
AI Boot Camp 分享之 ML.NET 機器學習指南

今天在中國七城聯動,全球134場的AI BootCamp勝利落幕,廣州由盧建暉老師組織,我參與分享了一個主題《ML.NET 機器學習指南和Azure Kinect .NET SDK概要》,活動雖然只有短短的2天時間的宣傳,報名70人,到場40多人。

下面我和你分享一下我對ML.NET 機器學習的一些內容。
作為一個.NET開發者的你,可能很難立即進入機器學習。主要原因之一就是我們無法啟動Visual Studio 使用我們所精通的.NET技術嘗試這個新事物,這個領域被認為更適合該工作的程式語言,例如Python和R所佔據,這個更準確的來說是機器學習的前期資料分析階段。一年多以前,微軟為我們的.NET技術帶來一個新功能ML.NET, 現在已經是1.4,最新發布的.NET Core 3.1之上七龍珠已經聚齊。

首先我們為什麼我們應該使用ML.NET 技術而不是Python和TensorFlow? 通常來說 除技術棧外,沒有其他特殊原因。如果您將ASP.NET應用程式與機器學習模組一起使用,無疑是將ML.NET整合起來要容易得多。此外,現在您可以將使用TensorFlow構建的模組載入到ML.NET中。不知道各位有沒有思考一下為什麼 Microsoft 現在要在.NET 平臺上引入機器學習以及我們為什麼要關心機器學習。

首先是機器學習這項技術正在跨越鴻溝。事實上這個鴻溝是非常難以跨越的,之所以那麼多的高科技產品只是在小眾範圍內流傳,而並沒有被主流市場接受,原因就是這些公司沒有能夠跨越這個鴻溝。成功跨越鴻溝的典型是小米手機,而被鴻溝擋住的典型當屬錘子手機,大家可以想想這兩家的區別,小米早期定義「為發燒而生」,而錘子手機則是「情懷」,都是針對某個特定群體,但是你看現在小米已經不再說發燒這類的詞了,因為它早已經進入主流市場。
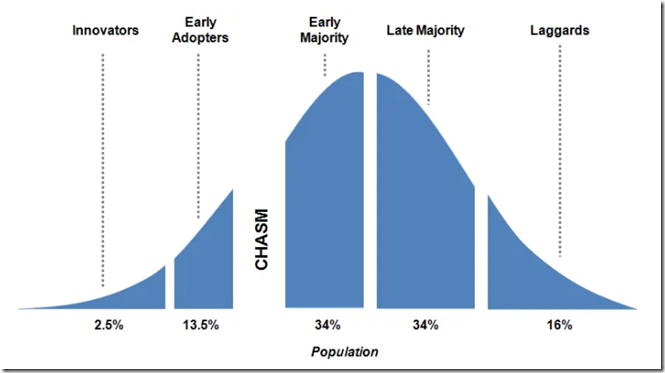
最早的機器學習演算法可以追溯到20世紀初,到今天為止,已經過去了100多年。從1980年機器學習稱為一個獨立的方向開始算起,到現在也已經過去了近40年。在這100多年中,經過一代又一代人的努力,最近這幾年終於跨越了鴻溝。 跨越鴻溝意味著機器學習正在從僅有少數人掌握的時代過渡到民主化、平民化。微軟的CEO 薩提亞·納德拉在他的書《重新整理:重新發現商業與未來》 之中就有提出“民主化”的人工智慧,ML.NET正是要完成這項使命的載體之一。如何實現人工智慧全民化,讓它惠及每個人?如何讓每個人打造自己的人工智慧和AI?在醫療、教育和零售機構當中,如何打造一個相適應的AI是至關重要的。當我們談AI的時候,不能空談任何一個AI公司,而是要“民主化”AI,讓AI真正落地應用到個人。為了達到這樣的一個目的,我們有一系列的解決方案。Azure 雲上在AI領域的GPU和FPGA等等一些基礎架構方面的合作都已準備就緒了,可以提供更多的可能性,確保業務的執行和效率。除此之外,我們的架構提供對TensorFlow的支援,這樣一來我們就有了一個非常開放的環境來支援所有的開發框架。
您應該開始探索這個機器學習領域的另一個原因是,作為一個人類,我們會產生大量資料。單獨地,我們無法處理那麼多的資料,甚至無法處理全部資料。從技術上講,我們面臨著無法從資料中提取資訊的問題。但是,機器學習模型卻可以幫助我們處理海量的資料。
機器學習是電腦科學的一個分支,它使用統計技術使計算機能夠學習如何解決某些問題而無需對其進行顯式程式設計。如上所述,所有重要的機器學習概念都可以追溯到1950年代。但是,主要思想是開發一個數學模型,該模型將能夠做出一些預測。通常會事先對一些資料進行訓練。簡而言之,數學模型使用對舊資料的見解對新資料進行預測。這整個過程稱為預測建模。如果從數學上講,我們正在嘗試近似一個對映函式 – f 從輸入變數 X 到輸出變數 y。 我們正在嘗試使用這種方法解決兩大類問題:迴歸和分類。迴歸問題需要預測數量。這意味著我們的輸出是連續的實值,通常是整數或浮點值。例如,我們要根據過去幾個月的資料預測公司股票的價格。分類問題有點不同。他們正在嘗試將輸入劃分為某些類別。這意味著此任務的輸出是離散的。


