
spark shuffle寫操作之SortShuffleWriter
提出問題
1. spark shuffle的預聚合操作是如何做的,其中底層的資料結構是什麼?在資料寫入到記憶體中有預聚合,在讀溢位檔案合併到最終的檔案時是否也有預聚合操作?
2. shuffle資料的排序是如何做的? 分割槽內的資料是否是有序的?若有序,spark 內部是按照什麼排序演算法來排序每一個分割槽上的key的?
3. shuffle的溢位操作和TaskMemoryManager的關係?
4. 在資料溢位階段,記憶體中資料的排序是使用演算法進行排序的?
5. 在溢位檔案資料合併階段,記憶體中的資料的排序是使用的什麼演算法?
6. 為什麼在讀取溢位檔案到記憶體中時,返回的結果是迭代器而不是直接的資料結果?
。。。。。。還有很多的細節。
前言
我們先來回首前幾篇文章的關係: spark 原始碼分析之二十一 -- Task的執行流程 從排程的角度說明了TaskScheduler是如何排程任務的,其中任務的執行目前為止寫了三篇文章,分別是 剖析Task執行時記憶體的管理的 spark 原始碼分析之二十二-- Task的記憶體管理,剖析shuffle寫操作執行前的準備工作,引出了三種shuffle的寫方式,前兩篇文章分別介紹了 spark shuffle寫操作三部曲之UnsafeShuffleWriter 和 spark shuffle寫操作三部曲之BypassMergeSortShuffleWriter 前兩種shuffle的寫的方式。本篇文章來剖析最後一種 shuffle 寫的方式。
我們先來看第三種shuffle的相關依賴類。
SizeTrackingAppendOnlyMap
這個類繼承了AppendOnlyMap並實現了SizeTracker trait。
其內部方法如下:

它依賴的類都是其父類,他只是它的兩個父類的拼湊,所以要想了解真正的動作,還是需要去看其父類AppendOnlyMap和trait SizeTracker。
父類AppendOnlyMap
這個類繼承了Iterable trait和 Serializable 介面。
其類結構如下:
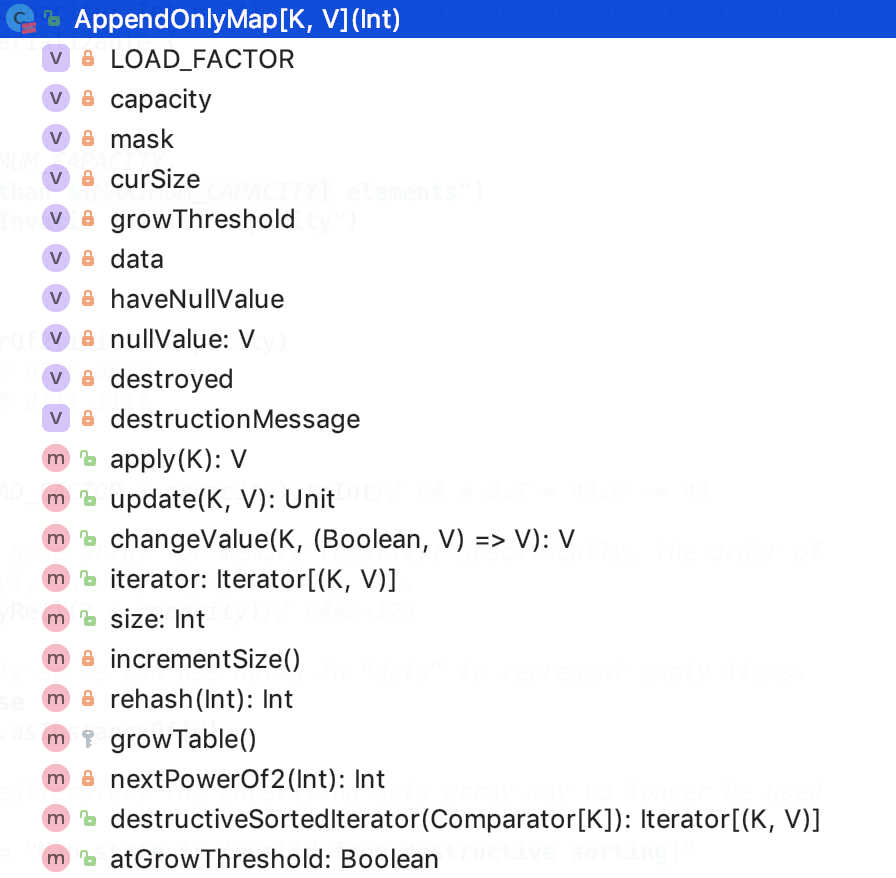
成員變數
成員變數如下:
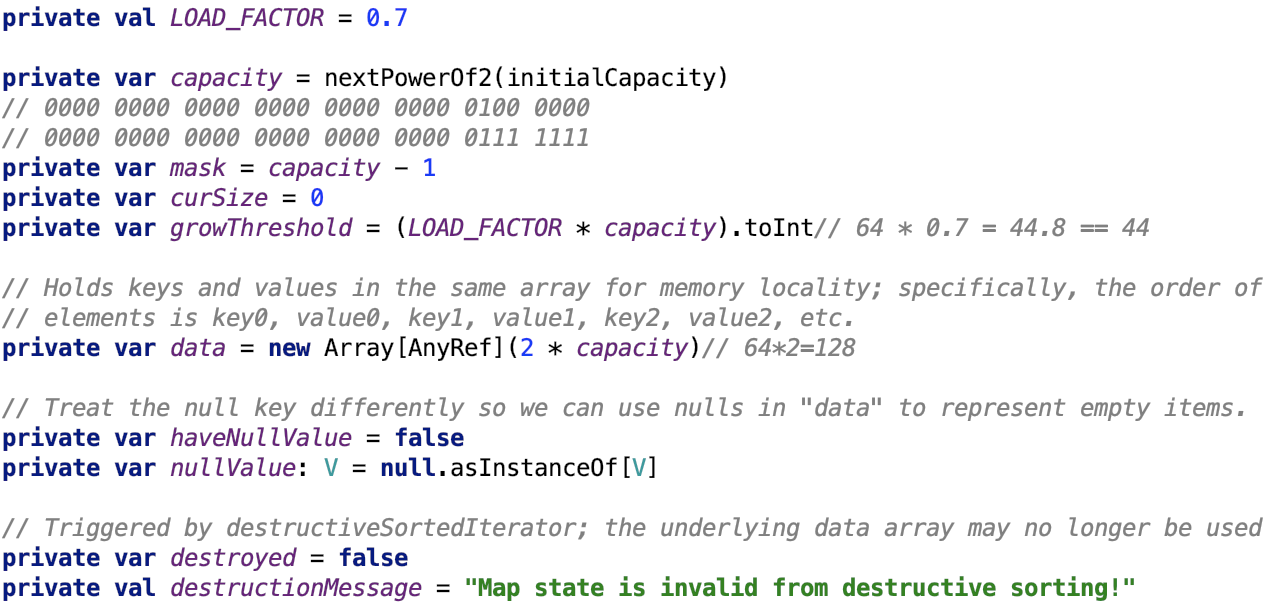

