
大資料篇:Zookeeper
Zookeeper

1 Zookeeper概念
Zookeeper是什麼
是一個基於觀察者設計模式的分散式服務管理框架,它負責和管理需要關心的資料,然後接受觀察者的註冊,一旦這些資料的狀態發生變化,Zookeeper就將負責通知已經在Zookeeper上註冊的那些觀察者做出相應的反應。
Zookeeper特點

哪些系統用到了Zookeeper
- HDFS
- YARN
- Storm
- HBase
- Flume
- Dubbo(阿里巴巴)
2 Zookeeper基本原理
2.1 Zookeeper架構
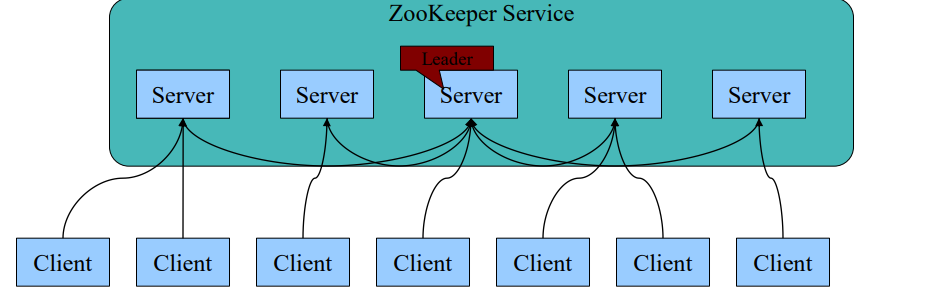
- 一個領導者(Leader)和多個跟隨者(Follower)組成的叢集,在啟動時根據Paxos協議選舉一個Leader。
- 叢集中只要有半數以上的節點存活,Zookeeper叢集就能正常服務。
- 全域性一致性:每個Server儲存一份相同的資料副本,Client無論連結到哪個Server,資料都是一致的。
- Leader根據Zab協議負責處理資料的更新等操作。
- 更新請求順序進行,來自同一個Client的更新請求按其傳送順序依次執行。
- 原子性:一次更新操作(可以是多個),當且僅當大多數Server在記憶體中成功修改資料,要麼成功,要麼失敗。
- 實時性:在一定時間範圍內,Client能讀到最新資料。
2.2 Zookeeper角色
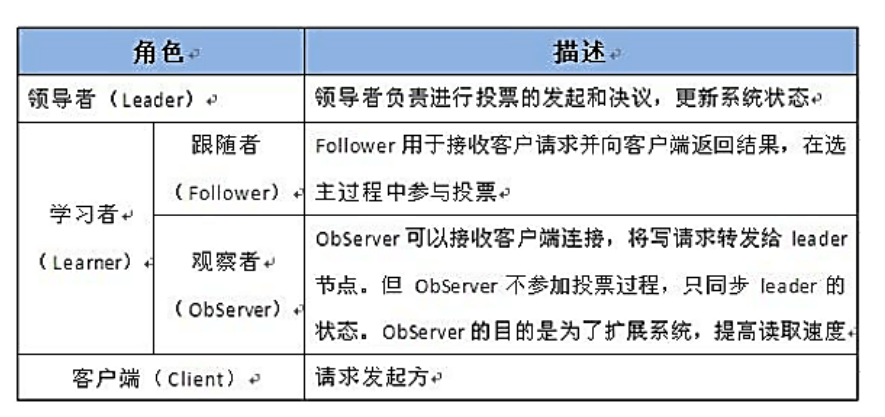
- Leader選舉演算法採用了Paxos協議;
- Paxos核心思想:當多數Server寫成功,則任務資料寫成功。
- 如果有3個Server,則需要2個寫成功即可。
- 如果有5個Server,則需要3個寫成功即可。
- Zookeeper Server數目一般為奇數
- 如果有3個Server,則最多允許1個Server掛掉。
- 如果有4個Server,則最多允許1個Server掛掉。
- 所以3臺和4臺效果一樣,那麼為什麼選4臺呢。
2.3 Zookeeper資料結構
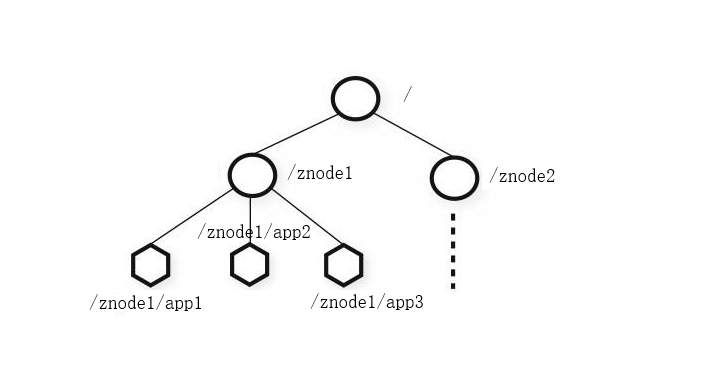
- Zookeeper資料模型結構與Unix檔案系統很像,整體可以看做是樹,每個節點為一個Znode,每一個Znode預設能儲存1MB資料,每個Znode都可以通過其路徑唯一標識。
- 和Unix不同的是,Znode可以存資料,又可有子節點。(不同於檔案和資料夾的概念)
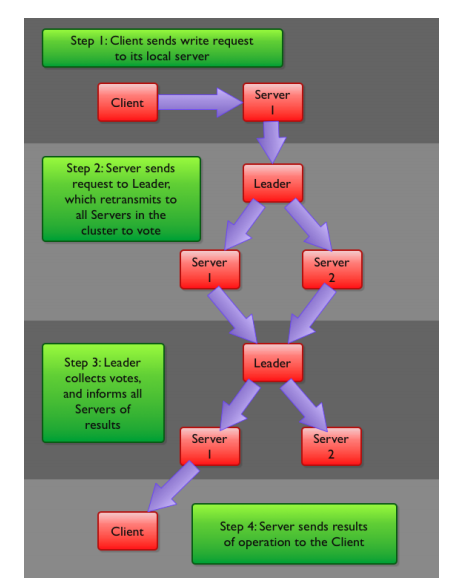
2.4 Zookeeper 資料寫流程
3 Zookeeper應用場景
- 統一命名服務
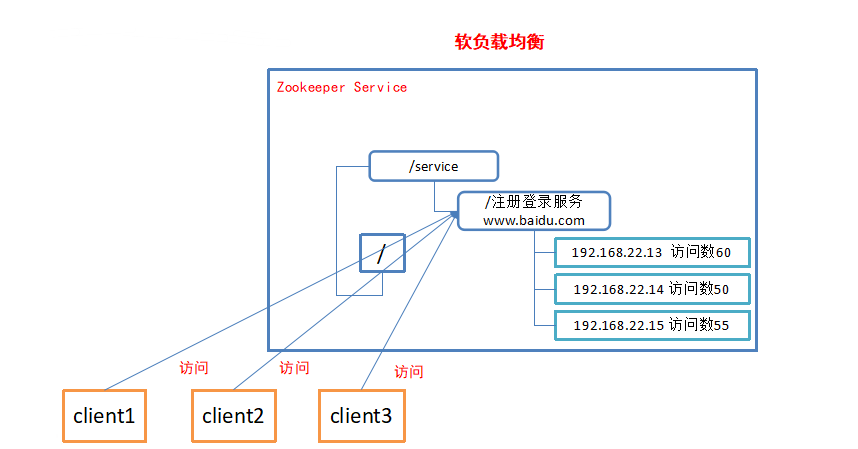
在分散式環境下,經常需要對應用/服務進行統一命名,便於識別。例如:IP不容易記住,而域名容易記住。
- 配置管理
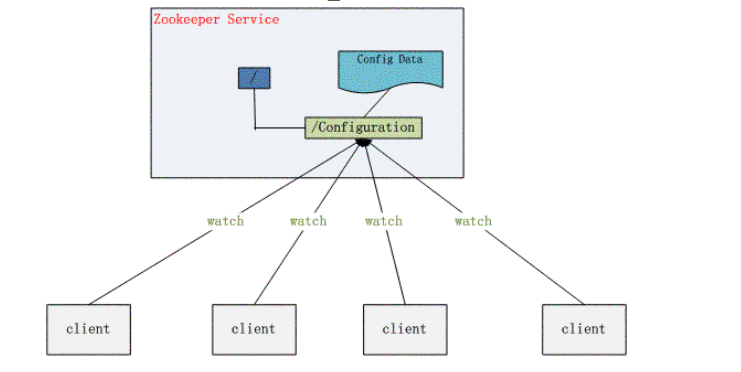
一個叢集中,搜遊節點的配置資訊是一致的,對配置檔案修改後,希望能夠快速同步到各個節點上。例如Hadoop。
- 叢集管理
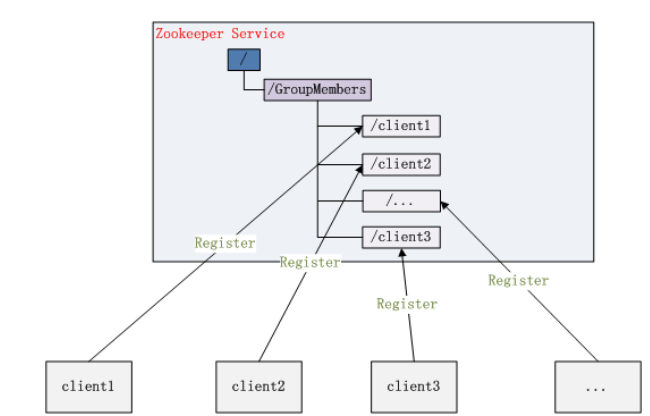
分散式環境中,實時掌握每個節點的狀態是必要的。例如叢集中的Master的監控和選舉。
- 分散式通知/協調
分散式環境中,經常存在一個服務需要知道它所管理的子服務狀態。例如NameNode需要知道DataNode狀態。
- 分散式鎖
多個客戶端同時在Zookeeper上建立相同的znode,只有一個建立成功。
建立成功的客戶端得到鎖,其他客戶端等待。
- 分散式佇列
當一個列隊的成員都聚齊時,這個列隊才可用,否則一直等待所有成員到達,這種事同步列隊。
列隊按照FIFO方式進行入隊和出隊操作,例如實現生產者和消費者模型。
同步列隊中一個Job由多個task組成,只有所有任務完成後,Job才執行完成。如:可以為Job建立一個/job的節點,在其下每完成一個task建立一個臨時的znode,一旦臨時節點數達到task總數,則Job執行完成。
4 zookeeper windows連結工具
下載地址
- 下載解壓
- 在此目錄下java -jar zookeeper-dev-ZooInspector.jar或者點選start.bat檔案啟動。
- 進行對zk的操作吧!
5 zookeeper命令列操作
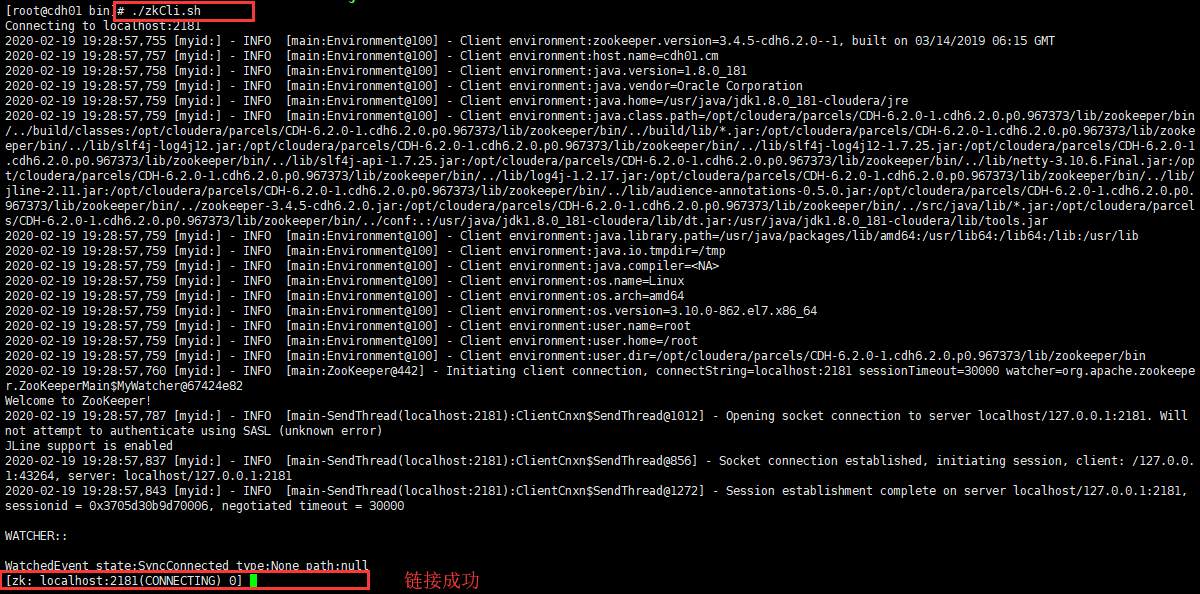
- 執行 zkCli.sh 指令碼進入命令列工具
5.1 help 幫助命令

