
圖解kubernetes排程器SchedulerCache核心原始碼實現
SchedulerCache是kubernetes scheduler中負責本地資料快取的核心資料結構, 其實現了Cache介面,負責儲存從apiserver獲取的資料,提供給Scheduler排程器獲取Node的資訊,然後由排程演算法的決策pod的最終node節點,其中Snapshot和節點打散演算法非常值得借鑑
設計目標
資料感知
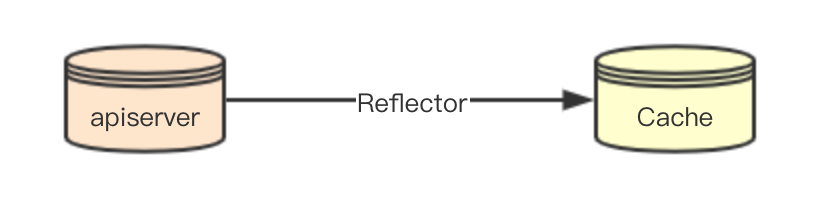
SchedulerCache的資料從apiserver通過網路感知,其資料的同步一致性主要是通過kubernetes中的Reflector元件來負責保證,SchedulerCache本身就是一個單純資料的儲存
Snapshot機制
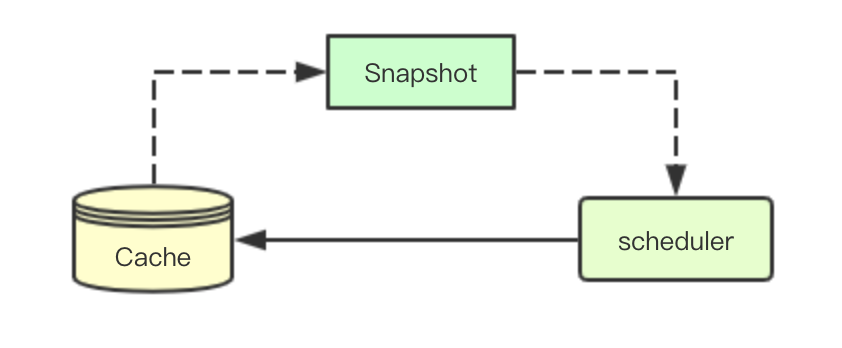
當scheduler獲取一個待排程的pod,則需要從Cache中獲取當前叢集中的快照資料(當前此時叢集中node的統計資訊), 用於後續排程流程中使用
節點打散

節點打散主要是指的排程器排程的時候,在滿足排程需求的情況下,為了保證pod均勻分配到所有的node節點上,通常會按照逐個zone逐個node節點進行分配,從而讓pod節點打散在整個叢集中
過期刪除
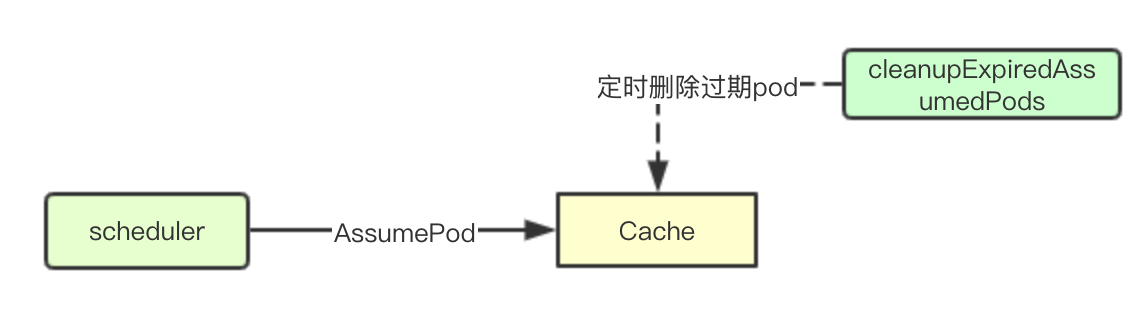
Scheduler進行完成排程流程的決策之後,為pod選擇了一個node節點,此時還未進行後續的Bind操作,但實際上資源已經分配給該pod, 此時會先更新到本地快取(),然後再等待apiserver進行資料的廣播並且最終被kubelet來進行實際的排程
但如果因為某些原因導致pod後續的事件都沒有被監聽到,則需要將對應的pod資源進行刪除,並刪除對node資源的佔用
cache內部pod狀態機
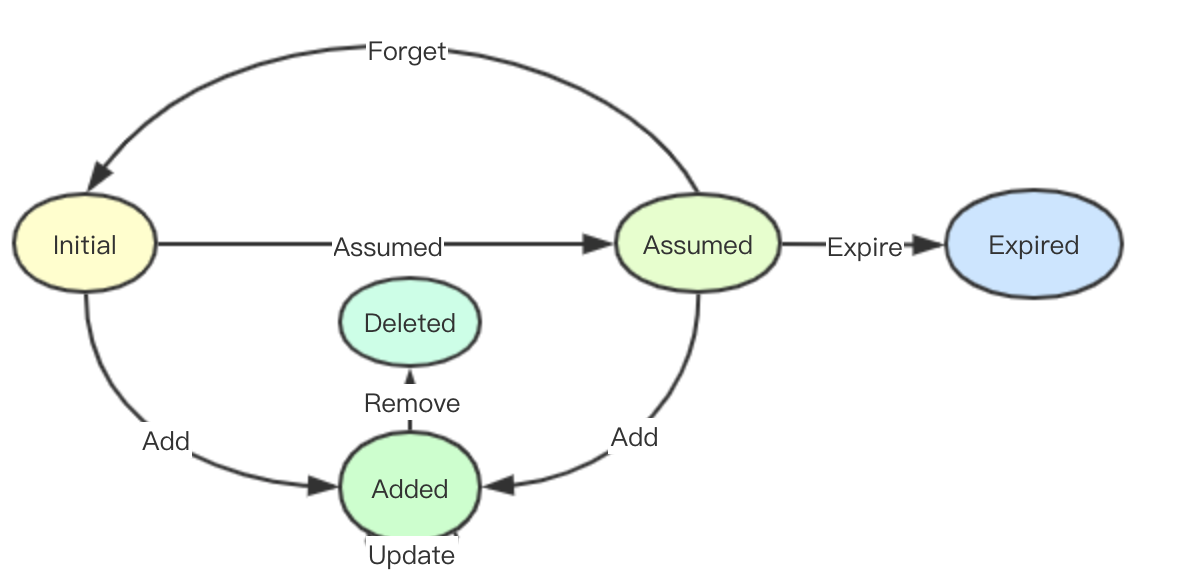
在scheduler cache中pod會一個內部的狀態機:initial、Assumed、Expired、Added、Delete,實際上所有的操作都是圍繞著該狀態機在進行,狀態如下:
Initial: 初始化完成從apiserver監聽到(也可能是監聽到一個已經完成分配的pod)
Assumed: 在scheduler中完成分配最終完成bind操作的pod(未實際分配)