LOAD_FACTOR:負載因子,為0.7,實際儲存資料佔比大於負載因子則需要擴容。
mask的作用:將任意的數對映到[0,mask]的範圍內。
data:是真正儲存資料的陣列。
haveNullValue:是否有null值,因為陣列中的null值還有一個作用,那就是表示該索引位置沒有元素存在。
nullValue:null值。
destoryed:表示資料是否已經被銷燬。
理論最大容量為:512MB
成員方法如下:
根據key獲取value
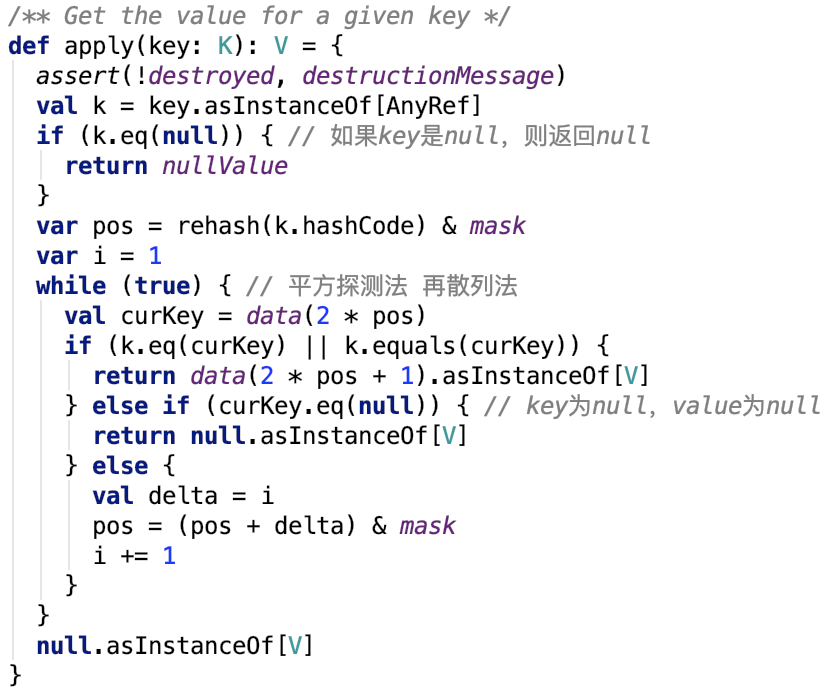
解釋:
1.如果是null值,則返回null值,因為約定 null值key對應null值value。
2. 首先先把原來的hashcode再求一次hash碼,然後和掩碼做與操作將其對映到 [0,mask] 範圍內。
3. 嘗試取出資料如果取出來的key是指定的key,則返回資料,若取出的key是null,表示之前沒有儲存過,返回null,若取出的資料的key不是當前key,則使用再雜湊法 先有pos + delta逐步雜湊,求得下一次的pos,然後再重複第三步,直至找匹配的值或null值後返回。
設定鍵值對
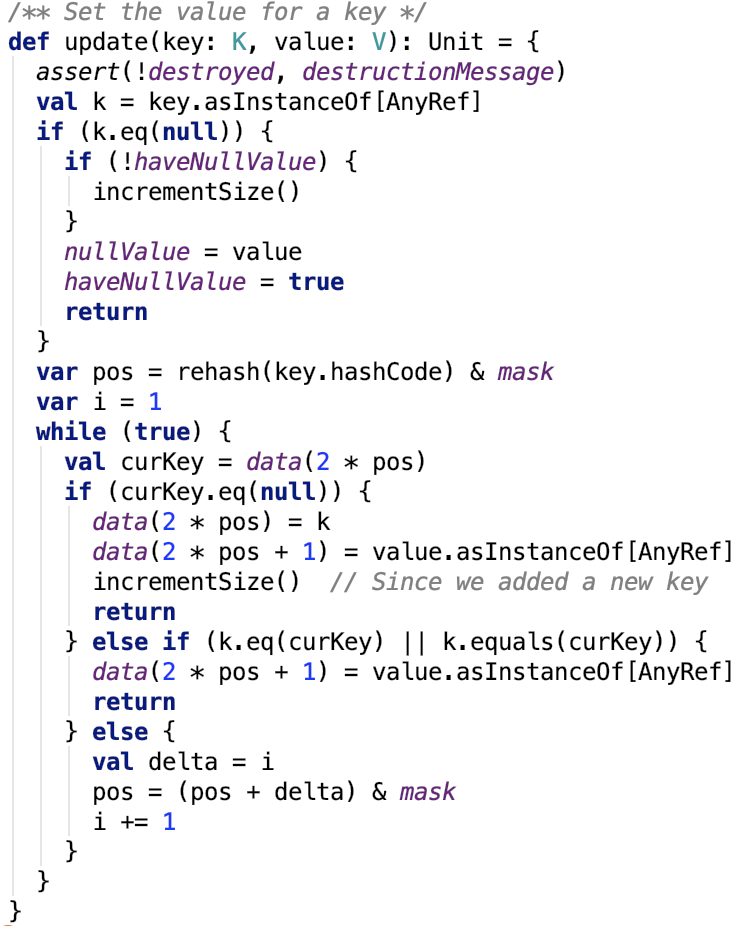
更新鍵值思路:跟查詢的思路一樣,只不過找到之後不返回,是執行更新操作。
在指定key的value上執行函式
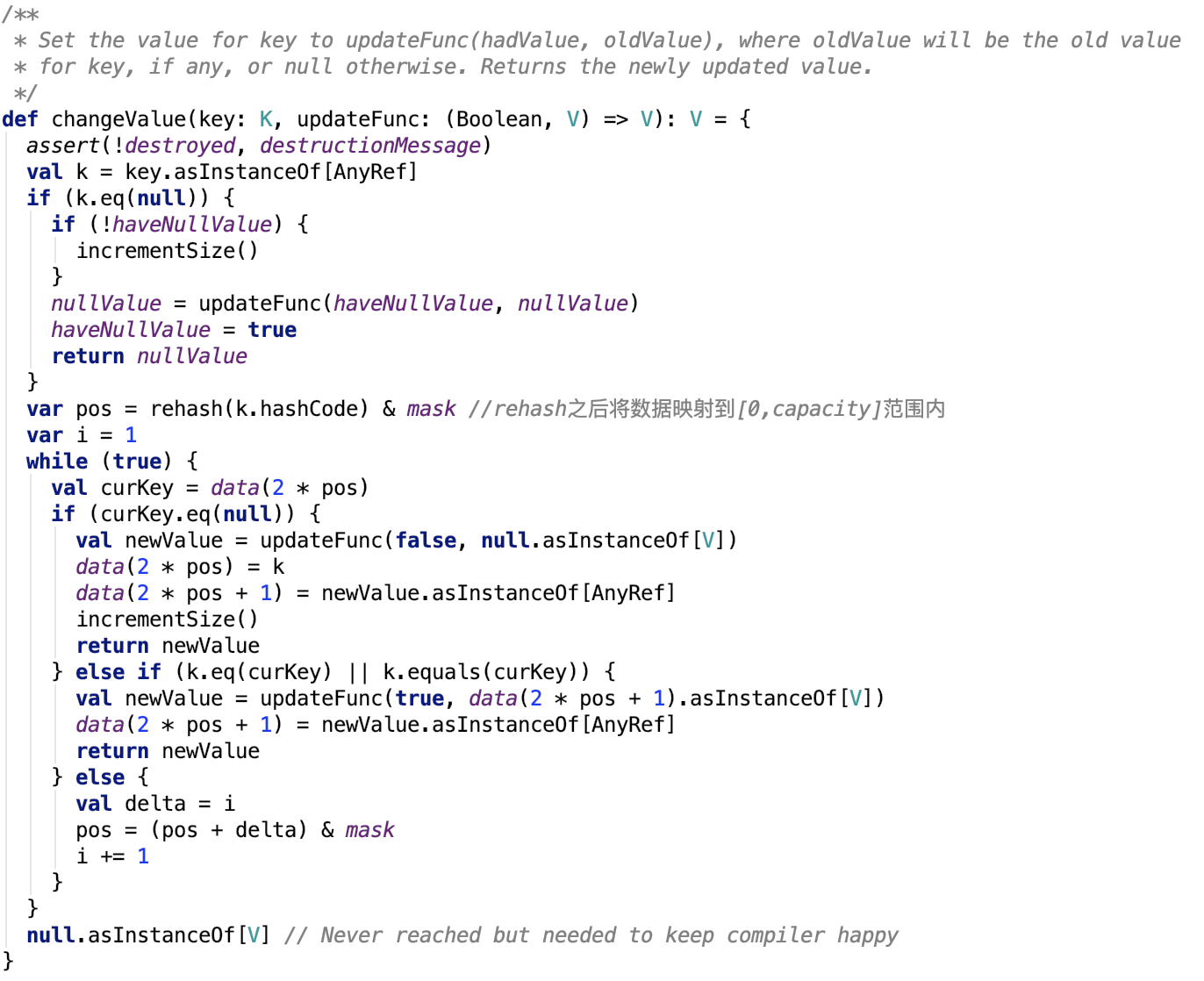
更新鍵值思路:跟查詢的思路一樣,只不過找到之後不返回,如果找的的值是null值,則執行賦值操作,否則更新value為執行更新函式後的值。
獲取未排序的迭代器
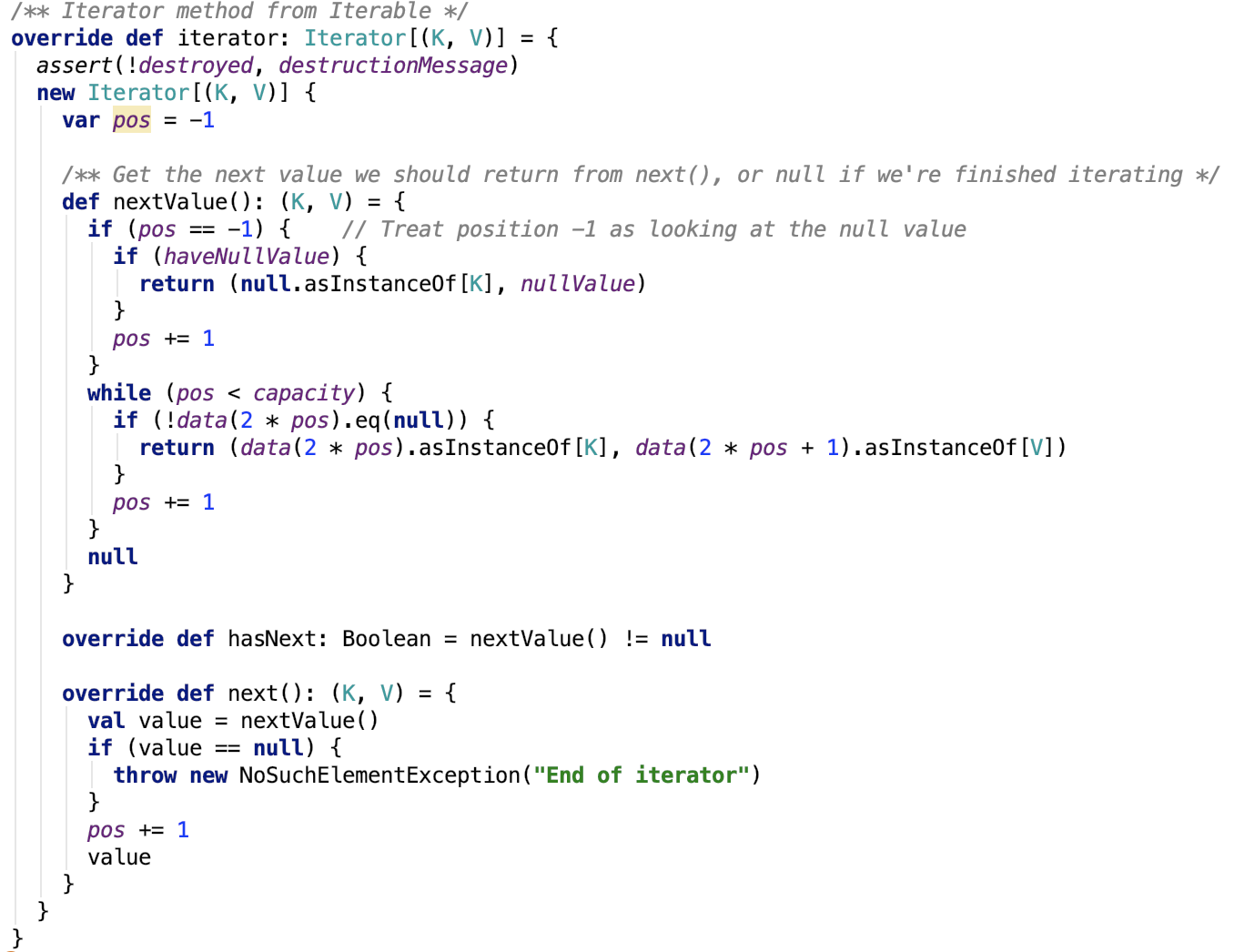
本質上是遍歷陣列,只不過這裡的元素是稀疏的,只返回有元素的資料,不做過多說明。

