
NLP(二十一)人物關係抽取的一次實戰
去年,筆者寫過一篇文章利用關係抽取構建知識圖譜的一次嘗試,試圖用現在的深度學習辦法去做開放領域的關係抽取,但是遺憾的是,目前在開放領域的關係抽取,還沒有成熟的解決方案和模型。當時的文章僅作為筆者的一次嘗試,在實際使用過程中,效果有限。
本文將講述如何利用深度學習模型來進行人物關係抽取。人物關係抽取可以理解為是關係抽取,這是我們構建知識圖譜的重要一步。本文人物關係抽取的主要思想是關係抽取的pipeline(管道)模式,因為人名可以使用現成的NER模型提取,因此本文僅解決從文章中抽取出人名後,如何進行人物關係抽取。
本文采用的深度學習模型是文字分類模型,結合BERT預訓練模型,取得了較為不錯的效果。
本專案已經開源,Github地址為:https://github.com/percent4/people_relation_extract 。
本專案的專案結構圖如下:
資料集介紹
在進行這方面的嘗試之前,我們還不得不面對這樣一個難題,那就是中文人物關係抽取語料的缺失。資料是模型的前提,沒有資料,一切模型無從談起。因此,筆者不得不花費大量的時間收集資料。
筆者利用大量自己業餘的時間,收集了大約1800條人物關係樣本,整理成Excel(檔名稱為人物關係表.xlsx),前幾行如下:
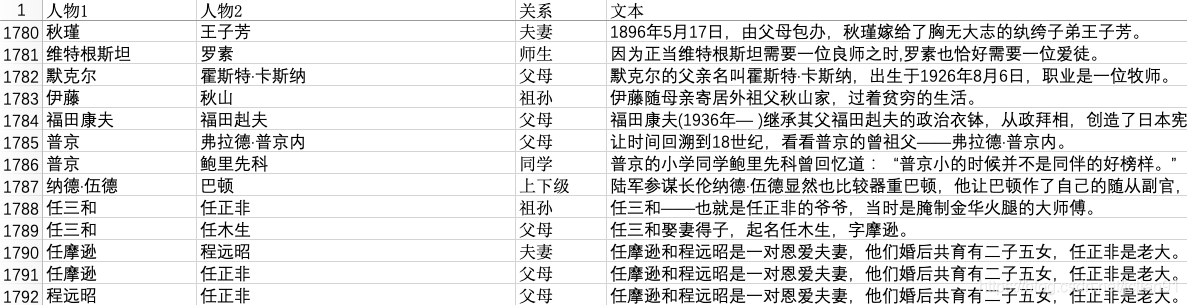
人物關係一共有14類,分別為unknown,夫妻,父母,兄弟姐妹,上下級,師生,好友,同學,合作,同人,情侶,祖孫,同門,親戚,其中unknown類別表示該人物關係不在其餘的13類中(人物之間沒有關係或者為其他關係),同人關係指的是兩個人物其實是同一個人,比如下面的例子:
邵逸夫(1907年10月4日—2014年1月7日),原名邵仁楞,生於浙江省寧波市鎮海鎮,祖籍浙江寧波。
上面的例子中,邵逸夫和邵仁楞就是同一個人。親戚關係指的是除了夫妻,父母,兄弟姐妹,祖孫之外的親戚關係,比如叔侄,舅甥關係等。
為了對該資料集的每個關係類別的數量進行統計,我們可以使用指令碼data/relation_bar_chart.py,完整的Python程式碼如下:
# -*- coding: utf-8 -*- # 繪製人物關係頻數統計條形圖 import pandas as pd import matplotlib.pyplot as plt # 讀取EXCEL資料 df = pd.read_excel('人物關係表.xlsx') label_list = list(df['關係'].value_counts().index) num_list= df['關係'].value_counts().tolist() # Mac系統設定中文字型支援 plt.rcParams["font.family"] = 'Arial Unicode MS' # 利用Matplotlib繪製條形圖 x = range(len(num_list)) rects = plt.bar(left=x, height=num_list, width=0.6, color='blue', label="頻數") plt.ylim(0, 500) # y軸範圍 plt.ylabel("數量") plt.xticks([index + 0.1 for index in x], label_list) plt.xticks(rotation=45) # x軸的標籤旋轉45度 plt.xlabel("人物關係") plt.title("人物關係頻數統計") plt.legend() # 條形圖的文字說明 for rect in rects: height = rect.get_height() plt.text(rect.get_x() + rect.get_width() / 2, height+1, str(height), ha="center", va="bottom") plt.show()
執行後的結果如下:
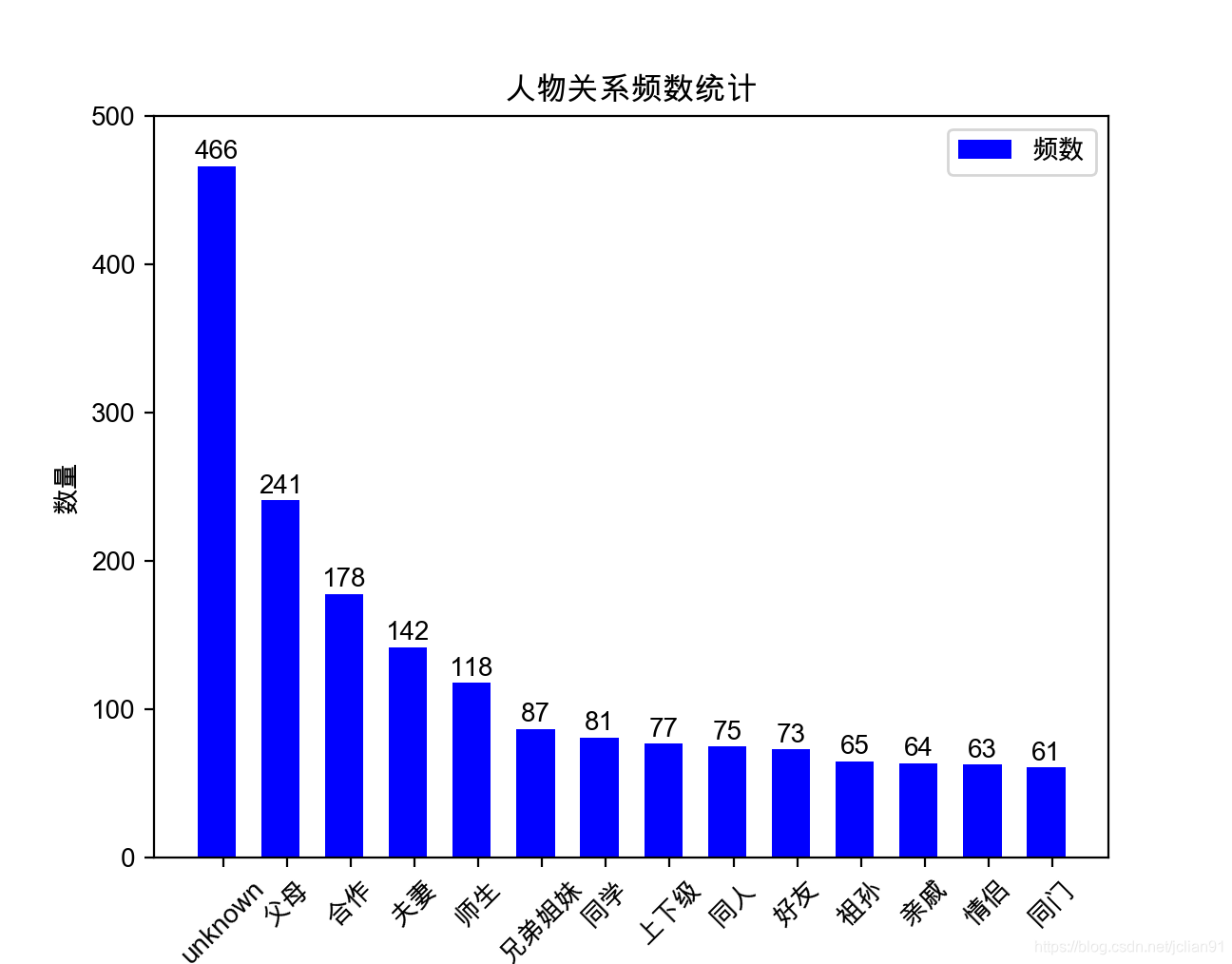