Added: 首先監聽到事件可能是一個已經完成實際排程的pod(即從initial到Added),其次可能是經過排程決策後,被實際排程(從Assumed到Added),最後則是後續pod的更新(Update), Added語義上其實就是往Cache中新增一個Pod狀態
Deleted: 某個pod被監聽到刪除事件,只有被Added過的資料才可以被Deleted
Expired: Assumed pod經過一段時間後沒有感知到真正的分配事件被刪除
原始碼實現
資料結構
type schedulerCache struct {
stop <-chan struct{}
ttl time.Duration
period time.Duration
// 保證資料的安全
mu sync.RWMutex
// 儲存假定pod的資訊集合,經過scheduler排程後假定pod被排程到某些節點,進行本地臨時儲存
// 主要是為了進行node資源的佔用,可以通過key在podStats查詢到假定的pod資訊
assumedPods map[string]bool
// pod的狀態
podStates map[string]*podState
// 儲存node的對映
nodes map[string]*nodeInfoListItem
csiNodes map[string]*storagev1beta1.CSINode
// node資訊的連結串列,按照最近更新時間來進行連線
headNode *nodeInfoListItem
// 儲存node、zone的對映資訊
nodeTree *NodeTree
// 映象資訊
imageStates map[string]*imageState
}Snapshot機制
資料結構
Snapshot資料結構主要負責儲存當前叢集中的node資訊,並且通過Generation記錄當前更新的最後一個週期
type Snapshot struct {
NodeInfoMap map[string]*NodeInfo
Generation int64
}Snapshot的建立與更新
建立主要位於kubernetes/pkg/scheduler/core/generic_scheduler.go,實際上就是建立一個空的snapshot物件
nodeInfoSnapshot: framework.NodeInfoSnapshot(),資料的更新則是通過snapshot方法來呼叫Cache的更新介面來進行更新
func (g *genericScheduler) snapshot() error {
// Used for all fit and priority funcs.
