
yolo進化史之yolov2
yolov1和當時最好的目標檢測系統相比,有很多缺點.比如和Fast R-CNN相比,定位錯誤更多.和基於區域選擇的目標檢測方法相比,recall也比較低.yolov2的目標即在保證分類準確度的情況下,儘可能地去提高recall和定位精度.
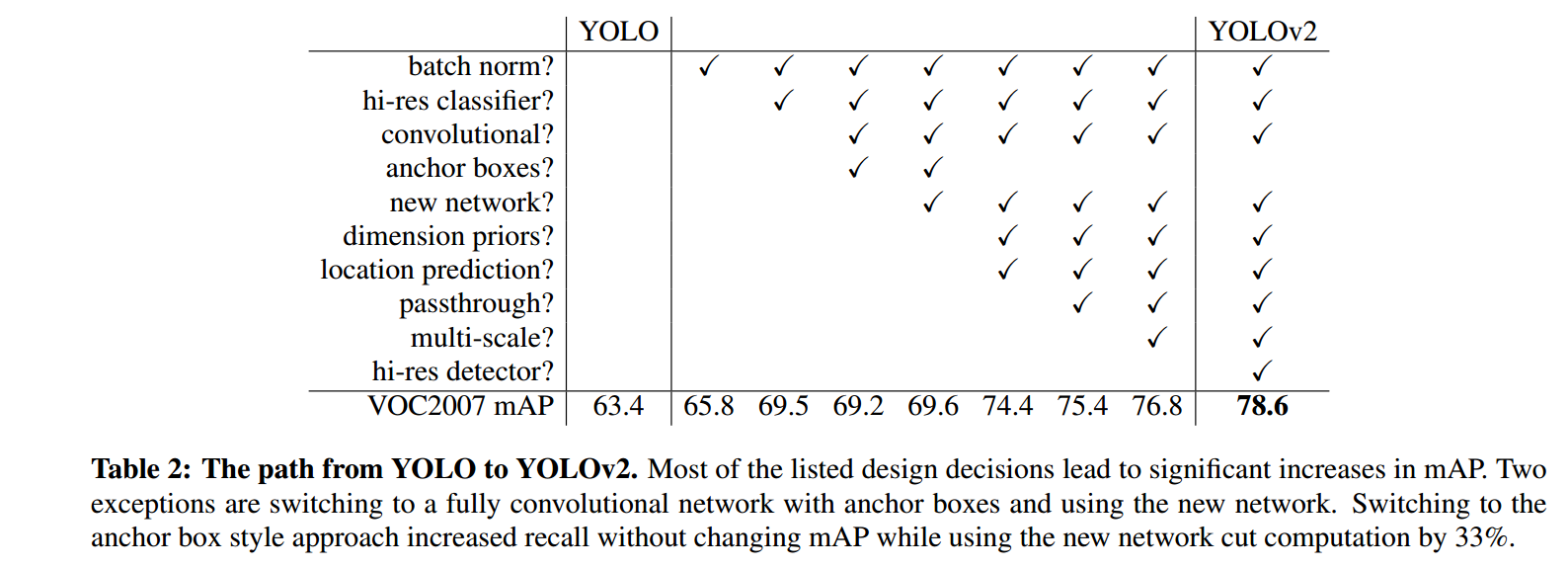
上圖是yolo嘗試了的方法.
可以看到使得檢測精度得到大幅提升的主要就是hi-res classifier和dimension priors && location prediction
Batch Normalization
bn使得mAP提高了2%.並且可以去掉dropout而不帶來過擬合.
High Resolution Classifier
yolo可以看成2部分組成,一個是特徵提取部分,這部分就是分類網路的全連線層之前的部分. 一個是yolo做預測的部分.
YOLO訓練分為兩個階段。首先,我們訓練一個像VGG16這樣的分類器網路。然後用卷積層替換全連線層,並對其進行端到端的再訓練,用於目標檢測。yolov1用224 * 224的圖片訓練分類器,然後用448 * 448的圖片做目標檢測。 yolov2在用224*224的圖片讀分類網路做訓練以後,再用10個迭代,用448*448的圖片去對網路做微調.這樣的話,卷積核的引數就可以更好地適應高解析度的輸入,然後用448*448的圖片去做檢測網路的訓練. 此舉提高了mAP 4%.
