
Elasticsearch如何修改Mapping結構並實現業務零停機
Elasticsearch 版本:6.4.0
一、疑問
在專案中後期,如果想調整索引的 Mapping 結構,比如將 ik_smart 修改為 ik_max_word 或者 增加分片數量 等,但 Elasticsearch 不允許這樣修改呀,怎麼辦?
常規 解決方法:
- 根據最新的 Mapping 結構再建立一個索引
- 將舊索引的資料全量匯入到新索引中
- 告知使用者,業務要暫停使用一段時間
- 修改程式,將索引名替換成新的索引名稱,打包,重新上線
- 告知使用者,服務可以繼續使用了,並說一聲抱歉
我認為最大的弊端就是:需要修改替換程式,甚至有時候還得告知使用者暫停使用業務。
有沒有更好的方式去解決上面的需求呢?有!幸好,Elasticsearch 為我們提供了另外一種解決方法,可以不需要告知使用者和修改程式程式碼。那就是通過索引別名來重建索引。
二、索引別名
索引別名可以關聯一個或多個索引,並且可以在任何需要索引名稱的 API 中使用。 通俗解釋,別名類似於 windows 的快捷方式,linux 的軟連結,mysql 的檢視。別名為我們提供了極大的靈活性。它們允許我們執行以下操作:
- 在正在執行的叢集上,允許一個索引與另外一個索引之間透明切換。
- 對多個索引進行分組組合。比如,有根據月份來建立的索引,別名可與近三個月的索引進行關聯。這樣的話,我們就可以通過 別名 來 查詢近三個月索引 的全部資料。如果別名用得好,可以更好地控制檢索資料量的大小,來提高查詢效率,但這也需要經驗的積累。
本文開頭遇到的問題,就可以通過索引別名來實現,現在我們學習一下具體操作。
三、具體操作
如何在零停機(該索引所用到的程式不停止執行)的前提下,修改索引的 Mapping 欄位型別呢?可大體分為三步:
1、步驟一:複製資料
使用 reindex 操作來將舊索引(dynamic_data_v2)的資料完全複製到新索引(dynamic_data_v5)上:
POST _reindex
{
"source": {
"index": "dynamic_data_v2"
},
"dest": {
"index": "dynamic_data_v5"
}
}執行結果:
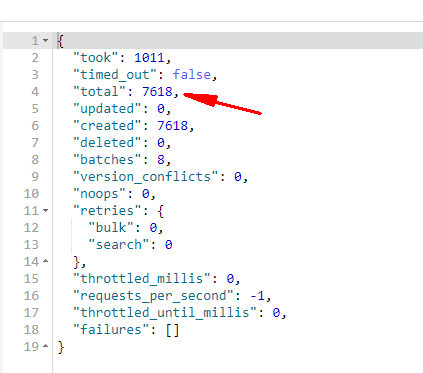
2、步驟二:修改別名關聯
POST /_aliases { "actions": [ { "remove": { "index": "dynamic_data_v2", "alias": "dynamic_data" }}, { "add": { "index": "dynamic_data_v5", "alias": "dynamic_data" }} ] }
3、步驟三:刪除舊索引(可選)
DELETE dynamic_data_v24、小結
至此,我們達到了偽更新(對於使用者來說透明化,無需停止服務)的效果。不過這裡存在一個問題,如果資料量超大的話,複製資料所消費的時間比較多,所以構建索引前還是要儘量考慮周全 mapping 結構。
關於索引別名更多操作,可參考:
https://www.elastic.co/guide/en/elasticsearch/reference/6.4/indices-aliases.html
四、可修改 mapping 的個別情況
Elasticsearch 不允許修改/刪除 Mapping 已存在欄位是因為:其底層使用的是 lucene 庫,索引和搜尋要涉及分詞方式等操作,更改 Mapping 將意味著使已建立索引的文件失效,所以不允許修改 已存在欄位型別等設定。
但也有個別情況:Elasticsearch 允許我們 將欄位新增到索引現有的 Mapping 結構中 或 更改現有欄位的僅搜尋設定。
1、可以新增欄位
POST dynamic_data_v2/_mapping/_doc
{
"properties": {
"amount":{
"type":"text"
}
}
}2、可以更改欄位型別為 multi_field
PUT dynamic_data_v2/_mapping/_doc
{
"properties": {
"amount":{
"type":"text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 10
}
}
}
}
}
# 為 amount 增加 multi_field
# "fields": {
# "keyword": {
# "type": "keyword",
# "ignore_above": 10
# }
# }3、可以將新 properties 新增到 “物件” 資料型別欄位。
在 Mapping 的 field 裡面設定 properties ,可以使欄位儲存 Object 的資料型別。以下的 name 可以理解為 “物件”資料型別欄位:
# 新增 name 欄位,附帶first的properties屬性
PUT dynamic_data_v2/_mapping/_doc