5.2 ls path [watch] 命令
- 檢視znode中包含內容
- watch為觀察的意思,觀察此路徑下的節點變化
5.2.1 普通查詢

5.2.2 帶監聽的查詢

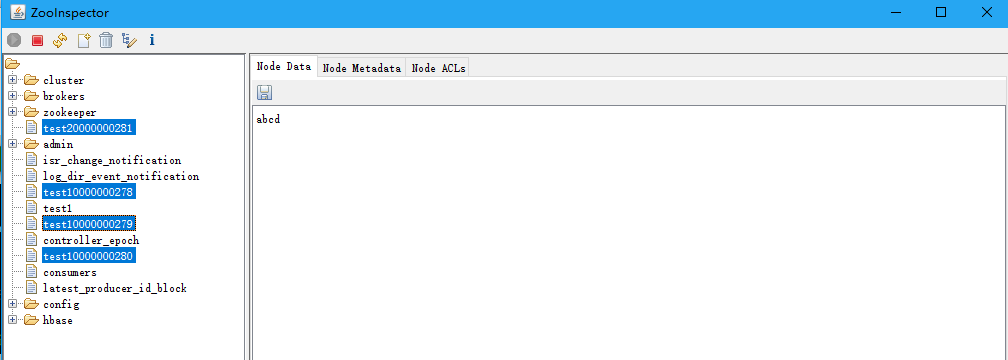
- 另起一個客戶端輸入 create /test1 abcd

- 監聽客戶端變化

5.3 create [-s] [-e] path data acl 建立命令
- 建立命令
- -s 帶序號的節點,把原節點的名字加一個全域性增加的序號拼接在一起。
- -e 臨時節點,未帶此引數的節點全部為永久節點。
- -s -e 同時帶上,建立有序的臨時節點。
5.3.1 普通新增

5.3.2 帶序號的節點新增

5.3.3 臨時節點新增(當前會話退出就消失)

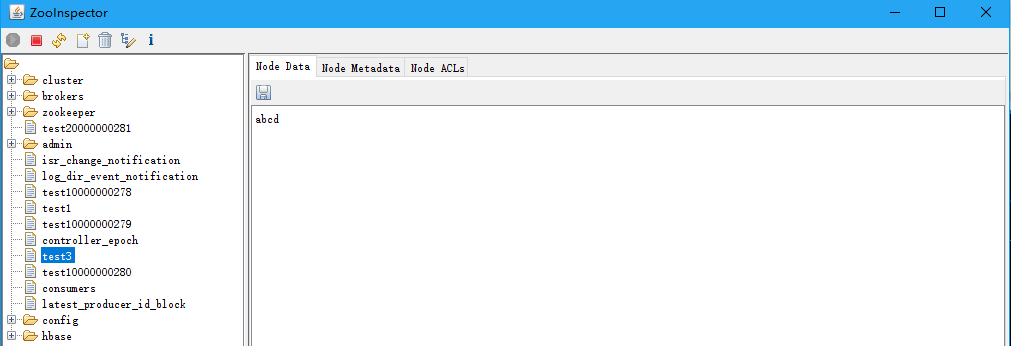
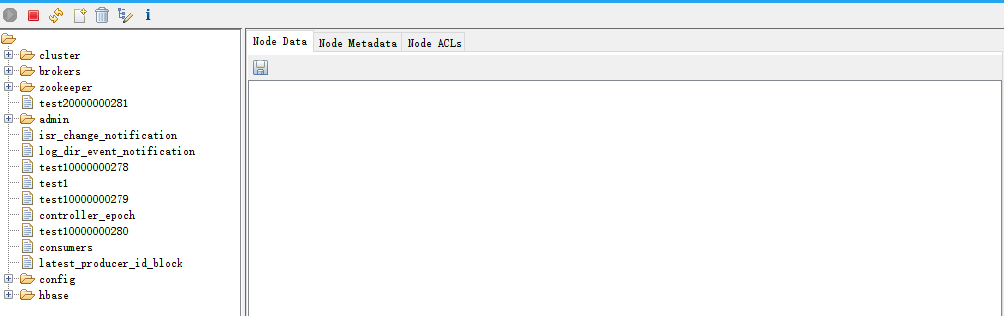
- 執行退出操作,再次查詢消失

- 總結,zk共有4種節點
- PERSISTENT 無序永久節點
- PERSISTENT_SEQUENTIAL 有序永久節點
- EPHEMERAL 無序臨時節點
- EPHEMERAL_SEQUENTIAL 有序臨時節點
5.4 get path [watch] 獲取命令
- 檢視znode內容
- watch為觀察的意思,觀察此路徑下的節點變化
5.4.1 普通獲取

