
最先進模型指南:NLP中的Transformers如何運作?
全文共5257字,預計學習時長11分鐘或更長
通過閱讀本篇文章,你將理解:
· NLP中的Transformer模型真正改變了處理文字資料的方式。
· Transformer支援NLP的最新變化,包括谷歌的BERT。
· 瞭解Transformer的運作規律,如何進行語言建模、序列到序列建模以及如何構建Google的BERT模型。
下面,我們開始學習吧!

圖片來源:pexels/Dominika Roseclay
當前,自然語言處理(NLP)的技術正以前所未有的速度發展。從超高效的ULMFiT框架到谷歌的BERT,NLP的確處於發展的黃金時代。
這場革命的核心就是Transformer概念,它改變了資料科學家使用文字資料的方式,下文將做具體介紹。
要舉個例子證明Transformer的實用嗎?請看下一段:

突出顯示的詞語指的是同一個人——Grieamann,一名受歡迎的足球運動員。對人類而言,弄清楚文字中這些詞之間的關係並不困難。然而,對於一臺機器來說,這是一項艱鉅的任務。
機器要想理解自然語言,明確句子中的此類關係和詞語序列至關重要。而Transformer 概念會在其中發揮重要作用。
目錄
1. 序列到序列模型——背景
· 基於序列到序列模型的迴圈神經網路
· 挑戰
2. NLP中的Transformer簡介
· 理解模型框架
· 獲得自注意力
· 計算自注意力
· Transformer的侷限
3. 瞭解Transformer-XL
· 使用Transformer進行語言建模
· 使用Transformer-XL進行語言建模
4. NLP中的新嘗試:Google的BERT
· 模型框架
· BERT訓練前的任務
序列到序列模型——背景
NLP中的序列到序列(seq2seq)模型用於將A型別的序列轉換為B型別的序列。例如,把英語句子翻譯成德語句子就是序列到序列的任務。
自2014年引進以來,基於seq2seq模型的迴圈神經網路(RNN)已經獲得了很多關注。當前世界的大多數資料都是序列形式,包括數字序列、文字序列、視訊幀序列和音訊序列。
2015年,seq2seq模型增加了注意力機制,使效能得到進一步提升。過去5年來NLP發展速度之快,簡直令人難以置信!
這些序列到序列模型用途非常廣泛,適用於各種NLP任務,例如:
· 機器翻譯
· 文字摘要
· 語音識別
· 問答系統等
基於seq2seq模型的迴圈神經網路
舉一個關於seq2seq模型的簡單例子。請看下圖:
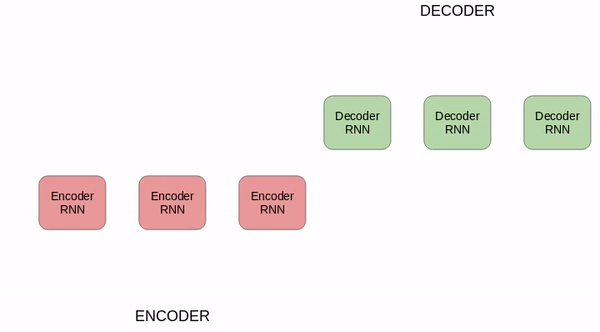
上方的seq2seq模型正將德語短語轉換為英語短語。下面進行分解:
· 編碼器和解碼器都是迴圈神經網路。
· 在編碼器中的每一步,迴圈神經網路會從輸入序列中獲取一個字向量(xi),並從上一個時間步驟中獲取一隱藏狀態(Hi)。
· 隱藏狀態會在每個時間步驟更新。
