
09 線性迴歸及矩陣運算
阿新 • • 發佈:2019-12-01
09 線性迴歸及矩陣運算
線性迴歸
定義:通過一個或者多個自變數與因變數之間進行建模的迴歸分析。其中可以為一個或者多個自變數之間的線性組合。
一元線性迴歸:涉及到的變數只有一個
多元線性迴歸:變數兩個或以上通用公式:h(w) = w0 + w1x1 + w2x2 + ....= wTx
其中w,x 為矩陣:wT=(w0, w1, w2) x=(1,x1, x2)T
迴歸的應用場景 (連續型資料)
- 房價預測
- 銷售額預測 (廣告,研發成本,規模等因素)
- 貸款額度
線性關係模型
- 定義: 通過屬性 (特徵) 的線性組合來進行預測的函式:
- f(x) = w1x1 + w2x2 + w3x3 + ...... + wdxd + b
- w : weight (權重) b: bias (偏置項)
- 多個特徵: (w1:房子的面積, w2:房子的位置 ..)
損失函式(誤差)
- 《統計學習方法》 - 演算法 ,策略, 優化
- 線性迴歸, 最小二乘法,正規方程 & 梯度下降
- 損失函式(誤差大小)
- yi 為第i個訓練樣本的真實值
- hw(xi)為第i個訓練樣本特徵值組合預測函式 (預測值)
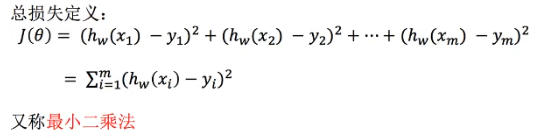
- 尋找最優化的w
- 最小二乘法之正規方程 (直接求解到最小值,特徵複雜時可能沒辦法求解)
- 求解:w= (xTx)-1 xTy
- X 為特徵值矩陣,y為目標值矩陣
- 缺點: 特徵過於複雜時,求解速度慢
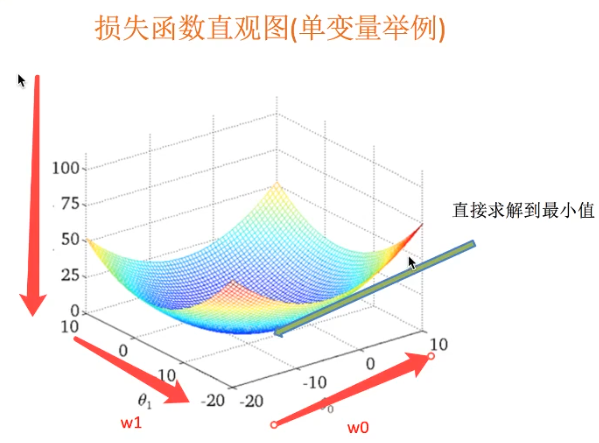
最小二乘法之梯度下降

- 使用場景:面對訓練資料規模龐大的任務
- 超引數:a
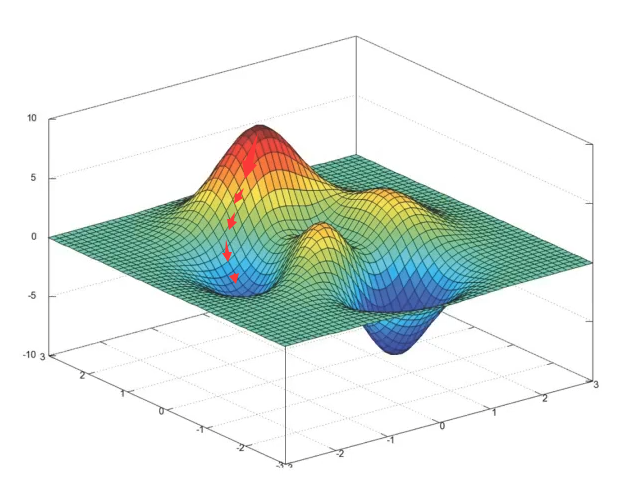
- 最小二乘法之正規方程 (直接求解到最小值,特徵複雜時可能沒辦法求解)
線性迴歸演算法案例
API
- sklearn.linear_model.LinealRegression()
- 普通最小二乘法線性迴歸
- coef_: 迴歸係數 (w值)
- sklearn.linear_model.SGDRegressir()
- 通過使用SGD最小化線性模型
- coef_: 迴歸係數
- 不能手動指定學習率
波士頓房價預測
from sklearn.datasets import load_boston from sklearn.linear_model import LinearRegression, SGDRegressor from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import mean_squared_error def mylinear(): """ 線性迴歸預測房價 :return: None """ # 1. 獲取資料 lb = load_boston() # 2. 分割資料集到訓練集和測試集 x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25) print(y_train, y_test) # 3. 