
關係抽取之遠端監督演算法
一、 關係抽取綜述
二、 遠端監督關係抽取演算法的濫觴
三、 多例項學習和分段最大池化
四、 句子級別的注意力機制
一、關係抽取綜述
資訊抽取是自然語言處理中非常重要的一塊內容,包括實體抽取(命名實體識別,Named Entity Recognition)、關係抽取(Relation Extraction)和事件抽取(Event Extraction)。
這次介紹的關係抽取屬於自然語言理解(NLU)的範疇,也是構建和擴充套件知識圖譜的一種方法。
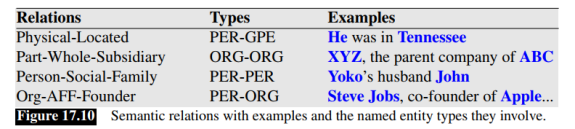
關係抽取理解起來也比較簡單,比如下面圖片中的第一句話:
He was in Tennessee.
首先做命名實體識別,識別出He(PER)和Tennessee(GPE)兩個實體,然後找出兩個實體之間的關係為:Physical-Located,最後可以把抽取出來的關係表示為三元組的形式:(HePER, Physical-Located, TennesseeGPE),或者Physical-Located(HePER, TennesseeGPE)。
可見關係抽取包含命名實體識別在內,在技術實現上更復雜。
關係抽取從流程上,可以分為流水線式抽取(Pipline)和聯合抽取(Joint Extraction)兩種,流水線式抽取就是把關係抽取的任務分為兩個步驟:首先做實體識別,再抽取出兩個實體的關係;而聯合抽取的方式就是一步到位,同時做好了實體和關係的抽取。流水線式抽取會導致誤差在各流程中傳遞和累加,而聯合抽取的方式則實現難度更大。
關係抽取從實現的演算法來看,主要分為四種:
1、手寫規則(Hand-Written Patterns);
2、監督學習演算法(Supervised Machine Learning);
3、半監督學習演算法(Semi-Supervised Learning,比如Bootstrapping和Distant Supervision);
4、無監督演算法。
本文的主人公是遠端監督演算法(Distant Supervision),這是一種半監督學習演算法。其他的方法大致瞭解一下,有助於理解,為什麼相對而言,遠端監督做關係抽取是一種比較可行的方法。
(一)手寫規則模板的方法
1、例子:
有種關係叫做上下位關係,比如hyponym(France; European countries)。從下面兩個句子中都可以抽取出這種關係:
European countries, especially France, England, and Spain...
European countries, such as France, England, and Spain...
兩個實體之間的especially和such as可以看做這種關係的特徵。觀察更多表達這種關係的句子,我們就可以構造如下的規則模板,來抽取構成上下位關係的實體,從而發現新的三元組。

2、優點和缺點:
優點是抽取的三元組查準率(Precision)高,尤其適合做特定領域的關係抽取;缺點是查全率(Recall)很低,也就是說查得準,但是查不全,而且針對每一種關係都需要手寫大量的規則,比較慘。
(二)監督學習的方法
監督學習的方法也就是給訓練語料中的實體和關係打上標籤,構造訓練集和測試集,再用傳統機器學習的演算法(LR,SVM和隨機森林等)或神經網路訓練分類器。
1、機器學習和深度學習方法
對於傳統的機器學習方法,最重要的步驟是構造特徵。可以使用的特徵有:
(1)詞特徵:實體1與實體2之間的詞、前後的詞,詞向量可以用Bag-of-Words結合Bigrams等。
(2)實體標籤特徵:實體的標籤。
(3)依存句法特徵:分析句子的依存句法結構,構造特徵。這個不懂怎麼弄。

