
圖解kubernetes服務打散演算法的實現原始碼
在分散式排程中為了保證服務的高可用和容災需求,通常都會講服務在多個區域、機架、節點上平均分佈,從而避免單點故障引起的服務不可用,在k8s中自然也實現了該演算法即SelectorSpread, 本文就來學習下這個演算法的底層實現細節
1. 設計要點
1.1 zone與node
zone即代表一個區域,node則是一個具體的節點,而該打散演算法的目標就是將pod在zone和node之間進行打散操作
1.2 namespace
namespace是k8s中進行資源隔離的實現,同樣的篩選也是如此,在篩選的過程中,不同namespace下面的pod並不會相互影響
1.3 計數與聚合
SelectorSpread演算法是scheduler中優先順序演算法的一種,其實現了優先順序演算法的map/reduce方法,其中map階段需要完成對各個節點親和性的統計, 也就是統計該節點上的匹配的pod的數量,而reduce階段則是聚合所有匹配的數量,進行統計打分
1.4 參考物件
在k8s中有很多上層物件諸如service、replicaSet、statefulset等,而演算法打散的物件也是依據這些上層物件,讓單個service的多個pod進行平均分佈
1.5 選擇器
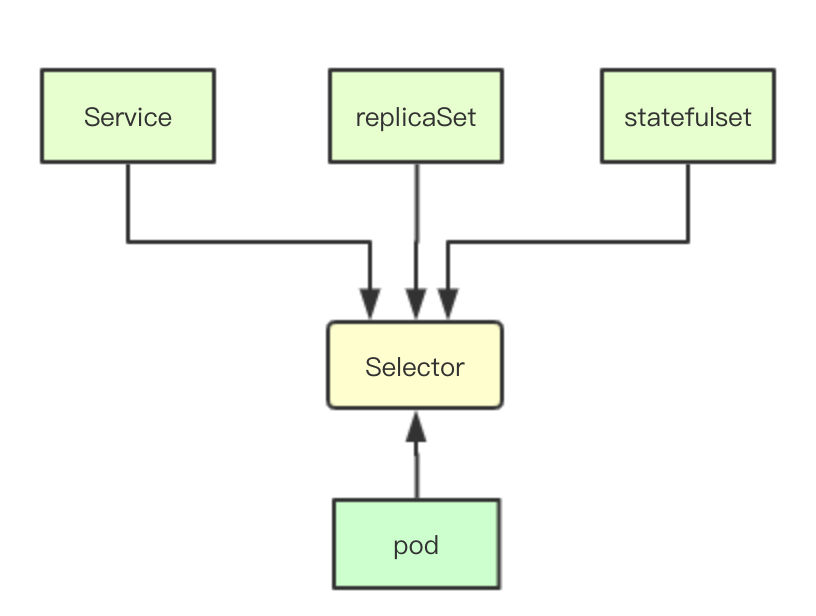
在傳統的基於資料庫的設計中,資料之間的關聯關係通常是基於外來鍵或者物件id來實現模型之間的關聯,而在kubernetes中則是通過selector來進行這種關係的對映,通過給物件定義不同的label然後在label上構造選擇器,從而實現各種資源之間的相互關聯
2. 實現原理
2.1 選擇器
2.1.1 選擇器介面
選擇器介面其關鍵方法主要是通過Matches來進行一組標籤的匹配,先關注這些就可以了,後續需要再去關注其核心實現
type Selector interface { // Matches returns true if this selector matches the given set of labels. Matches(Labels) bool // String returns a human readable string that represents this selector. String() string // Add adds requirements to the Selector Add(r ...Requirement) Selector }
2.1.2 資源篩選
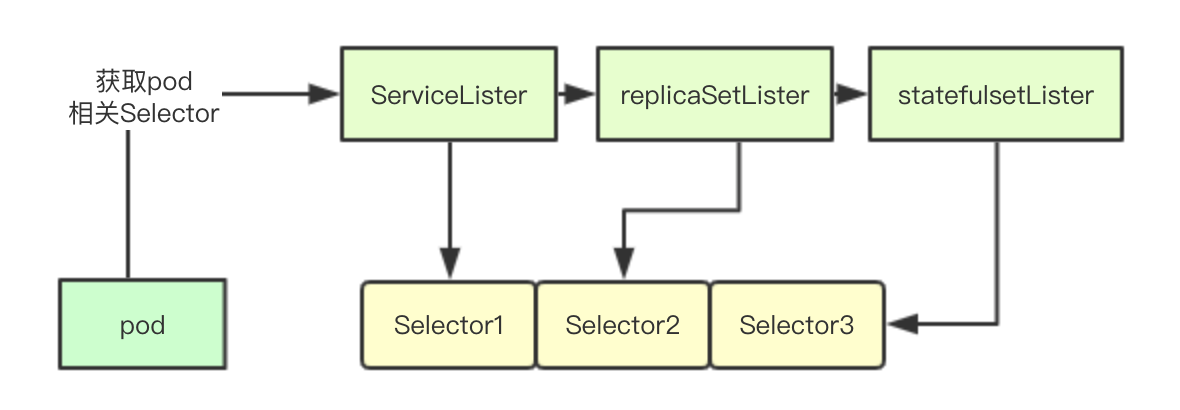
Selector陣列的實現其實也很簡單,就是遍歷所有相關聯的資源,然後用當前的pod上的Label標籤去搜索,如果發現有資源包含當前pod的標籤,就把對應資源的所有Selector都獲取出來,加入到selectors陣列中
func getSelectors(pod *v1.Pod, sl algorithm.ServiceLister, cl algorithm.ControllerLister, rsl algorithm.ReplicaSetLister, ssl algorithm.StatefulSetLister) []labels.Selector {
var selectors []labels.Selector
if services, err := sl.GetPodServices(pod); err == nil {
for _, service := range services {
selectors = append(selectors, labels.SelectorFromSet(service.Spec.Selector))
}
}
if rcs, err := cl.GetPodControllers(pod); err == nil {
for _, rc := range rcs {
selectors = append(selectors, labels.SelectorFromSet(rc.Spec.Selector))
}
}