return g.cache.UpdateNodeInfoSnapshot(g.nodeInfoSnapshot)
}藉助headNode實現增量標記
隨著叢集中node和pod的數量的增加,如果每次都全量獲取snapshot則會嚴重影響排程器的排程效率,在Cache中通過一個雙向連結串列和node的遞增計數(etcd實現)來實現增量更新
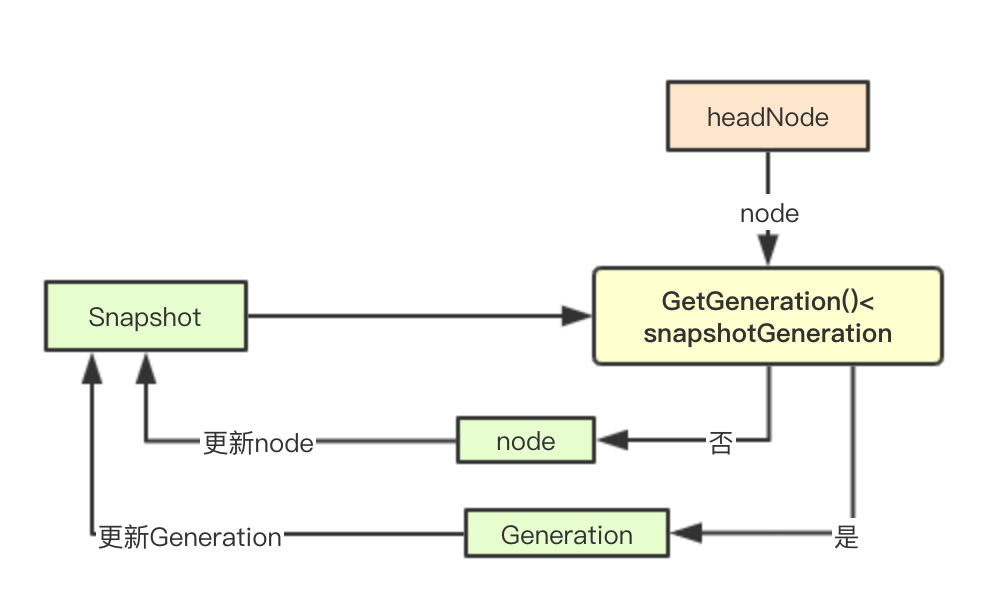
func (cache *schedulerCache) UpdateNodeInfoSnapshot(nodeSnapshot *schedulernodeinfo.Snapshot) error {
cache.mu.Lock()
defer cache.mu.Unlock()
balancedVolumesEnabled := utilfeature.DefaultFeatureGate.Enabled(features.BalanceAttachedNodeVolumes)
// 獲取當前snapshot的Genration
snapshotGeneration := nodeSnapshot.Generation
// 遍歷雙向連結串列,更新snapshot資訊
for node := cache.headNode; node != nil; node = node.next {
if node.info.GetGeneration() <= snapshotGeneration {
//所有node資訊都更新完畢
break
}
if balancedVolumesEnabled && node.info.TransientInfo != nil {
// Transient scheduler info is reset here.