人工構造特徵非常麻煩,而且某些特徵比如依存句法分析,依賴於NLP工具庫,比如HanLP,工具帶來的誤差不可避免會影響特徵的準確性。
用端到端的深度學習方法就沒這麼費勁了。比如使用CNN或BI-LSTM作為句子編碼器,把一個句子的詞嵌入(Word Embedding)作為輸入,用CNN或LSTM做特徵的抽取器,最後經過softmax層得到N種關係的概率。這樣省略了特徵構造這一步,自然不會在特徵構造這裡引入誤差。
2、監督學習的優缺點
監督學習的優點是,如果標註好的訓練語料足夠大,那麼分類器的效果是比較好的,可問題是標註的成本太大了。
(三)半監督
鑑於監督學習的成本太大,所以用半監督學習做關係抽取是一個很值得研究的方向。
半監督學習的演算法主要有兩種:Bootstrapping和Distant Supervision。Bootstrapping不需要標註好實體和關係的句子作為訓練集,不用訓練分類器;而Distant Supervision可以看做是Bootstrapping和Supervise Learning的結合,需要訓練分類器。
這裡介紹Bootstrapping的思想,Distant Supervision作為主人公,在後面的部分詳細介紹。
1、例子
Bootstrapping演算法的輸入是擁有某種關係的少量實體對,作為種子,輸出是更多擁有這種關係的實體對。敲黑板!不是找到更多的關係,而是發現擁有某種關係的更多新實體對。
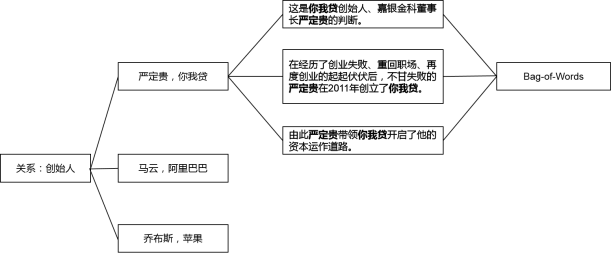
怎麼做的呢?舉個栗子,“創始人”是一種關係,如果我們已經有了一個小型知識圖譜,裡面有3個表達這種關係的實體對:(嚴定貴,你我貸),(馬雲,阿里巴巴),(雷軍,小米)。
第一步:在一個大型的語料集中去找包含某一實體對(3箇中的任意1個)的句子,全部挑出來。比如:嚴定貴於2011年創立了你我貸;嚴定貴是你我貸的創始人;在嚴定貴董事長的帶領下,嘉銀金科赴美上市成功。
第二步:歸納實體對的前後或中間的詞語,構造特徵模板。比如:A 創立了 B;A 是 B 的創始人;A 的帶領下,B。
第三步:用特徵模板去語料集中尋找更多的實體對,然後給所有找到的實體對打分排序,高於閾值的實體對就加入到知識圖譜中,擴充套件現有的實體對。
第四步:回到第一步,進行迭代,得到更多模板,發現更多擁有該關係的實體對。