ML.NET 是什麼 給我們介紹了 ML.NET在幾乎每種情況下都遵循相同的基本步驟。它結合了資料載入,轉換和模型訓練,使您輕鬆建立機器學習模型。
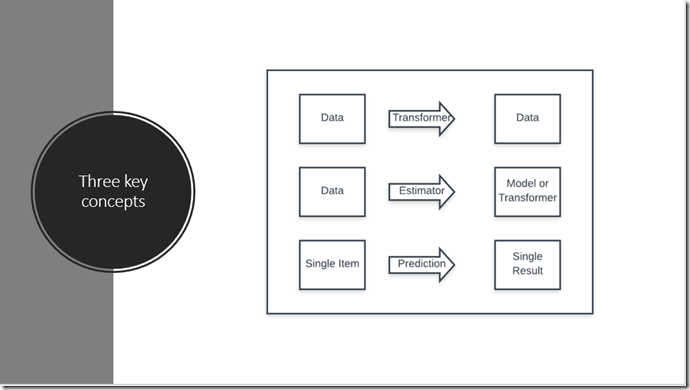
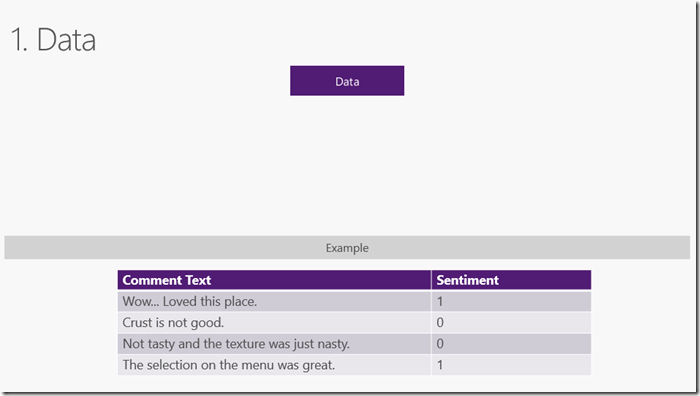
機器學習使用已知資料(例如訓練資料)來找到模式,以便對新的未知資料進行預測。機器學習的輸入稱為 特徵,這是用於進行預測的屬性。機器學習的輸出稱為Label,它是實際的預測。 ML.NET中的資料表示為IDataView,這是一種描述表格資料(例如行和列)的靈活,高效的方法。IDataView物件可以包含數字,文字,布林值,向量等。您可以將資料從檔案或實時流源載入到IDataView。具體參考 從檔案和其他源載入資料
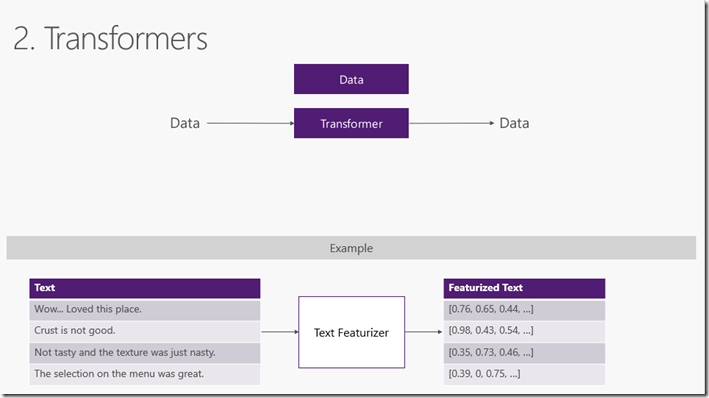
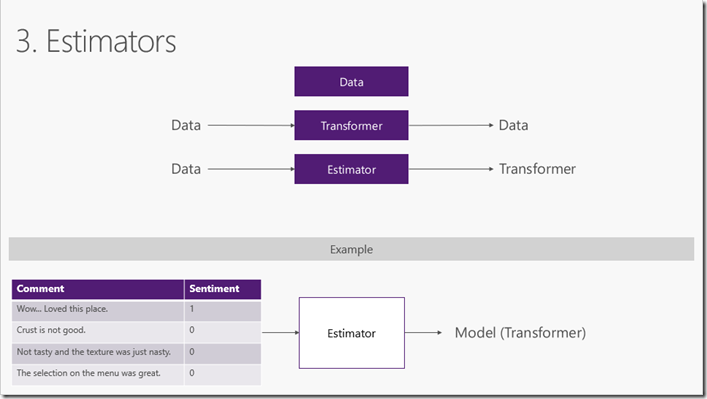
在大多數情況下,您可用的資料不適合直接用於訓練機器學習模型。原始資料需要使用資料轉換進行預處理。Transformers 獲取資料,對其進行一些處理,然後返回經過轉換的新資料。ML.NET內建了一組資料轉換,用於替換缺失值,資料轉換,使文字特徵化等等。參考準備建模的資料
Estimator從資料中學習以建立Transformer 。現在,將輸入要素轉換為輸出預測的模型是Transformer
ML.NET 基礎知識
概述
- 什麼是 ML.NET?
VIDEO
- 機器學習基礎知識
概念
- 機器學習任務和演算法
- 如何選擇演算法
10 分鐘入門
快速入門
- 在 Visual Studio 中設定模型生成器
- ML.NET API 入門
- 在 Mac OS、Windows 或 Linux 上安裝 CLI
教程
- 分析網站評論情緒(模型生成器)
- 預測價格(模型生成器)
- 對衛生違規行為分類(模型生成器和 SQL Server)
- 對支援問題進行分類 (API)
- 使用影象分類 API (API) 分類影象
- 使用模型組合 (API) 分類影象
- 檢測影象中的物件 (API)
- 檢測產品銷售中的異常 (API)
- 預測自行車租賃需求(API 和 SQL Server)
- 生成電影推薦系統 (API)
操作指南
- 從各種源載入資料
- 準備建模的資料
- 訓練和評估模型
- 使用經過訓練的模型進行預測
- 儲存和載入經過訓練的模型
- 重新訓練模型
參考
- ML.NET API 引用
- ML.NET 示例