5.4.2 帶監聽的獲取

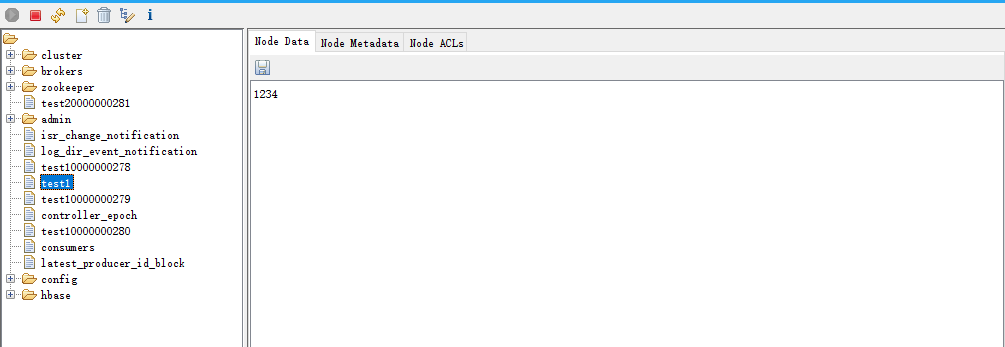
- 另起一個客戶端輸入 set/test1 1234

- 監聽客戶端變化

5.5 stat path [watch] 檢視節點狀態

建立節點的事務zxid cZxid = 0xa00000117
- zk就是靠事務ID保證每批次操作的順序執行。
- ZXID是一個64位的數字,低32代表一個單調遞增的計數器,高32位代表Leader週期
- 高32位:a0000 ----Leader的週期編號+myid的組合
- 低32位:0117 ----事務的自增序列(單調遞增的序列)只要客戶端有請求,就+1
- 每次修改Zookeeper狀態都會受到一個zxid形式的時間戳,也就是zk的事務ID,事務ID是zk中所有修改的總的次序。
- 每個修改都有唯一的zxid,如果zxid1小於zxid2,那麼zxid1發生在zxid2之前。
建立時間 ctime = Wed Feb 19 19:42:34 CST 2020
最後更新的事務zxid mZxid = 0xa00000511
最後更新的時間 mtime = Wed Feb 19 20:48:02 CST 2020
最後更新的子節點zxid pZxid = 0xa00000524
子節點修改次數 cversion = 2
資料被修改的次數 dataVersion = 3
訪問控制列表變化號 aclVersion = 0
如果是臨時節點,這個是znode擁有者sessionID,如果是永久節點則為0 ephemeralOwner = 0x0
資料長度 dataLength = 4
子節點數量 numChildren = 0
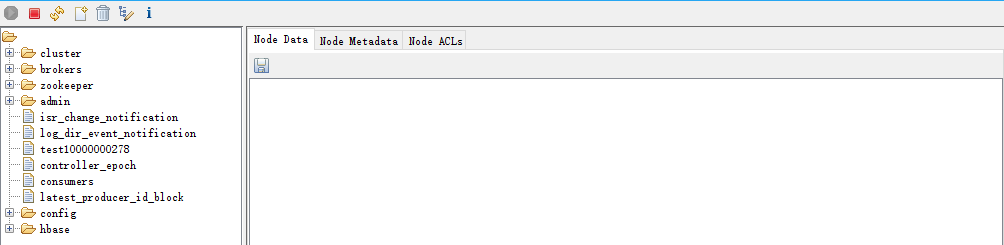
5.6 刪除命令
delete path [version] 普通刪除
rmr path 遞迴刪除


6 zookeeper-java-api應用
- maven pom參考
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.5-cdh6.2.0</version>
</dependency>| 功能 | 描述 | |
|---|---|---|
| create | 在本地目錄樹中建立一個節點 | |
| delete | 刪除一個節點 | |
| exists | 測試本地是否存在目標節點 | |
| get/set data | 從目標節點上讀取 / 寫資料 | |
| get/set ACL | 獲取 / 設定目標節點訪問控制列表資訊 | |
| get children | 檢索一個子節點上的列表 | |
| sync | 等待要被傳送的資料 |
6.1 增刪改查demo
import org.apache.zookeeper.*;
import java.io.IOException;
public class SimpleDemo {
// 會話超時時間
private static final int SESSION_TIMEOUT = 2000;
// 連結叢集地址
private static final String CONNECT_ADDRESS = "192.168.37.10:2181,192.168.37.11:2181,192.168.37.12:2181";
// 建立 ZooKeeper 例項
ZooKeeper zk;
// 建立 Watcher 例項
Watcher wh = event -> System.out.println(event.toString());
// 初始化 ZooKeeper 例項
private void createZKInstance() throws IOException {
zk = new ZooKeeper(CONNECT_ADDRESS, SimpleDemo.SESSION_TIMEOUT, this.wh);
}
private void ZKOperations() throws IOException, InterruptedException, KeeperException {
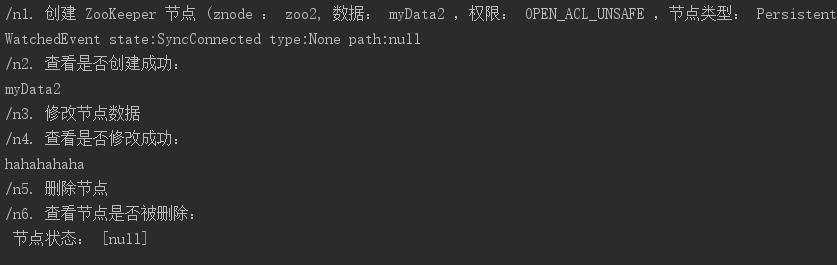
System.out.println("/n1. 建立 ZooKeeper 節點 (znode : zoo2, 資料: myData2 ,許可權: OPEN_ACL_UNSAFE ,節點型別: Persistent");
zk.create("/zoo2", "myData2".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("/n2. 檢視是否建立成功: ");
System.out.println(new String(zk.getData("/zoo2", false, null)));
System.out.println("/n3. 修改節點資料 ");
zk.setData("/zoo2", "hahahahaha".getBytes(), -1);
System.out.println("/n4. 檢視是否修改成功: ");
System.out.println(new String(zk.getData("/zoo2", false, null)));
System.out.println("/n5. 刪除節點 ");
zk.delete("/zoo2", -1);
System.out.println("/n6. 檢視節點是否被刪除: ");
System.out.println(" 節點狀態: [" + zk.exists("/zoo2", false) + "]");
}
private void ZKClose() throws InterruptedException {
zk.close();
}
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
SimpleDemo dm = new SimpleDemo();
dm.createZKInstance();
dm.ZKOperations();
dm.ZKClose();
}
}- 效果:
6.2 伺服器上下線動態感知程式demo
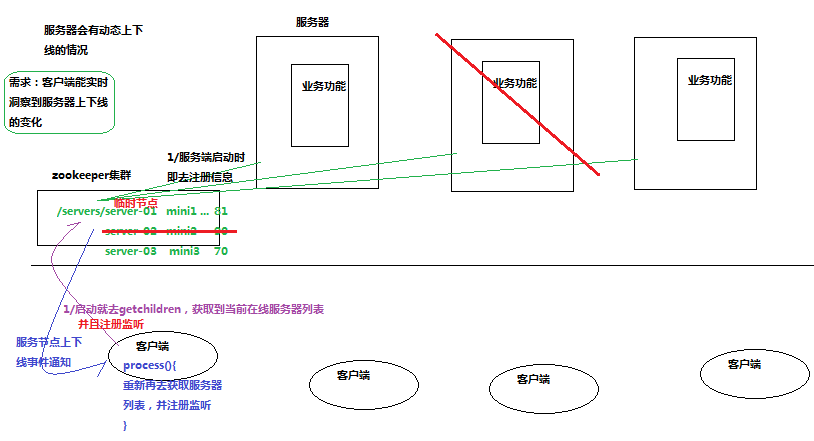
- AppServer.java
import org.apache.zookeeper.*;
public class AppServer {
private String groupNode = "sgroup";
private String subNode = "sub";
/**
* 連線zookeeper
*
* @param address server的地址
*/
public void connectZookeeper(String address) throws Exception {
ZooKeeper zk = new ZooKeeper(
"192.168.147.10:2181,192.168.147.11:2181,192.168.147.12:2181",
5000, new Watcher() {
public void process(WatchedEvent event) {
// 不做處理
}
});
// 在"/sgroup"下建立子節點
// 子節點的型別設定為EPHEMERAL_SEQUENTIAL, 表明這是一個臨時節點, 且在子節點的名稱後面加上一串數字字尾
// 將server的地址資料關聯到新建立的子節點上
String createdPath = zk.create("/" + groupNode + "/" + subNode, address.getBytes("utf-8"),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("create: " + createdPath);
}
/**
* server的工作邏輯寫在這個方法中
* 此處不做任何處理, 只讓server sleep
*/
public void handle() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 在引數中指定server的地址
if (args.length == 0) {
System.err.println("The first argument must be server address");
System.exit(1);
}
AppServer as = new AppServer();
as.connectZookeeper(args[0]);
as.handle();
}
}- AppClient.java
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.util.ArrayList;
import java.util.List;
public class AppClient {
private String groupNode = "sgroup";
private ZooKeeper zk;
private Stat stat = new Stat();
private volatile List<String> serverList;
/**
* 連線zookeeper
*/
public void connectZookeeper() throws Exception {
zk = new ZooKeeper("192.168.147.10:2181,192.168.147.11:2181,192.168.147.12:2181", 5000, new Watcher() {
public void process(WatchedEvent event) {
// 如果發生了"/sgroup"節點下的子節點變化事件, 更新server列表, 並重新註冊監聽
if (event.getType() == Event.EventType.NodeChildrenChanged
&& ("/" + groupNode).equals(event.getPath())) {
try {
updateServerList();
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
updateServerList();
}
/**
* 更新server列表
*/
private void updateServerList() throws Exception {
List<String> newServerList = new ArrayList<String>();
// 獲取並監聽groupNode的子節點變化
// watch引數為true, 表示監聽子節點變化事件.
// 每次都需要重新註冊監聽, 因為一次註冊, 只能監聽一次事件, 如果還想繼續保持監聽, 必須重新註冊
List<String> subList = zk.getChildren("/" + groupNode, true);
for (String subNode : subList) {
// 獲取每個子節點下關聯的server地址
byte[] data = zk.getData("/" + groupNode + "/" + subNode, false, stat);
newServerList.add(new String(data, "utf-8"));
}
// 替換server列表
serverList = newServerList;
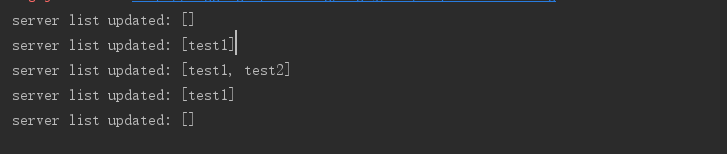
System.out.println("server list updated: " + serverList);
}
/**
* client的工作邏輯寫在這個方法中
* 此處不做任何處理, 只讓client sleep
*/
public void handle() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
AppClient ac = new AppClient();
ac.connectZookeeper();
ac.handle();
}
}- 開啟client

