
NLP(二十二)利用ALBERT實現文字二分類
阿新 • • 發佈:2020-03-05
在文章[NLP(二十)利用BERT實現文字二分類](https://www.cnblogs.com/jclian91/p/12301056.html)中,筆者介紹瞭如何使用BERT來實現文字二分類功能,以判別是否屬於出訪類事件為例子。但是呢,利用BERT在做模型預測的時候存在預測時間較長的問題。因此,我們考慮用新出來的預訓練模型來加快模型預測速度。
本文將介紹如何利用ALBERT來實現文字二分類。
### 關於ALBERT
ALBERT的提出時間大約是在2019年10月,其第一作者為谷歌科學家藍振忠博士。ALBERT的論文地址為:[https://openreview.net/pdf?id=H1eA7AEtvS](https://openreview.net/pdf?id=H1eA7AEtvS) , Github專案地址為: [https://github.com/brightmart/albert_zh](https://github.com/brightmart/albert_zh) 。
簡單說來,ALBERT是BERT的一個精簡版,它在BERT模型的基礎上進行改造,減少了大量引數,使得其在模型訓練和模型預測的速度上有很大提升,而模型的效果只會有微小幅度的下降,具體的效果和速度方面的說明可以參考Github專案。
ALBERT相對於BERT的改進如下:
- 對Embedding因式分解(Factorized embedding parameterization);
- 跨層的引數共享(Cross-layer parameter sharing);
- 句間連貫(Inter-sentence coherence loss);
- 移除dropout 。
筆者在北京的時候也寫過ALBERT在提升序列標註演算法的預測速度方面的一篇文章:[NLP(十八)利用ALBERT提升模型預測速度的一次嘗試](https://blog.csdn.net/jclian91/article/details/102631837) ,該專案的Github地址為:[https://github.com/percent4/ALBERT_4_Time_Recognition](https://github.com/percent4/ALBERT_4_Time_Recognition) 。
### 專案說明
本專案的資料和程式碼主要參考筆者的文章[NLP(二十)利用BERT實現文字二分類](https://www.cnblogs.com/jclian91/p/12301056.html),該專案是想判別輸入的句子是否屬於政治上的出訪類事件。筆者一共收集了340條資料,其中280條用作訓練集,60條用作測試集。
專案結構如下圖:
在這裡我們使用ALBERT已經訓練好的檔案`albert_tiny`,借鑑BERT的呼叫方法,我們在這裡給出`albert_zh`模組,能夠讓ALBERT提取文字的特徵,具體程式碼不在這裡給出,有興趣的讀者可以訪問該專案的Github地址:。
注意,`albert_tiny`給出的向量維度為312,我們的模型訓練程式碼(model_train.py)如下:
```python
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-03-04 13:37
import os
import numpy as np
from load_data import train_df, test_df
from keras.utils import to_categorical
from keras.models import Model
from keras.optimizers import Adam
from keras.layers import Input, BatchNormalization, Dense
import matplotlib.pyplot as plt
from albert_zh.extract_feature import BertVector
# 讀取檔案並進行轉換
bert_model = BertVector(pooling_strategy="REDUCE_MEAN", max_seq_len=100)
print('begin encoding')
f = lambda text: bert_model.encode([text])["encodes"][0]
train_df['x'] = train_df['text'].apply(f)
test_df['x'] = test_df['text'].apply(f)
print('end encoding')
x_train = np.array([vec for vec in train_df['x']])
x_test = np.array([vec for vec in test_df['x']])
y_train = np.array([vec for vec in train_df['label']])
y_test = np.array([vec for vec in test_df['label']])
print('x_train: ', x_train.shape)