先整理陣列,將陣列的資料變為緊湊的資料。再按照key來進行排序。最後返回一個迭代器,這個迭代器裡的資料是有序的。
rehash

擴容
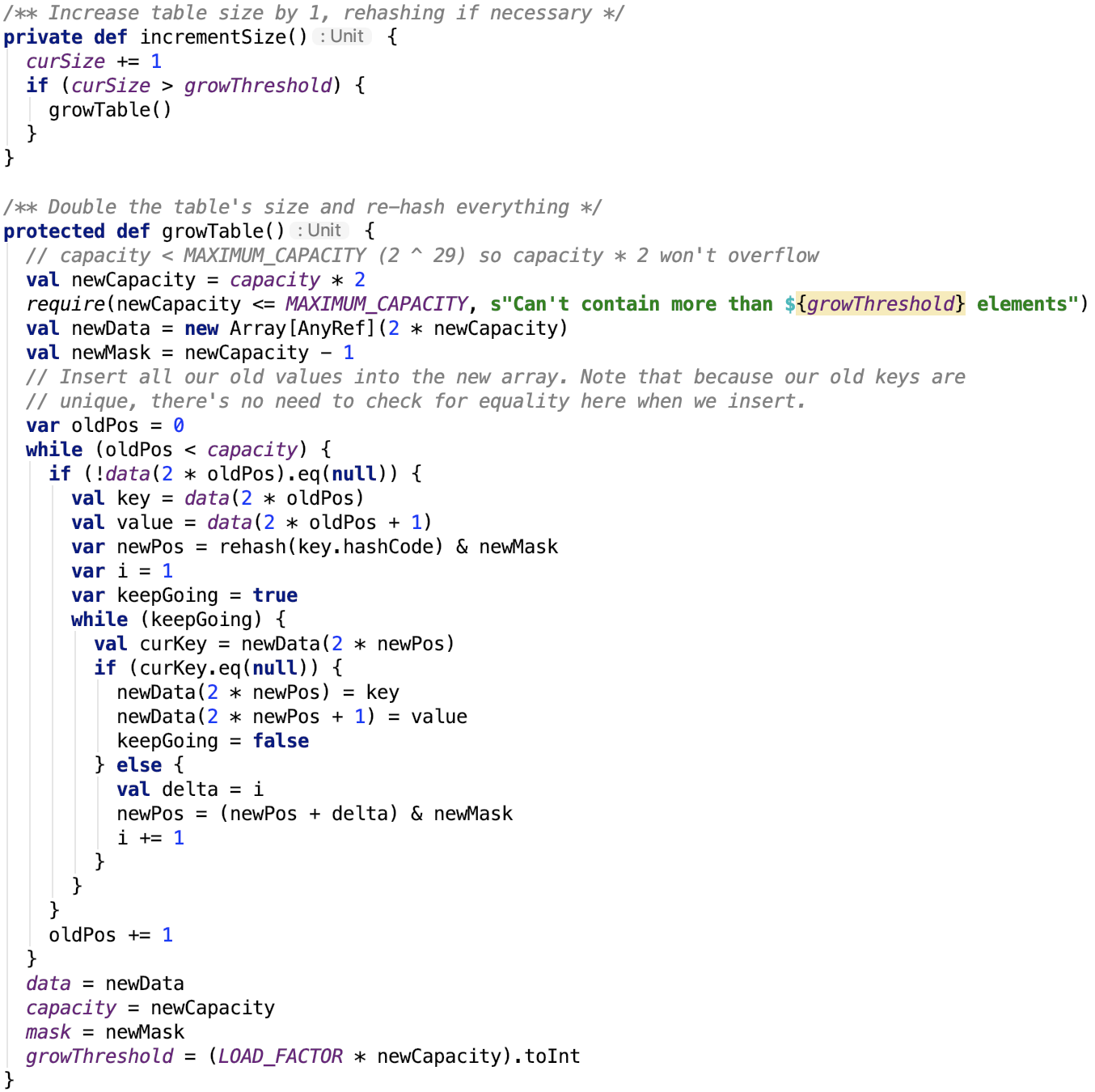
如果當前使用容量佔比大於負載因子,則開始擴容。
新容量是舊容量的一倍。遍歷舊的陣列中的每一個非null元素,將其對映到新的陣列中。
父類SizeTracker
A general interface for collections to keep track of their estimated sizes in bytes. We sample with a slow exponential back-off using the SizeEstimator to amortize the time, as each call to SizeEstimator is somewhat expensive (order of a few milliseconds).
集合的通用介面,用於跟蹤其估計的大小(以位元組為單位)。 我們使用SizeEstimator以緩慢的指數退避進行取樣以分攤時間,因為每次呼叫SizeEstimator都有點昂貴。
成員變數

SAMPLE_GROWTH_RATE指數增長因子,比如是2,則是 1,2,4,8,16,......
核心方法如下:
取樣

估算大小

重取樣

更新後取樣

依賴類 -- SizeEstimator
主要用於資料佔用記憶體的估算。
ExternalAppendOnlyMap
繼承關係
其繼承關係如下:
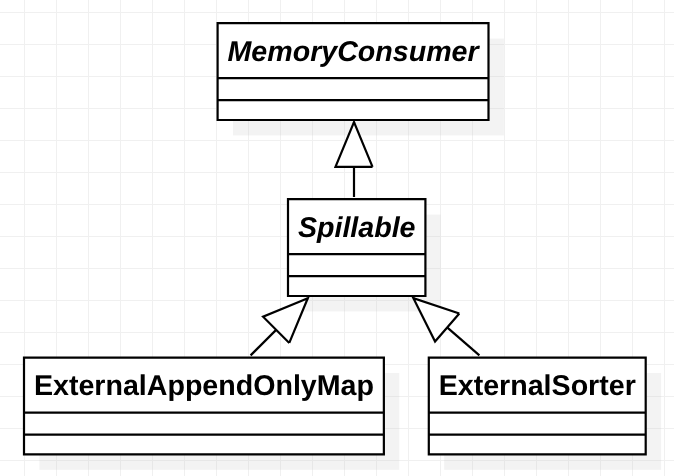
其父類是Spillable抽象類。
先來看父類Spillable
超類--Spillable
類說明:當記憶體不足時,這個類會把記憶體裡的集合溢位到磁碟中。
其成員變數如下,不做過多解釋。
主要方法如下:
溢位記憶體到磁碟
它實現了父類的抽象方法 spill方法,原始碼如下:

思路:如果consumer不是這個類並且記憶體模式是堆內記憶體才支援記憶體溢位。
其依賴方法如下:
org.apache.spark.util.collection.Spillable#forceSpill原始碼如下,它是一個抽象方法,沒有具體實現。

釋放記憶體方法,其呼叫了 父類的freeMemory方法:

嘗試溢位來釋放記憶體
org.apache.spark.util.collection.Spillable#maybeSpill 原始碼如下:

其依賴方法spill方法如下,注意這個方法是用來溢位集合的資料到記憶體的,它是抽象方法,待子類實現。

這個類留給子類兩個方法來實現,forceSpill和spill方法。
ExternalAppendOnlyMap這個類裡面的是對 SizeTrackingAppendOnlyMap 的進一步封裝,下面我們先看 SizeTrackingAppendOnlyMap。
資料比較器 -- HashComparator
其原始碼如下:

總之,它是根據雜湊碼進行比較的。
SpillableIterator
首先,它是org.apache.spark.util.collection.ExternalAppendOnlyMap的內部類,實現了Iterator trait,它是跟ExternalAppendOnlyMap一起使用的,也使用了 ExternalAppendOnlyMap 裡的方法。
成員變數
其成員變數如下:

SPILL_LOCK是一個物件鎖,每次執行溢位操作都會先獲取鎖再執行溢位操作,執行完畢後釋放鎖。
cur表示下一個未讀的元素。
hasSpilled表示是否有溢位。
核心方法
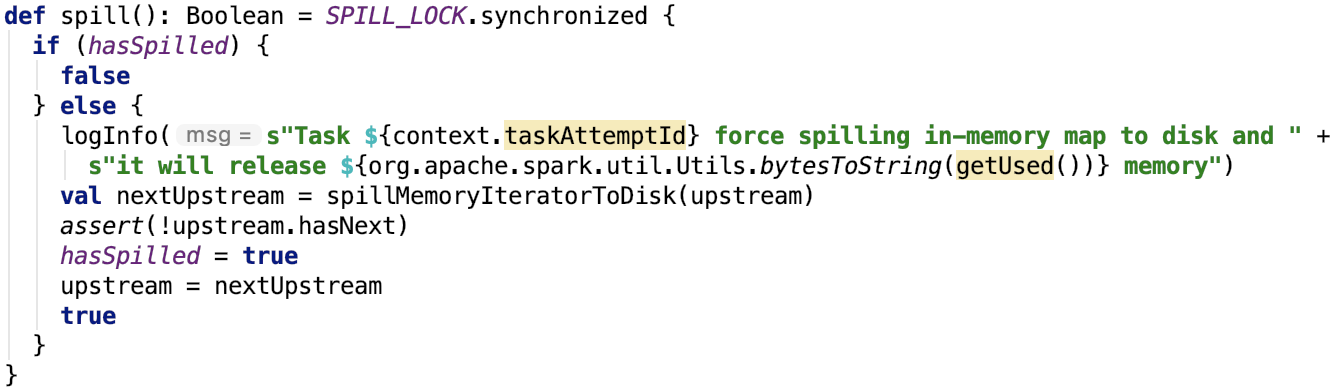
1.溢位
其原始碼如下:
2.銷燬資料釋放記憶體