加入節點名稱引數開啟server


- client端變化

- 再次加入節點名稱引數開啟server

- client端變化

- 關閉其中一個服務client端變化

關閉另一個服務client端變化
6.3 分散式共享鎖demo

- DistributedClient.java
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class DistributedClient {
// 超時時間
private static final int SESSION_TIMEOUT = 5000;
// zookeeper server列表
private String hosts = "192.168.147.10:2181,192.168.147.11:2181,192.168.147.12:2181";
private String groupNode = "locks";
private String subNode = "sub";
private ZooKeeper zk;
// 當前client建立的子節點
private String thisPath;
// 當前client等待的子節點
private String waitPath;
private CountDownLatch latch = new CountDownLatch(1);
/**
* 連線zookeeper
*/
public void connectZookeeper() throws Exception {
zk = new ZooKeeper(hosts, SESSION_TIMEOUT, new Watcher() {
public void process(WatchedEvent event) {
try {
// 連線建立時, 開啟latch, 喚醒wait在該latch上的執行緒
if (event.getState() == Event.KeeperState.SyncConnected) {
latch.countDown();
}
// 發生了waitPath的刪除事件
if (event.getType() == Event.EventType.NodeDeleted && event.getPath().equals(waitPath)) {
doSomething();
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
// 等待連線建立
latch.await();
// 建立子節點
thisPath = zk.create("/" + groupNode + "/" + subNode, null, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// wait一小會, 讓結果更清晰一些
Thread.sleep(10);
// 注意, 沒有必要監聽"/locks"的子節點的變化情況
List<String> childrenNodes = zk.getChildren("/" + groupNode, false);
// 列表中只有一個子節點, 那肯定就是thisPath, 說明client獲得鎖
if (childrenNodes.size() == 1) {
doSomething();
} else {
String thisNode = thisPath.substring(("/" + groupNode + "/").length());
// 排序
Collections.sort(childrenNodes);
int index = childrenNodes.indexOf(thisNode);
if (index == -1) {
// never happened
} else if (index == 0) {
// inddx == 0, 說明thisNode在列表中最小, 當前client獲得鎖
doSomething();
} else {
// 獲得排名比thisPath前1位的節點
this.waitPath = "/" + groupNode + "/" + childrenNodes.get(index - 1);
// 在waitPath上註冊監聽器, 當waitPath被刪除時, zookeeper會回撥監聽器的process方法
zk.getData(waitPath, true, new Stat());
}
}
}
private void doSomething() throws Exception {
try {
System.out.println("gain lock: " + thisPath);
Thread.sleep(2000);
// do something
} finally {
System.out.println("finished: " + thisPath);
// 將thisPath刪除, 監聽thisPath的client將獲得通知
// 相當於釋放鎖
zk.delete(this.thisPath, -1);
}
}
public static void main(String[] args) throws Exception {
for (int i = 0; i < 10; i++) {
new Thread() {
public void run() {
try {
DistributedClient dl = new DistributedClient();
dl.connectZookeeper();
} catch (Exception e) {
e.printStackTrace();
}
}
}.start();
}
Thread.sleep(Long.MAX_VALUE);
}
}- 測試:

7 Paxos演算法(帕索斯演算法)
參考:
https://www.cnblogs.com/xuwc/p/9029882.html
https://blog.csdn.net/cnh294141800/article/details/53768464
http://www.cnblogs.com/shangxiaofei/p/5207218.html
- 維基的簡介:Paxos演算法是萊斯利·蘭伯特(Leslie Lamport,就是 LaTeX 中的"La",此人現在在微軟研究院)於1990年提出的一種基於訊息傳遞且具有高度容錯特性的一致性演算法。
- 在節點很多的情況下,如果要收斂,也就是確定一個一致的值,需要不停的迴圈,那麼必然會造成速度慢。
7.1 生活中的例子
假如有一群驢友要決定中秋節去旅遊,這群驢友分佈在全國各地,假定一共25個 人,分別在不同的省,要決定到底去拉薩、昆明、三亞等等哪個地點(會合時間中秋節已經定了,此時需要決定旅遊地)。最直接的方式當然就是建一個QQ群,大家都在裡面投票,按照少數服從多數的原則。這種方式類似於“共享記憶體”實現的一致性,實現起來簡單,但Paxos演算法不是這種場景,因為Paxos演算法認為這種方式有一個很大的問題,就是QQ伺服器掛掉怎麼辦?Paxos的原則是容錯性一定要很強。所以,Paxos的場景類似於這25個人相互之間只能發簡訊,需要解決的核心問題是,哪怕任意的一部分人(Paxos的目的其實是少於半數的人)“失聯”了,其它人也能夠在會合地點上達成一致。好了,怎麼設計呢?
這25個人找了另外的5個人(當然這5個人可以從25個人中選,這裡為了描述方便,就單拿出另外5個人),比如北京、上海、廣州、深圳、成都的5個人,25個人都給他們發簡訊,告訴自己傾向的旅遊地。這5個人相互之間可以並不通訊, 只接受25個人發過來的簡訊。這25個人我們稱為驢友,那5個人稱為隊長。
先來看驢友的邏輯。驢友可以給任意5個隊長都發簡訊,發簡訊的過程分為兩個步驟:
第一步(申請階段):詢問5個隊長,試圖與隊長溝通旅遊地。因為每個隊長一直會收到不同驢友的簡訊,不能跟多個驢友一起溝通,在任何時刻只能跟一個驢友溝通,按照什麼原則才能做到公平公正公開呢?這些簡訊都帶有傳送時間,隊長採用的原則是同意與簡訊傳送時間最新的驢友溝通,如果出現了更新的簡訊,則與簡訊更新的驢友溝通。總之,作為一個有話語權的人,只有時刻保持傾聽最新的呼聲,才能做出最明智的選擇。在驢友發出簡訊後,等著隊長。某些隊長可能會說,你這條簡訊太老了,我不與你溝通;有些隊長則可能返回說,你的簡訊是我收到的最新的,我同意跟你溝通。對於後面這些隊長,還得返回自己決定的旅遊地。關於隊長是 怎麼決定旅遊地的,後面再說。
對於驢友來說,第一步必須至少有半數以上隊長都同意溝通了,才能進入下一步。否則,你連溝通的資格都沒有,一直在那兒狂發吧。你發的簡訊更新,你獲得溝通權的可能性才更大。。。。。。
因為至少有半數以上隊長(也就是3個隊長以上)同意,你才能與隊長們進行實質性的溝通,也就是進入第二步;而隊長在任何時候只能跟1個驢友溝通,所以,在任何時候,不可能出現兩個驢友都達到了這個狀態。。。當然,你可以通過狂發簡訊把溝通權搶了。。。。
對於獲得溝通權的那個驢友(稱為A),那些隊長會給他傳送他們自己決定的旅遊地(也可能都還沒有決定)。可以看出,各個隊長是自己決定旅遊地的,隊長之間無需溝通。
第二步(溝通階段):這個幸運的驢友收到了隊長們給他發的旅遊地,可能有幾種情況:
第一種情況:跟A溝通的隊長們(不一定是全部5個隊長,但是半數以上)全部都還沒有決定到底去那兒旅遊,此時驢友A心花怒放,給這些隊長髮第二條簡訊,告訴他們自己希望的旅遊地(比如馬爾地夫);
可能會收到兩種結果:一是半數以上隊長都同意了,於是表明A建議的馬爾地夫被半數以上隊長都 同意了,整個決定過程完畢了,其它驢友遲早會知道這個訊息的,A先去收拾東西準備去馬爾地夫;除此之外,表明失敗。可能隊長出故障了,比如某個隊長在跟女 朋友打電話等等,也可能被其它驢友搶佔溝通權了(因為隊長喜新厭舊嘛,只有要更新的驢友給自己發簡訊,自己就與新人溝通,A的建議隊長不同意)等等。不管 怎麼說,苦逼的A還得重新從第一步開始,重新給隊長們發簡訊申請。
第二種情況:至少有一個隊長已經決定旅遊地了,A可能會收到來自不同隊長決定的多 個旅遊地,這些旅遊地是不同隊長跟不同驢友在不同時間上做出的決定,那麼,A會先看一下,是不是有的旅遊地已經被半數以上隊長同意了(比如3個隊長都同意 去三亞,1個同意去昆明,另外一個沒搭理A),如果出現了這種情況,那就別扯了,說明整個決定過程已經達成一致了,收拾收拾準備去三亞吧,結束了;如果都 沒有達到半數以上(比如1個同意去昆明,1個同意去三亞,2個同意去拉薩,1個沒搭理我),A作為一個高素質驢友,也不按照自己的意願亂來了(Paxos 的關鍵所在,後者認同前者,否則整個決定過程永無止境),雖然自己原來可能想去馬爾地夫等等。就給隊長們發第二條簡訊的時候,告訴他們自己希望的旅遊地, 就是自己收到的那堆旅遊地中最新決定的那個。(比如,去昆明那個是北京那個隊長前1分鐘決定的,去三亞的決定是上海那個隊長1個小時之前做出來的,於是頂 昆明)。驢友A的想法是,既然有隊長已經做決定了,那我就乾脆頂最新那個決定。
從上面的邏輯可以看出,一旦某個時刻有半數以上隊長同意了某個地點比如昆明,緊跟著後面的驢友B繼續發簡訊時,如果獲得溝通權,因為半數以上隊長都同意與B溝通了,說明B收到了來自半數以上隊長髮過來的訊息,B必然會收到至少一個隊長給他發的昆明這個結果(否則說明半數以上隊長都沒有同意昆明這個結果,這顯然與前面的假設矛盾),B於是會頂這個最新地點,不會更改,因為後面的驢友都會頂昆明,因此同意昆明的隊長越來越多,最終必然達成一致。
看完了驢友的邏輯,那麼隊長的邏輯是什麼呢?
隊長的邏輯比較簡單。
在申請階段,隊長只會選擇與最新發申請簡訊的驢友溝通,隊長知道自己接收到最新簡訊的時間,對於更老的簡訊,隊長不會搭理;隊長同意溝通了的話,會把自己決定的旅遊地(或者還沒決定這一資訊)發給驢友。
在溝通階段,驢友C會把自己希望的旅遊地發過來(同時會附加上自己申請簡訊的時 間,比如3分鐘前),所以隊長要檢查一下,如果這個時間(3分鐘前)確實是當前自己最新接收到申請簡訊的時間(說明這段時間沒有驢友要跟自己溝通),那 麼,隊長就同意驢友C的這個旅遊地了(比如昆明,哪怕自己1個小時前已經做過去三亞的決定,誰讓C更新呢,於是更新為昆明);如果不是最新的,說明這3分 鍾內又有其它驢友D跟自己申請了,因為自己是個喜新厭舊的傢伙,同意與D溝通了,所以驢友C的決定自己不會同意,等著D一會兒要發過來的決定吧。
Paxos的基本思想大致就是上面的過程。可以看出,其實驢友的策略才是Paxos的關鍵。讓我們來跟理論對應一下。
Paxos主要用於保證分散式儲存中副本(或者狀態)的一致性。副本要保持一致, 那麼,所有副本的更新序列就要保持一致。因為資料的增刪改查操作一般都存在多個客戶端併發操作,到底哪個客戶端先做,哪個客戶端後做,這就是更新順序。如 果不是分散式,那麼可以利用加鎖的方法,誰先申請到鎖,誰就先操作。但是在分散式條件下,存在多個副本,如果依賴申請鎖+副本同步更新完畢再釋放鎖,那麼 需要有分配鎖的這麼一個節點(如果是多個鎖分配節點,那麼又出現分散式鎖管理的需求,把鎖給哪一個客戶端又成為一個難點),這個節點又成為單點,豈不是可 靠性不行了,失去了分散式多副本的意義,同時效能也很差,另外,還會出現死鎖等情況。
所以,說來說去,只有解決分散式條件下的一致性問題,似乎才能解決本質問題。
如上面的例子,Paxos解決這一問題利用的是選舉,少數服從多數的思想,只要 2N+1個節點中,有N個以上同意了某個決定,則認為系統達到了一致,並且按照Paxos原則,最終理論上也達到了一致,不會再改變。這樣的話,客戶端不 必與所有伺服器通訊,選擇與大部分通訊即可;也無需伺服器都全部處於工作狀態,有一些伺服器掛掉,只有保證半數以上存活著,整個過程也能持續下去,容錯性 相當好。因此,以前看有的部落格說在部署ZooKeeper這種服務的時候,需要奇數臺機器,這種說法當然有一定來源背景,比如如果是5臺,那麼任意客戶端 與任意其中3臺達成一致就相當於投票結束,不過6臺有何不可?只是此時需要與4臺以上達成一致。
Paxos中的Acceptor就相當於上面的隊長,Proposer就相當於上 面的驢友,epoch編號就相當於例子中申請簡訊的傳送時間。關於Paxos的正式描述已經很多了,這裡就不復述了,關於Paxos正確性的證明,因為比 較複雜,以後有時間再分析。另外,Paxos最消耗時間的地方就在於需要半數以上同意溝通了才能進入第二步,試想一下,一開始,所有驢友就給隊長狂發短 信,每個隊長收到的最新簡訊的是不同驢友,這樣,就難以達到半數以上都同意與某個驢友溝通的狀態,為了減小這個時間,Paxos還有Fast Paxos的改進等等,有空再分析。
倒是有一些問題可以思考一下:在Paxos之前,或者說除了Chubby,ZooKeeper這些系統,其它分散式系統同樣面臨這樣的一致性問題,比如HDFS、分散式資料庫、Amazon的Dynamo等等,解決思路又不同,有空再進行對比分析。
最後談談一致性這個名詞。
關於Paxos說的一致性,個人理解是指冗餘副本(或狀態等,但都是因為存在冗餘)的一致性。這與關係型資料庫中ACID的一致性說的不是一個東西。在關係資料庫裡,可以連副本都沒有,何談副本的一致性?按照經典定義,ACID中的C指的是在一個事務中,事務執行的結果必須是使資料庫從一個一致性狀態變到另一個一致性狀態。那麼,什麼又是一致性狀態呢,這跟業務約束有關係,比如經典的轉賬事務,事務處理完畢後,不能出現一個賬戶錢被扣了,另一個賬戶的錢沒有增加的情況,如果兩者加起來的錢還是等於轉賬前的錢,那麼就是一致性狀態。
從很多博文來看,對這兩種一致性往往混淆起來。另外,CAP原則裡面所說的一致 性,個人認為是指副本一致性,與Paxos裡面的一致性接近。都是處理“因為冗餘資料的存在而需要保證多個副本保持一致”的問題,NoSQL放棄的強一致 性也是指副本一致性,最終一致性也是指副本達到完全相同存在一定延時。
當然,如果資料庫本身是分散式的,且存在冗餘副本,則除了解決事務在業務邏輯上的一致性問題外,同時需要解決副本一致性問題,此時可以利用Paxos協議。但解決了副本一致性問題,還不能完全解決業務邏輯一致性;如果是分散式資料庫,但並不存在副本的情況,事務的一致性需要根據業務約束進行設計。
另外,談到Paxos時,還會涉及到拜占庭將軍問題,它指的是在存在訊息丟失的不 可靠通道上試圖通過訊息傳遞的方式達到一致性是不可能的。Paxos本身就是利用訊息傳遞方式解決一致性問題的,所以它的假定是通道必須可靠,這裡的可 靠,主要指訊息不會被篡改。訊息丟失是允許的。
關於一致性、事務的ACID,CAP,NoSQL等等問題,以後再詳細分析。本文的描述也許可能存在一些舉例不太恰當的地方,如果錯誤,歡迎批評指正。
7.2 Paxos協議解釋
Paxos演算法的目的
Paxos演算法的目的是為了解決分散式環境下一致性的問題。
多個節點併發操縱資料,如何保證在讀寫過程中資料的一致性,並且解決方案要能適應分散式環境下的不可靠性(系統如何就一個值達到統一)
Paxos的兩個元件
- Proposer:提議發起者,處理客戶端請求,將客戶端的請求傳送到叢集中,以便決定這個值是否可以被批准。
- Acceptor:提議批准者,負責處理接收到的提議,他們的回覆就是一次投票。會儲存一些狀態來決定是否接收一個值
- Paxos有兩個原則
- 安全原則---保證不能做錯的事:
- 針對某個例項的表決只能有一個值被批准,不能出現一個被批准的值被另一個值覆蓋的情況;(假設有一個值被多數Acceptor批准了,那麼這個值就只能被學習)
- 每個節點只能學習到已經被批准的值,不能學習沒有被批准的值。
- 存活原則---只要有多數伺服器存活並且彼此間可以通訊,最終都要做到的下列事情:
- 最終會批准某個被提議的值;
- 一個值被批准了,其他伺服器最終會學習到這個值。
- 安全原則---保證不能做錯的事:
7.3 Paxos流程圖

