
主題模型TopicModel:LDA中的數學模型
瞭解LDA需要明白如下數學原理:
一個函式:gamma函式
四個分佈:二項分佈、多項分佈、beta分佈、Dirichlet分佈
一個概念和一個理念:共軛先驗和貝葉斯框架
兩個模型:pLSA、LDA(文件-主題,主題-詞語)
一個取樣:Gibbs取樣
估計未知引數所採用的不同思想:頻率學派、貝葉斯學派
gamma函式
Gamma函式
通過分部積分的方法,可以推匯出這個函式有如下的遞迴性質
於是很容易證明,
1728年,哥德巴赫在考慮數列插值的問題,通俗的說就是把數列的通項公式定義從整數集合延拓到實數集合,例如數列

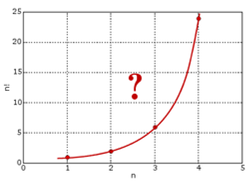
但是哥德巴赫無法解決階乘往實數集上延拓的這個問題,於是寫信請教尼古拉斯.貝努利和他的弟弟丹尼爾.貝努利,由於尤拉當時和丹尼爾.貝努利在一塊,他也因此得知了這個問題。而尤拉於1729 年完美的解決了這個問題,由此導致了
事實上首先解決
於是用這個無窮乘積的方式可以把
尤拉也偶然的發現
用極限形式,這個式子整理後可以寫為
左邊可以整理為
所以 (*)、(**)式都成立。
尤拉開始嘗試從一些簡單的例子開始做一些計算,看看是否有規律可循,尤拉極其擅長數學的觀察與歸納。當
相關推薦
主題模型TopicModel:LDA中的數學模型
瞭解LDA需要明白如下數學原理:一個函式:gamma函式四個分佈:二項分佈、多項分佈、beta分佈、Dirichlet分佈一個概念和一個理念:共軛先驗和貝葉斯框架兩個模型:pLSA、LDA(文件-主題,主題-詞語)一個取樣:Gibbs取樣估計未知引數所採用的不同思想:頻率學派
主題模型TopicModel:LDA的缺陷和改進
LDA的缺陷和改進 1. 短文字與LDA ICML論文有理論分析,文件太短確實不利於訓練LDA,但平均長度是10這個數量級應該是可以的,如peacock基於query 訓練模型。 有一些經驗技巧加工資料,譬如把同一session 的查詢拼接,同一個人的twitter 拼
主題模型TopicModel:LDA程式設計實現
LDA的python實現從0開始實現Shuyo的github程式碼:實現語言,Python,實現模型,LDA,Dirichlet Process Gaussian Mixture Model,online HDP,HDPLDA,Interactive Topic Model,
主題模型TopicModel:主題模型LDA的應用
主題模型LDA的應用拿到這些topic後繼續後面的這些應用怎麼做呢:除了推斷出這些主題,LDA還可以推斷每篇文章在主題上的分佈。例如,X文章大概有60%在討論“空間探索”,30%關於“電腦”,10%關於其他主題。這些主題分佈可以有多種用途:聚類: 主題是聚類中心,文章和多個類
主題模型TopicModel:通過gensim實現LDA
使用python gensim輕鬆實現lda模型。gensim簡介gemsim是一個免費python庫,能夠從文件中有效地自動抽取語義主題。gensim中的演算法包括:LSA(Latent Semantic Analysis), LDA(Latent Dirichlet Al
主題模型TopicModel:隱含狄利克雷分佈LDA
主題模型LDA簡介隱含狄利克雷分佈簡稱LDA(Latent Dirichlet allocation),首先由Blei, David M.、吳恩達和Jordan, Michael I於2003年提出,目前在文字挖掘領域包括文字主題識別、文字分類以及文字相似度計算方面都有應用。
主題模型TopicModel:Unigram、LSA、PLSA模型
主題模型歷史Papadimitriou、Raghavan、Tamaki和Vempala在1998年發表的一篇論文中提出了潛在語義索引。1999年,Thomas Hofmann又在此基礎上,提出了概率性潛在語義索引(Probabilistic Latent Semantic I
主題模型TopicModel:LSA(隱性語義分析)模型和其實現的早期方法SVD
傳統方法向量空間模型(VSM)的缺點傳統向量空間模型使用精確的詞匹配,即精確匹配使用者輸入的詞與向量空間中存在的詞。由於一詞多義(polysemy)和一義多詞(synonymy)的存在,使得該模型無法提供給使用者語義層面的檢索。比如使用者搜尋”automobile”,即汽車,
flask學習(十):模板中訪問模型和字典的屬性
src info .com 分享圖片 prop 學習 pan ram 使用 訪問模型中的屬性或者是字典,可以通過{{params.property}}的形式,或者是使用{{params[‘age‘]}}這樣的形式 flask學習(十):模板中訪問模型和字典的屬性
內容(content)、填充(padding)、邊框(border)、邊界(margin):CSS中盒子模型有何區別?
