
HashMap、lru、散列表
HashMap
- HashMap的資料結構:HashMap實際上是一個數組和連結串列(“連結串列雜湊”)的資料結構。底層就是一個數組結構,陣列中的每一項又是一個連結串列。

- hashCode是一個物件的標識,Java中物件的hashCode是一個int型別值。通過hashCode來算出指定陣列的索引可以快速定位到要找的物件在陣列中的位置,之後再遍歷連結串列找到對應值,理想情況下時間複雜度為O(1),並且不同物件可以擁有相同的hashCode(hash碰撞)。發生碰撞後會把相同hashcode的物件放到同一個連結串列裡,但是在陣列大小不變的情況下,存放鍵值對越多,查詢的時間效率也會降低
- 擴容可以解決該問題,而負載因子決定了什麼時候擴容,負載因子是已存鍵值對的數量和總的陣列長度的比值。預設情況下負載因子為0.75,我們可在初始化HashMap的時候自己修改。閥值 = 當前陣列長度✖負載因子
- hashmap中預設負載因子為0.75,長度預設是16,預設情況下第一次擴容判斷閥值是16 ✖ 0.75 = 12;所以第一次存鍵值對的時候,在存到第13個鍵值對時就需要擴容了,變成16X2=32。
put流程
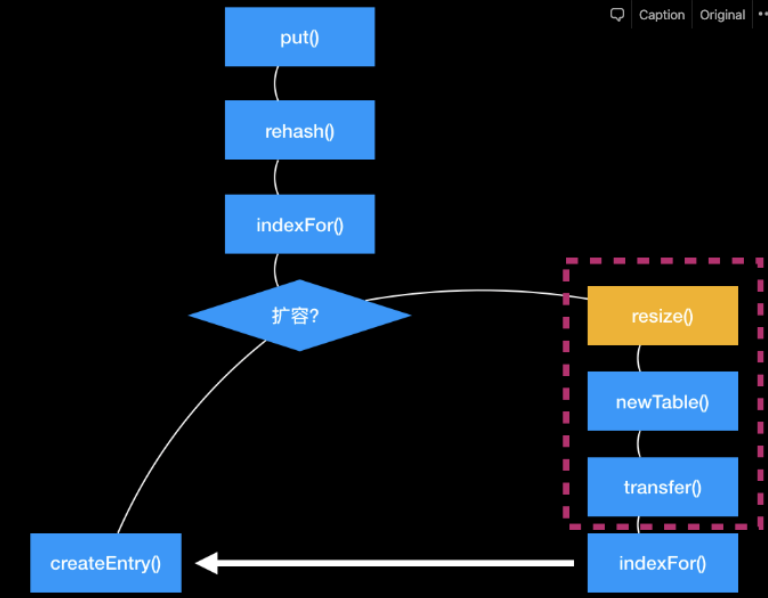
- 對key hash,二次hash,hash擾亂函式,減少hash碰撞
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capitity -1); //capicity表示散列表的大小
}獲取物件的hashcode以後,先進行移位運算,然後再和自己做異或運算,即:hashcode ^ (hashcode >>> 16),這一步甚是巧妙,是將高16位移到低16位,這樣計算出來的整型值將“具有”高位和低位的性質
- 通過hash算出陣列角標(indexfor())
- 新增元素,看是否需要擴容,需要的話變陣列變成原來的2倍,把舊的拷貝到新的陣列上去,然後舊的指標指向新的。
- 如果key相同的覆蓋;沒有的話新增元素
get流程
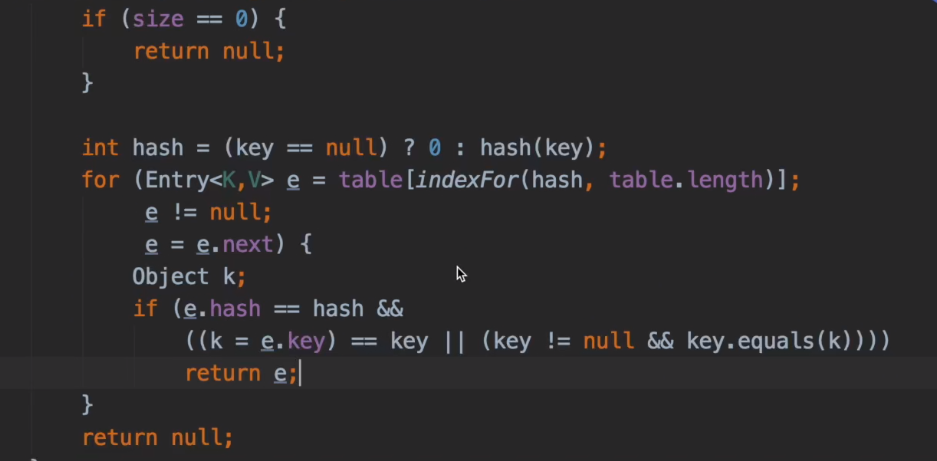
- get對key hash,找到陣列角標(indexfor())
- 如果hash相同key相同就找到了
- 如果hash相同key不相同,找連結串列的下一個(通過值找)
其他問題
- 1.7 和 1.8 資料結構有什麼不同?