進行標準化處理(特徵值和目標值都必須標準化處理) # 例項化兩個標準化API,特徵值和目標值要用各自fit # 特徵值 std_x = StandardScaler() x_train = std_x.fit_transform(x_train) x_test = std_x.transform(x_test) std_y = StandardScaler() y_train = std_y.fit_transform(y_train) y_test = std_y.transform(y_test) # 4. estimator預測 # 4.1 正規方程求解預測結果 lr = LinearRegression() lr.fit(x_train, y_train) print(lr.coef_) y_lr_predict = std_y.inverse_transform(lr.predict(x_test)) print('正規方程測試集裡面每個房子的預測價格:', y_lr_predict) print('正規方程的均方誤差:',mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict)) # 4.1 梯度下降進行梯度預測 sgd = SGDRegressor() lr.fit(x_train, y_train) print(sgd.coef_) y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test)) print('梯度下降測試集裡面每個房子的預測價格:', y_sgd_predict) print('梯度下降的均方誤差:', mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict)) return None if __name__ == '__main__': mylinear()
迴歸效能評估
均方誤差 (Mean Squared Error MSE) 評價機制
- mean_squared_error(y_true, y_pred)
- 真實值和預測值為標準化話之前的值

兩種預測方式的選擇
- 樣本量選擇
樣本量大於100K --> SGD 梯度下降
樣本量小於100K --> 其他
| 梯度下降 | 正規方程 |
|---|---|
| 需要選擇學習率 | 不需要 |
| 需要多次迭代 | 一次運算得出 |
| 當特徵數量大時也能較好使用 | 需要計算(xTx)-1,運算量大 |
| 適用於各種型別的模型 | 只適用於線性模型 |
- 特點:線性迴歸器是最為簡單、易用的迴歸模型,在不知道特徵之間關係的情況下,
可以使用線性迴歸器作為大多數系統的首要選擇。LinearRegression 不能解決擬合問題。
過擬合與欠擬合
- 定義:
過擬合(overfitting):一個假設在訓練資料上能夠獲得比其他假設更好的擬合,但是在訓練資料外卻不能很好擬合。(模型過於複雜)
模型複雜的原因: 資料的特徵和目標值之間的關係不僅僅是線性關係。欠擬合(underfitting):一個假設在訓練資料上不能獲得更好的擬合,但是在訓練資料外也不能很好的擬合。 (模型過於簡單)
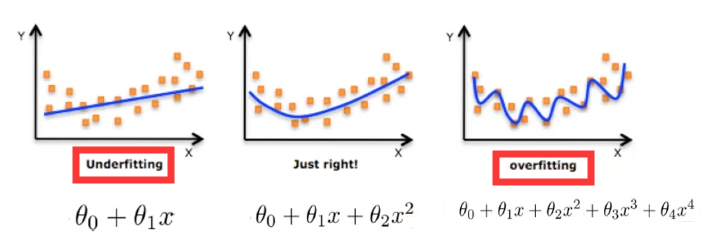
欠擬合原因及解決方法
- 原因: 學習到的資料特徵過少
- 解決方法: 增加資料的特徵數量
過擬合原因及解決方法
- 原因: 原始特徵過多,存在一些嘈雜特徵,模型過於複雜是因為模型嘗試去兼顧各個測試資料點
- 解決方法:
- 進行特徵選擇,消除關聯性很大的特徵(人為排除,很難做)
- 交叉驗證(讓所有資料都有過訓練)- 檢驗但不能解決
- 正則化 :不斷嘗試,減少權重(高次項特徵的影響)
- 特徵選擇:
- 過濾式:低方差特徵
- 嵌入式:正則化,決策樹,神經網路
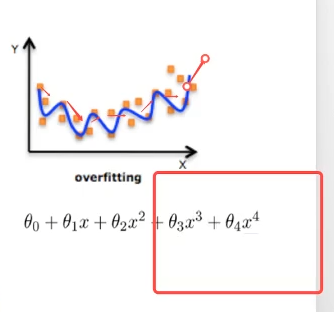
(減少高指數項係數,趨近於0,減少權重)