# Convert class vectors to binary class matrices.
num_classes = 2
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# 建立模型
x_in = Input(shape=(312, ))
x_out = Dense(32, activation="relu")(x_in)
x_out = BatchNormalization()(x_out)
x_out = Dense(num_classes, activation="softmax")(x_out)
model = Model(inputs=x_in, outputs=x_out)
print(model.summary())
model.compile(loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
# 模型訓練以及評估
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), batch_size=8, epochs=20)
model.save('visit_classify.h5')
print(model.evaluate(x_test, y_test))
# 繪製loss和acc影象
plt.subplot(2, 1, 1)
epochs = len(history.history['loss'])
plt.plot(range(epochs), history.history['loss'], label='loss')
plt.plot(range(epochs), history.history['val_loss'], label='val_loss')
plt.legend()
plt.subplot(2, 1, 2)
epochs = len(history.history['acc'])
plt.plot(range(epochs), history.history['acc'], label='acc')
plt.plot(range(epochs), history.history['val_acc'], label='val_acc')
plt.legend()
plt.savefig("loss_acc.png")
```
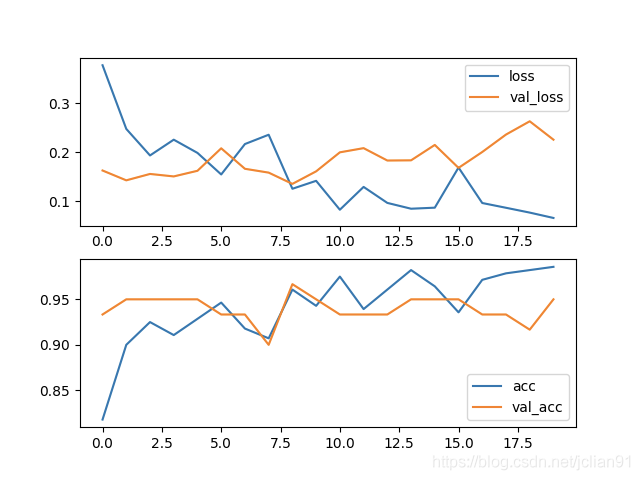
模型訓練的效果很不錯,在訓練集的acc為0.9857,在測試集上的acc為0.9500,具體如下:
### 與BERT的預測對比
接下來我們在模型預測上的時間,與BERT的文字二分類模型預測時間做一個對比,這樣有助於提升我們對ALBERT的印象。
BERT的文字二分類模型預測可以參考文章[NLP(二十)利用BERT實現文字二分類](https://www.cnblogs.com/jclian91/p/12301056.html),本文給出的程式碼與BERT實現的模型預測程式碼基本一致,只不過BERT提取特徵改成ALBERT提取特徵。
本文的模型預測程式碼(model_predict.py)如下:
```python
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-03-04 17:33
import time
import pandas as pd
import numpy as np
from albert_zh.extract_feature import BertVector
from keras.models import load_model
load_model = load_model("visit_classify.h5")
# 預測語句
texts = ['在訪問限制中,使用者可以選擇禁用iPhone的功能,包括Siri、iTunes購買功能、安裝/刪除應用等,甚至還可以讓iPhone變成一臺功能手機。以下是訪問限制具體可以實現的一些功能',
'IT之家4月23日訊息 近日,谷歌在其官方論壇釋出訊息表示,他們為Android Auto添加了一項新功能:可以訪問完整聯絡人列表。使用者現在可以通過在Auto的電話撥號介面中開啟左上角的選單訪問完整的聯絡人列表。值得注意的是,這一功能僅支援在車輛停止時使用。',
'要通過telnet 訪問路由器,需要先通過console 口對路由器進行基本配置,例如:IP地址、密碼等。',
'IT之家3月26日訊息 近日反盜版的國際諮詢公司MUSO釋出了2017年的年度報告,其中的資料顯示,去年盜版資源網站訪問量達到了3000億次,比前一年(2016年)提高了1.6%。美國是訪問盜版站點次數最多的國家,共有279億次訪問;其後分別是俄羅斯、印度和巴西,中國位列第18。',