· 最後一個單元的隱藏狀態稱為上下文向量,包含有關輸入序列的資訊。
· 將上下文向量傳給解碼器,生成目標序列(英語短語)。
· 如果使用注意力機制,則隱藏狀態的加權之和將作為上下文向量傳給解碼器。
挑戰
儘管seq-2-seq模型表現良好,但仍存在一定的侷限性:
· 處理長時依賴仍頗具挑戰性。
· 模型框架的順序阻止了並行化。而Google Brain的Transformer概念解決了這一挑戰。
NLP中的Transformer簡介
NLP中的Transformer是全新的框架,旨在解決序列到序列的任務,同時輕鬆處理長時依賴。Transformer是由Attention Is All You Need這篇論文提出的。建議對NLP感興趣的人閱讀該論文。
論文傳送門:https://arxiv.org/abs/1706.03762
引自該論文:
Transformer是首個完全依靠自注意力來計算其輸入和輸出表示,而不使用序列對齊的迴圈神經網路或卷積的轉換模型。
此處,“轉換”是指將輸入序列轉換成輸出序列。Transformer的建立理念是通過注意和重複,徹底處理輸入和輸出之間的依賴關係。
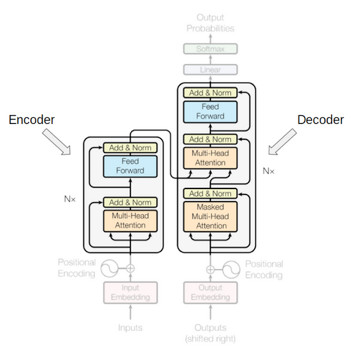
下面請看Transformer的框架。它可能看起來令人生畏,但不要擔心,下面將進行分解,以便逐塊理解。
理解Transformer的模型框架
圖片來源: https://arxiv.org/abs/1706.03762
上圖是Transformer框架的精彩插圖。首先只需關注編碼器和解碼器的部分。
現在看看下圖。編碼器塊具有一多頭注意力層,然後另一層是前饋神經網路。而解碼器具有額外的遮擋式多頭注意力層。
編碼器和解碼器塊實際上是由多個相同的編碼器和解碼器彼此堆疊而成的。編碼器堆疊和解碼器堆疊具有相同數量的單元。
編碼器和解碼器單元的數量是超引數的。在本文中,使用了6個編碼器和解碼器。
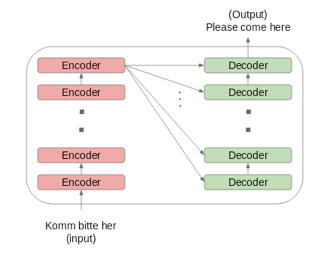
如何設定編碼器和解碼器堆疊:
· 將輸入序列的嵌入詞傳給第一個編碼器。
· 然後進行轉換並傳給下一個編碼器。
· 將編碼器堆疊中最後一個編碼器的輸出傳給解碼器堆疊中的所有解碼器,如下圖所示:
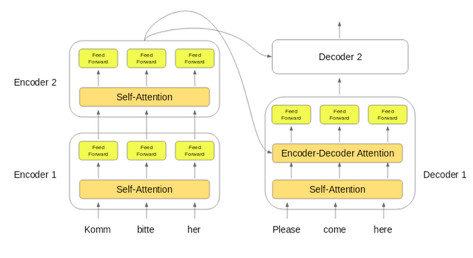
此處需要注意的重要事項——除了自注意力和前饋層外,解碼器還有一層編碼器——解碼器注意層。這有助於解碼器聚焦於輸入序列的適當部分。
你可能會想這個“自注意力”層究竟在Transformer中做了什麼?好問題!這可以說是整個設定中最重要的組成部分,所以首先要理解這個概念。
獲得自注意力
根據該論文:
自注意力,有時稱為內部注意力,是注意力機制,其關聯單個序列的不同位置以計算序列的表示。

請看上方圖片,你能弄清楚這句話中的“it”這個詞的意思嗎?