unknown類別最多,有466條,其餘的如祖孫, 親戚, 情侶, 同門等較多,只有60多條,這是因為這類人物關係的資料缺失不好收集。因此,語料的收集費時費力,需要消耗大量的精力。
資料預處理
收集好資料後,我們需要對資料進行預處理,預處理主要分兩步,一步是將人物關係和原文字整合在一起,第二步簡單,將資料集劃分為訓練集和測試集,比例為8:2。
我們對第一步進行詳細說明,將人物關係和原文字整合在一起。一般我們給定原文字和該文字中的兩個人物,比如:
邵逸夫(1907年10月4日—2014年1月7日),原名邵仁楞,生於浙江省寧波市鎮海鎮,祖籍浙江寧波。這句話中有兩個人物:邵逸夫,邵仁楞, 這個容易在語料中找到。然後我們將原文字的這兩個人物中的每個字元分別用'#'號程式碼,並通過'$'符號拼接在一起,形成的整合文字如下:
邵逸夫$邵仁楞$###(1907年10月4日—2014年1月7日),原名###,生於浙江省寧波市鎮海鎮,祖籍浙江寧波。處理成這種格式是為了方便文字分類模型進行呼叫。
資料預處理的指令碼為data/data_into_train_test.py,完整的Python程式碼如下:
# -*- coding: utf-8 -*-
import json
import pandas as pd
from pprint import pprint
df = pd.read_excel('人物關係表.xlsx')
relations = list(df['關係'].unique())
relations.remove('unknown')
relation_dict = {'unknown': 0}
relation_dict.update(dict(zip(relations, range(1, len(relations)+1))))
with open('rel_dict.json', 'w', encoding='utf-8') as h:
h.write(json.dumps(relation_dict, ensure_ascii=False, indent=2))
pprint(df['關係'].value_counts())
df['rel'] = df['關係'].apply(lambda x: relation_dict[x])
texts = []
for per1, per2, text in zip(df['人物1'].tolist(), df['人物2'].tolist(), df['文字'].tolist()):
text = '$'.join([per1, per2, text.replace(per1, len(per1)*'#').replace(per2, len(per2)*'#')])
texts.append(text)
df['text'] = texts
train_df = df.sample(frac=0.8, random_state=1024)
test_df = df.drop(train_df.index)
with open('train.txt', 'w', encoding='utf-8') as f:
for text, rel in zip(train_df['text'].tolist(), train_df['rel'].tolist()):
f.write(str(rel)+' '+text+'\n')
with open('test.txt', 'w', encoding='utf-8') as g:
for text, rel in zip(test_df['text'].tolist(), test_df['rel'].tolist()):
g.write(str(rel)+' '+text+'\n')執行完該指令碼後,會在data目錄下生成train.txt, test.txt和rel_dict.json,該json檔案中儲存的資訊如下:
{
"unknown": 0,
"夫妻": 1,
"父母": 2,
"兄弟姐妹": 3,
"上下級": 4,
"師生": 5,
"好友": 6,
"同學": 7,
"合作": 8,
"同人": 9,
"情侶": 10,
"祖孫": 11,
"同門": 12,
"親戚": 13