'應葡萄牙議會邀請,全國人大常委會副委員長吉炳軒率團於12月14日至16日訪問葡萄牙,會見副議長費利佩、社會黨副總書記卡內羅。',
'2月26日至3月2日,應香港特區政府“內地貴賓訪港計劃”邀請,省委常委、常務副省長陳向群赴港考察訪問,重點圍繞“香港所長、湖南所需”,與特區政府相關部門和機構深入交流,推動湖南與香港交流合作取得新進展。',
'目前A站已經恢復了訪問,可以直接登入,網頁載入正常,視訊已經可以正常播放。',
'難民署特使安吉麗娜·朱莉6月8日結束了對哥倫比亞和委內瑞拉邊境地區的難民營地為期兩天的訪問,她對哥倫比亞人民展現的人道主義和勇氣表示讚揚。',
'據《南德意志報》報道,德國總理默克爾計劃明年1月就前往安卡拉,和土耳其總統埃爾多安進行會談。',
'自9月14日至18日,由越共中央政治局委員、中央書記處書記、中央經濟部部長阮文平率領工作代表團對希臘進行工作訪問。',
'Win7電腦提示無線介面卡或訪問點有問題怎麼辦?很多使用者在使用無線網連線上網時,發現無線網顯示已連線,但旁邊卻出現了一個黃色感嘆號,無法進行網路操作,通過診斷提示電腦無線介面卡或訪問點有問題,且處於未修復狀態,這該怎麼辦呢?下面小編就和大家分享下Win7電腦提示無線介面卡或訪問點有問題的解決方法。',
'2019年10月13日至14日,外交部副部長馬朝旭訪問智利,會見智利外長裡韋拉,同智利總統外事顧問薩拉斯舉行會談,就智利舉辦亞太經合組織(APEC)第二十七次領導人非正式會議等深入交換意見。',
'未開發所有安全組之前訪問,FTP可以連結上,但是開啟會很慢,需要1-2分鐘才能連結上',
'win7系統電腦的使用者,在連線WIFI網路網上時,有時候會遇到突然上不了網,檢視連線的WIFI出現“有限的訪問許可權”的文字提示。',
'聯合國祕書長潘基文8日訪問了日本福島縣,與當地災民交流並訪問了一所高中。',
'國務院總理溫家寶當地時間23日下午乘專機抵達布宜諾斯艾利斯,開始對阿根廷進行正式訪問。',
'正在中國訪問的巴貝多總理斯圖爾特15日在陝西西安參觀訪問。',
'據外媒報道,當地時間10日,美國白宮發聲明稱,美國總統特朗普將於2月底訪問印度,與印度總理莫迪進行戰略對話。',
'2月28日,唐山曹妃甸藍色海洋科技有限公司董事長趙力軍等一行5人到黃海水產研究所交流訪問。黃海水產研究所副所長辛福言及相關部門負責人、專家等參加了會議。',
'2018年7月2日,莫斯科孔子文化促進會會長姜彥彬,常務副會長陳國建,在中國著名留俄油畫大師牟克教授的陪同下,訪問了莫斯科國立蘇里科夫美術學院,受到第一副校長伊戈爾·戈爾巴秋克先生接待。'
'據外媒報道,當地時間26日晚,阿爾及利亞總統特本抵達沙烏地阿拉伯,進行為期三天的訪問。兩國領導人預計將就國家間合作和地區發展進行磋商。',
'與標準Mozy一樣,Stash資料夾為使用者提供了對其備份檔案的基於雲的訪問,但是它們還使他們可以隨時,跨多個裝置(包括所有計算機,智慧手機和平板電腦)訪問它們。換句話說,使用瀏覽器的任何人都可以同時檢視檔案(如果需要)。作業系統和裝置品牌無關。',
'研究表明,每個網頁的平均預期壽命為44至100天。當用戶通過瀏覽器訪問已消失的網頁時,就會看到「Page Not Found」的錯誤資訊。對於這種情況,相信大多數人也只能不了了之。不過有責任心的組織——網際網路檔案館為了提供更可靠的Web服務,它聯手Brave瀏覽器專門針對此類網頁提供了一鍵載入存檔頁面的功能。',
'據外媒報道,土耳其總統府於當地時間2日表示,土耳其總統埃爾多安計劃於5日對俄羅斯進行為期一天的訪問。',
'3日,根據三星電子的訊息,李在鎔副會長這天訪問了位於韓國慶尚北道龜尾市的三星電子工廠。'] * 10
labels = []
bert_model = BertVector(pooling_strategy="REDUCE_MEAN", max_seq_len=100)
init_time = time.time()
# 對上述句子進行預測
for text in texts:
# 將句子轉換成向量
vec = bert_model.encode([text])["encodes"][0]
x_train = np.array([vec])
# 模型預測
predicted = load_model.predict(x_train)
y = np.argmax(predicted[0])
label = 'Y' if y else 'N'
labels.append(label)
cost_time = time.time() - init_time
print("Average cost time: %s." % (cost_time/len(texts)))
for text, label in zip(texts, labels):