1).獲取一個proposal number, n;
2).提議者向所有節點廣播prepare(n)請求;
3).接收者(Acceptors比較善變,如果還沒最終認可一個值,它就會不斷認同提案號最大的那個方案)比較n和minProposal,如果n>minProposal,表示有更新的提議minProposal=n;如果此時該接受者並沒有認可一個最終值,那麼認可這個提案,返回OK。如果此時已經有一個accptedValue, 將返回(acceptedProposal,acceptedValue);
4).提議者接收到過半數請求後,如果發現有acceptedValue返回,表示有認可的提議,儲存最高acceptedProposal編號的acceptedValue到本地;
5).廣播accept(n,value)到所有節點;
6).接收者比較n和minProposal,如果n>=minProposal,則acceptedProposal=minProposal=n,acceptedValue=value,本地持久化後,返回;否則,拒絕並且返回minProposal;
7).提議者接收到過半數請求後,如果發現有返回值>n,表示有更新的提議,跳轉1(重新發起提議);否則value達成一致。
7.4 Paxos議案ID生成演算法
在Google的Chubby論文中給出了這樣一種方法:假設有n個proposer,每個編號為ir(0<=ir<n),proposal編號的任何值s都應該大於它已知的最大值,並且滿足: s % n = ir => s = m * n + ir;
proposer已知的最大值來自兩部分:proposer自己對編號自增後的值和接收到acceptor的拒絕後所得到的值。
例: 以3個proposer P1、P2、P3為例,開始m=0,編號分別為0,1,2。
1) P1提交的時候發現了P2已經提交,P2編號為1 >P1的0,因此P1重新計算編號:new P1 = 1 * 3 + 1 = 4;
2) P3以編號2提交,發現小於P1的4,因此P3重新編號:new P3 = 1 * 3+2 = 5。
7.5 Paxos原理
任意兩個法定集合,必定存在一個公共的成員。該性質是Paxos有效的基本保障
- 活鎖
- 當某一proposer提交的proposal被拒絕時,可能是因為acceptor 承諾返回了更大編號的proposal,因此proposer提高編號繼續提交。 如果2個proposer都發現自己的編號過低轉而提出更高編號的proposal,會導致死迴圈,這種情況也稱為活鎖。
- 比如說當此時的 proposer1提案是3, proposer2提案是4, 但acceptor承諾的編號是5,那麼此時proposer1,proposer2 都將提高編號假設分別為6,7,並試圖與accceptor連線,假設7被接受了,那麼提案5和提案6就要重新編號提交,從而不斷死迴圈。
- 異常情況——持久儲存
- 在演算法執行的過程中會產生很多的異常情況:proposer宕機,acceptor在接收proposal後宕機,proposer接收訊息後宕機,acceptor在accept後宕機,learn宕機,儲存失敗,等等。
- 為保證paxos演算法的正確性,proposer、aceptor、learn都實現持久儲存,以做到server恢復後仍能正確參與paxos處理。
- propose儲存已提交的最大proposal編號、決議編號(instance id)。
- acceptor儲存已承諾(promise)的最大編號、已接受(accept)的最大編號和value、決議編號。
- learn儲存已學習過的決議和編號
具體例項:(假設的3軍問題)
1) 1支紅軍在山谷裡紮營,在周圍的山坡上駐紮著3支藍軍;
2) 紅軍比任意1支藍軍都要強大;如果1支藍軍單獨作戰,紅軍勝;如果2支或以上藍軍同時進攻,藍軍勝;
3) 三支藍軍需要同步他們的進攻時間;但他們惟一的通訊媒介是派通訊兵步行進入山谷,在那裡他們可能被俘虜,從而將資訊丟失;或者為了避免被俘虜,可能在山谷停留很長時間;
4) 每支軍隊有1個參謀負責提議進攻時間;每支軍隊也有1個將軍批准參謀提出的進攻時間;很明顯,1個參謀提出的進攻時間需要獲得至少2個將軍的批准才有意義;
5) 問題:是否存在一個協議,能夠使得藍軍同步他們的進攻時間?
接下來以兩個假設的場景來演繹BasicPaxos;參謀和將軍需要遵循一些基本的規則
1) 參謀以兩階段提交(prepare/commit)的方式來發起提議,在prepare階段需要給出一個編號;
2) 在prepare階段產生衝突,將軍以編號大小來裁決,編號大的參謀勝出;
3) 參謀在prepare階段如果收到了將軍返回的已接受進攻時間,在commit階段必須使用這個返回的進攻時間;
7.5.1 先後提議的場景
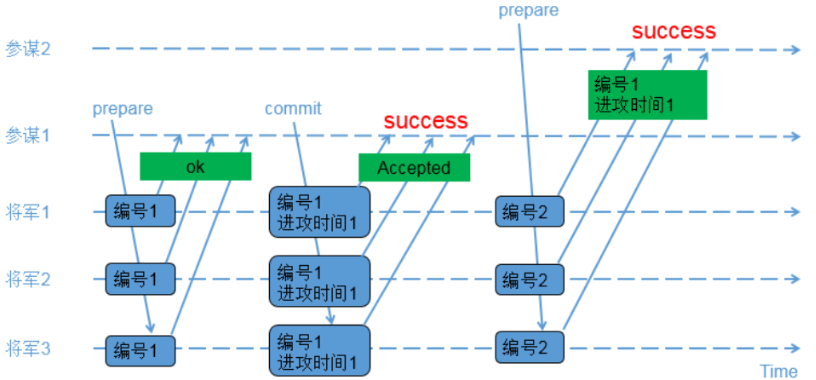
參與角色:
proposer(提議者):參謀1,參謀2
acceptor(決策者):將軍1,將軍2,將軍3
1)參謀1發起提議,派通訊兵帶信給3個將軍,內容為(編號1);
2)3個將軍收到參謀1的提議,由於之前還沒有儲存任何編號,因此把(編號1)儲存下來,避免遺忘;同時讓通訊兵帶信回去,內容為(ok);
3)參謀1收到至少2個將軍的回覆,再次派通訊兵帶信給3個將軍,內容為(編號1,進攻時間1);
4)3個將軍收到參謀1的時間,把(編號1,進攻時間1)儲存下來,避免遺忘;同時讓通訊兵帶信回去,內容為(Accepted);
5)參謀1收到至少2個將軍的(Accepted)內容,確認進攻時間已經被大家接收;
6)參謀2發起提議,派通訊兵帶信給3個將軍,內容為(編號2);
7)3個將軍收到參謀2的提議,由於(編號2)比(編號1)大,因此把(編號2)儲存下來,避免遺忘;又由於之前已經接受參謀1的提議,因此讓通訊兵帶信回去,內容為(編 號1,進攻時間1);
8)參謀2收到至少2個將軍的回覆,由於回覆中帶來了已接受的參謀1的提議內容,參謀2因此不再提出新的進攻時間,接受參謀1提出的時間;
7.5.2 交叉場景
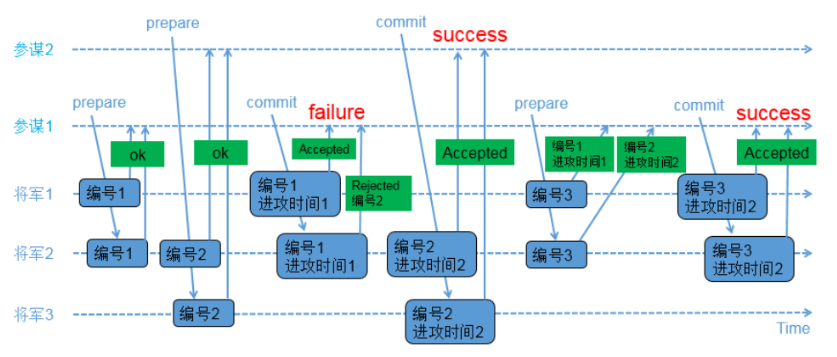
參與角色:
proposer(提議者):參謀1,參謀2
acceptor(決策者):將軍1,將軍2,將軍3
1)參謀1發起提議,派通訊兵帶信給3個將軍,內容為(編號1);
2)3個將軍的情況如下
a)將軍1和將軍2收到參謀1的提議,將軍1和將軍2把(編號1)記錄下來,如果有其他參謀提出更小的編號,將被拒絕;同時讓通訊兵帶信回去,內容為(ok);
b)負責通知將軍3的通訊兵被抓,因此將軍3沒收到參謀1的提議;3)參謀2在同一時間也發起了提議,派通訊兵帶信給3個將軍,內容為(編號2);
4)3個將軍的情況如下
a)將軍2和將軍3收到參謀2的提議,將軍2和將軍3把(編號2)記錄下來,如果有其他參謀提出更小的編號,將被拒絕;同時讓通訊兵帶信回去,內容為(ok);
b)負責通知將軍1的通訊兵被抓,因此將軍1沒收到參謀2的提議;
5)參謀1收到至少2個將軍的回覆,再次派通訊兵帶信給有答覆的2個將軍,內容為(編號1,進攻時間1);
6)2個將軍的情況如下
a)將軍1收到了(編號1,進攻時間1),和自己儲存的編號相同,因此把(編號1,進攻時間1)儲存下來;同時讓通訊兵帶信回去,內容為(Accepted);
b)將軍2收到了(編號1,進攻時間1),由於(編號1)小於已經儲存的(編號2),因此讓通訊兵帶信回去,內容為(Rejected,編號2);
7)參謀2收到至少2個將軍的回覆,再次派通訊兵帶信給有答覆的2個將軍,內容為(編號2,進攻時間2);
8)將軍2和將軍3收到了(編號2,進攻時間2),和自己儲存的編號相同,因此把(編號2,進攻時間2)儲存下來,同時讓通訊兵帶信回去,內容為(Accepted);
9)參謀2收到至少2個將軍的(Accepted)內容,確認進攻時間已經被多數派接受;10)參謀1只收到了1個將軍的(Accepted)內容,同時收到一個(Rejected,編號2);參謀1重新發起提議,派通訊兵帶信給3個將軍,內容為(編號3);
11)3個將軍的情況如下
a)將軍1收到參謀1的提議,由於(編號3)大於之前儲存的(編號1),因此把(編號3)儲存下來;由於將軍1已經接受參謀1前一次的提議,因此讓通訊兵帶信回去,內容為(編號1,進攻時間1);
b)將軍2收到參謀1的提議,由於(編號3)大於之前儲存的(編號2),因此把(編號3)儲存下來;由於將軍2已經接受參謀2的提議,因此讓通訊兵帶信回去,內容為(編號2,進攻時間2);
c)負責通知將軍3的通訊兵被抓,因此將軍3沒收到參謀1的提議;12)參謀1收到了至少2個將軍的回覆,比較兩個回覆的編號大小,選擇大編號對應的進攻時間作為最新的提議;參謀1再次派通訊兵帶信給有答覆的2個將軍,內容為(編號3,進攻時間2);
13)將軍1和將軍2收到了(編號3,進攻時間2),和自己儲存的編號相同,因此儲存(編號3,進攻時間2),同時讓通訊兵帶信回去,內容為(Accepted);
14)參謀1收到了至少2個將軍的(accepted)內容,確認進攻時間已經被多數派接受。
7.6 paxos演算法
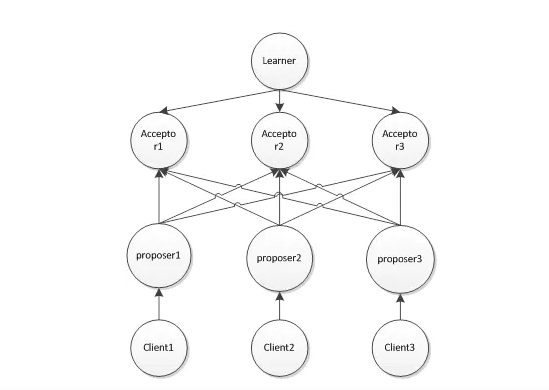
- 在paxos演算法中,分為4種角色:
- Proposer :提議者
- Acceptor:決策者
- Client:產生議題者
- Learner:最終決策學習者
上面4種角色中,提議者和決策者是很重要的,其他的2個角色在整個演算法中應該算做 打醬油的,Proposer就像Client的使者,由Proposer使者拿著Client的議題去向Acceptor提議,讓Acceptor來決 策。這裡上面出現了個新名詞:最終決策。現在來系統的介紹一下paxos演算法中所有的行為:
Proposer提出議題
Acceptor初步接受 或者 Acceptor初步不接受
如果上一步Acceptor初步接受則Proposer再次向Acceptor確認是否最終接受
Acceptor 最終接受 或者Acceptor 最終不接受
上面Learner最終學習的目標是Acceptor們最終接受了什麼議題?注意,這裡是向所有Acceptor學習,如果有多數派個Acceptor最終接受了某提議,那就得到了最終的結果,演算法的目的就達到了。畫一幅圖來更加直觀:
例子paxos的演算法的流程(2階段提交)
有2個Client(老闆,老闆之間是競爭關係)和3個Acceptor(政府官員):
現在需要對一項議題來進行paxos過程,議題是“A專案我要中標!”,這裡的“我”指每個帶著他的祕書Proposer的Client老闆。
Proposer當然聽老闆的話了,趕緊帶著議題和現金去找Acceptor政府官員。
作為政府官員,當然想誰給的錢多就把專案給誰。Proposer-1小姐帶著現金同時找 到了Acceptor-1~Acceptor-3官員,1與2號官員分別收取了10比特幣,找到第3號官員時,沒想到遭到了3號官員的鄙視,3號官員告訴 她,Proposer-2給了11比特幣。不過沒關係,Proposer-1已經得到了1,2兩個官員的認可,形成了多數派(如果沒有形成多數 派,Proposer-1會去銀行提款在來找官員們給每人20比特幣,這個過程一直重複每次+10比特幣,直到多數派的形成),滿意的找老闆覆命去了,但 是此時Proposer-2保鏢找到了1,2號官員,分別給了他們11比特幣,1,2號官員的態度立刻轉變,都說Proposer-2的老闆懂事,這下子 Proposer-2放心了,搞定了3個官員,找老闆覆命去了,當然這個過程是第一階段提交,只是官員們初步接受賄賂而已。故事中的比特幣是編號,議題是 value。
這個過程保證了在某一時刻,某一個proposer的議題會形成一個多數派進行初步支援;華麗的,第一階段結束
現在進入第二階段提交,現在proposer-1小姐使用分身術(多線 程併發)分了3個自己分別去找3位官員,最先找到了1號官員籤合同,遭到了1號官員的鄙視,1號官員告訴他proposer-2先生給了他11比特幣,因 為上一條規則的性質proposer-1小姐知道proposer-2第一階段在她之後又形成了多數派(至少有2位官員的贓款被更新了);此時她趕緊去提 款準備重新賄賂這3個官員(重新進入第一階段),每人20比特幣。剛給1號官員20比特幣, 1號官員很高興初步接受了議題,還沒來得及見到2,3號官員的時候
這時proposer-2先生也使用分身術分別找3位官員(注意這裡是 proposer-2的第二階段),被第1號官員拒絕了告訴他收到了20比特幣,第2,3號官員順利簽了合同,這時2,3號官員記錄client-2老闆 用了11比特幣中標,因為形成了多數派,所以最終接受了Client2老闆中標這個議題,對於proposer-2先生已經出色的完成了工作;
這時proposer-1小姐找到了2號官員,官員告訴她合同已經簽了,將合同給 她看,proposer-1小姐是一個沒有什麼職業操守的聰明人,覺得跟Client1老闆混沒什麼前途,所以將自己的議題修改為“Client2老闆中 標”,並且給了2號官員20比特幣,這樣形成了一個多數派。順利的再次進入第二階段。由於此時沒有人競爭了,順利的找3位官員籤合同,3位官員看到議題與 上次一次的合同是一致的,所以最終接受了,形成了多數派,proposer-1小姐跳槽到Client2老闆的公司去了。
華麗的,第二階段結束
Paxos過程結束了,這樣,一致性得到了保證,演算法執行到最後所有的 proposer都投“client2中標”所有的acceptor都接受這個議題,也就是說在最初的第二階段,議題是先入為主的,誰先佔了先機,後面的 proposer在第一階段就會學習到這個議題而修改自己本身的議題,因為這樣沒職業操守,才能讓一致性得到保證,這就是paxos演算法的一個過程。原來 paxos演算法裡的角色都是這樣的不靠譜,不過沒關係,結果靠譜就可以了。該演算法就是為了追求結果的一致性。
8 ZAB協議
ZooKeeper並沒有直接採用Paxos演算法,因為Paxos演算法在節點很多的情況下,如果要收斂,也就是確定一個一致的值,需要不停的迴圈,那麼必然會造成速度慢。所以zk參考Paxos提供了一種被稱為ZAB(ZooKeeper Atomic Broadcast)的一致性協議。
ZAB協議主要用於構建一個高可用的分散式資料主備系統--AP
Paxos演算法則是用於構建一個分散式的一致性狀態機系統--CP
CAP原則又稱CAP定理,指的是在一個分散式系統中,一致性(Consistency)、可用性(Availability)、分割槽容錯性(Partition tolerance)。CAP 原則指的是,這三個要素最多隻能同時實現兩點,不可能三者兼顧。
CAP原則的精髓就是要麼AP,要麼CP,要麼AC,但是不存在CAP。如果在某個分散式系統中資料無副本, 那麼系統必然滿足強一致性條件, 因為只有獨一資料,不會出現資料不一致的情況,此時C和P兩要素具備,但是如果系統發生了網路分割槽狀況或者宕機,必然導致某些資料不可以訪問,此時可用性條件就不能被滿足,即在此情況下獲得了CP系統,但是CAP不可同時滿足。
8.1 zookeeper中節點分四種狀態
- looking:選舉Leader的狀態(叢集剛啟動時或崩潰恢復狀態下,也就是需要選舉的時候)
- following:跟隨者(follower)的狀態,服從Leader命令
- leading:當前節點是Leader,負責協調工作。
- observing:observer(觀察者),不參與選舉,只讀節點。
8.2 zookeeper選舉過程
- 舉例場景:leader掛了,需要選舉新的leader