node.info.TransientInfo.ResetTransientSchedulerInfo()
}
if np := node.info.Node(); np != nil {
nodeSnapshot.NodeInfoMap[np.Name] = node.info.Clone()
}
}
// 更新snapshot的genration
if cache.headNode != nil {
nodeSnapshot.Generation = cache.headNode.info.GetGeneration()
}
// 如果snapshot裡面包含過期的pod資訊則進行清理工作
if len(nodeSnapshot.NodeInfoMap) > len(cache.nodes) {
for name := range nodeSnapshot.NodeInfoMap {
if _, ok := cache.nodes[name]; !ok {
delete(nodeSnapshot.NodeInfoMap, name)
}
}
}
return nil
}
nodeTree
nodeTree主要負責節點的打散,用於讓pod均勻分配在多個zone中的node節點上
2.3.1 資料結構
type NodeTree struct {
tree map[string]*nodeArray // 儲存zone和zone下面的node資訊
zones []string // 儲存zones
zoneIndex int
numNodes int
mu sync.RWMutex
}其中zones和zoneIndex主要用於後面的節點打散演算法使用,實現按zone逐個分配
nodeArray
nodeArray負責儲存一個zone下面的所有node節點,並且通過lastIndex記錄當前zone分配的節點索引
type nodeArray struct {
nodes []string
lastIndex int
}新增node
新增node其實很簡單,只需要獲取對應node的zone資訊,然後加入對應zone的nodeArray中
func (nt *NodeTree) addNode(n *v1.Node) {
// 獲取zone
zone := utilnode.GetZoneKey(n)
if na, ok := nt.tree[zone]; ok {
for _, nodeName := range na.nodes {
if nodeName == n.Name {
klog.Warningf("node %q already exist in the NodeTree", n.Name)
return
}
}
// 吧節點加入到zone中
na.nodes = append(na.nodes, n.Name)
} else {
// 新加入zone
nt.zones = append(nt.zones, zone)
nt.tree[zone] = &nodeArray{nodes: []string{n.Name}, lastIndex: 0}
}
klog.V(2).Infof("Added node %q in group %q to NodeTree", n.Name, zone)