print('%s\t%s' % (label, text))
df = pd.DataFrame({'句子':texts, "是否屬於出訪類事件": labels})
df.to_excel('./result.xlsx', index=False)
```
輸出的平均預測時長為:`16.98ms`,而BERT版的平均預測時間為:`257.31ms`。
我們將模型預測寫成HTTP服務,程式碼(server.py)如下:
```python
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-03-04 20:13
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
from tornado.options import define, options
import json
import numpy as np
from albert_zh.extract_feature import BertVector
from keras.models import load_model
# 定義埠為10008
define("port", default=10008, help="run on the given port", type=int)
# 載入ALBERT
bert_model = BertVector(pooling_strategy="REDUCE_MEAN", max_seq_len=100)
# 載入已經訓練好的模型
load_model = load_model("visit_classify.h5")
# 對句子進行預測
class PredictHandler(tornado.web.RequestHandler):
def post(self):
text = self.get_argument("text")
# 將句子轉換成向量
vec = bert_model.encode([text])["encodes"][0]
x_train = np.array([vec])
# 模型預測
predicted = load_model.predict(x_train)
y = np.argmax(predicted[0])
label = '是' if y else "否"
# 返回結果
result = {"原文": text, "是否屬於出訪類事件?": label}
self.write(json.dumps(result, ensure_ascii=False, indent=2))
# 主函式
def main():
# 開啟tornado服務
tornado.options.parse_command_line()
# 定義app
app = tornado.web.Application(
handlers=[(r'/predict', PredictHandler)] #網頁路徑控制
)
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
main()
```
用Postman進行測試,如下圖:

實踐證明,用ALBERT做文字特徵提取,模型訓練的效果基本與BERT差別微小,模型訓練速度明顯提升,更重要的是,模型預測的速度只有BERT版本的6.6%(不同情況下可能有略微差異),這在生產上是十分有幫助的。
### 參考網址
1. 中文預訓練ALBERT模型來了:小模型登頂GLUE,Base版模型小10倍速度快1倍: [https://zhuanlan.zhihu.com/p/85037097](https://zhuanlan.zhihu.com/p/85037097)
2. ALBERT一作藍振忠:預訓練模型應用已成熟,ChineseGLUE要對標GLUE基準:[https://tech.sina.com.cn/roll/2019-11-17/doc-iihnzhfy9804802.shtml](https://tech.sina.com.cn/roll/2019-11-17/doc-iihnzhfy9804802.shtml) 。
3. 解讀ALBERT:[https://blog.csdn.net/weixin_37947156/article/details/101529943](https://blog.csdn.net/weixin_37947156/article/details/101529943) 。
4. ALBERT的Github專案地址:[https://github.com/brightmart/albert_zh](https://github.com/brightmart/albert_