if rss, err := rsl.GetPodReplicaSets(pod); err == nil {
for _, rs := range rss {
if selector, err := metav1.LabelSelectorAsSelector(rs.Spec.Selector); err == nil {
selectors = append(selectors, selector)
}
}
}
if sss, err := ssl.GetPodStatefulSets(pod); err == nil {
for _, ss := range sss {
if selector, err := metav1.LabelSelectorAsSelector(ss.Spec.Selector); err == nil {
selectors = append(selectors, selector)
}
}
}
return selectors
}2.1 演算法註冊與初始化
2.1.1 演算法註冊
在構建演算法的時候,首先會從引數中獲取各種資源的Lister, 其實就是篩選物件的一個介面,可以從該介面中獲取叢集中對應型別的所有資源
factory.RegisterPriorityConfigFactory(
priorities.SelectorSpreadPriority,
factory.PriorityConfigFactory{
MapReduceFunction: func(args factory.PluginFactoryArgs) (priorities.PriorityMapFunction, priorities.PriorityReduceFunction) {
return priorities.NewSelectorSpreadPriority(args.ServiceLister, args.ControllerLister, args.ReplicaSetLister, args.StatefulSetLister)
},
Weight: 1,
},
)2.1.2 演算法初始化
演算法初始化則是構建一個SelectorSpread物件,我們可以看到其map和reduce的關鍵實現分別對應內部的兩個方法
func NewSelectorSpreadPriority(
serviceLister algorithm.ServiceLister,
controllerLister algorithm.ControllerLister,
replicaSetLister algorithm.ReplicaSetLister,
statefulSetLister algorithm.StatefulSetLister) (PriorityMapFunction, PriorityReduceFunction) {
selectorSpread := &SelectorSpread{
serviceLister: serviceLister,
controllerLister: controllerLister,
replicaSetLister: replicaSetLister,
statefulSetLister: statefulSetLister,
}
return selectorSpread.CalculateSpreadPriorityMap, selectorSpread.CalculateSpreadPriorityReduce
}2.2 CalculateSpreadPriorityMap
2.2.1 構建選擇器
在進行Map核心統計階段之前會先根據當前的pod獲取其上的選擇器Selector陣列,即當前pod有那些選擇器相關聯,這個是在建立meta的時候完成
var selectors []labels.Selector
node := nodeInfo.Node()
if node == nil {
return schedulerapi.HostPriority{}, fmt.Errorf("node not found")
}
priorityMeta, ok := meta.(*priorityMetadata)
if ok {