nt.numNodes++
}資料打散演算法
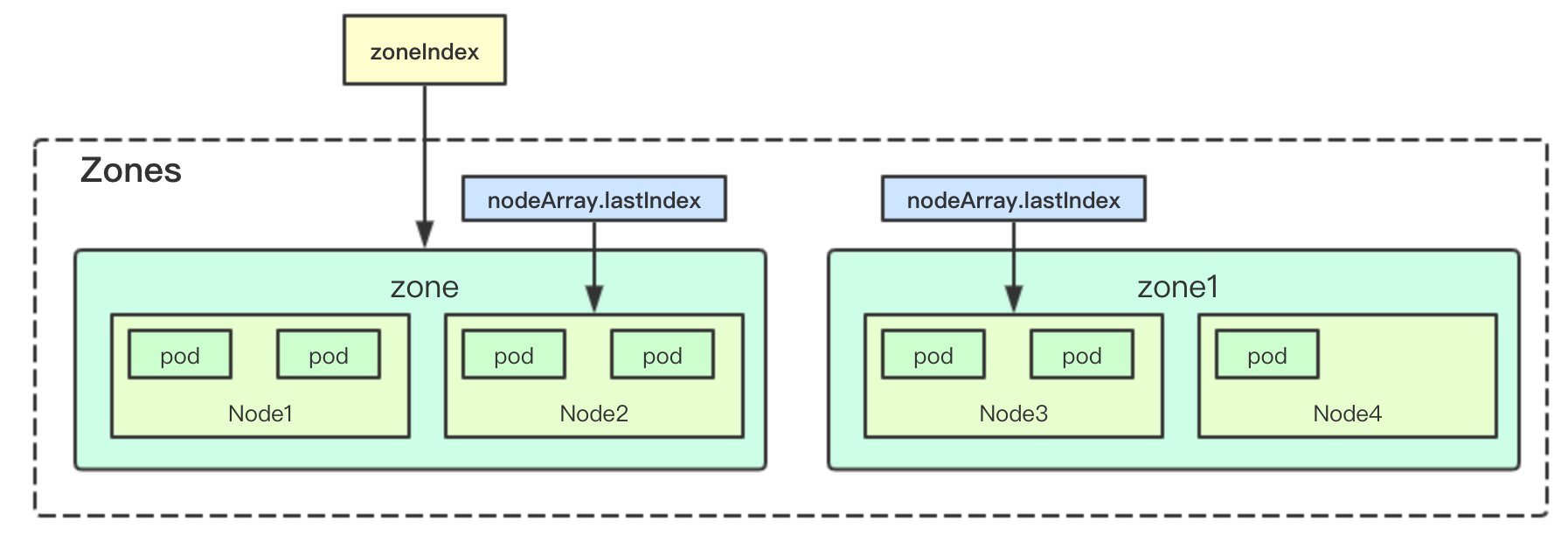
資料打散演算法很簡單,首先我們儲存了zone和nodeArray的資訊,然後我們只需要通過兩個索引zoneIndex和nodeIndex就可以實現節點的打散操作, 只有噹噹前叢集中所有zone裡面的所有節點都進行一輪分配後,然後重建分配索引
func (nt *NodeTree) Next() string {
nt.mu.Lock()
defer nt.mu.Unlock()
if len(nt.zones) == 0 {
return ""
}
// 記錄分配完所有node的zone的計數,用於進行狀態重置
// 比如有3個zone: 則當numExhaustedZones=3的時候,就會重新從頭開始進行分配
numExhaustedZones := 0
for {
if nt.zoneIndex >= len(nt.zones) {
nt.zoneIndex = 0
}
// 按照zone索引來進行逐個zone分配
zone := nt.zones[nt.zoneIndex]
nt.zoneIndex++
// 返回當前zone下面的next節點,如果exhausted為True則表明當前zone所有的節點,在這一輪排程中都已經分配了一次
// 就需要從下個zone繼續獲取節點
nodeName, exhausted := nt.tree[zone].next()
if exhausted {
numExhaustedZones++
// 所有的zone下面的node都被分配了一次,這裡進行重置,從頭開始繼續分配
if numExhaustedZones >= len(nt.zones) { // all zones are exhausted. we should reset.
nt.resetExhausted()
}
} else {
return nodeName
}
}
}重建索引
重建索引則是將所有nodeArray的索引和當前zoneIndex進行歸零
func (nt *NodeTree) resetExhausted() {// 重置索引
for _, na := range nt.tree {
na.lastIndex = 0
}
nt.zoneIndex = 0
}
資料過期清理
資料儲存
Cache要定時將之前在經過本地scheduler分配完成後的假設的pod的資訊進行清理,如果這些pod在給定時間內仍然沒有感知到對應的pod真正的新增事件則就這些pod刪除
assumedPods map[string]bool後臺定時任務
預設每30s進行清理一次
func (cache *schedulerCache) run() {
go wait.Until(cache.cleanupExpiredAssumedPods, cache.period, cache.stop)
}清理邏輯
清理邏輯主要是針對那些已經完成繫結的pod來進行,如果一個pod完成了在scheduler裡面的所有操作後,會有一個過期時間,當前是30s,如果超過該時間即deadline小於當前的時間就刪除該pod
