
redis應用實戰(布隆過濾器)
布隆過濾器是Burton Howard Bloom在1970年提出來的,一種空間效率極高的概率型演算法和資料結構,主要用來
判斷一個元素是否在集合中存在。因為他是一個概率型的演算法,所以會存在一定的誤差,如果傳入一個值去布隆過
濾器中檢索,可能會出現檢測存在的結果但是實際上可能是不存在的,但是肯定不會出現實際上不存在然後反饋存
在的結果。因此,Bloom Filter不適合那些“零錯誤”的應用場合。而在能容忍低錯誤率的應用場合下,Bloom Filter
通過極少的錯誤換取了儲存空間的極大節省。
bitmap
所謂的Bit-map就是用一個bit位來標記某個元素對應的Value,通過Bit為單位來儲存資料,可以大大節省儲存空間.
所以我們可以通過一個int型的整數的32位元位來儲存32個10進位制的數字,那麼這樣所帶來的好處是記憶體佔用少、
效率很高(不需要比較和位移)比如我們要儲存5(101)、3(11)四個數字,那麼我們申請int型的記憶體空間,會有32
個位元位。這四個數字的二進位制分別對應
從右往左開始數,比如第一個數字是5,對應的二進位制資料是101, 那麼從右往左數到第5位,把對應的二進位制資料
儲存到32個位元位上。
第一個5就是 00000000000000000000000000101000
輸入3時候 00000000000000000000000000001100
布隆過濾器原理
有了對點陣圖的理解以後,我們對布隆過濾器的原理理解就會更容易了,仍然以前面提到的40億資料為案例,假設這
40億資料為某郵件伺服器的黑名單資料,郵件服務需要根據郵箱地址來判斷當前郵箱是否屬於垃圾郵件。原理如下
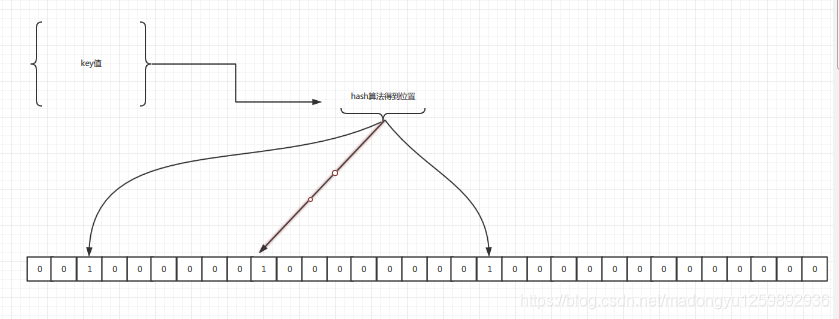
假設集合裡面有3個元素{x, y, z},雜湊函式的個數為3。首先將位陣列進行初始化,將裡面每個位都設定位0。對於
集合裡面的每一個元素,將元素依次通過3個雜湊函式進行對映,每次對映都會產生一個雜湊值,這個值對應位數
組上面的一個點,然後將位陣列對應的位置標記為1。查詢W元素是否存在集合中的時候,同樣的方法將W通過哈
希對映到位陣列上的3個點。如果3個點的其中有一個點不為1,則可以判斷該元素一定不存在集合中。反之,如果
3個點都為1,則該元素可能存在集合中
public static void main(String[] args) {
BloomFilter bloomFilter=BloomFilter.create
(Funnels.stringFunnel(Charset.defaultCharset()),1000000,0.001); //1%,有個概率問題,布隆越大,佔用的空間越多,但是錯誤概率減小了
bloomFilter.put("ma");
System.out.println(bloomFilter.mightContain("ma"));//為true表示在布隆過濾器裡
}
接下來按照該方法處理所有的輸入物件,每個物件都可能把bitMap中一些白位置塗黑,也可能會遇到已經塗黑的
位置,遇到已經為黑的讓他繼續為黑即可。處理完所有的輸入物件之後,在bitMap中可能已經有相當多的位置已
經被塗黑。至此,一個布隆過濾器生成完成,這個布隆過濾器代表之前所有輸入物件組成的集合。
如何去判斷一個元素是否存在bit array中呢? 原理是一樣,根據k個雜湊函式去得到的結果,如果所有的結果都是
1,表示這個元素可能(假設某個元素通過對映對應下標為4,5,6這3個點。雖然這3個點都為1,但是很明顯這3
個點是不同元素經過雜湊得到的位置,因此這種情況說明元素雖然不在集合中,也可能對應的都是1)存在。 如果
一旦發現其中一個位元位的元素是0,表示這個元素一定不存在
至於k個雜湊函式的取值為多少,能夠最大化的降低錯誤率(因為雜湊函式越多,對映衝突會越少),這個地方就
會涉及到最優的雜湊函式個數的一個演算法邏輯