1.8 增加了轉換為紅⿊樹 - 插⼊資料的⽅式
1.7 的連結串列從前⾯插⼊,1.8 的連結串列從後⾯插⼊ - HashMap 什麼時候會把連結串列轉化為紅⿊樹?
連結串列⻓度超過 8 ,並且陣列⻓度不⼩於 64在 JDK1.8 版本中,為了對 HashMap 做進一步優化,引入了紅黑樹。而當連結串列長度太長(預設超過 8)時,連結串列就轉換為紅黑樹。可以利用紅黑樹快速增刪改查的特點,提高 HashMap 的效能。當紅黑樹結點個數少於 8 個的時候,又會將紅黑樹轉化為連結串列。因為在資料量較小的情況下,紅黑樹要維護平衡,比起連結串列來,效能上的優勢並不明顯。
優化hashmap
- HashMap 預設的初始大小是 16,當然這個預設值是可以設定的,如果事先知道大概的資料量有多大,可以通過修改預設初始大小,減少動態擴容的次數,這樣會大大提高 HashMap 的效能。
ArrayMap是Android專門針對記憶體優化而設計的,用於取代Java API中的HashMap資料結構。為了更進一步優化key是int型別的Map,Android再次提供效率更高的資料結構SparseArray,可避免自動裝箱過程。對於key為其他型別則可使用ArrayMap。HashMap的查詢和插入時間複雜度為O(1)的代價是犧牲大量的記憶體來實現的,而SparseArray和ArrayMap效能略遜於HashMap,但更節省記憶體。
- SparseBooleanArray: 當map的結構為Map<Integer,Boolean>的時候使用,效率較高。
- SparseLongArray: 當map的結構為Map<Integer,Long>的時候使用,效率較高。
- LongSparseArray: 當map的結構為Map<Long,Value>的時候使用,效率較高。
- ArraySet:和ArrayMap的目的類似,用來提高HashSet的效率。使用方法跟HashSet類似
ArrayMap的key是任意物件,list等等,一般是存一個鍵值,獲取資料簡單
map.keyAt(0)
map.valueAt(0)
- ArrayMap的內部實現是兩個陣列,一個int陣列是儲存物件資料對應下標,一個物件陣列儲存key和value,內部使用二分法對key進行排序,所以在新增、刪除、查詢資料的時候,都會使用二分法查詢,只適合於小資料量操作, 通常情況下要比傳統的HashMap慢,因為查詢是用二分查詢法搜尋,新增和刪除需要對陣列進行新增和刪除。
- 為了提高效能,該容器提供了一個優化:當刪除key鍵時,不是立馬刪除這一項,而是留下需要刪除的選項給一個刪除的標記。該條目可以被重新用於相同的key,或者被單個垃圾收集器逐步刪除完全部的條目後壓縮。
- 為了減少頻繁地建立和回收Map物件,ArrayMap採用了兩個大小為10的快取佇列來分別儲存大小為4和8的Map物件。為了節省記憶體有更加保守的記憶體擴張(擴容的少)以及記憶體收縮策略(gc的頻繁(刪除不用的空間,新的陣列))
- 當mSize大於或等於mHashes陣列長度時則擴容,完成擴容後需要將老的陣列拷貝到新分配的陣列,並釋放老的記憶體。
- 當map個數滿足條件 osize<4時,則擴容後的大小為4;
- 當map個數滿足條件 4<= osize < 8時,則擴容後的大小為8;當map個數滿足條件 osize>=8時,則擴容後的大小為原來的1.5倍;
- 可見ArrayMap大小在不斷增加的過程,size的取值一般情況依次會是4,8,12,18,27,40,60
HashMap存物件
HashMap是基於雜湊表的Map介面的非同步實現。此實現提供所有可選的對映操作,並允許使用null值和null鍵。此類不保證對映的順序,特別是它不保證該順序恆久不變。如果要用物件作為key的話需要重新該物件的equals方法和hashCode方法。
new一個新的物件時,地址變了,不能保證hash值和equals結果還是一樣。所以取不到對應的value。
Map<People,Integer> map = new HashMap<People, Integer>();
map.put(new People("liu",18),5);
People p = new People("liu",18);
System.out.println(map.get(p)); LinkedHashMap
HashMap 底層是通過散列表這種資料結構實現的。而 LinkedHashMap 前面比 HashMap 多了一個“Linked”,這裡的“Linked”是不是說,LinkedHashMap 是一個通過連結串列法解決雜湊衝突的散列表呢?