細心的小夥伴會發現,不是所有包含“嚴定貴”和“你我貸”的句子都表達了“創始人”這種關係啊,比如:“在嚴定貴董事長的帶領下,嘉銀金科赴美上市成功”——這句話就不是表達“創始人”這個關係的。某個實體對之間可能有很多種關係,哪能一口咬定就是知識圖譜中已有的這種關係呢?這不是會得到錯誤的模板,然後在不斷的迭代中放大錯誤嗎?
沒錯,這個問題叫做語義漂移(Semantic Draft),一般有兩種解決辦法:
一是人工校驗,在每一輪迭代中觀察挑出來的句子,把不包含這種關係的句子剔除掉。
二是Bootstrapping演算法本身有給新發現的模板和實體對打分,然後設定閾值,篩選出高質量的模板和實體對。具體的公式可以看《Speech and Language Processing》(第3版)第17章。
2、Bootstrapping的優缺點
Bootstrapping的缺點一是上面提到的語義漂移問題,二是查準率會不斷降低而且查全率太低,因為這是一種迭代演算法,每次迭代準確率都不可避免會降低,80%---->60%---->40%---->20%...。所以最後發現的新實體對,還需要人工校驗。
(四)無監督
半監督的辦法效果已經勉強,無監督的效果就更差強人意了,這裡就不介紹了。
二、遠端監督關係抽取演算法的濫觴
第一篇要介紹的論文是《Distant supervision for relation extraction without labeled data》,斯坦福大學出品,把遠端監督的方法用於關係抽取。研究關係抽取的遠端監督演算法,不得不提這篇論文。
(一)遠端監督的思想
這篇論文首先回顧了關係抽取的監督學習、無監督學習和Bootstrapping演算法的優缺點,進而結合監督學習和Bootstrapping的優點,提出了用遠端監督做關係抽取的演算法。
遠端監督演算法有一個非常重要的假設:對於一個已有的知識圖譜(論文用的Freebase)中的一個三元組(由一對實體和一個關係構成),假設外部文件庫(論文用的Wikipedia)中任何包含這對實體的句子,在一定程度上都反映了這種關係。基於這個假設,遠端監督演算法可以基於一個標註好的小型知識圖譜,給外部文件庫中的句子標註關係標籤,相當於做了樣本的自動標註,因此是一種半監督的演算法。
具體來說,在訓練階段,用命名實體識別工具,把訓練語料庫中句子的實體識別出來。如果多個句子包含了兩個特定實體,而且這兩個實體是Freebase中的實體對(對應有一種關係),那麼基於遠端監督的假設,認為這些句子都表達了這種關係。於是從這幾個句子中提取文字特徵,拼接成一個向量,作為這種關係的一個樣本的特徵向量,用於訓練分類器。
論文中把Freebase的資料進行了處理,篩選出了94萬個實體、102種關係和180萬實體對。下面是實體對數量最多的23種關係。
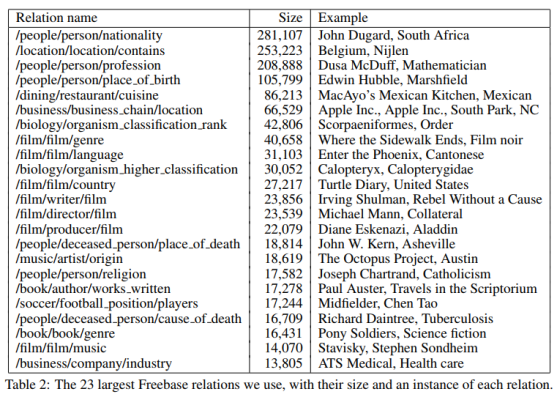
關係種類相當於分類的類別,那麼有102類;每種關係對應的所有實體對就是樣本;從Wikipedia中所有包含某實體對的句子中抽取特徵,拼接成這個樣本的特徵向量。最後訓練LR多分類器,用One-vs-Rest,而不是softmax,也就是訓練102個LR二分類器——把某種關係視為正類,把其他所有的關係視為負類。
因為遠端監督演算法可以使用大量無標籤的資料,Freebase中的每一對實體在文件庫中可能出現在多個句子中。從多個句子中抽出特徵進行拼接,作為某個樣本(實體對)的特徵向量,有兩個好處:
一是單獨的某個句子可能僅僅包含了這個實體對,並沒有表達Freebase中的關係,那麼綜合多個句子的資訊,就可以消除噪音資料的影響。
二是可以從海量無標籤的資料中獲取更豐富的資訊,提高分類器的準確率。
但是問題也來了,這個假設一聽就不靠譜!哪能說一個實體對在Freebase中,然後只要句子中出現了這個實體對,就假定關係為Freebase中的這種關係呢?一個實體對之間的關係可能有很多啊,比如馬雲和阿里巴巴的關係,就有“董事長”、“工作”等關係,哪能斷定就是“創始人”的關係呢?
這確實是個大問題,在本篇論文中也沒有提出解決辦法。
(二)分類器的特徵
論文中使用了三種特徵:詞法特徵(Lexical features)、句法特徵(Syntactic features)和實體標籤特徵(Named entity tag features)。
1、詞法特徵
詞法特徵描述的是實體對中間或兩端的特定詞彙相關的資訊。比如有:
- 兩個實體中間的詞語和詞性
- 實體1左邊的k個詞語和詞性,k取{0,1,2}
- 實體2右邊的k個詞語和詞性,k取{0,1,2}
然後把這些特徵表示成向量再拼接起來。比如用詞袋模型,把詞語和詞性都表示為向量。
2、句法特徵
論文中的句法特徵就是對句子進行依存句法分析(分析詞彙間的依存關係,如並列、從屬、遞進等),得到一條依存句法路徑,再把依存句法路徑中的各成分作為向量,拼接起來。
如下為一個句子的依存句法路徑,我不太懂,不多說。