Convolutional With Anchor Boxes
yolov1用全連線層做box的座標預測. 這個會造成在訓練的初始,梯度不夠穩定,因為一開始預測的尺寸對某一物體有效,可能對另一物體無效.但是現實世界裡,目標的尺寸並不是隨機的,所以我們事先聚類好一些anchor box(錨或者叫先驗框),依次為基礎,去做box座標預測.
anchor的採用讓mAP從69.5掉到了69.2,但是recall從81%上升到了88%.
Using anchor boxes we get a small decrease in accuracy.
YOLO only predicts 98 boxes per image but with anchor
boxes our model predicts more than a thousand. Without
anchor boxes our intermediate model gets 69:5 mAP with a
recall of 81%. With anchor boxes our model gets 69:2 mAP
with a recall of 88%. Even though the mAP decreases, the
increase in recall means that our model has more room to
improve.
論文裡,這裡讓人有點迷惑,其實這裡說的anchor box是作者手工選擇的box,而不是k-means聚類出來的,採用了k-means聚類的box作為anchor box,把mAP提高了接近5%. 對應於文章開頭的圖裡的dimension priors. 聚類先驗框可以參考https://www.cnblogs.com/sdu20112013/p/10937717.html
去除全連線層
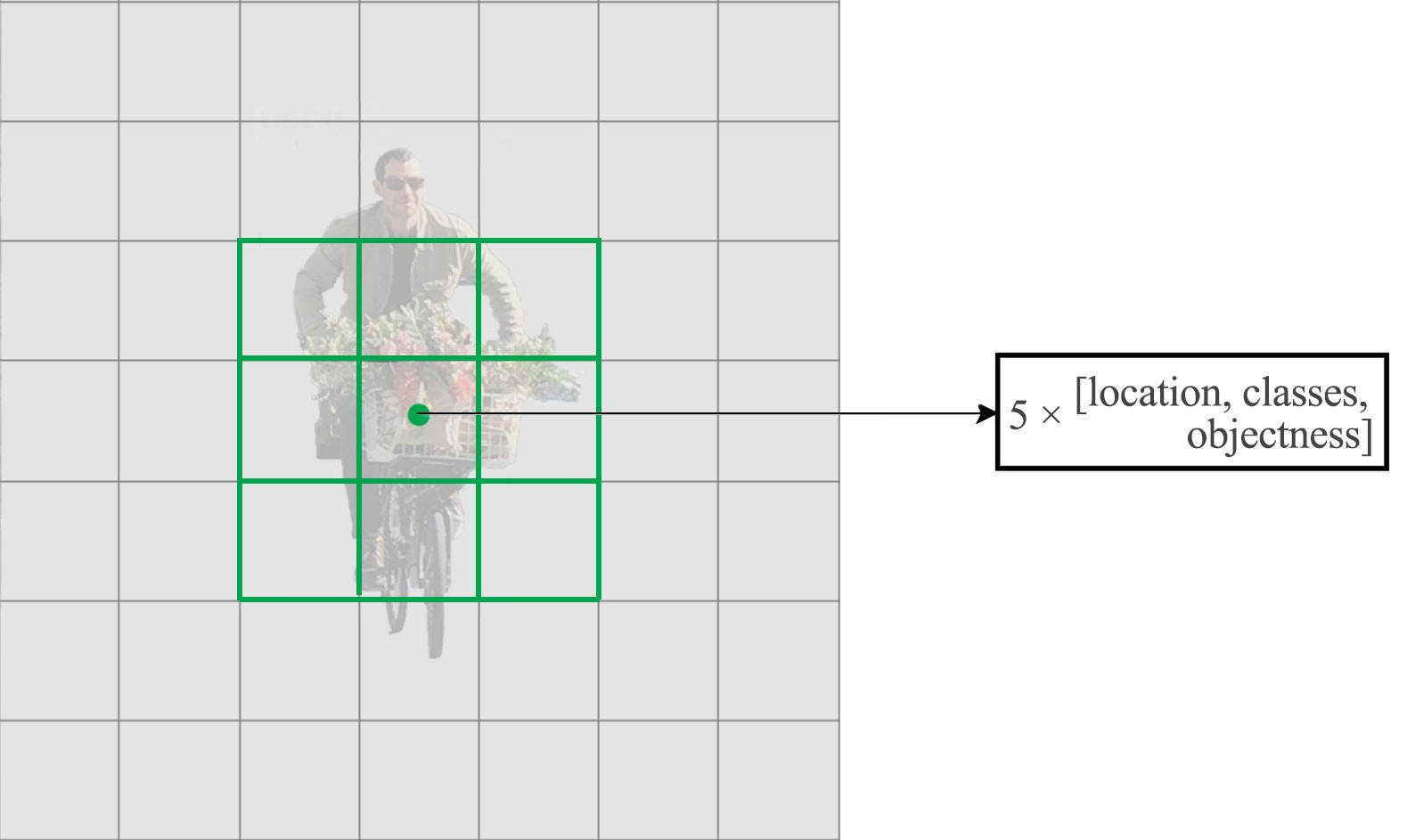
把對class的預測從cell級別調整到針對box.
yolov1每個cell預測出2個box,class個prob. yolov2有5個anchor box.依據每個anchor box預測出(1+4+20)個引數,所以每個cell預測出
5*(1+4+20)=125個引數.
- 影象輸入尺寸由448調整到416,同時去掉一個池化層
這樣最終得到的feature map的13*13的.

作者認為通常目標位於圖片中央,尤其是大目標,所以希望特徵圖是奇數的,這樣就有某一個確定的cell去預測目標而不是用臨近的4個cell.
We do this because we want an odd number of
locations in our feature map so there is a single center cell.
Objects, especially large objects, tend to occupy the center
of the image so it’s good to have a single location right at
the center to predict these objects instead of four locations
that are all nearby
- 去掉一個池化層使得最終輸出是 13×13 (instead of 7×7).
Direct location prediction
我們怎麼計算預測的box座標值呢?

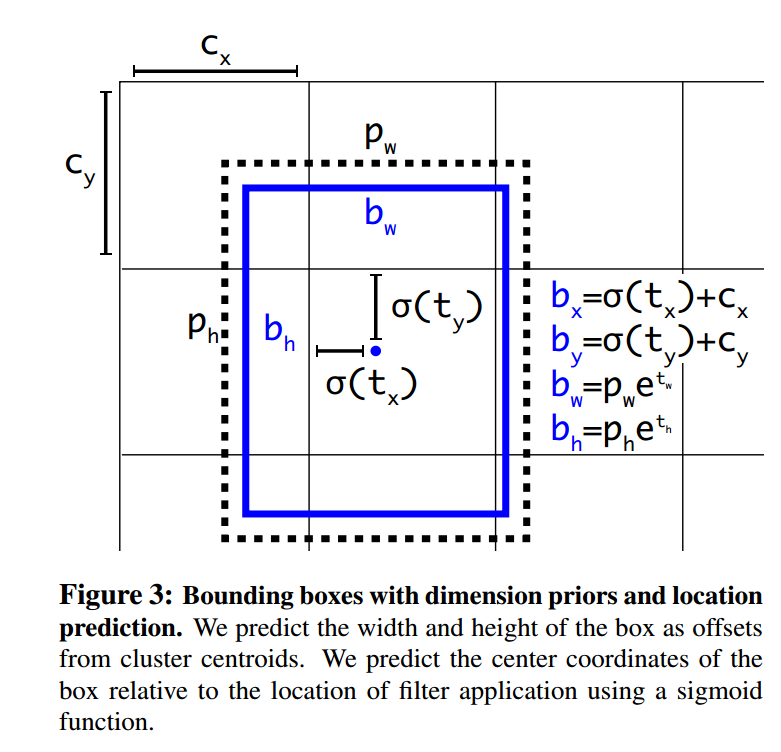
σ(tx)函式將預測值限定到了0-1之間.這樣就保證了我們預測出來的box仍然是圍繞著當前cell的.這一點也使得網路更穩定.