}簡單來說,是給每種關係一個id,轉化成類別型變數。
以train.txt為例,其前5行的內容如下:
4 方琳$李偉康$在生活中,###則把##看作小輩,常常替她解決難題。
3 佳子$久仁$12月,##和弟弟##參加了在東京舉行的全國初中生演講比賽。
2 錢慧安$錢祿新$###,生卒年不詳,海上畫家###之子。
0 吳繼坤$鄧新生$###還曾對媒體說:“我這個小小的投資商,經常得到###等領導的親自關注和關照,我覺到受寵若驚。”
2 洪博培$喬恩·M·亨茨曼$###的父親########是著名企業家、美國最大化學公司亨茨曼公司創始人。
10 夏樂$陳飛$兩小無猜劇情簡介:##和##是一對從小一起長大的青梅竹馬。在每一行中,空格之前的數字所對應的人物關係可以在rel_dict.json中找到。
模型訓練
在模型訓練前,為了將資料的格式更好地適應模型,需要再對trian.txt和test.txt進行處理。處理指令碼為load_data.py,完整的Python程式碼如下:
# -*- coding: utf-8 -*-
import pandas as pd
# 讀取txt檔案
def read_txt_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
content = [_.strip() for _ in f.readlines()]
labels, texts = [], []
for line in content:
parts = line.split()
label, text = parts[0], ''.join(parts[1:])
labels.append(label)
texts.append(text)
return labels, texts
# 獲取訓練資料和測試資料,格式為pandas的DataFrame
def get_train_test_pd():
file_path = 'data/train.txt'
labels, texts = read_txt_file(file_path)
train_df = pd.DataFrame({'label': labels, 'text': texts})
file_path = 'data/test.txt'
labels, texts = read_txt_file(file_path)
test_df = pd.DataFrame({'label': labels, 'text': texts})
return train_df, test_df
if __name__ == '__main__':
train_df, test_df = get_train_test_pd()
print(train_df.head())
print(test_df.head())
train_df['text_len'] = train_df['text'].apply(lambda x: len(x))
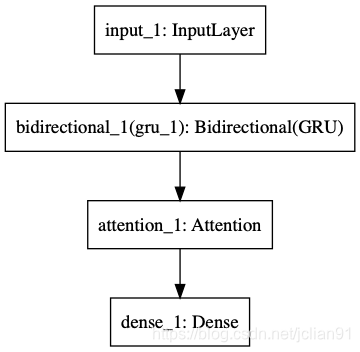
print(train_df.describe()) 本專案所採用的模型為:BERT + 雙向GRU + Attention + FC,其中BERT用來提取文字的特徵,關於這一部分的介紹,已經在文章NLP(二十)利用BERT實現文字二分類中給出;Attention為注意力機制層,FC為全連線層,模型的結構圖如下(利用Keras匯出):
模型訓練的指令碼為model_train.py,完整的Python程式碼如下:
# -*- coding: utf-8 -*-
# 模型訓練
import numpy as np
from load_data import get_train_test_pd
from keras.utils import to_categorical
from keras.models import Model
from keras.optimizers import Adam
from keras.layers import Input, Dense