3、命名實體標籤特徵
論文中做命名實體識別用的是斯坦福的NER工具包。把兩個實體的標籤也作為特徵,拼接起來。
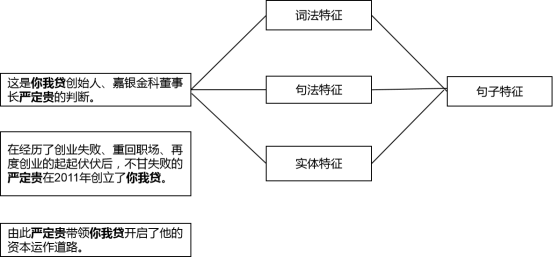
總結一下,論文中使用的特徵不是單個特徵,而是多種特徵拼接起來的。有多個句子包含某實體對,可以從每個句子中抽取出詞法特徵、句法特徵和實體特徵,拼接起來,得到一個句子的特徵向量,最後把多個句子的特徵向量再拼接起來,得到某實體對(一個樣本)的特徵向量。
不過作者為了比較詞法特徵和句法特徵的有效性,把特徵向量分為了3種情況:只使用詞法特徵,只使用句法特徵,詞法特徵與句法特徵拼接。

(三)實驗細節
1、資料集說明
知識圖譜或者說標註資料為Freebase,非結構化文字庫則是Wikipedia中的文章。
論文中把Freebase的三元組進行了篩選,篩選出了94萬個實體、102種關係和相應的180萬實體對。用留出法進行自動模型評估時,一半的實體對用於訓練,一半的實體對用於模型評估。
同樣對Wikipedia中的文章進行篩選,得到了180萬篇文章,平均每篇文章包含約14.3個句子。從中選擇80萬條句子作為訓練集,40萬條作為測試集。
2、構造負樣本
由於對於每種關係,都要訓練一個LR二分類器,所以需要構造負樣本。這裡的負樣本不是其他101種關係的訓練樣本,而是這樣的句子:從訓練集中的句子中抽取實體對,如果實體對不在Freebase中,那麼就隨機挑選這樣的句子就作為負樣本。
3、訓練過程
LR分類器以實體對的特徵向量為輸入,輸出關係名和概率值。每種關係訓練一個二分類器,一共訓練102個分類器。
訓練好分類器後,對測試集中的所有實體對的關係進行預測,並得到概率值。然後對所有實體對按概率值進行降序排列,從中挑選出概率最高的N個實體對(概率值大於0.5),作為發現的新實體對。
4、測試方法和結論
測試的指標採用查準率,方法採用了留出法(自動評估)和人工評估兩種方法。留出法的做法是,把Freebase中的180萬實體對的一半作為測試集(另一半用於訓練)。新發現的N個實體對中,如果有n個實體對在Freebase的測試集中,那麼查準率為n/N。人工評估則採用多數投票的方法。
模型評估的結果表明,遠端監督是一種較好的關係抽取演算法。在文字特徵的比較上,詞法特徵和句法特徵拼接而成的特徵向量,優於單獨使用其中一種特徵的情況。此外,句法特徵在遠端監督中比詞法特徵更有效,尤其對於依存句法結構比較短而實體對之間的詞語非常多的句子。

(四)評價
這篇論文把遠端監督的思想引入了關係抽取中,充分利用未標註的非結構化文字,從詞法、句法和實體三方面構造特徵,最後用留出法和人工校驗兩種方法進行模型評估,是一種非常完整規範的關係抽取正規化。
不足之處有兩點:
第一個是前面所提到的問題,那就是遠端監督所基於的假設是一個非常強的假設。哪能說一個實體對在Freebase中存在一種關係,那麼只要外部語料庫中的句子中出現了這個實體對,就假定關係為Freebase中的關係呢?還可能是其他關係啊?
Bootstrapping中也有這個問題,稱為語義漂移問題,但Bootstrapping本身通過給新發現的規則模板和實體對打分,在一定程度上緩解了這個問題,而這篇論文並沒有提到這個問題,更沒有涉及到解決辦法。我猜這是因為Freebase中的實體對和關係主要就是從Wikipedia中抽取出來的,而且關係屬於比較典型的關係。
這點就成了後續遠端監督關係抽取演算法的一個改進方向,後面的研究人員提出了利用多例項學習和句子級別的注意力機制來解決這個問題。
第二個是論文中用到了三種特徵,貌似一頓操作猛如虎,但實際上構造這些特徵非常繁瑣,而且詞性標註和依存句法分析依賴於NLP工具庫,因此工具庫在標註和解析中所產生的誤差,自然會影響到文字特徵的準確性。
這點也是後續研究的一個改進方向,後面的研究人員用神經網路作為特徵提取器,代替人工提取的特徵,並用詞嵌入作為文字特徵。
三、多例項學習和分段最大池化
第二篇論文是《Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks》,是用神經網路結合遠端監督做關係抽取的扛鼎之作。
(一)論文的貢獻
1、用PCNNs的神經網路結構自動學習文字特徵,代替複雜的人工構造特徵和特徵處理流程。
PCNNs全名為Piecewise Convolutional Neural Networks,包含兩層含義:Piecewise max pooling layer和Convolutional Neural Networds,對應到最大池化層和卷積層。用卷積神經網路強大的特徵提取功能,能自動抽取豐富的特徵,並且減少人工設計特徵和NLP工具庫抽取特徵帶來的誤差。省時省力又能減少誤差,何樂不為。
2、設計了分段最大池化層(三段,Piecewise max pooling layer)代替一般的最大池化層,提取更豐富的文字結構特徵。
一般的最大池化層直接從多個特徵中選出一個最重要的特徵,實際上是對卷積層的輸出進行降維,但問題是維度降低過快,無法獲取實體對在句子中所擁有的結構資訊。
如下圖,把一個句子按兩個實體切分為前、中、後三部分的詞語,然後將一般的最大池化層相應地劃分為三段最大池化層,從而獲取句子的結構資訊。