散列表中資料是經過雜湊函式打亂之後無規律儲存的,LinkedHashMap是如何實現按照資料的插入順序來遍歷列印的呢?
LinkedHashMap 也是通過散列表和連結串列組合在一起實現的。實際上,它不僅支援按照插入順序遍歷資料,還支援按照訪問順序來遍歷資料。你可以看下面這段程式碼:
// 10是初始大小,0.75是裝載因子,true是表示按照訪問時間排序
HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
m.put(3, 26);
m.get(5);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}這段程式碼列印的結果是 1,2,3,5、
每次呼叫 put() 函式,往 LinkedHashMap 中新增資料的時候,都會將資料新增到連結串列的尾部,所以,在前四個操作完成之後,連結串列中的資料是下面這樣:
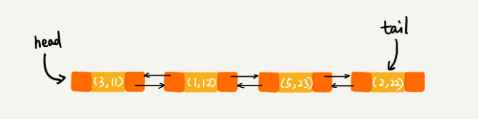
在第 8 行程式碼中,再次將鍵值為 3 的資料放入到 LinkedHashMap 的時候,會先查詢這個鍵值是否已經有了,然後,再將已經存在的 (3,11) 刪除,並且將新的 (3,26) 放到連結串列的尾部。所以,這個時候連結串列中的資料就是下面這樣:

當第 9 行程式碼訪問到 key 為 5 的資料的時候,我們將被訪問到的資料移動到連結串列的尾部。所以,第 9 行程式碼之後,連結串列中的資料是下面這樣:
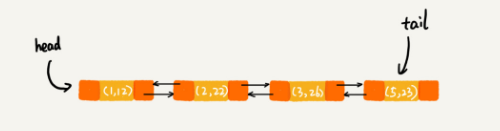
從上面的分析,你有沒有發現,按照訪問時間排序的 LinkedHashMap 本身就是一個支援 LRU 快取淘汰策略的快取系統?實際上,它們兩個的實現原理也是一模一樣的。我也就不再囉嗦了。
LinkedHashMap 是通過雙向連結串列和散列表這兩種資料結構組合實現的。LinkedHashMap 中的“Linked”實際上是指的是雙向連結串列,並非指用連結串列法解決雜湊衝突。
散列表這種資料結構雖然支援非常高效的資料插入、刪除、查詢操作,但是散列表中的資料都是通過雜湊函式打亂之後無規律儲存的。也就說,它無法支援按照某種順序快速地遍歷資料。如果希望按照順序遍歷散列表中的資料,那我們需要將散列表中的資料拷貝到陣列中,然後排序,再遍歷。
因為散列表是動態資料結構,不停地有資料的插入、刪除,所以每當我們希望按順序遍歷散列表中的資料的時候,都需要先排序,那效率勢必會很低。為了解決這個問題,我們將散列表和連結串列(或者跳錶)結合在一起使用。
least recentlly use
最少最近使用演算法,就是使用的LinkedHashMap
- 會將記憶體控制在一定的大小內, 這個最大值可以自己定,超出最大值時會自動回收。他內部是是一個LinkedHashMap儲存外界的快取物件,提供了get,put方法來操作,當快取滿了,lru會移除較早使用的快取物件,把新的新增進來。
- HashMap是無序的,而LinkedHashMap預設實現是按插入順序排序的,怎麼存怎麼取。LinkedHashMap每次呼叫get(也就是從記憶體快取中取圖片),則將該物件移到連結串列的尾端。呼叫put插入新的物件也是儲存在連結串列尾端,這樣當記憶體快取達到設定的最大值時,將連結串列頭部的物件(近期最少用到的)移除。