// 在priorityMeta構建的時候已經完成
selectors = priorityMeta.podSelectors
} else {
// 獲取當前pod的所有的selector 包括service rs rc
selectors = getSelectors(pod, s.serviceLister, s.controllerLister, s.replicaSetLister, s.statefulSetLister)
}
if len(selectors) == 0 {
return schedulerapi.HostPriority{
Host: node.Name,
Score: int(0),
}, nil
}2.2.2 統計匹配計數
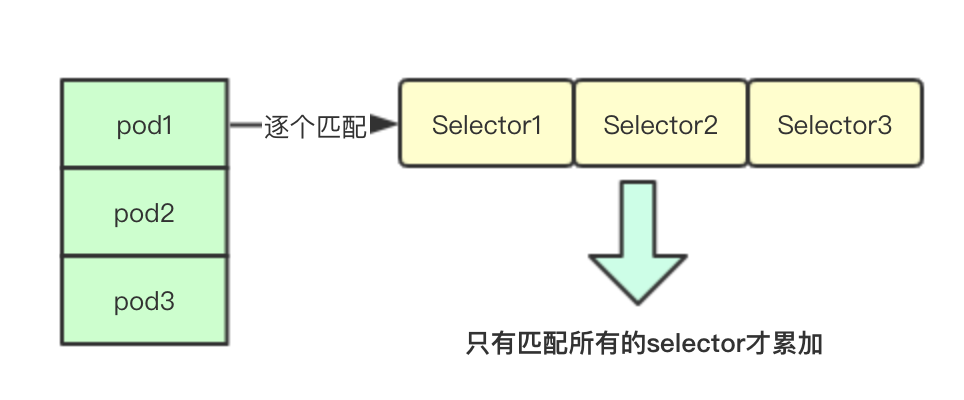
統計計數其實就是根據上面的selector陣列逐個遍歷當前node上面的所有pod如果發現全都匹配則計數一次,最後返回當前節點上匹配的pod的數量(這裡的匹配是指的所有都匹配即跟當前的pod的所有label匹配都一樣)
func countMatchingPods(namespace string, selectors []labels.Selector, nodeInfo *schedulernodeinfo.NodeInfo) int {
// 計算當前node上面匹配的node的數量
if nodeInfo.Pods() == nil || len(nodeInfo.Pods()) == 0 || len(selectors) == 0 {
return 0
}
count := 0
for _, pod := range nodeInfo.Pods() {
// 這裡會跳過不同namespace和被刪除的pod
if namespace == pod.Namespace && pod.DeletionTimestamp == nil {
matches := true
// 遍歷所有的選擇器,如果不匹配,則會立馬跳出
for _, selector := range selectors {
if !selector.Matches(labels.Set(pod.Labels)) {
matches = false
break
}
}
if matches {
count++ // 記錄當前節點上匹配的pod的數量
}
}
}
return count
}2.2.3 返回統計結果
最後返回對應node的名字和node上的匹配的pod的數量
count := countMatchingPods(pod.Namespace, selectors, nodeInfo)
return schedulerapi.HostPriority{
Host: node.Name,
Score: count,
}, nil2.4 CalculateAntiAffinityPriorityReduce
2.4.1 計數器
計數器主要包含三個:單個node上最大的pod數量、單個zone裡面最大pod的數量、每個zone中pod的數量
countsByZone := make(map[string]int, 10)
maxCountByZone := int(0)
maxCountByNodeName := int(0)2.4.2 單節點最大統計與zone區域聚合
for i := range result {
if result[i].Score > maxCountByNodeName {
maxCountByNodeName = result[i].Score // 尋找單節點上的最大pod數量
}
zoneID := utilnode.GetZoneKey(nodeNameToInfo[result[i].Host].Node())
if zoneID == "" {
continue
}
// 進行zone所有node匹配pod的聚合
countsByZone[zoneID] += result[i].Score
}2.4.3 zone最大值統計
for zoneID := range countsByZone {
