
詳細解析Redis中的布隆過濾器及其應用
歡迎關注微信公眾號:萬貓學社,每週一分享Java技術乾貨。
什麼是布隆過濾器
布隆過濾器(Bloom Filter)是由Howard Bloom在1970年提出的一種比較巧妙的概率型資料結構,它可以告訴你某種東西一定不存在或者可能存在。當布隆過濾器說,某種東西存在時,這種東西可能不存在;當布隆過濾器說,某種東西不存在時,那麼這種東西一定不存在。
布隆過濾器相對於Set、Map 等資料結構來說,它可以更高效地插入和查詢,並且佔用空間更少,它也有缺點,就是判斷某種東西是否存在時,可能會被誤判。但是隻要引數設定的合理,它的精確度也可以控制的相對精確,只會有小小的誤判概率。
歡迎關注微信公眾號:萬貓學社
Redis中布隆過濾器
之前的布隆過濾器可以使用Redis中的點陣圖操作實現,直到Redis4.0版本提供了外掛功能,Redis官方提供的布隆過濾器才正式登場。布隆過濾器作為一個外掛載入到Redis Server中,就會給Redis提供了強大的布隆去重功能。
歡迎關注微信公眾號:萬貓學社,每週一分享Java技術乾貨。
布隆過濾器的基本使用
在Redis中,布隆過濾器有兩個基本命令,分別是:
bf.add:新增元素到布隆過濾器中,類似於集合的sadd命令,不過bf.add命令只能一次新增一個元素,如果想一次新增多個元素,可以使用bf.madd命令。bf.exists:判斷某個元素是否在過濾器中,類似於集合的sismember命令,不過bf.exists命令只能一次查詢一個元素,如果想一次查詢多個元素,可以使用bf.mexists命令。
比如:
> bf.add one-more-filter fans1 (integer) 1 > bf.add one-more-filter fans2 (integer) 1 > bf.add one-more-filter fans3 (integer) 1 > bf.exists one-more-filter fans1 (integer) 1 > bf.exists one-more-filter fans2 (integer) 1 > bf.exists one-more-filter fans3 (integer) 1 > bf.exists one-more-filter fans4 (integer) 0 > bf.madd one-more-filter fans4 fans5 fans6 1) (integer) 1 2) (integer) 1 3) (integer) 1 > bf.mexists one-more-filter fans4 fans5 fans6 fans7 1) (integer) 1 2) (integer) 1 3) (integer) 1 4) (integer) 0
上面的例子中,沒有發現誤判的情況,是因為元素數量比較少。當元素比較多時,可能就會發生誤判,怎麼才能減少誤判呢?
歡迎關注微信公眾號:萬貓學社,每週一分享Java技術乾貨。
布隆過濾器的高階使用
上面的例子中使用的布隆過濾器只是預設引數的布隆過濾器,它在我們第一次使用bf.add命令時自動建立的。Redis還提供了自定義引數的布隆過濾器,想要儘量減少布隆過濾器的誤判,就要設定合理的引數。
在使用bf.add命令新增元素之前,使用bf.reserve命令建立一個自定義的布隆過濾器。bf.reserve命令有三個引數,分別是:
key:鍵error_rate:期望錯誤率,期望錯誤率越低,需要的空間就越大。capacity:初始容量,當實際元素的數量超過這個初始化容量時,誤判率上升。
比如:
> bf.reserve one-more-filter 0.0001 1000000
OK如果對應的key已經存在時,在執行bf.reserve命令就會報錯。如果不使用bf.reserve命令建立,而是使用Redis自動建立的布隆過濾器,預設的error_rate是 0.01,capacity是 100。
布隆過濾器的error_rate越小,需要的儲存空間就越大,對於不需要過於精確的場景,error_rate設定稍大一點也可以。布隆過濾器的capacity設定的過大,會浪費儲存空間,設定的過小,就會影響準確率,所以在使用之前一定要儘可能地精確估計好元素數量,還需要加上一定的冗餘空間以避免實際元素可能會意外高出設定值很多。總之,error_rate和 capacity都需要設定一個合適的數值。
歡迎關注微信公眾號:萬貓學社,每週一分享Java技術乾貨。
布隆過濾器的原理簡介
瞭解了布隆過濾器的使用,我們再來介紹一下布隆過濾器的原理,做到“知其然,知其所以然”。
Redis中布隆過濾器的資料結構就是一個很大的位陣列和幾個不一樣的無偏雜湊函式(能把元素的雜湊值算得比較平均,能讓元素被雜湊到位陣列中的位置比較隨機)。如下圖,A、B、C就是三個這樣的雜湊函式,分別對“OneMoreStudy”和“萬貓學社”這兩個元素進行雜湊,位陣列的對應位置則被設定為1:
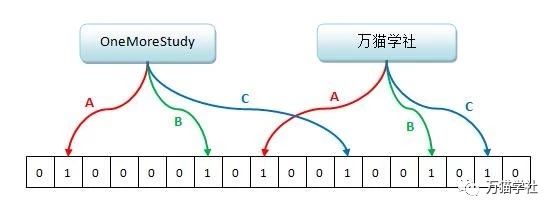
向布隆過濾器中新增元素時,會使用多個無偏雜湊函式對元素進行雜湊,算出一個整數索引值,然後對位陣列長度進行取模運算得到一個位置,每個無偏雜湊函式都會得到一個不同的位置。再把位陣列的這幾個位置都設定為1,這就完成了bf.add命令的操作。
向布隆過濾器查詢元素是否存在時,和新增元素一樣,也會把雜湊的幾個位置算出來,然後看看位陣列中對應的幾個位置是否都為1,只要有一個位為0,那麼就說明布隆過濾器裡不存在這個元素。如果這幾個位置都為1,並不能完全說明這個元素就一定存在其中,有可能這些位置為1是因為其他元素的存在,這就是布隆過濾器會出現誤判的原因。
歡迎關注微信公眾號:萬貓學社,每週一分享Java技術乾貨。
布隆過濾器的應用
解決快取擊穿的問題
一般情況下,先查詢快取是否有該條資料,快取中沒有時,再查詢資料庫。當資料庫也不存在該條資料時,每次查詢都要訪問資料庫,這就是快取擊穿。快取擊穿帶來的問題是,當有大量請求查詢資料庫不存在的資料時,就會給資料庫帶來壓力,甚至會拖垮資料庫。
可以使用布隆過濾器解決快取擊穿的問題,把已存在資料的key存在布隆過濾器中。當有新的請求時,先到布隆過濾器中查詢是否存在,如果不存在該條資料直接返回;如果存在該條資料再查詢快取查詢資料庫。
歡迎關注微信公眾號:萬貓學社,每週一分享Java技術乾貨。
黑名單校驗
發現存在黑名單中的,就執行特定操作。比如:識別垃圾郵件,只要是郵箱在黑名單中的郵件,就識別為垃圾郵件。假設黑名單的數量是數以億計的,存放起來就是非常耗費儲存空間的,布隆過濾器則是一個較好的解決方案。把所有黑名單都放在布隆過濾器中,再收到郵件時,判斷郵件地址是否在布隆過濾器中即可。
歡迎關注微信公眾號:萬貓學社,每週一分享Java技術乾貨