- 記憶體中使用LRUCache是最合適的。如果用HashMap來實現,不是不可以,但需要注意在合適的時候釋放快取,還得控制快取的大小。
public class BitmapCache implements ImageCache {
private LruCache<String, Bitmap> mCache;
public BitmapCache() {
long maxSize = Runtime.getRuntime().maxMemory() / 8;
// int maxSize = 10 * 1024 * 1024;
mCache = new LruCache<String, Bitmap>(maxSize) {
@Override
protected int sizeOf(String key, Bitmap bitmap) {
//獲取圖片佔用記憶體大小
return bitmap.getRowBytes() * bitmap.getHeight();
}
};
}
@Override
public Bitmap getBitmap(String url) {
return mCache.get(url);
}
@Override
public void putBitmap(String url, Bitmap bitmap) {
mCache.put(url, bitmap);
}
} 散列表
散列表的英文叫“Hash Table”,我們平時也叫它“雜湊表”或者“Hash 表"
散列表用的是陣列支援按照下標隨機訪問資料的特性,所以散列表其實就是陣列的一種擴充套件,由陣列演化而來。可以說,如果沒有陣列,就沒有散列表。
其中,參賽選手的編號我們叫作鍵(key)或者關鍵字。我們用它來標識一個選手。我們把參賽編號轉化為陣列下標的對映方法就叫作雜湊函式(或“Hash 函式”“雜湊函式”),而雜湊函式計算得到的值就叫作雜湊值(或“Hash 值”“雜湊值”)
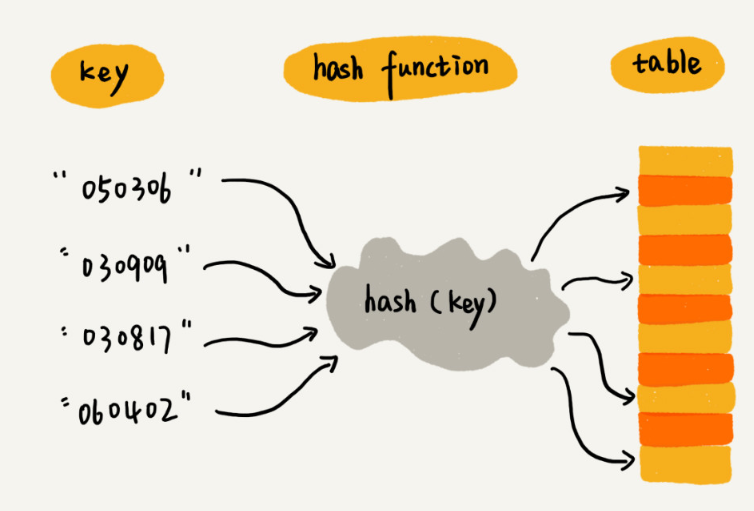
散列表用的就是陣列支援按照下標隨機訪問的時候,時間複雜度是 O(1) 的特性。我們通過雜湊函式把元素的鍵值對映為下標,然後將資料儲存在陣列中對應下標的位置。當我們按照鍵值查詢元素時,我們用同樣的雜湊函式,將鍵值轉化陣列下標,從對應的陣列下標的位置取資料。
時間複雜度
插入一個數據,最好情況下,不需要擴容,最好時間複雜度是 O(1)。最壞情況下,散列表裝載因子過高,啟動擴容,我們需要重新申請記憶體空間,重新計算雜湊位置,並且搬移資料,所以時間複雜度是 O(n)。用攤還分析法,均攤情況下,時間複雜度接近最好情況,就是 O(1)
然後遍歷連結串列查詢或者刪除。那查詢或刪除操作的時間複雜度是多少呢?實際上,這兩個操作的時間複雜度跟連結串列的長度 k 成正比,也就是 O(k)。對於雜湊比較均勻的雜湊函式來說,理論上講,k=n/m,其中 n 表示雜湊中資料的個數,m 表示散列表中“槽”的個數。
雜湊函式
雜湊函式,顧名思義,它是一個函式。我們可以把它定義成 hash(key),其中 key 表示元素的鍵值,hash(key) 的值表示經過雜湊函式計算得到的雜湊值。
該如何構造雜湊函式呢?我總結了三點雜湊函式設計的基本要求:
- 雜湊函式計算得到的雜湊值是一個非負整數;
- 如果 key1 = key2,那 hash(key1) == hash(key2);