- 階段一:崩潰恢復
a.每個server都有一張選票<myid,zxid>,如(3,9),選票投自己。
b.每個server投完自己後,再分別投給其他還可用的伺服器。如把Server3的(3,9)分別投給Server4和Server5,依次類推
c.比較投票,比較邏輯:優先比較Zxid,Zxid相同時才比較myid。比較Zxid時,大的做leader;比較myid時,小的做leader
d.改變伺服器狀態(崩潰恢復->資料同步,或者崩潰恢復->訊息廣播)
- 階段二:訊息廣播
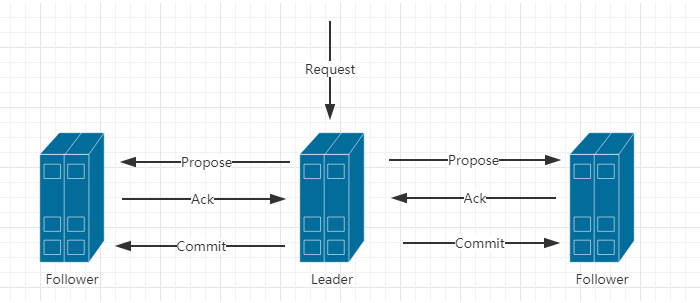
a.Leader接受請求後,將這個請求賦予全域性的唯一64位自增Id(zxid)。
b.將zxid作為議案發給所有follower。
c.所有的follower接受到議案後,想將議案寫入硬碟後,馬上回復Leader一個ACK(OK)。
d.當Leader接受到合法數量(過半)Acks,Leader給所有follower傳送commit命令。
e.follower執行commit命令。
注意:到了這個階段,ZK叢集才正式對外提供服務,並且Leader可以進行訊息廣播,如果有新節點加入,還需要進行同步。
- 階段三:資料同步
a.取出Leader最大lastZxid(從本地log日誌來)
b.找到對應zxid的資料,進行同步(資料同步過程保證所有follower一致)
c.只有滿足quorum同步完成,準Leader才能成為真正的Leader
8.3 寫資料流程