其依賴方法 org.apache.spark.util.collection.ExternalAppendOnlyMap#freeCurrentMap 如下:

3. 讀取下一個

4. 是否有下一個

5. 獲取下一個元素

6. 轉換為CompletionIterator

總結
從本質來來說,它是一個包裝類,資料從構造方法以Iterator的形式傳遞過來,而它自己也是一個Iterator,除了實現了Iterator本身的方法外,還具備了溢位到磁碟、銷燬記憶體資料、轉換為CompletionIterator的功能。
DiskMapIterator
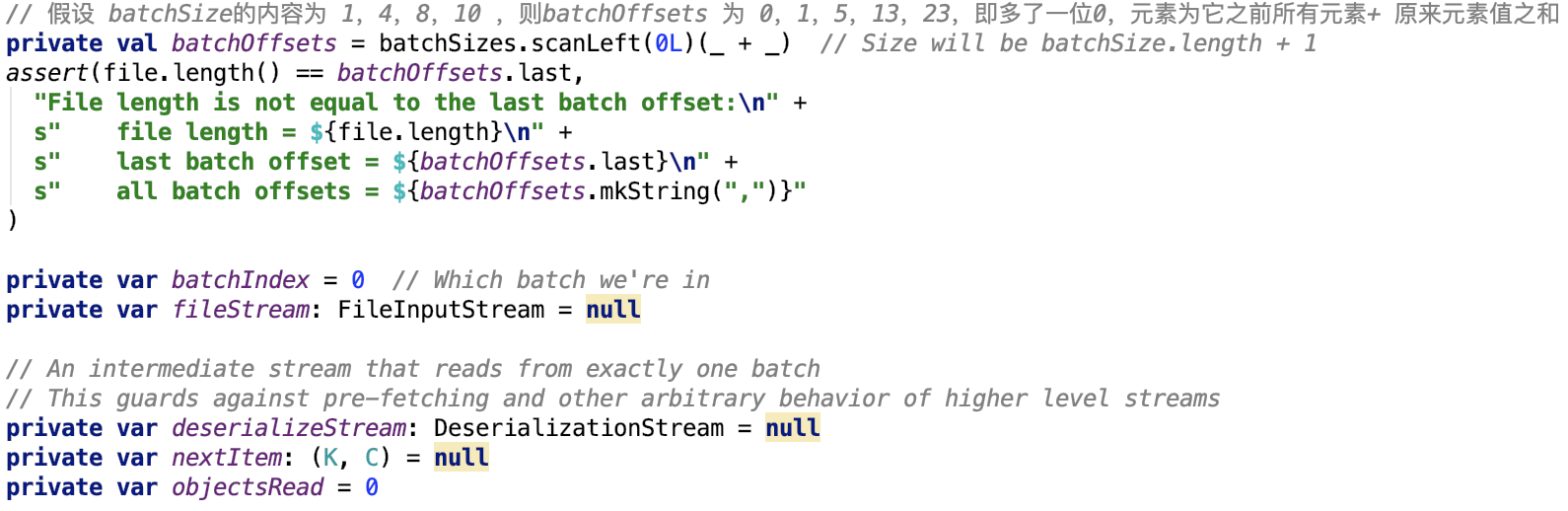
這個類就是用來讀取檔案的資料的,只不過檔案被劃分為了多個檔案段,有一個數組專門記錄這多個檔案段的段大小,如建構函式所示:

其中file就是要讀取的資料檔案,blockId表示檔案在shuffle系統中對應的blockId,batchSize就是指的每一個檔案段的大小。
成員變數如下:
下面從Iterator的主要方法入手,去剖析整個類。
是否有下一個元素

其依賴方法 org.apache.spark.util.collection.ExternalAppendOnlyMap.DiskMapIterator#readNextItem 原始碼如下:

思路:首先先讀取下一個key-value對,若讀取完畢後,發現這個批次的資料已經讀取完畢,則呼叫 nextBatchStream 方法,關閉現有反序列化流,初始化讀取下一個檔案段的反序列化流。
其依賴方法 org.apache.spark.util.collection.ExternalAppendOnlyMap.DiskMapIterator#nextBatchStream 如下:

思路:首先先確定該批次的資料是否讀取完畢,若讀取完畢,則做完清理操作後,返回null值,否則先關閉現有的反序列化流,然後獲取下一個反序列化流的開始和結束offset,最後初始化一個反序列化流返回給呼叫端。
其依賴方法 org.apache.spark.util.collection.ExternalAppendOnlyMap.DiskMapIterator#cleanup 方法如下:

思路:首先關閉現有的反序列化流和檔案流,最後如果檔案存在,則刪除之。
讀取下一個元素

思路很簡單,其中,nextItem已經在是否有下一個元素的時候反序列化出來了。
構造方法
它有兩個過載的構造方法:

和

解釋一下其中的引數:
createCombiner:是根據一個原值來建立其combine之後的值的函式。
mergeValue:是根據一個combine之後的值和一個原值求combine之後的值的函式。
mergeCombiner:是根據兩個combine之後的值求combine之後的值函式。
本質上這幾個函式就是逐步歸併聚合的體現。
成員變數

serializerBatchSize:表示每次溢位時,寫入檔案的批次大小,這個批次是指的寫入的物件的次數,而不是通常意義上的buffer的緩衝區大小。
_diskBytesSpilled :表示總共溢位的位元組大小
fileBufferSize: 檔案快取大小,預設為 32k
_peakMemoryUsedBytes: 表示記憶體使用峰值
keyComparater:表示記憶體排序的比較器
核心方法
插入資料


溢位操作

思路:首先先呼叫currentMap的destructiveSortedIterator方法,先整理其內部的資料成緊湊的資料,然後對資料進行排序,最終有序資料以Iterator的結果返回。然後呼叫
將資料溢位到磁碟,最後將溢位的資訊記錄到spilledMaps中,其依賴方法 org.apache.spark.util.collection.ExternalAppendOnlyMap#spillMemoryIteratorToDisk 原始碼如下:

思路:建立本地臨時block,並獲取其writer,最終遍歷記憶體陣列的迭代器,將資料都通過writer寫入到file中,其中寫檔案是分批寫入的,即每次滿足serializerBatchSize大小之後,執行flush寫入,最後執行一次flush寫入,關閉檔案,最終返回DiskMapIterator物件。
強制溢位

摧毀迭代器

獲取迭代器

預聚合類 -- Aggregator
其原始碼如下:

這個類的兩個方法 combineValuesByKey 和 combineCombinersByKey 都依賴於 ExternalAppendOnlyMap類。
下面繼續來看ExternalSorter類的內部實現。
支援排序預聚合的sorter -- ExternalSorter
類說明
Sorts and potentially merges a number of key-value pairs of type (K, V) to produce key-combiner pairs of type (K, C). Uses a Partitioner to first group the keys into partitions, and then optionally sorts keys within each partition using a custom Comparator. Can output a single partitioned file with a different byte range for each partition, suitable for shuffle fetches. If combining is disabled, the type C must equal V -- we'll cast the objects at the end. Note: Although ExternalSorter is a fairly generic sorter, some of its configuration is tied to its use in sort-based shuffle (for example, its block compression is controlled by spark.shuffle.compress). We may need to revisit this if ExternalSorter is used in other non-shuffle contexts where we might want to use different configuration settings.
對型別(K,V)的多個鍵值對進行排序並可能合併,以生成型別(K,C)的鍵組合對。使用分割槽程式首先將key分組到分割槽中,然後可以選擇使用自定義Comparator對每個分割槽中的key進行排序。可以為每個分割槽輸出具有不同位元組範圍的單個分割槽檔案,適用於隨機提取。如果禁用了組合,則型別C必須等於V - 我們將在末尾轉換物件。注意:雖然ExternalSorter是一個相當通用的排序器,但它的一些配置與基於排序的shuffle的使用有關(例如,它的塊壓縮由spark.shuffle.compress控制)。如果在我們可能想要使用不同配置設定的其他非隨機上下文中使用ExternalSorter,我們可能需要重新審視這一點。
下面,先來看其構造方法:
構造方法

引數如下:
aggregator:可選的聚合器,可以用於歸併資料
partitioner :可選的分割槽器,如果有的話,先按分割槽Id排序,再按key排序
ordering : 可選的排序,它在每一個分割槽內按key進行排序,它也可以是全域性排序
serializer :用於溢位記憶體資料到磁碟的序列化器
其成員變數和核心方法,先不做剖析,其方法圍繞兩個核心展開,一部分是跟資料的插入有關的方法,一部分是跟多個溢位檔案的合併操作有關的方法。
下面來看看它的一些內部類。
只讀一個分割槽資料的迭代器 -- IteratorForPartition
這個類實現了Iterator trait,只負責迭代讀取一個特定分割槽的資料,其定義如下:

比較簡單,不做過多說明。
溢位檔案的描述 -- SpilledFile

這個類是一個 case class ,它記錄了溢位檔案的一些關鍵資訊,構造方法的各個欄位如下:
file:溢位檔案
blockId:溢位檔案對應的blockId
serializerBatchSizes:表示每一個序列化類對應的batch的大小。
elementsPerPartition:表示每一個分割槽的元素的個數。
比較簡單,沒有類的方法定義。
讀取溢位檔案的內容 -- SpillReader
它負責讀取一個按分割槽做檔案分割槽的檔案,希望按分割槽順序讀取分割槽檔案的內容。
其類結構如下:
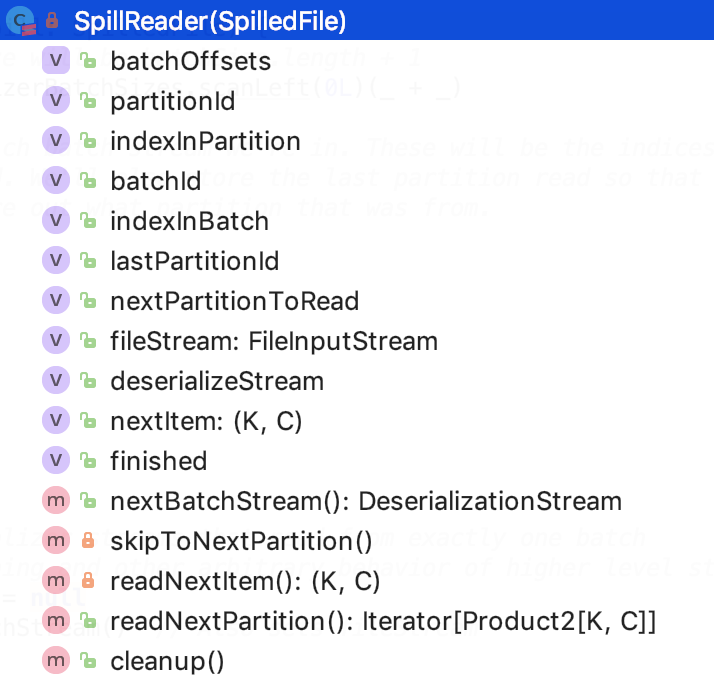
成員變數
先看其成員變數:
batchOffsets:序列化類的每一個批次的offset
partitionId:分割槽id
indexInPartition:在分割槽內的索引資訊
batchId:batch的id
indexInBatch:在batch中的索引資訊
lastPartitionId:上一個partition ID
nextPartitionToRead:下一個要讀取的partition的id
fileStream:檔案輸入流
deserializeStream:分序列化流
nextItem:下一個鍵值對
finished:是否讀取完畢
下面,來看其核心方法:
獲取下一個批次的反序列化流

思路跟DiskMapIterator的獲取下一個流的思路很類似,不做過多解釋。
讀取下一個partition的資料
其返回的是一個迭代器,org.apache.spark.util.collection.ExternalSorter.SpillReader#readNextPartition原始碼如下:
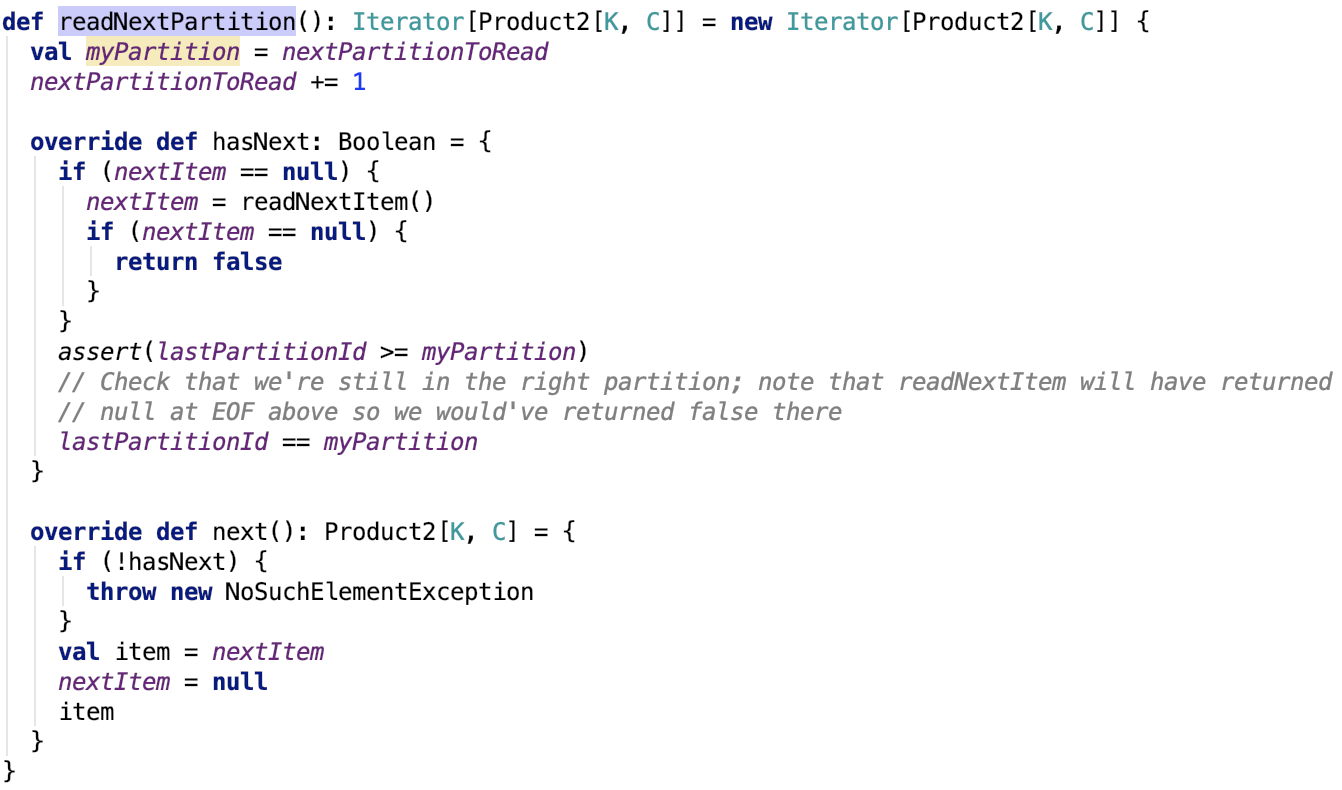
思路:其返回迭代器中,的hasNext中先去讀取下一個item,如果讀取到的下一個元素為null,則返回false,表示沒有資料可以返回。
其依賴方法 org.apache.spark.util.collection.ExternalSorter.SpillReader#readNextItem 原始碼如下:
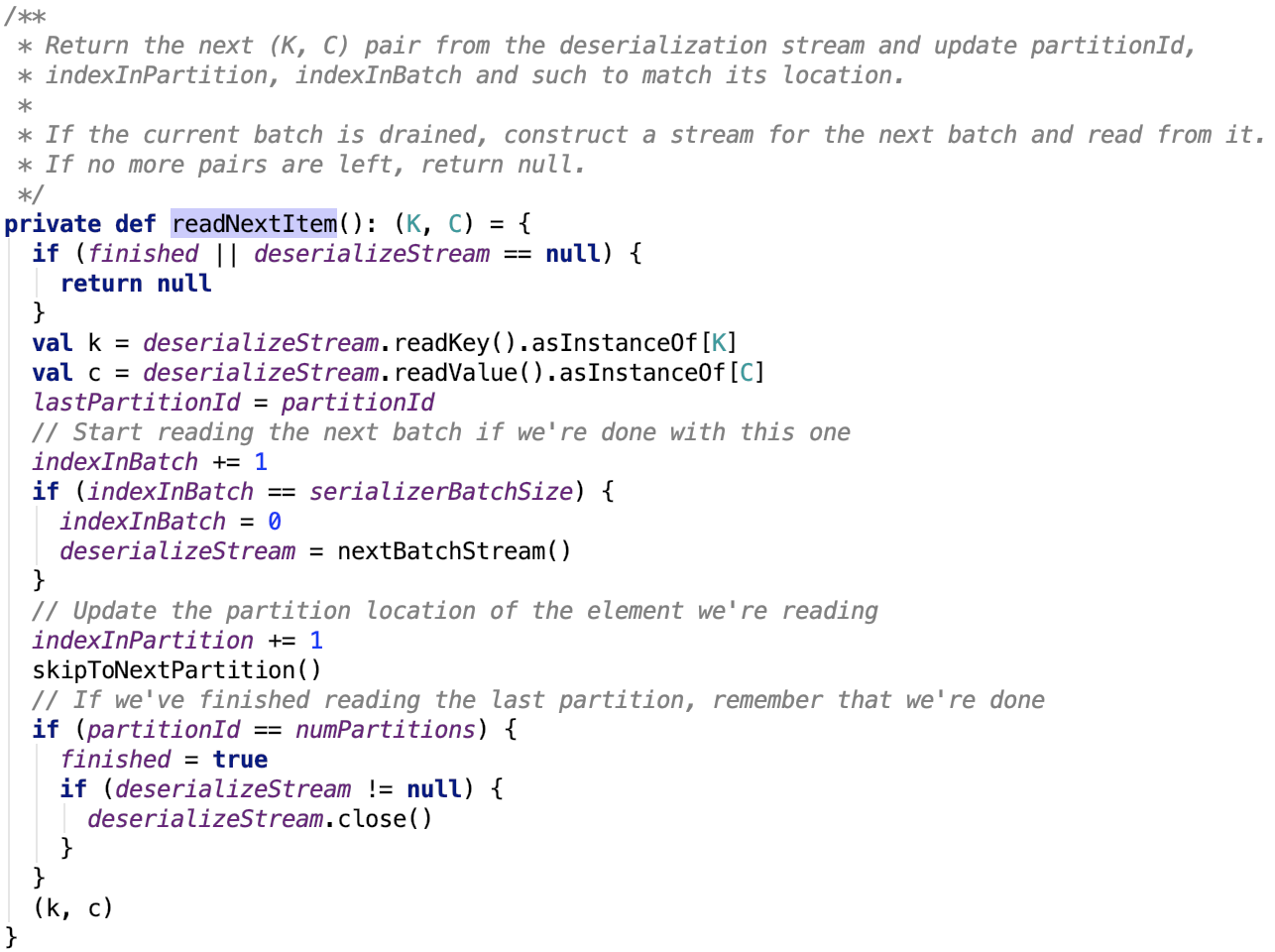
思路:首先該批次資料讀取完畢,則關閉掉讀取該批次資料的流,繼續讀取下一個批次的流。
其依賴方法 org.apache.spark.util.collection.ExternalSorter.SpillReader#skipToNextPartition 方法如下:

下面,整理一下思路:
每次讀取一個檔案的分割槽,該分割槽讀取完畢,關閉分割槽檔案,讀取下一個檔案的下一個分割槽資料。只不過它在讀檔案的分割槽的時候,會有batch操作,一個分割槽可能會對應多個batch,但是一個batch有且只能有一個分割槽。
SpillableIterator
首先它跟 org.apache.spark.util.collection.ExternalAppendOnlyMap.SpillableIterator 很像, 實現方法也很類似,都是實現了一個Iterator trait,構造方法以一個Iterator物件傳入,並且對其做了封裝,可以跟上文的 SpillableIterator 對比剖析。
其成員變數如下:

nextUpStream:下一個批次的stream
對Iterator的實現
先來看Iterator的方法實現:

溢位
其原始碼如下:
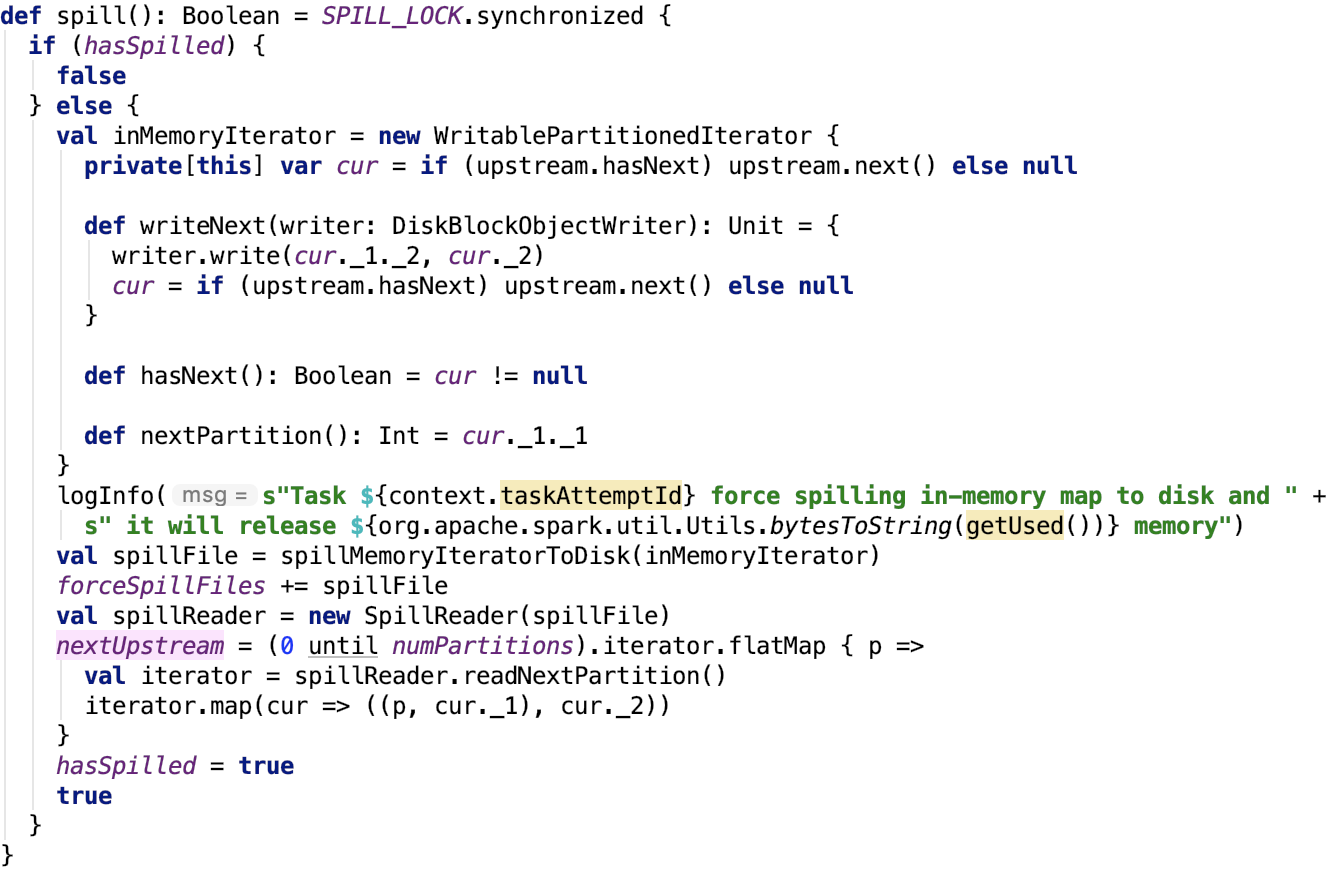
思路如下:首先建立記憶體迭代器,然後遍歷記憶體迭代器,將資料溢位到磁碟中,其關鍵方法 spillMemoryIteratorToDisk。
兩種存放溢位前資料的資料結構
PartitionedAppendOnlyMap
這個類底層是陣列,資料按照Map的形式稀疏排列,它還支援多個key的預聚合操作。
它是SizeTrackingAppendOnlyMap和 WritablePartitionPairCollection的子類。
其原始碼如下:

PartitionedPairBuffer
這個類底層是陣列,資料按陣列的形式緊湊排列。不支援多個相同key的預聚合操作。
它是SizeTracker 和 WritablePartitionPairCollection的子類。
其原始碼如下:
插入資料

陣列擴容

獲取排序後的迭代器

獲取讀取陣列資料的迭代器

下面來看最後一種shuffle資料寫的方式。
使用SortShuffleWriter寫資料
這種shuffle方式支援預聚合操作。
其下操作原始碼如下:
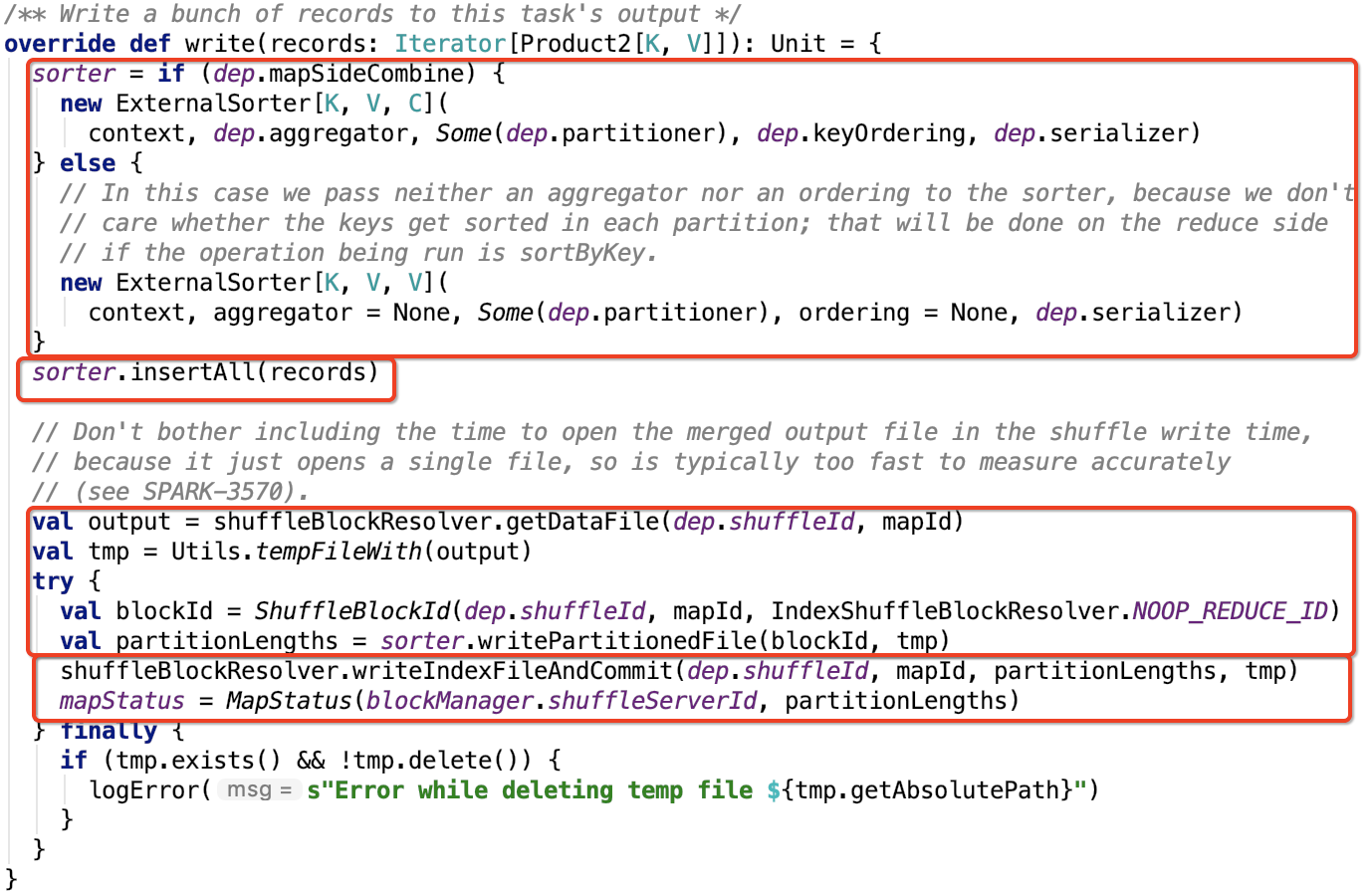
初始化Sorter
如果需要在map段做combine操作,則需要指定 aggragator和 keyOrdering,即map端的資料會做預聚合操作,並且分割槽內的資料有序,其排序規則是按照hashCode做排序的。
否則這兩個引數為null,即map端的資料沒有預聚合,並且分割槽內資料無序。
向sorter插入資料
其原始碼如下:

org.apache.spark.util.collection.ExternalSorter#insertAll的原始碼如下:
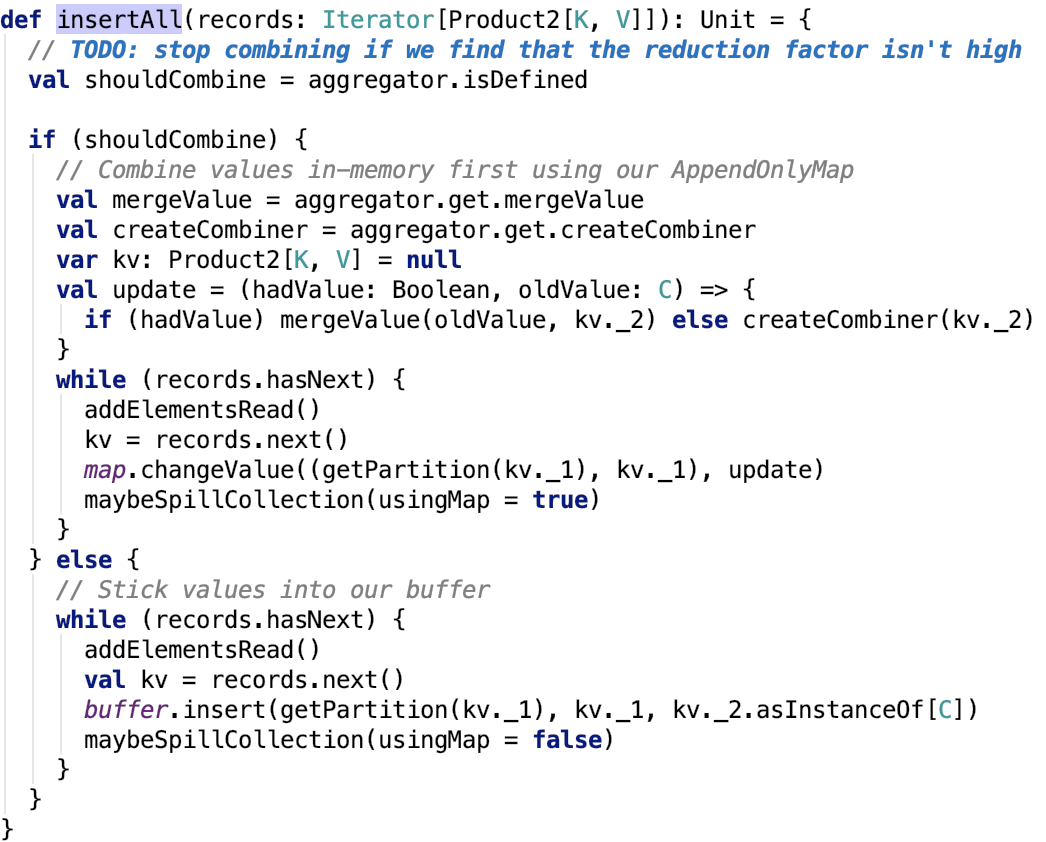
思路:首先如果資料需要執行map端的combine操作,則使用 PartitionedAppendOnlyMap 類來操作,這個類可以支援資料的combine操作。如果不需要 執行map 端的combine 操作,則使用 PartitionedPairBuffer 來實現,這個類不會對資料進行預聚合。每次資料寫入之後,都要檢視是否需要執行溢位記憶體資料到磁碟的操作。
這兩個類在上文中已經做了詳細的說明。
其依賴方法 addElementsRead 原始碼如下:

溢位記憶體資料到磁碟的核心方法 maybeSpillCollection 原始碼如下:

思路:它有一個標誌位 usingMap表示是否使用的是map的資料結構,即是否是 PartitionedAppendOnlyMap,其思路幾乎一樣,只不過在呼叫 mayBeSpill 方法中傳入的引數不一樣。其中使用的記憶體的大小,都是經過取樣評估計算過的。其依賴方法 org.apache.spark.util.collection.Spillable#maybeSpill 如下:

思路:如果讀取的資料是 32 的整數倍並且當前使用的記憶體比初始記憶體大,則開始向TaskMemoryManager申請分配記憶體,如果申請成功,則返回申請的大小,注意:在向TaskMemoryManager申請記憶體的過程中,如果記憶體不夠,也會去呼叫 org.apache.spark.util.collection.Spillable#spill 方法,在其內部也會去呼叫 org.apache.spark.util.collection.ExternalSorter#forceSpill 方法其原始碼如下,其中readingIterator是SpillableIterator型別的物件。

其依賴方法 org.apache.spark.util.collection.Spillable#logSpillage 會列印一些溢位日誌。不再過多說明。
其依賴方法 org.apache.spark.util.collection.ExternalSorter#spill 原始碼如下:
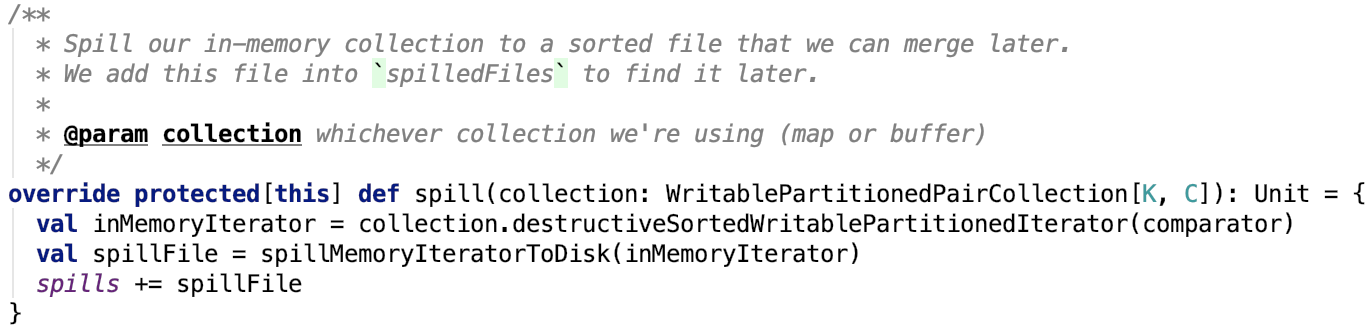
思路相對比較簡單,主要是先獲取排序後集合的迭代器,然後將迭代器傳入 org.apache.spark.util.collection.ExternalSorter#spillMemoryIteratorToDisk ,將記憶體資料溢位到臨時的磁碟檔案後返回一個SpilledFile物件,將其記錄到 spills中,spills這個變數主要記錄了記憶體資料的溢位過程中的溢位檔案的資訊。
其溢位磁碟方法 org.apache.spark.util.collection.ExternalSorter#spillMemoryIteratorToDisk 原始碼如下:

首先獲取寫序列化檔案的writer,然後遍歷資料的迭代器,將資料迭代寫入到磁碟中,在寫入過程中,不斷將每一個分割槽的大小資訊以及每一個分割槽內元素的個數記錄下來,最終將溢位檔案、分割槽元素個數,以及每一個segment的大小資訊封裝到SpilledFile物件中返回。
多檔案歸併為一個檔案
其核心程式碼如下:

思路:首先先初始化一個臨時的最終檔案(以uuid作為字尾),然後初始化blockId,最後呼叫 org.apache.spark.util.collection.ExternalSorter的writePartitionedFile 方法。將資料寫入一個臨時檔案,並將該檔案中每一個分割槽對應的FileSegment的大小返回。
其關鍵方法 org.apache.spark.util.collection.ExternalSorter#writePartitionedFile 原始碼如下:

思路:首先如果從來沒有過溢位檔案,則首先先看一下是否需要map端聚合,若是需要,則資料已經被寫入到了map中,否則是buffer中。然後呼叫集合的轉成迭代器的方法,將記憶體的資料排序後輸出,最終迭代遍歷這個迭代器,將資料不斷寫入到最終的臨時檔案中,更新分割槽大小返回。
如果之前已經有溢位檔案了,則先呼叫 org.apache.spark.util.collection.ExternalSorter的partitionedIterator 方法將資料合併後返回合併後的迭代器。
最終遍歷每一個分割槽的資料,將分割槽的資料寫入到最終的臨時檔案,更新分割槽大小;最後返回分割槽大小。
下面重點剖析一下合併方法 org.apache.spark.util.collection.ExternalSorter#partitionedIterator,其原始碼如下:

首先,要說明的是,通過我們上面的程式分支進入該程式,此時歷史溢位檔案集合是空的,即它不會執行第一個分支的處理流程,但還是要做一下簡單的說明。
它有三個依賴方法分別如下:
依賴方法 org.apache.spark.util.collection.ExternalSorter#destructiveIterator 原始碼如下:

思路:首先 isShuffleSort為 true,我們現在就是走的 shuffle sort的流程,肯定是需要走第一個分支的,即它不會返回一個SpillableIterator迭代器。
依賴方法 org.apache.spark.util.collection.ExternalSorter#groupByPartition 原始碼如下:

思路:遍歷每一個分割槽返回一個IteratorForPartition的分割槽迭代器。
注意:由於歷史溢位檔案集合此時不為空,將不會呼叫這個方法。
依賴方法 org.apache.spark.util.collection.ExternalSorter#merge 原始碼如下:

思路:傳給merge方法的有兩個引數,一個是代表溢位檔案的SpiiledFile集合,一個是代表記憶體資料的迭代器。
首先遍歷每一個溢位檔案,建立一個讀取該溢位檔案的SpillReader物件,然後遍歷每一個分割槽建立一個IteratorForPartition迭代器,然後讀取每一個溢位檔案的分割槽的迭代器,最終和 作為引數傳入merge 方法的記憶體迭代器合併到一個迭代器集合中。
如果是需要預聚合的,則呼叫 mergeWithAggregation 方法,如果是需要排序的,則呼叫mergeSort 方法,對其進行排序,最後如果不滿足前兩種情況,呼叫集合的flatten 方法,將打平到一個迭代器中返回。
它有兩個依賴方法,分別如下:
org.apache.spark.util.collection.ExternalSorter#mergeSort 原始碼如下:
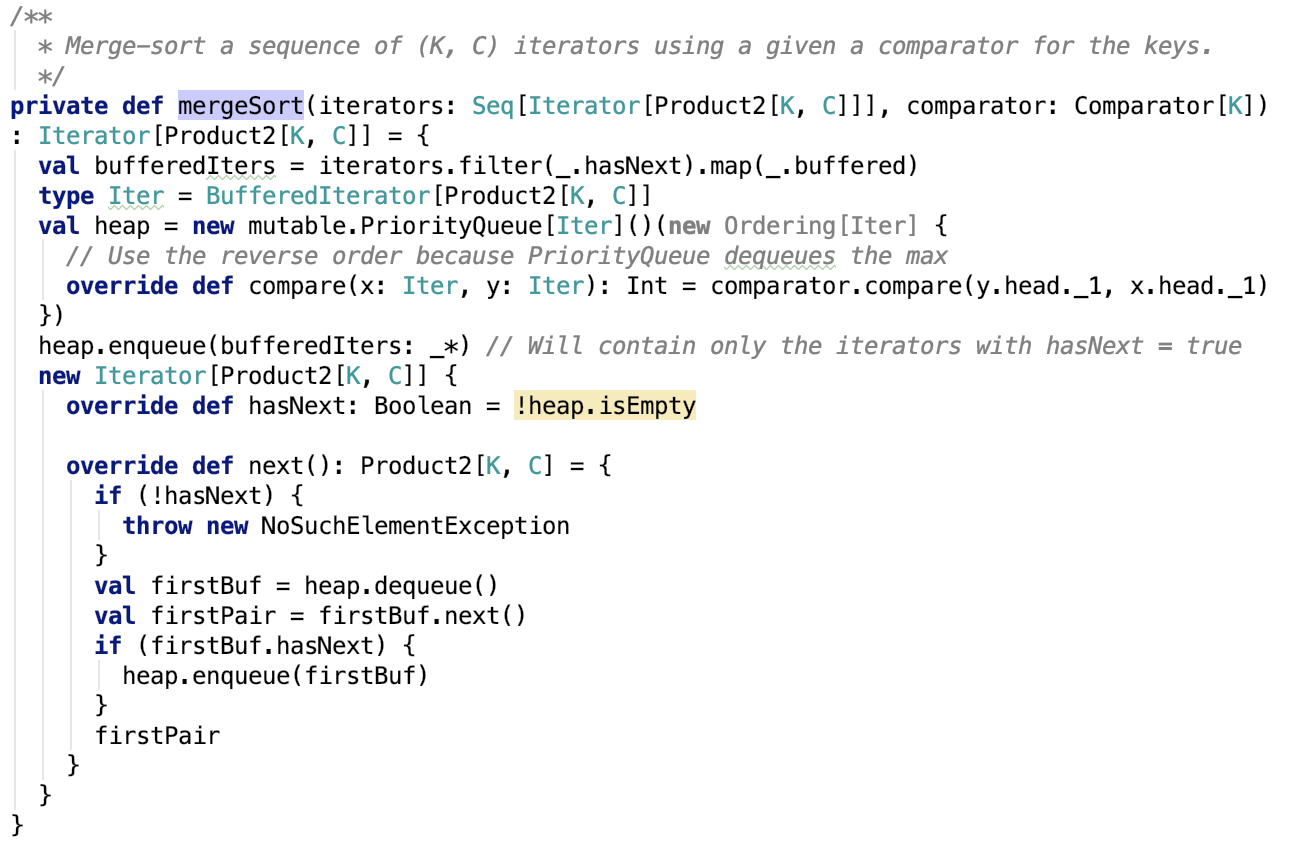
思路:使用堆排序構造優先佇列,對資料進行排序,最終返回一個迭代器。每次先從堆中根據partitionID排序,將同一個partition的排到前面,每次取出一個Iterator,然後取出該Iterator中的一個元素,再放入堆中,因為可能取出一個元素後,Iterator的頭節點的partitionId改變了,所以需要再次排序,就這樣動態的出堆入堆,讓不同Iterator的相同partition的資料總是在一起被迭代取出。注意這裡的comparator在指定ordering或aggragator的時候,是支援二級排序的,即不僅僅支援分割槽排序,還支援分割槽內的資料按key進行排序,其排序器原始碼如下:
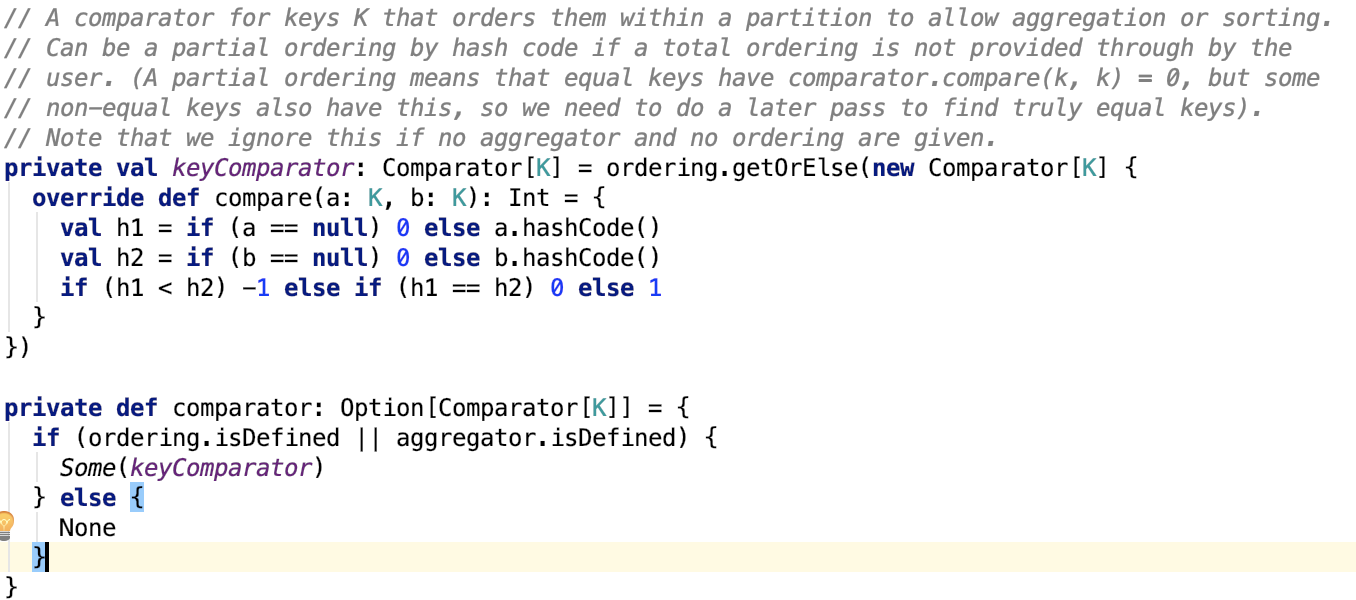

如果ordering和aggragator沒有指定,則資料排序器為:

即只按分割槽排序,跟第二種shuffle的最終格式很類似。
org.apache.spark.util.collection.ExternalSorter#mergeWithAggregation原始碼如下:

思路:如果資料整體並不要求有序,則會使用combiner將資料整體進行combine操作,最終相同key的資料被聚合在一起。如果資料整體要求有序,則直接對有序的資料按照順序一邊聚合一邊迭代輸出下一個元素,最終資料是整體有序的。
建立索引檔案
其關鍵原始碼如下:

其思路很簡單,可以參考 spark shuffle寫操作三部曲之UnsafeShuffleWriter 對應部分的說明。
總結
在本篇文章中,剖析了spark shuffle的最後一種寫方式。溢位前資料使用陣列自定義的Map或者是列表來儲存,如果指定了aggerator,則使用Map結構,Map資料結構支援map端的預聚合操作,但是列表方式的不支援預聚合。
資料每次溢位資料都進行排序,如果指定了ordering,則先按分割槽排序,再按每個分割槽內的key排序,最終資料溢位到磁碟中的臨時檔案中,在merge階段,資料被SpillReader讀取出來和未溢位的資料整體排序,最終資料可以整體有序的落到最終的資料檔案中。
至此,spark shuffle的三種寫方式都剖析完了。之後會有文章來剖析shuffle的讀取操作。
不足之處:這篇文章歷時比較久,也由於平時工作原因,用的都是碎片時間,可能有一些部分思路接不上,可能還有部分類沒有剖析,望見諒,雖然本文有諸多問題,但是對預整體理解第三種shuffle的寫方式來說,都無足輕重