{
"properties": {
"name":{
"properties": {
"first": {
"type": "text"
}
}
}
}
}
# 可以支援繼續新增一個名為last的properties屬性
PUT dynamic_data_v2/_mapping/_doc
{
"properties": {
"name":{
"properties": {
"last": {
"type": "text"
}
}
}
}
}如下圖所示:

儲存資料:
# name 的物件裡面有兩個欄位,分別為:first 和 last,代表名和姓,比如“範閒”。
PUT dynamic_data_v2/_doc/1
{
"name": {
"first": "閒",
"last": "範"
}
}查詢資料:
GET dynamic_data_v2/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"name.last": "範"
}
},
{
"match_phrase": {
"name.first": "閒"
}
}
]
}
}
}返回結果:
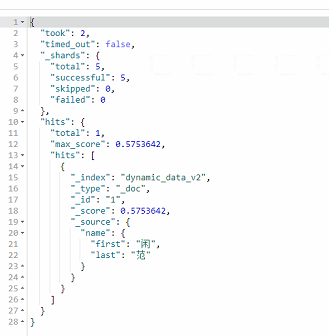
上述三種方式,詳情可參考:
https://www.elastic.co/guide/en/elasticsearch/reference/6.4/indices-put-mapping.html#updating-field-mappings
五、總結
別名是個好東西,而索引別名只是別名的其中一個型別。一般在專案中後期,索引中有大量資料的時候,才能體會到索引別名的妙用。正如本文提及:
- 使用者無感知地維護資料修改更新。
- 索引組合查詢,如果使用得當,可以實現精準快速查詢,提高效率。
建議: 相同索引別名的物理索引有 一致的 Mapping 和 資料結構 ,以提升檢索效率。
點關注,不迷路
好了各位,以上就是這篇文章的全部內容了,能看到這裡的人呀,都是人才。
白嫖不好,創作不易。各位的支援和認可,就是我創作的最大動力,我們下篇文章見!
如果本篇部落格有任何錯誤,請批評指教,不勝感激 !

相關推薦
Elasticsearch如何修改Mapping結構並實現業務零停機
Elasticsearch 版本:6.4.0 一、疑問 在專案中後期,如果想調整索引的 Mapping 結構,比如將 ik_smart 修改為 ik_max_word 或者 增加分片數量 等,但 Elasticsearch 不允許這樣修改呀,怎麼辦? 常規 解決方法: 根據最新的 Mapping 結構
68.qq號索引結構體寫入內存,並實現快速排序
ets style pau ont 步驟 之前 比較 多個 兩個 1 //兩個步驟,第一步讀取文件,並且初始化索引結構體,把初始化的索引結構體寫入到文件,第二步,讀取這個文件到索引結構體 2 //並對這個結構體進行快速排序,得到順序的索引,再寫入文件 3 #d
videojs修改播放器樣式並實現四路動態播放rtmp流視頻
擴展 pos 重載 部分 拍攝 播放器 並且 一個 視頻流 接了個無人機的項目,負責視頻播放這一塊,選用的是video.js這個視頻插件,本以為可以開開心心的開發,誰怎料網上有關這部分的資料如此之少,給我這個伸手黨給予了重大壓力。好了,不說廢話了。 項目的需求為實現
ElasticSearch最佳入門實踐(四十四)手動建立和修改mapping以及定製string型別資料是否分詞
1、如何建立索引 如果想設定 string 為分詞 把它設定為 analyzed not_analyzed 則是 設定為 exact value 全匹配 no 則 是不能被索引和匹配 2、修改mapping 注意事項:只能建立index時手動建立mapp
ElasticSearch最佳入門實踐(六十五)基於scoll+bulk+索引別名實現零停機重建索引
1、重建索引 一個field的設定是不能被修改的,如果要修改一個Field,那麼應該重新按照新的mapping,建立一個index,然後將資料批量查詢出來,重新用bulk api寫入index中 批量查詢的時候,建議採用scroll api,並且採用多執行緒
spring boot整合elasticsearch並實現簡單的增刪改查
java操作elasticsearch是作為一個無資料節點與其他節點之間通訊,因此使用的是tcp埠,elasticsearch預設的節點間通訊的tcp埠是9300。elasticsearch和jdk版本一定要適配,因為elasticsearch是用java編寫的,隨著版本的升
資料結構:實現一個棧,並完成各個介面的實現
實現一個棧 棧的概念 棧:一種特殊的線性表,其只允許在固定的一端進行插入和刪除元素操作。進行資料插入和刪除操作的一端 稱為棧頂,另一端稱為棧底。棧中的資料元素遵守 後進先出 LIFO(Last In First Out)的原則。 壓棧:棧的插入操作叫做進棧/壓棧