相關推薦
大資料篇:Zookeeper
Zookeeper 1 Zookeeper概念 Zookeeper是什麼 是一個基於觀察者設計模式的分散式服務管理框架,它負責和管理需要關心的資料,然後接受觀察者的註冊,一旦這些資料的狀態發生變化,Zookeeper就將負責通知已經在Zookeeper上註冊的那些觀察者做出相應的反應。 Zookee
大資料篇:Spark 啟動時,提示 slave1 JAVA_HOME not set
Problem: [[email protected] ~]# start-slaves.sh slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.
大資料篇:Hive的安裝詳解
hive是什麼? 由facebook開源,用於解決海量結構化日誌的資料統計; 基於hadoop的一個數據倉庫工具,使用HDFS進行儲存並將結構化資料檔案對映成一張表,並提供類sql查詢的功能,其底層採用MR進行計算; 本質是將HQL轉化成MR程式。
大資料篇:Spark入門第一個Spark應用程式詳解:WordCount
任務要求 編寫一個Spark應用程式,對某個檔案中的單詞進行詞頻統計。 備註:本文spark的根目錄名:spark-1.6.3-bin-hadoop2.6 #準備工作 cd /usr/local/spark-1.6.3-bin-hadoop2.6 mkdir mycode
大資料篇:Spark-shell的測試及Scala獨立應用程式的編寫與sbt打包
一、在 Spark Shell 中執行程式碼 Spark shell 提供了簡單的方式來學習 API,並且提供了互動的方式來分析資料。你可以輸入一條語句,Spark shell會立即執行語句並返回結果,這就是我們所說的REPL(Read-Eval-Print Loop,互動式直譯器
大資料篇:Linux(Centos7)虛擬機器的安裝
不管是做大資料hadoop、spark等框架,或者初學linux,一臺或幾臺linux系統拿來玩玩是必不可少的。要想裝好Linux虛擬系統,VMware Workstation Pro和CentOs(Linux的一種)必不可少,這裡我裝的是VMware Workstation Pro 1
大資料篇:Spark安裝及測試PI的值
本文執行的具體環境如下: centos7.3 Hadoop 2.8.4 Java JDK 1.8 Spark 1.6.3 一、安裝Hadoop 關於Hadoop的安裝,這裡就不概述了! 二、安裝 Spark 下載網址http://archive.apa
大資料篇:hadoop測試WordCount mapreduce出錯問題
[[email protected] ~]# hadoop jar /usr/local/hadoop-2.8.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar wordcount /data/wordcount /o
大資料篇:hadoop測試WordCount hdfs拒絕連線
18/11/02 11:50:03 INFO ipc.Client: Retrying connect to server: master/192.168.10.251:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCo
大資料篇:叢集 Spark的安裝
叢集安裝Spark 這裡採用3臺機器(節點)作為例項來演示如何搭建Spark叢集,其中1臺機器(節點)作為Master節點,另外兩臺機器(節點)作為Slave節點(即作為Worker節點),主機名分別為Slave1和Slave2。在Master節點機器上,訪問Spark官方下載地址
大資料篇:Elasticsearch分散式搜尋與分析引擎
Elasticsearch簡介 Elasticsearch是一個實時的分散式搜尋和分析引擎。它可以幫助你用前所未有的速度去處理大規模資料。 它可以用於全文搜尋,結構化搜尋以及分析,當然你也可以將這三者進行組合。 Elasticsearch是一個建立在全文搜尋引擎 Apa
大資料篇:Hadoop叢集統一時間
修改系統時間,將時間改為一致(建議採用本方法): 1.修改日期 date -s 11/2/2018 2.修改時間 date -s 20:40:00 3.檢查硬體(CMOS)時間 clock -r 4.這個修改在系統重啟後就失效了,因此為了將這個時間永久生效,需要
大資料篇:HDFS
HDFS HDFS是什麼? Hadoop分散式檔案系統(HDFS)是指被設計成適合執行在通用硬體(commodity hardware)上的分散式檔案系統(Distributed File System)。它和現有的分散式檔案系統有很多共同點。但同時,它和其他的分散式檔案系統的區別也是很明顯的。HDFS
大資料篇:Hbase
大資料篇:Hbase Hbase是什麼 Hbase是一個分散式、可擴充套件、支援海量資料儲存的NoSQL資料庫,物理結構儲存結構(K-V)。 如果沒有Hbase 如何在大資料場景中,做到上億資料秒級返回。(有條件:單條資料,範圍資料) hbase.apache.org 1 Hbase結構及
大資料篇:Spark
大資料篇:Spark Spark是什麼 Spark是一個快速(基於記憶體),通用,可擴充套件的計算引擎,採用Scala語言編寫。2009年誕生於UC Berkeley(加州大學伯克利分校,CAL的AMP實驗室),2010年開源,2013年6月進入Apach孵化器,2014年成為Apach頂級專案,目
大資料篇:一文讀懂@資料倉庫
# 大資料篇:一文讀懂@資料倉庫 ## 1 網路詞彙總結 - 人工智慧層的:智慧地球、智慧城市、智慧社會 - 企業層面的:數字網際網路,數字經濟、數字平臺、數字城市、數字政府; - 平臺層面的:物聯網,雲端計算,大資料,5G,人工智慧,機器智慧,深度學習,知識圖譜 - 技術層面的:資料倉庫、資料集市、大資
大資料篇:資料倉庫案例
# 離線資料倉庫 > 資料倉庫(Data WareHouse)是為企業所有決策制定過程,提供所有系統資料支援的戰略集合 > > 通過對資料倉庫中資料的分析,可以幫助企業,改進業務流程、控制、成本、提高產品質量等 > > 資料倉庫,並不是資料最終目的地,而是為資料最終的目的地做好準備:清洗、轉義、分類、重組、
大資料篇:一文讀懂@資料倉庫(PPT文字版)
# 大資料篇:一文讀懂@資料倉庫  :Zookeeper、 Yarn簡介、原理
https://blog.csdn.net/wzk646795873/article/details/79583218 Zookeeper Zookeeper是一個分散式協調服務,一個leader,多個follower組成的叢集,就是為使用者的分散式應用程式提供協調服務。 Zookeep
大資料學習路線:Zookeeper叢集管理與選舉
大資料技術的學習,逐漸成為很多程式設計師的必修課,因為趨勢也是因為自己的職業生涯。在各個技術社群分享交流成為很多人學習的方式,今天很榮幸給我們分享一些大資料基礎知識,大家可以一起學習! 1.叢集機器監控 這通常用於那種對叢集中機器狀態,機器線上率有較高要求的場景,能夠快速對叢集中機器變化作出響