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)
我來解釋一下這三點。其中,第一點理解起來應該沒有任何問題。因為陣列下標是從 0 開始的,所以雜湊函式生成的雜湊值也要是非負整數。第二點也很好理解。相同的 key,經過雜湊函式得到的雜湊值也應該是相同的。
第三點理解起來可能會有問題,我著重說一下。這個要求看起來合情合理,但是在真實的情況下,要想找到一個不同的 key 對應的雜湊值都不一樣的雜湊函式,幾乎是不可能的。即便像業界著名的MD5、SHA、CRC等雜湊演算法,也無法完全避免這種雜湊衝突。而且,因為陣列的儲存空間有限,也會加大雜湊衝突的概率。
雜湊衝突
- 開放定址法
線性探測
我們往散列表中插入資料時,如果某個資料經過雜湊函式雜湊之後,儲存位置已經被佔用了,我們就從當前位置開始,依次往後查詢,看是否有空閒位置,直到找到為止。
當資料量比較小、裝載因子小的時候,適合採用開放定址法。這也是 Java 中的ThreadLocalMap使用開放定址法解決雜湊衝突的原因。
ThreadLocalMap 是通過線性探測的開放定址法來解決衝突
散列表的裝載因子=填入表中的元素個數/散列表的長度裝載因子越大,說明空閒位置越少,衝突越多,散列表的效能會下降。
- 連結串列法
Java 中 LinkedHashMap 就採用了連結串列法解決衝突
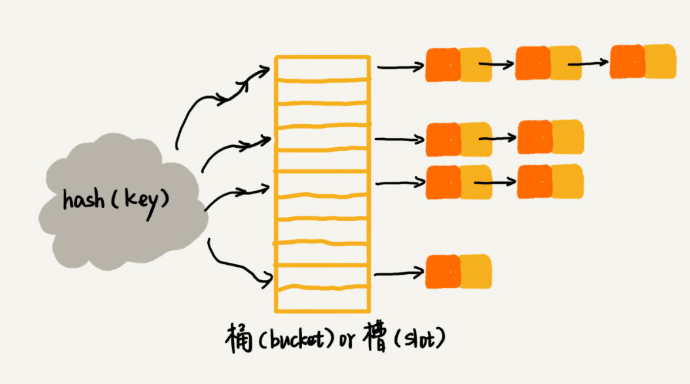
如何設計雜湊函式?
如何設計一個可以應對各種異常情況的工業級散列表,來避免在雜湊衝突的情況下,散列表效能的急劇下降,並且能抵抗雜湊碰撞攻擊?
首先,雜湊函式的設計不能太複雜。過於複雜的雜湊函式,勢必會消耗很多計算時間,也就間接的影響到散列表的效能。其次,雜湊函式生成的值要儘可能隨機並且均勻分佈,這樣才能避免或者最小化雜湊衝突,而且即便出現衝突,雜湊到每個槽(連結串列)裡的資料也會比較平均,不會出現某個槽內資料特別多的情況。
裝載因子過大了怎麼辦?
裝載因子越大,說明散列表中的元素越多,空閒位置越少,雜湊衝突的概率就越大。不僅插入資料的過程要多次定址或者拉很長的鏈,查詢的過程也會因此變得很慢。
擴容解決
實際上,對於動態散列表,隨著資料的刪除,散列表中的資料會越來越少,空閒空間會越來越多。
避免低效地擴容
我舉一個極端的例子,如果散列表當前大小為 1GB,要想擴容為原來的兩倍大小,那就需要對 1GB 的資料重新計算雜湊值,並且從原來的散列表搬移到新的散列表,聽起來就很耗時,是不是?
為了解決一次性擴容耗時過多的情況,我們可以將擴容操作穿插在插入操作的過程中,分批完成。當裝載因子觸達閾值之後,我們只申請新空間,但並不將老的資料搬移到新散列表中。
當有新資料要插入時,我們將新資料插入新散列表中,並且從老的散列表中拿出一個數據放入到新散列表。每次插入一個數據到散列表,我們都重複上面的過程。經過多次插入操作之後,老的散列表中的資料就一點一點全部搬移到新散列表中了。這樣沒有了集中的一次性資料搬移,插入操作就都變得很快了。
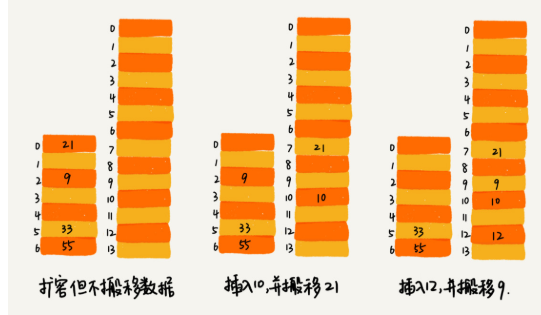
這期間的查詢操作怎麼來做呢?對於查詢操作,為了相容了新、老散列表中的資料,我們先從新散列表中查詢,如果沒有找到,再去老的散列表中查詢。
部分內容摘抄至極客時間《資料結構與演算法之美》,更多精彩內容,歡迎訂閱老師課程