if countsByZone[zoneID] > maxCountByZone {
maxCountByZone = countsByZone[zoneID]
}
}2.4.4 核心計算打分演算法
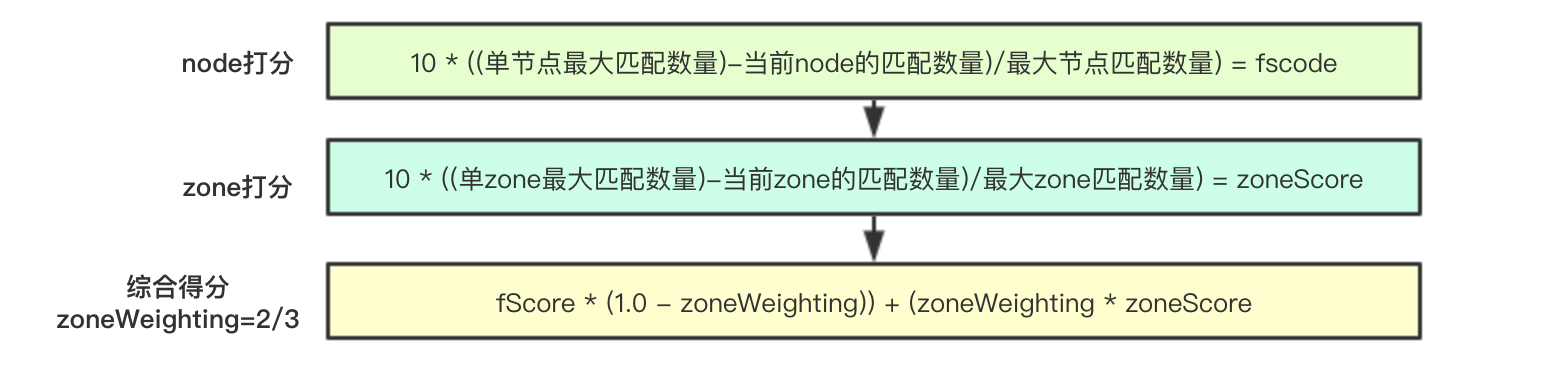
核心打分演算法流程包含兩個級別:node級別和zone級別,其演算法為:
node: 10 * ((單節點最大匹配數量)-當前node的匹配數量)/最大節點匹配數量) = fscode
zone: 10 * ((單zone最大匹配數量)-當前zone的匹配數量)/最大zone匹配數量) = zoneScore
合併: fScore * (1.0 - zoneWeighting)) + (zoneWeighting * zoneScore (zoneWeighting=2/3)
即優先進行zone級別分佈,其次再是node
比如分別有3個node其匹配pod數量分別為:
node1:3, node2:5, node3:10 則打分結果為:
node1: 10 * ((10-3)/10) = 7
node2: 10 * ((10-5)/10) = 5
node3: (10* ((10-5)/10) = 0
可以看到其上匹配的pod數量越多最終的優先順序則越小
假設分別有3個zone(跟node編號相同), 則zone得分為:zone1=7, zone2=5, zone3=0
最終計分(zoneWeighting=2/3): node1=7, node2=5, node3=0
maxCountByNodeNameFloat64 := float64(maxCountByNodeName)
maxCountByZoneFloat64 := float64(maxCountByZone)
MaxPriorityFloat64 := float64(schedulerapi.MaxPriority)
for i := range result {
// initializing to the default/max node score of maxPriority
fScore := MaxPriorityFloat64
if maxCountByNodeName > 0 {
fScore = MaxPriorityFloat64 * (float64(maxCountByNodeName-result[i].Score) / maxCountByNodeNameFloat64)
}
// If there is zone information present, incorporate it
if haveZones {
zoneID := utilnode.GetZoneKey(nodeNameToInfo[result[i].Host].Node())
if zoneID != "" {
zoneScore := MaxPriorityFloat64
if maxCountByZone > 0 {
zoneScore = MaxPriorityFloat64 * (float64(maxCountByZone-countsByZone[zoneID]) / maxCountByZoneFloat64)
}
fScore = (fScore * (1.0 - zoneWeighting)) + (zoneWeighting * zoneScore)
}
}
result[i].Score = int(fScore)
if klog.V(10) {
klog.Infof(
"%v -> %v: SelectorSpreadPriority, Score: (%d)", pod.Name, result[i].Host, int(fScore),
)
}
}今天就到這裡吧,其實可以看出在分佈的時候,是會優先嚐試zone分佈,然後在進行節點分佈,我比較好奇zoneWeighting=2/3這個值是怎麼來的,從註釋上看,老外也沒有證明,可能就是為了傾斜zone吧,大家週末愉快
微訊號:baxiaoshi2020

關注公告號閱讀更多原始碼分析文章
更多文章關注 www.sreguide.com
本文由部落格一文多發平臺 OpenWrite 釋出