from bert.extract_feature import BertVector
from att import Attention
from keras.layers import GRU, Bidirectional
# 讀取檔案並進行轉換
train_df, test_df = get_train_test_pd()
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=80)
print('begin encoding')
f = lambda text: bert_model.encode([text])["encodes"][0]
train_df['x'] = train_df['text'].apply(f)
test_df['x'] = test_df['text'].apply(f)
print('end encoding')
# 訓練集和測試集
x_train = np.array([vec for vec in train_df['x']])
x_test = np.array([vec for vec in test_df['x']])
y_train = np.array([vec for vec in train_df['label']])
y_test = np.array([vec for vec in test_df['label']])
# print('x_train: ', x_train.shape)
# 將型別y值轉化為ont-hot向量
num_classes = 14
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# 模型結構:BERT + 雙向GRU + Attention + FC
inputs = Input(shape=(80, 768,))
gru = Bidirectional(GRU(128, dropout=0.2, return_sequences=True))(inputs)
attention = Attention(32)(gru)
output = Dense(14, activation='softmax')(attention)
model = Model(inputs, output)
# 模型視覺化
# from keras.utils import plot_model
# plot_model(model, to_file='model.png')
model.compile(loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
# 模型訓練以及評估
model.fit(x_train, y_train, batch_size=8, epochs=30)
model.save('people_relation.h5')
print(model.evaluate(x_test, y_test))利用該模型對資料集進行訓練,輸出的結果如下:
begin encoding
end encoding
Epoch 1/30
1433/1433 [==============================] - 15s 10ms/step - loss: 1.5558 - acc: 0.4962
**********(中間部分省略輸出)**************
Epoch 30/30
1433/1433 [==============================] - 12s 8ms/step - loss: 0.0210 - acc: 0.9951
[1.1099, 0.7709]整個訓練過程持續十來分鐘,經過30個epoch的訓練,最終在測試集上的loss為1.1099,acc為0.7709,在小資料量下的效果還是不錯的。
模型預測
上述模型訓練完後,利用儲存好的模型檔案,對新的資料進行預測。模型預測的指令碼為model_predict.py,完整的Python程式碼如下:
# -*- coding: utf-8 -*-
# 模型預測
import json