3、用多例項學習(Multi-Instances Learning)解決遠端監督做自動標註的錯誤標註問題。
遠端監督本質上是一種自動標註樣本的方法,但是它的假設太強了,會導致錯誤標註樣本的問題。
論文認為遠端監督做關係抽取類似於多例項問題(Multi-Instances Problem)。知識圖譜中一個實體對(論文中的Bag)的關係是已知的,而外部語料庫中包含該實體對的多個句子(Instances of Bag),表達的關係是未知的(自動標註的結果未知真假),那麼多例項學習的假設是:這些句子中至少有一個句子表達了已知的關係。於是從多個句子中只挑出最重要的一個句子,作為這個實體對的樣本加入到訓練中。
本篇論文設計了一個目標函式,在學習過程中,把句子關係標籤的不確定性考慮進去,從而緩解錯誤標註的問題。
總結一下,本文的亮點在於把多例項學習、卷積神經網路和分段最大池化結合起來,用於緩解句子的錯誤標註問題和人工設計特徵的誤差問題,提升關係抽取的效果。
(二)研究方法
本文把PCNNs的神經網路結構和多例項學習結合,完成關係抽取的任務。
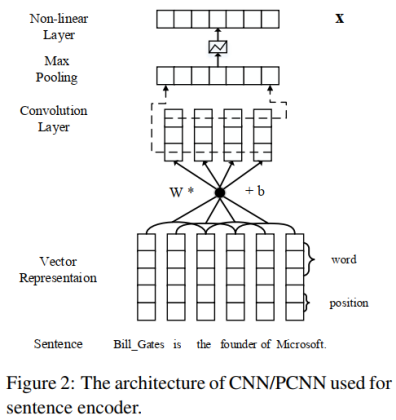
1、PCNNs網路的處理流程
PCNNs網路結構處理一個句子的流程分為四步:特徵表示、卷積、分段最大池化和softmax分類。具體如下圖所示。
(1)文字特徵表示
(1)文字特徵表示
使用詞嵌入(Word Embeddings)和位置特徵嵌入(Position Embeddings),然後把句子中每個詞的這兩種特徵拼接起來。
詞嵌入使用的是預訓練的Word2Vec詞向量,用Skip-Gram模型來訓練。
位置特徵是某個詞與兩個實體的相對距離,位置特徵嵌入就是把兩個相對距離轉化為向量,再拼接起來。
比如下面這個句子中,單詞son和實體Kojo Annan的相對距離為3,和實體Kofi Annan的相對距離為-2。

假設詞嵌入的維度是dw,位置特徵嵌入的維度是dp,那麼每個詞的特徵向量的維度就是:d=dw+2*dp。假設句子長度為s,那麼神經網路的輸入就是s×d維的矩陣。
(2)卷積
假設卷積核的寬為w(滑動視窗),長為d(詞的特徵向量維度),那麼卷積核的大小為W=w * d。步長為1。
輸入層為q = s×d維的矩陣,卷積操作就是每滑動一次,就用卷積核W與q的w-gram做點積,得到一個數值。