L2正則化
- 作用:可以使得W的每個元素都很小,都接近於0
- 優點:越小的引數說明模型越簡單,越簡單的模型越不容易產生過擬合現象。
- 迴歸解決過擬合的方式:
L2正則化, Ridge:嶺迴歸:帶有正則化的線性迴歸,解決過擬合。
Ridge API
sklearn.linear_model.Ridge(alpha=1.0)
- 具有L2正則化的線性最小二乘法
- alpha: 正則化力度 0~1(小數), 1~10(整數)
- coef_: 迴歸係數
正則化力度對權重的影響 (力度越大,越趨向於0)
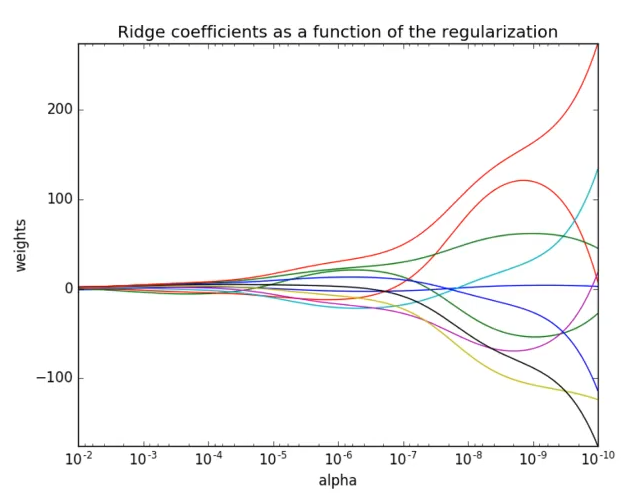
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def mylinear():
"""
線性迴歸預測房價
:return: None
"""
# 1. 獲取資料
lb = load_boston()
# 2. 分割資料集到訓練集和測試集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train, y_test)
# 3. 進行標準化處理(特徵值和目標值都必須標準化處理)
# 例項化兩個標準化API,特徵值和目標值要用各自fit
# 特徵值
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 4. estimator預測
# 4.1 正規方程求解預測結果
lr = LinearRegression()
lr.fit(x_train, y_train)
print(lr.coef_)
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
print('正規方程測試集裡面每個房子的預測價格:', y_lr_predict)
print('正規方程的均方誤差:',mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
# 4.2 梯度下降進行梯度預測
sgd = SGDRegressor()
lr.fit(x_train, y_train)
print(sgd.coef_)
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
print('梯度下降測試集裡面每個房子的預測價格:', y_sgd_predict)
print('梯度下降的均方誤差:', mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
# 4.3 嶺迴歸預測
rd = Ridge(alpha=1.0)
rd.fit(x_train, y_train)
print(rd.coef_)
y_rd_predict = std_y.inverse_transform(rd.predict(x_test))
print('嶺迴歸測試集裡面每個房子的預測價格:', y_rd_predict)
print('嶺迴歸的均方誤差:', mean_squared_error(std_y.inverse_transform(y_test), y_rd_predict))
return None
if __name__ == '__main__':
mylinear()
線性迴歸LinearRegression 與 Ridge對比
嶺迴歸:迴歸得到的迴歸係數更符合實際,更可靠。另外,能讓估計引數的波動範圍變小,變得更穩定。在存在病態資料偏多的研究中有較大的使用價值