什麼是CSS的盒子模式呢?為什麼叫它是盒子?先說說我們在網頁設計中常聽的屬性名: 內容(content)、填充(padding)、邊框(border)、邊界(margin),CSS盒子模式都具備這些屬性。 一個盒子模型由 content(內容)、border(邊
最先進模型指南:NLP中的Transformers如何運作?
全文共5257字,預計學習時長11分鐘或更長 通過閱讀本篇文章,你將理解: · NLP中的Transformer模型真正改變了
以圖搜圖之模型篇: 基於 InceptionV3 的模型 finetune
cte nec inpu 大神 rms mode cto num 創建 在以圖搜圖的過程中,需要以來模型提取特征,通過特征之間的歐式距離來找到相似的圖形。 本次我們主要講訴以圖搜圖模型創建的方法。 本文主要參考了這位大神的文章, 傳送門在此: InceptionV3進行fi
Spark機器學習(8):LDA主題模型算法
算法 ets 思想 dir 骰子 cati em算法 第一個 不同 1. LDA基礎知識 LDA(Latent Dirichlet Allocation)是一種主題模型。LDA一個三層貝葉斯概率模型,包含詞、主題和文檔三層結構。 LDA是一個生成模型,可以用來生成一篇文
幽默感也有套路:可用數學模型量化
簡單的 urn pos 產生 衡量 證明 chris 打分 雜誌 摘自: https://wap.ithome.com/html/297978.htm 我們如何量化幽默感呢?它是如此復雜又個性化。來自阿爾伯塔大學的研究者們為此量身定做了一個數學模型,發現幽默或許不僅僅關乎
C++筆記007:易犯錯誤模型——類中為什麽需要成員函數
計算 成員 area 分享圖片 end src 賦值 內存空間 3.1 先看源碼,在VS2010環境下無法編譯通過,在VS2013環境下可以編譯通過,並且可以運行,只是運行結果並不是我們期待的結果。 最初通過MyCircle類定義對象c1時,為對象分配內存空間,r沒有初
數學模型:3.非監督學習--聚類分析 和K-means聚類
rand tar 聚類分析 復制 clust tle 降維算法 generator pro 1. 聚類分析 聚類分析(cluster analysis)是一組將研究對象分為相對同質的群組(clusters)的統計分析技術 ---->> 將觀測對象的群體按照
UVM暫存器篇之四:暫存器模型的整合(中)
本文轉自:http://www.eetop.cn/blog/html/28/1561828-6266221.html MCDF暫存器模組程式碼 下面我們給出實現後的MCDF暫存器RTL設計程式碼: 上面的設計中採取了巨集的
tensorflow利用預訓練模型進行目標檢測(四):檢測中的精度問題以及evaluation
一、tensorflow提供的evaluation Inference and evaluation on the Open Images dataset:https://github.com/tensorflow/models/blob/master/research/object_detection/g
模型優化:BatchNorm合併到卷積中
1.bn合併的必要性: bn層即batch-norm層,一般是深度學習中用於加速訓練速度和一種方法,一般放置在卷積層(conv層)或者全連線層之後,將資料歸一化並加速了訓練擬合速度。但是bn層雖然在深度學習模型訓練時起到了一定的積極作用,但是在預測時因為憑空多了一些層,影響了整體的計算速度
機器學習實戰系列:sklearn 中模型儲存的兩種方法
一、 sklearn中提供了高效的模型持久化模組joblib,將模型儲存至硬碟。 from sklearn.externals import joblib #lr是一個LogisticRegression模型 joblib.dump(lr, 'lr.model') lr =