卷積完成後會得到(s+w-1)個數值,也就是長度為(s+w-1)的向量c。文字的卷積和影象的卷積不同,只能沿著句子的長度方向滑動,所以得到的是一個向量而不是矩陣。
為了得到更豐富的特徵,使用了n個卷積核W={W1, W2, ... Wn},第i個卷積核滑動一次得到的數值為:
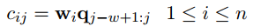
最終,卷積操作完成後會輸出一個矩陣C:
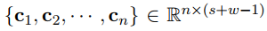
(3)分段最大池化
把每個卷積核得到的向量ci按兩個實體劃分為三部分{ci1, ci2, ..., ci3},分段最大池化也就是分別取每個部分的最大值:
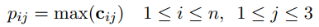
那麼對於每個卷積核得到的向量ci,我們都能得到一個3維的向量pi。為了便於下一步輸入到softmax層,把n個卷積核經過池化後的向量pi拼接成一個向量p1:n,長度為3n。
最後用tanh啟用函式進行非線性處理,得到最終的輸出:

(4)softmax多分類
把池化層得到的g輸入到softmax層,計算屬於每種關係的概率值。論文中使用了Dropout正則化,把池化層的輸出g以r的概率隨機丟棄,得到的softmax層的輸出為:
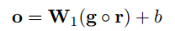

輸出的向量是關係的概率分佈,長度為關係的種類(n1)。概率值最大的關係就是句子中的實體對被預測的關係。
2、多例項學習的過程
我們知道一般神經網路模型的套路是,batch-size個句子經過神經網路的sotfmax層後,得到batch-size個概率分佈,然後與關係標籤的one-hot向量相比較,計算交叉熵損失,最後進行反向傳播。因此上述PCNNs網路結構的處理流程僅是一次正向傳播的過程。
PCNNs結合多例項學習的做法則有些差別,目標函式仍然是交叉熵損失函式,但是基於實體對級別(論文中的bags)去計算損失,而不是基於句子級別(論文中的instances)。這是什麼意思呢?
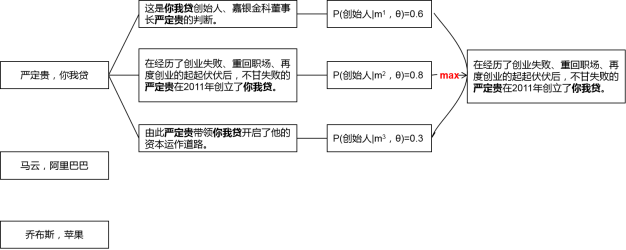
對照上面的圖,計算交叉熵損失分為兩步:
第一步,對於每個實體對,會有很多包含該實體對的句子(qi個),每個句子經過softmax層都可以得到一個概率分佈,進而得到預測的關係標籤和概率值。為了消除錯誤標註樣本的影響,從這些句子中僅挑出一個概率值最大的句子和它的預測結果,作為這個實體對的預測結果,用於計算交叉熵損失。比如上面的例子中,挑出了第二個句子。公式為:

第二步,如果一個batch-size有T個實體對,那麼用第一步挑選出來的T個句子,計算交叉熵損失:
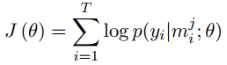
最後用梯度下降法求出梯度,並進行誤差反向傳播。
如下是演算法的虛擬碼,θ是PCNNs的引數,Eq.(9)是第一步中的公式。

(四)實驗細節
1、資料集和評估方法
知識圖譜為Freebase,外部文件庫為NYT。把NYT文件庫中2005-2006年的句子作為訓練集,2007年的句子作為測試集。
評估方法沿用第一篇論文中的方法,留出法和人工校驗相結合。
2、詞嵌入和調參
預訓練的詞向量方面,本文用Skip-Gram模型和NYT文件庫訓練了50維的詞向量。
位置特徵嵌入使用隨機初始化的向量,維度為5。
調參方面,PCNNs網路結構中有兩個引數比較重要:卷積核的滑動視窗大小和卷積核的個數。本文使用網格搜尋,最終確定滑動視窗為3,卷積核個數為230。
模型的其他引數如下:

3、模型評估結果
(1)對留出法和人工校驗法的說明
使用留出法和人工校驗法來評估模型的效果。這裡對這兩種評估方法進行補充說明:
留出法的做法是把Freebase中一半的實體對用於訓練,一半的實體對用於測試。多分類模型訓練好之後,對外部文件庫NYT中的測試集進行預測,得到測試集中實體對的關係標籤。如果新發現的實體對有N個,其中有n個出現在Freebase的測試集中,那麼準確率為n/N,而不在Freebase測試集中的實體對就視為不存在關係。可是由於Freebase中的實體對太少了,新發現的、不在Freebase裡的實體對並非真的不存在關係,這就會出現假負例(False Negatives)的問題,低估了準確率。
所以人工校驗的方法是對留出法的一個補充,對於那些新發現的、不在Freebase測試集中的實體對(一個實體不在或者兩個實體都不在)進行檢查,計算查準率。所以留出法和人工校驗要評估的兩個新實體對集合是沒有交集的。具體做法是從這些新實體對中選擇概率值最高的前N個,然後人工檢查其中關係標籤正確的實體對,如果有n個,那麼查準率為n/N。
(2)卷積神經網路與人工構造特徵的對比
首先把PCNNs結合多例項學習的遠端監督模型(記為PCNNs+MIL),與人工構造特徵的遠端監督演算法(記為Mintz)和多例項學習的演算法(記為MultiR和MIML)進行比較。
從下面的實驗結果中可以看到,無論是查準率還是查全率,PCNNs+MIL模型都顯著優於其他模型,這說明用卷積神經網路作為自動特徵抽取器,可以有效降低人工構造特徵和NLP工具提取特徵帶來的誤差。

(3)分段最大池化和多例項學習的有效性
將分段最大池化和普通的最大池化的效果進行對比(PCNNs VS CNNs),將結合多例項學習的卷積網路與單純的卷積網路進行對比(PCNNs+MIL VS PCNNs)。
可以看到,分段最大池化比普通的最大池化效果更好,表明分段最大池化可以抽取更豐富的結構特徵。把多例項學習加入到卷積網路中,效果也有一定的提升,表明多例項學習可以緩解樣本標註錯誤的問題。

(四)評價
這篇論文中,分段最大池化的奇思妙想來自於傳統人工構造特徵的思想,而多例項學習的引入緩解了第一篇論文中的樣本錯誤標註問題。這篇論文出來以後是當時的SOTA。
不足之處在於,多例項學習僅從包含某個實體對的多個句子中,挑出一個最可能的句子來訓練,這必然會損失大量的資訊。所以有學者提出用句子級別的注意力機制來解決這個問題。
四、句子級別的注意力機制
第三篇論文是《Neural Relation Extraction with Selective Attention over Instances》,這篇論文首次把注意力機制引入到了關係抽取的遠端監督演算法中,重新整理了當時的SOTA。論文作者中有知乎網紅劉知遠老師。
(一)論文的貢獻
這篇論文要解決的問題,就是多例項學習會遺漏大量資訊的問題。所以這篇論文用句子級別的注意力機制代替多例項學習,對於包含某實體對的所有句子,給每一個句子計算一個注意力得分,動態地降低標註錯誤的樣本的得分,再進行加權求和,從而充分利用所有句子的資訊。
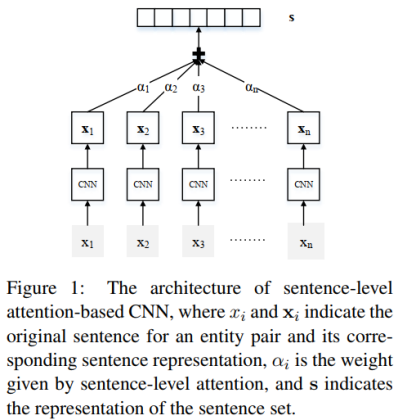
多例項學習相當於硬注意力機制(Hard Attention),而我們耳熟能詳的以及論文中用到的注意力機制是選擇性注意力機制(Selective Attention)或者說軟注意力機制(Soft Attention),所以多例項學習其實是選擇性注意力機制的特殊情況(只有一個句子的權重為1,其他全為0)。
(二)模型介紹
模型主要分為兩個部分:句子編碼器和注意力層。
1、句子編碼器
句子編碼器就是上一篇論文中的PCNN或CNN網路結構,由卷積神經網路的輸入層、卷積層、池化層、非線性對映層(或者說啟用函式)構成。
文字特徵同樣用詞嵌入和位置特徵嵌入,池化層用普通的最大池化或者分段最大池化。
因此,本文的句子編碼器部分輸出的是一個句子經過最大池化並且非線性啟用後的特徵向量,用於輸入到注意力層。這部分和上一篇論文基本相同,無須贅述。
2、注意力層
句子編碼器的作用是抽取一個句子的特徵,得到一個特徵向量。如果外部文件庫中包含某實體對的句子有n條,那麼經過句子編碼器的處理後,可以得到n個特徵向量:x1, x2, ..., xn。在句子編碼器和softmax層之間加一個選擇性注意力層,那麼處理的步驟如下:
第一步:計算句子的特徵向量xi和關係標籤r的匹配度ei,並計算注意力得分αi。公式中的r是關係標籤的向量表示。

