
}
func startHPAControllerWithMetricsClient(ctx ControllerContext, metricsClient metrics.MetricsClient) (http.Handler, bool, error) {
hpaClient := ctx.ClientBuilder.ClientOrDie("horizontal-pod-autoscaler")
hpaClientConfig := ctx.ClientBuilder.ConfigOrDie("horizontal-pod-autoscaler")
scaleKindResolver := scale.NewDiscoveryScaleKindResolver(hpaClient.Discovery())
scaleClient, err := scale.NewForConfig(hpaClientConfig, ctx.RESTMapper, dynamic.LegacyAPIPathResolverFunc, scaleKindResolver)
if err != nil {
return nil, false, err
}
// 初始化
go podautoscaler.NewHorizontalController(
hpaClient.CoreV1(),
scaleClient,
hpaClient.AutoscalingV1(),
ctx.RESTMapper,
metricsClient,
ctx.InformerFactory.Autoscaling().V1().HorizontalPodAutoscalers(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerSyncPeriod.Duration,
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerDownscaleStabilizationWindow.Duration,
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerTolerance,
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerCPUInitializationPeriod.Duration,
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerInitialReadinessDelay.Duration,
).Run(ctx.Stop)
return nil, true, nil
}
```
最後會呼叫到startHPAControllerWithMetricsClient方法,啟動一個執行緒來呼叫NewHorizontalController方法初始化一個HPA Controller,然後執行Run方法。
#### Run
檔案位置:pkg/controller/podautoscaler/horizontal.go
```go
func (a *HorizontalController) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer a.queue.ShutDown()
klog.Infof("Starting HPA controller")
defer klog.Infof("Shutting down HPA controller")
if !cache.WaitForNamedCacheSync("HPA", stopCh, a.hpaListerSynced, a.podListerSynced) {
return
}
// 啟動非同步執行緒,每秒執行一次
go wait.Until(a.worker, time.Second, stopCh)
<-stopCh
}
```
這裡會呼叫worker執行具體的擴縮容的邏輯。
### 核心程式碼分析
worker裡面一路執行下來會走到reconcileAutoscaler方法裡面,這裡是HPA的核心。下面我們專注看看這部分。
#### reconcileAutoscaler:計算副本數
```go
func (a *HorizontalController) reconcileAutoscaler(hpav1Shared *autoscalingv1.HorizontalPodAutoscaler, key string) error {
...
//副本數為0,不啟動自動擴縮容
if scale.Spec.Replicas == 0 && minReplicas != 0 {
// Autoscaling is disabled for this resource
desiredReplicas = 0
rescale = false
setCondition(hpa, autoscalingv2.ScalingActive, v1.ConditionFalse, "ScalingDisabled", "scaling is disabled since the replica count of the target is zero")
// 如果當前副本數大於最大期望副本數,那麼設定期望副本數為最大副本數
} else if currentReplicas >