##資料結構##如何建立一棵哈夫曼樹並實現堆
哈夫曼樹是一種二叉樹,但是它是一種加權路徑長度最短的二叉樹。其可用堆來實現它的構建其構建方法如下://heap.h //仿函式 template<class T> struct Less { bool operator()(const T& left,
入門shader,並實現normal mapping on earth
shader 試執行在可程式設計gpu內的小程式 使用shader開始要使用兩個著色器 從vertex到fragment vertex 輸入的是頂點資訊,在中間傳遞最後在fragment輸出color 在新的version中,也可以使用兩者中間的 geometry shader. The geometry s
SpringBoot整合Elasticsearch並實現CRUD操作
配置準備 在build.gradle檔案中新增如下依賴: compile "org.elasticsearch.client:transport:5.5.2" compile "org.elasticsearch:elasticsearch:
ES修改mapping對映type或全部結構
測試伺服器一套ES,正式伺服器一套ES,突然正式網的搜尋開始出問題了,然後就像把測試網的ES對映直接導到正式網,因為一開始維護ES的人已經離職了,所以正式網和測試網對映結構有些不一樣的時候,不確定是不是這個原因導致的,所以就打算先把測試網的對映結構拿過來,看看是不是這個原因,於是有了下面一系列操
Elasticsearch索引mapping的寫入、檢視與修改
mapping的寫入與檢視 首先建立一個索引: curl -XPOST "http://127.0.0.1:9200/productindex" {"acknowledged":true} 現在只建立了一個索引,並沒有設定mapping,檢視一下索引mapping的
使用sql語句建立表,並實現對錶的修改操作
>需求: a. 在test資料庫中建立person表,其結構如表1所示。 b. 將表名稱修改為tb_person。 c. 刪除出生日期欄位。 d. 添加出生日期欄位,資料型別為DATE型別。 e. 修改number欄位為id,型別改為BIG
elasticsearch核心知識---52.倒排索引組成結構以及實現TF-IDF演算法
首先實現了採用java 簡易的實現TF-IDF演算法package matrixOnto.Ja_9_10_va; import com.google.common.base.Preconditions; import org.nutz.lang.Strings; impo
資料結構--並查集的原理及實現
一,並查集的介紹 並查集(Union/Find)從名字可以看出,主要涉及兩種基本操作:合併和查詢。這說明,初始時並查集中的元素是不相交的,經過一系列的基本操作(Union),最終合併成一個大的集合。 而在某次合併之後,有一種合理的需求:某兩個元素是否已經處在同一個集合中了?因此就需要Find操作。 並
easyui-combotree實現樹形結構的下拉控制元件,並實現節點回顯
專案開發,臨時的一個需求,將8000條資料整成樹形機構的下拉控制元件,網上找了資料,可以使用easyUI的combotree實現 看了官網資料,combotree需要的資料必須是json資料,json的key為 id,text,children,用的是jsonarray生成
el-tree+vue+js實現修改樹結構單選以及輸入框
如圖所示,點選左側檢視許可權,點選修改可以進行修改選擇,並帶有input輸入框以及單選框進行配置 element+vue展示程式碼: <el-tree v-show="!authorityDialog" :class="{'treeId':!authorit
jsp連線oracle資料庫並實現簡單登入功能,來自網路,部分修改。(亞信聯創實習)
共三個頁面:login.jsp、loginconf.jsp、loginsucess.jsp 使用者首先開啟login.jsp輸入使用者名稱及密碼,此時login.jsp會將輸入的使用者名稱及密碼提交到loginconf.jsp loginconf.jsp通過初始化連線資料庫
Activiti-5.18.0與springMvc專案整合和activiti-explorer單獨部署Web專案並與業務資料庫關聯方法(AutoEE_V2實現方式)
Activiti-5.18.0與springMvc專案整合和 activiti-explorer單獨部署Web專案並與業務資料庫關聯方法 (AutoEE實現方式) Double_AutoEE 2015-10-15 AutoEE-自動智慧快速開發
用js實現對話方塊修改內容,並更新主頁面
方法一: <SCRIPT LANGUAGE=Javascript> opener.location.reload(); window.close(); </SCRIPT> 方法二: <script language=javascrip