Since we constrain the location prediction the
parametrization is easier to learn, making the network
more stable. Using dimension clusters along with directly
predicting the bounding box center location improves
YOLO by almost 5% over the version with anchor boxes
Fine-Grained Features
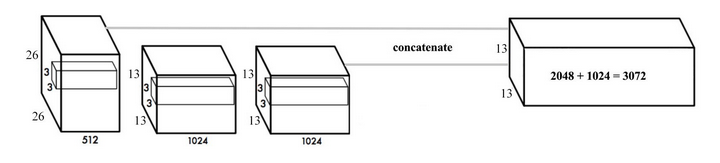
隨著卷積不斷進行,我們最終得到一個13*13的特徵圖.對大目標來說,基於這個特徵圖做預測是ok的,但是對小目標來說就沒那麼好了.Faster R-CNN或者SSD在不同的layer生成的特徵圖上去做位置的預測,相當於不同解析度的特徵圖負責不同尺寸的目標. yolo採取了一個不同的思路,把兩個layer的feature map連成一個.稱之為passthrough,在此基礎去做預測.如下圖:
Multi-Scale Training
由於去掉了全連線層,模型的輸入可以使任意size.為了讓yolov2有更好的魯棒性,在訓練的時候,我們每10個batch就隨機改變input的size.由於模型是進行32倍下采樣的,所以我們把input size改變成320,352...608這些尺寸.
以上是yolov2提升準確率所做的改造.現在我們來看下為了更快的推理速度,yolov2都做了什麼.
Googlenet
大部分檢測網路是以VGG-16做為特徵提取器的.以一個224*224的圖片為例,一次前向傳播,VGG-16有30.69 billion次浮點數運算.yolo用了一個基於googlenet的定製化的網路,一次前向傳播只有8.52 billion次運算.相應的,代價是準確率的稍微下降.
Darknet-19
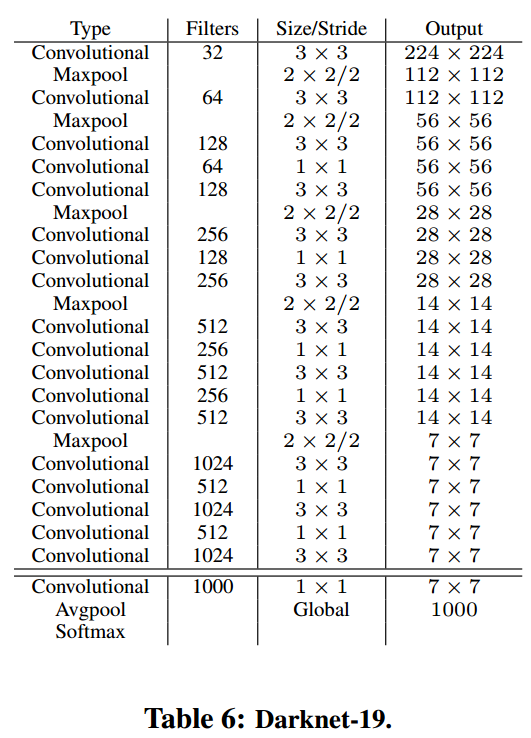
作者繼續去簡化特徵提取層的網路結構.如上圖. 注意上圖份兩部分. 最後三層(conv,avgpool,softmax)是做分類的.前面的n層是做特徵提取的.
對這個分類網路,先在ImageNet做分類的訓練,把特徵提取的網路的引數訓練出來,先用224*224的做訓練,再用448*448的做微調.之後保持特徵提取部分的網路不變,把最後幾層替換掉,去做檢測網路的訓練.如下圖

參考:https://arxiv.org/abs/1612.08242