// cleanupAssumedPods exists for making test deterministic by taking time as input argument.
func (cache *schedulerCache) cleanupAssumedPods(now time.Time) {
cache.mu.Lock()
defer cache.mu.Unlock()
// The size of assumedPods should be small
for key := range cache.assumedPods {
ps, ok := cache.podStates[key]
if !ok {
panic("Key found in assumed set but not in podStates. Potentially a logical error.")
}
// 未完成繫結的pod不會被進行清理
if !ps.bindingFinished {
klog.V(3).Infof("Couldn't expire cache for pod %v/%v. Binding is still in progress.",
ps.pod.Namespace, ps.pod.Name)
continue
}
// 在完成bind之後會設定一個過期時間,目前是30s,如果deadline即bind時間+30s小於當前時間就過期刪除
if now.After(*ps.deadline) {
klog.Warningf("Pod %s/%s expired", ps.pod.Namespace, ps.pod.Name)
if err := cache.expirePod(key, ps); err != nil {
klog.Errorf("ExpirePod failed for %s: %v", key, err)
}
}
}
}清理pod
清理pod主要分為如下幾個部分:
1.對應pod假定分配node的資訊
2.清理對映的podState資訊
func (cache *schedulerCache) expirePod(key string, ps *podState) error {
if err := cache.removePod(ps.pod); err != nil {
return err
}
delete(cache.assumedPods, key)
delete(cache.podStates, key)
return nil
}
設計總結
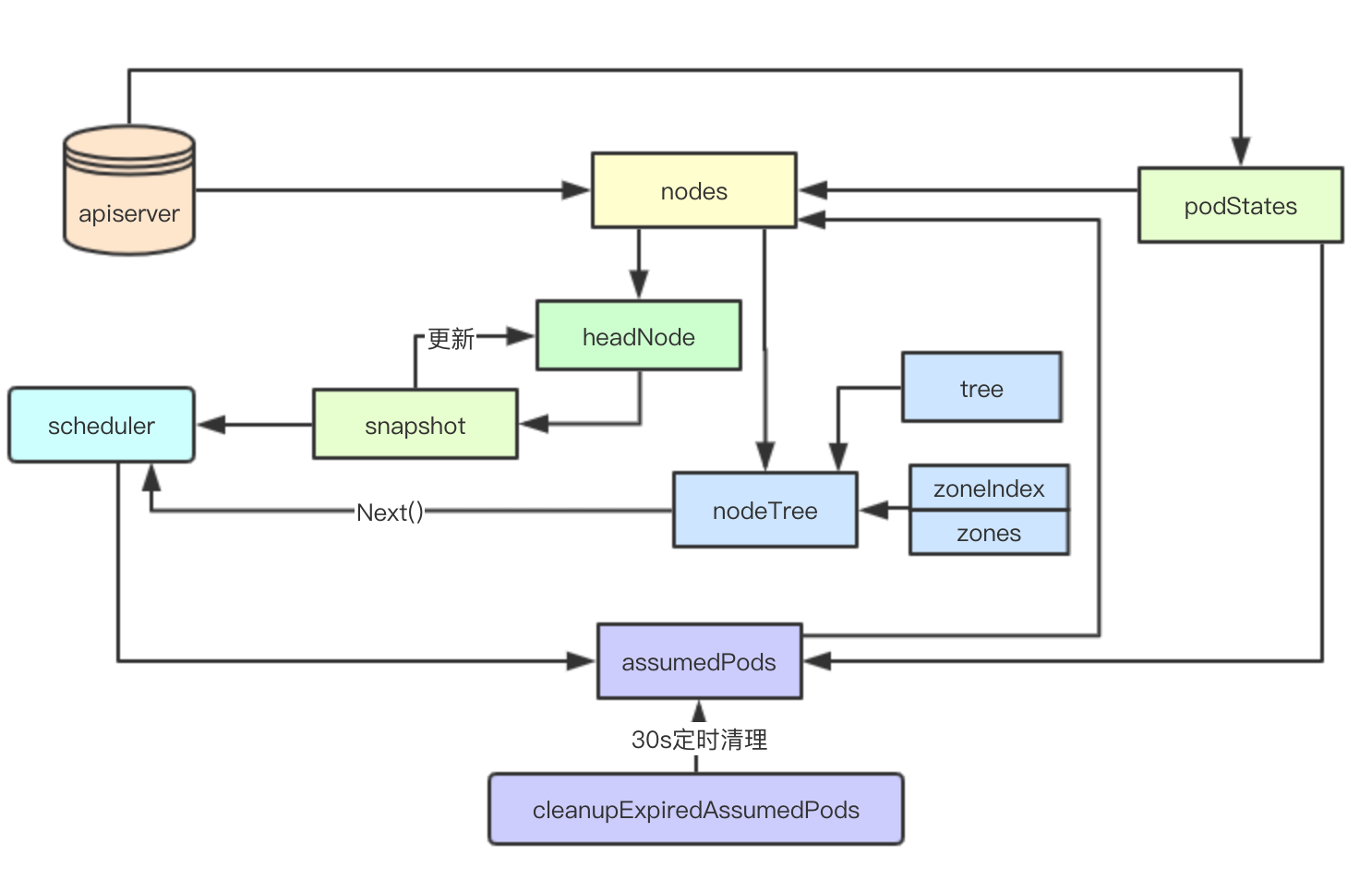
核心資料結構資料流如上所示,其核心是通過nodes、headNode實現一個Snapshot為排程器提供當前系統資源的快照,並通過nodeTree進行node節點的打散,最後內部通過一個pod的狀態機來進行系統內部的pod資源狀態的轉換,並通過後臺的定時任務來保證經過經過Reflector獲取的資料的最終一致性(刪除那些經過bind的但是卻沒被實際排程或者事件丟失的pod), 藉助這些其實一個最基礎的工業級排程器的本地cache功能就實現了
微訊號:baxiaoshi2020

關注公告號閱讀更多原始碼分析文章
更多文章關注 www.sreguide.com
本文由部落格一文多發平臺 OpenWrite 釋出