“it”指的是街道還是動物?對人們來說,這是個簡單的問題。但對於演算法而言,並非如此。模型處理“它”一詞時,自注意力試圖將“它”與同一句子中的“animal”聯絡起來。
自注意力允許模型檢視輸入序列中的其他詞語,以更好地理解序列中的某個詞語。現在,請看如何計算自注意力。
計算自注意力
為便於理解,筆者將此節分為以下步驟。
1. 首先,需要從編碼器的每個輸入向量中建立三個向量:
· 查詢向量
· 關鍵向量
· 價值向量
訓練過程中會訓練和更新這些向量。看完本節後,將更加了解其作用。
2. 接下來,將計算輸入序列中每個詞語的自注意力。
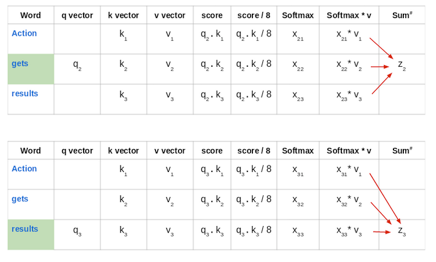
3. 以“Action gets results”這一短語為例。為計算第一個單詞“Action”的自注意力,將計算短語中與“Action”相關的所有單詞的分數。當對輸入序列中某個單詞編碼時,該分數將確定其他單詞的重要性。
第一個單詞的得分是通過將查詢向量(q1)的點積與所有單詞的關鍵向量(k1,k2,k3)進行計算得出的:
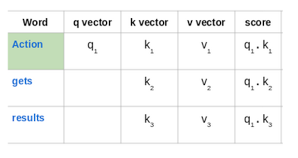
然後,將這些得分除以8,即關鍵向量維數的平方根:
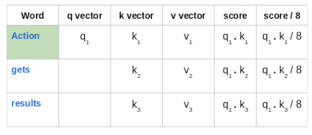
接下來,使用softmax啟用函式使這些分數標準化:
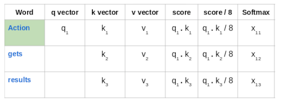
然後將這些標準化後的分數乘以價值向量(v1,v2,v3),並將其相加,得到最終向量(z1)。這是自注意力層的輸出。然後將其作為輸入傳給前饋網路:
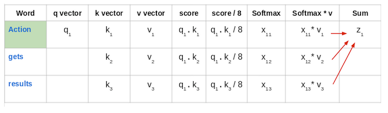
因此,z1是輸入序列“Action gets results”的首個單詞的自注意力向量。以相同的方式獲取輸入序列中其餘單詞的向量:
在Transformer的框架中,多次而非一次並行或獨立地計算自注意力。因此,自注意力被稱為多頭注意力。輸出的連線與線性轉換如下圖所示:
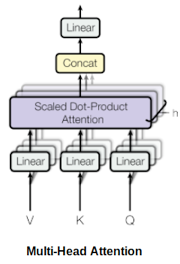
根據論文:
多頭注意力允許模型共同關注來自不同位置的、不同子空間表示的資訊。
Transformer的侷限
Transformer無疑是對基於迴圈神經網路的seq2seq模型的巨大改進。但其本身有一些侷限:
· 注意力只能處理固定長度的文字字串。在作為輸入進入饋入系統前,必須將文字分成一定數量的段或塊。
· 這種文字分塊會導致上下文碎片化。例如,如果句子從中間分割,則會丟失大量上下文。換句話說,文字分塊時,未考慮句子或其他語義邊界。
那麼如何處理這些非常重要的問題呢?這是與Transformer合作的人們提出的問題,在此基礎上產生了Transformer-XL。
瞭解Transformer-XL
Transformer 框架可習得長時依賴性。但由於使用了固定長度的上下文(輸入文字段),框架無法超出一定的水平。為克服這一缺點,提出了一種新的框架——Transformer-XL:超出固定長度上下文的注意語言模型。
在該框架中,前段中獲得的隱藏狀態被再次用作當前段的資訊源。它可以建模長時依賴性,因為資訊可從一段流向下一段。
使用Transformer進行語言建模
將語言建模視為在給定前一單詞後,估計下一單詞概率的過程。
Al-Rfou等人 (2018)提出了將Transformer模型應用於語言建模的想法。根據該論文,整個語料庫應依照可管理能力,劃分固定長度段。然後,在段上單獨訓練Transformer模型,忽略所有來自前段的上下文資訊:
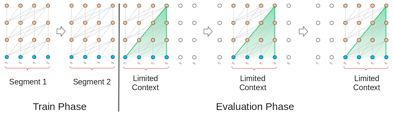
圖片來源:https://arxiv.org/abs/1901.02860
這種框架不會出現消失梯度的問題。但語境碎片限制了其習得長期依賴性。在評估階段,該段僅會向右移動一個位置。新段必須完全從頭開始處理。遺憾的是,這種評估方法計算量非常大。
使用Transformer-XL進行語言建模