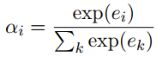
第二步:計算該實體對的特徵向量s。該實體對的特徵向量是所有句子的特徵向量xi的加權之和,權重為每個句子的注意力得分αi。

第三步:經過softmax層得到該實體對關於所有關係的概率分佈,概率值最大的關係為預測的關係標籤。
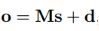
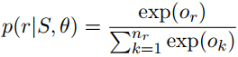
3、誤差反向傳播
如果一個batch-size有s個實體對,那麼用s個實體對的概率分佈,計算交叉熵損失:
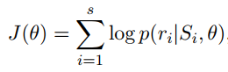
最後用梯度下降法求出梯度,並進行誤差反向傳播。
(三)實驗細節
1、資料集和評估方法
資料集和上一篇論文一樣,知識圖譜是Freebase,外部的文件庫是NYT(New York Times corpus)。劃分資料集的做法也一致。
評估方法採用留出法,不再贅述。
2、詞嵌入和引數設定
用NYT資料集訓練Word2Vec,用網格搜尋(Grid Search)確定引數。

3、選擇性注意力機制的效果
句子編碼器分別採用CNN和PCNN的網路結構,PCNN+ONE表示PCNN結合多例項學習的模型,PCNN+ATT表示論文中的選擇性注意力模型,PCNN+AVE表示對各句子求算術平均的模型(每個句子的注意力得分相同)。
實驗結果表明,無論是CNN還是PCNN,加入注意力機制的模型在查準率和查全率上,都顯著優於其他模型。
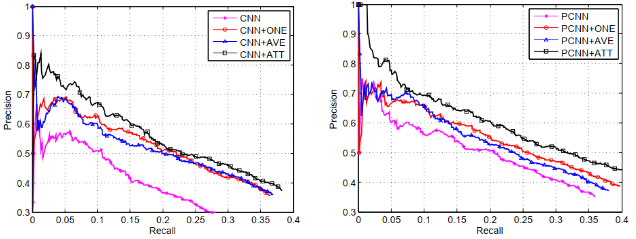
論文還有其他更細緻的實驗,欲知詳情,請自行翻看論文。
(四)評價
這篇論文把注意力機制和CNN句子編碼器結合,用來解決多例項學習存在的遺漏資訊問題,更好地緩解了遠端監督演算法中的樣本錯誤標註問題。
注意力機制在NLP任務中的效果是有目共睹的,PCNN+ATT的模型看起來非常漂亮,那麼有什麼改進方向呢?
開頭我們說了,關係抽取可以分為流水線式抽取(Pipline)和聯合抽取(Joint Extraction)兩種,流水線式抽取就是把關係抽取的任務分為兩個步驟:首先做實體識別,再抽取出兩個實體的關係;而聯合抽取的方式就是一步到位,同時抽取出實體和關係。
因此上面介紹的三篇論文中的模型都屬於流水線式抽取的方法,實體識別和關係抽取的模型是分開的,那麼實體識別中的誤差會影響到關係抽取的效果。而聯合抽取用一個模型直接做到了實體識別和關係抽取,是一個值得研究的方向。
參考資料:
1、《Speech and Language Processing》(Third Edition draft)第17章
2、《cs224u: Relation extraction with distant supervision》
3、《Distant supervision for relation extraction without labeled data》
4、《Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks》
5、《Neural Relation Extraction with Selective Attention over Instances》
6、《Joint Extraction of Entities and Relations Based on a Novel Tagging Schem