import numpy as np
from bert.extract_feature import BertVector
from keras.models import load_model
from att import Attention
# 載入模型
model = load_model('people_relation.h5', custom_objects={"Attention": Attention})
# 示例語句及預處理
text = '趙金閃#羅玉兄#在這裡,趙金閃和羅玉兄夫婦已經生活了大半輩子。他們夫婦都是哈密市伊州區林業和草原局的護林員,紮根東天山腳下,守護著這片綠。'
per1, per2, doc = text.split('#')
text = '$'.join([per1, per2, doc.replace(per1, len(per1)*'#').replace(per2, len(per2)*'#')])
print(text)
# 利用BERT提取句子特徵
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=80)
vec = bert_model.encode([text])["encodes"][0]
x_train = np.array([vec])
# 模型預測並輸出預測結果
predicted = model.predict(x_train)
y = np.argmax(predicted[0])
with open('data/rel_dict.json', 'r', encoding='utf-8') as f:
rel_dict = json.load(f)
id_rel_dict = {v:k for k,v in rel_dict.items()}
print(id_rel_dict[y])該人物關係輸出的結果為夫妻。
接著,我們對更好的資料進行預測,輸出的結果如下:
原文: 潤生#潤葉#不過,他對潤生的姐姐潤葉倒懷有一種親切的感情。
預測人物關係: 兄弟姐妹
原文: 孫玉厚#蘭花#腦子裡把前後村莊未嫁的女子一個個想過去,最後選定了雙水村孫玉厚的大女子蘭花。
預測人物關係: 父母
原文: 金波#田福堂#每天來回二十里路,與他一塊上學的金波和大隊書記田福堂的兒子潤生都有自行車,只有他是兩條腿走路。
預測人物關係: unknown
原文: 潤生#田福堂#每天來回二十里路,與他一塊上學的金波和大隊書記田福堂的兒子潤生都有自行車,只有他是兩條腿走路。
預測人物關係: 父母
原文: 周山#李自成#周山原是李自成親手提拔的將領,闖王對他十分信任,叫他擔任中軍。
預測人物關係: 上下級
原文: 高桂英#李自成#高桂英是李自成的結髮妻子,今年才三十歲。
預測人物關係: 夫妻
原文: 羅斯福#特德#果然,此後羅斯福的政治旅程與長他24歲的特德叔叔如出一轍——紐約州議員、助理海軍部長、紐約州州長以至美國總統。
預測人物關係: 親戚
原文: 詹姆斯#克利夫蘭#詹姆斯擔任了該公司的經理,作為一名民主黨人,他曾資助過克利夫蘭的再度競選,兩人私交不錯。
預測人物關係: 上下級(預測出錯,應該是好友關係)
原文: 高劍父#關山月#高劍父是關山月在藝術道路上非常重要的導師,同時關山月也是最能夠貫徹高劍父“折中中西”理念的得意門生。
預測人物關係: 師生
原文: 唐怡瑩#唐石霞#唐怡瑩,姓他他拉氏,名為他他拉·怡瑩,又名唐石霞,隸屬於滿洲鑲紅旗。
預測人物關係: 同人總結
本文采用的深度學習模型是文字分類模型,結合BERT預訓練模型,在小標註資料量下對人物關係抽取這個任務取得了還不錯的效果。同時模型的識別準確率和使用範圍還有待於提升,提升點筆者認為如下:
- 標註的資料量需要加大,現在的資料才1800條左右,如果資料量上去了,那麼模型的準確率還有使用範圍也會提升;
- 其他更多的模型有待於嘗試;
- 在預測時,模型的預測時間較長,原因在於用BERT提取特徵時耗時較長,可以考慮縮短模型預測的時間;
- 其他問題歡迎補充。
感謝大家閱讀~
本人的微信公眾號: Python之悟(微訊號為:easy_web_scrape),歡迎大家關注~