在Transformer-XL的訓練階段,之前狀態計算的隱藏狀態被用作當前段的附加上下文。Transformer-XL的這種重複機制解決了使用固定長度上下文的限制。
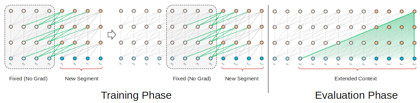
在評估階段,可重複使用前段的表示,而非從頭開始計算(如Transformer模型)。當然,這會提高計算速度。
NLP中的新嘗試:Google的BERT(來自Transformers雙向編碼器的表示)
眾所周知遷移學習在計算機視覺領域的重要性。例如,可針對ImageNet資料集上的新任務微調預訓練的深度學習模型,並仍然可在相對較小的標記資料集上得到適當的結果。
同樣,語言模型預訓練可有效改進許多自然語言處理任務。
傳送門:https://paperswithcode.com/paper/transformer-xl-attentive-language-models
BERT框架是Google AI新的語言表示模型,可進行預訓練和微調,為各種任務建立最先進的模型。這些任務包括問答系統、情感分析和語言推理。
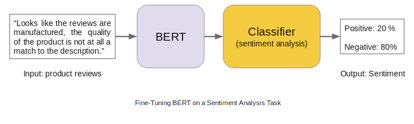
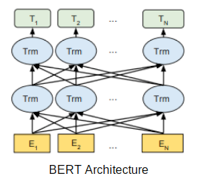
BERT的模型框架
BERT使用多層雙向Transformer編碼器。其自注意力層在兩個方向上都有自注意力。谷歌釋出了該模型的兩個變體:
1BERT Base:Transformers 層數 = 12, 總引數 = 110M
2BERT Large:Transformers 層數 = 24, 總引數 = 340M
BERT通過雙向性完成幾項任務的預訓練——遮擋式語言模型和下一句預測。下面將詳細討論這兩項任務。
BERT訓練前的任務
使用以下兩個無人監督的預測任務對BERT進行預訓練。
1. 遮擋式語言模型(MLM)
根據該論文:
遮擋式語言模型隨機地從輸入中遮擋了一些標記,目的是僅根據其上下文,預測被遮擋單詞的原始詞彙。與從左到右的語言模型預訓練不同,MLM目標允許表示融合左右的上下文,這使我們可以對雙向Transformer進行深度預訓練。
Google AI研究人員隨機遮擋每個序列中15%的單詞。任務是什麼呢?預測這些被遮擋的單詞。需要注意——遮擋的單詞並非總是帶有遮擋的標記[MASK],因為在微調期間不會出現[MASK]標記。
因此,研究人員使用以下方法:
· 80%的單詞帶有被遮擋的標記[MASK]
· 10%的單詞被隨機單詞替換
· 10%的單詞保持不變
2. 下一句話預測
通常,語言模型不會理解連續句子間的關係。BERT也接受過這項任務的預訓練。
對於語言模型預訓練,BERT使用成對的句子作為其訓練資料。每對句子的選擇非常有趣。舉個例子,以便更好地理解。
假設一個文字資料集有100,000個句子,想要使用這個資料集對BERT語言模型進行預訓練。因此,將有50,000個訓練樣例或50,000對句子作為訓練資料。
· 50%的句對中,第二句實際上是第一句的下一句。
· 其餘50%的句對,第二句是來自語料庫的隨機句子。
· 第一種情況的標籤將成為第二種情況的'IsNext'和'NotNext'。
像BERT這樣的框架表明,無人監督學習(預訓練和微調)將成為許多語言理解系統的關鍵要素。低資源任務尤其可從這些深度雙向框架中獲得巨大收益。
下面是一些NLP任務的快照,BERT在其中扮演著重要角色:

圖片來源:https://arxiv.org/abs/1810.04805
我們應該很慶幸,在自己身處的時代裡,NLP發展如此迅速,Transformers和BERT這樣的架構正在為未來幾年更為先進的突破鋪平道路。
更多課程傳送門:https://courses.analyticsvidhya.com/courses/natural-language-processing-nlp??utm_source=blog&utm_medium=understanding-transformers-nlp-state-of-the-art-models
留言 點贊 關注
我們一起分享AI學習與發展的乾貨
歡迎關注全平臺AI垂類自媒體 “讀芯術”
(新增小編微信:dxsxbb,加入讀者圈,一起討論最新鮮的人工