
大資料篇:叢集 Spark的安裝
阿新 • • 發佈:2018-11-10
叢集安裝Spark
這裡採用3臺機器(節點)作為例項來演示如何搭建Spark叢集,其中1臺機器(節點)作為Master節點,另外兩臺機器(節點)作為Slave節點(即作為Worker節點),主機名分別為Slave1和Slave2。在Master節點機器上,訪問Spark官方下載地址,按照如下圖下載。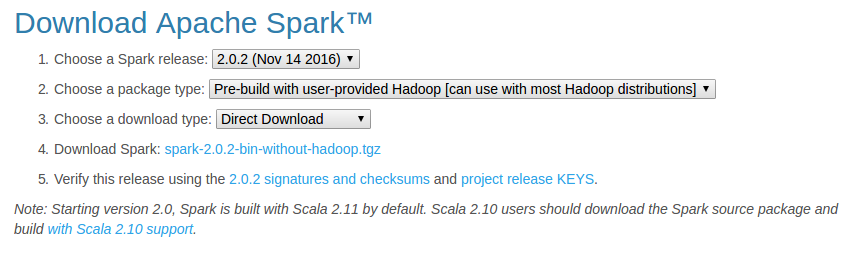
下載完成後,執行如下命令:
sudo tar -zxf spark-2.0.2-bin-without-hadoop.tgz -C /usr/local/ cd /usr/local sudo mv ./spark-2.0.2-bin-without-hadoop/ ./spark sudo chown -R hadoop ./spark
配置環境變數
在Mster節點主機的終端中執行如下命令:
vi ~/.bashrc在.bashrc新增如下配置:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
執行如下命令使得配置立即生效:
source ~/.bashrcSpark配置
在Master節點主機上進行如下操作:
配置slaves檔案 將 slaves.template 拷貝到 slaves cd /usr/local/spark/ cp ./conf/slaves.template ./conf/slaves
slaves檔案設定Worker節點。編輯slaves內容,把預設內容localhost替換成如下內容:
slave1
slave2
- 配置spark-env.sh檔案
將 spark-env.sh.template 拷貝到 spark-env.shcp ./conf/spark-env.sh.template ./conf/spark-env.sh編輯spark-env.sh,新增如下內容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SPARK_MASTER_IP=192.168.1.104SPARK_MASTER_IP 指定 Spark 叢集 Master 節點的 IP 地址;
配置好後,將Master主機上的/usr/local/spark資料夾複製到各個節點上。在Master主機上執行如下命令:
cd /usr/local/
tar -zcf ~/spark.master.tar.gz ./spark
cd ~
#將spark的tar包傳送到slave上
scp ./spark.master.tar.gz slave01:/home/hadoop
scp ./spark.master.tar.gz slave02:/home/hadoop在slave1,slave2節點上分別執行下面同樣的操作:
sudo rm -rf /usr/local/spark/
sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/spark啟動Spark叢集
啟動Hadoop叢集
啟動Spark叢集前,要先啟動Hadoop叢集。在Master節點主機上執行如下命令:
##啟動dfs及yarn
cd /usr/local/hadoop/
sbin/start-all.sh啟動Spark叢集
- 啟動Master節點
在Master節點主機上執行如下命令:cd /usr/local/spark/ sbin/start-master.sh在Master節點上執行jps命令,可以看到多了個Master程序:
15093 Jps 14343 SecondaryNameNode 14121 NameNode 14891 Master 14509 ResourceManager - 啟動所有Slave節點,在Master節點主機上執行如下命令:
sbin/start-slaves.sh分別在slave01、slave02節點上執行jps命令,可以看到多了個Worker程序
37553 DataNode
37684 NodeManager
37876 Worker
37924 Jps
- 在瀏覽器上檢視Spark獨立叢集管理器的叢集資訊
- 在master主機上開啟瀏覽器,訪問http://master:8080,如下圖:
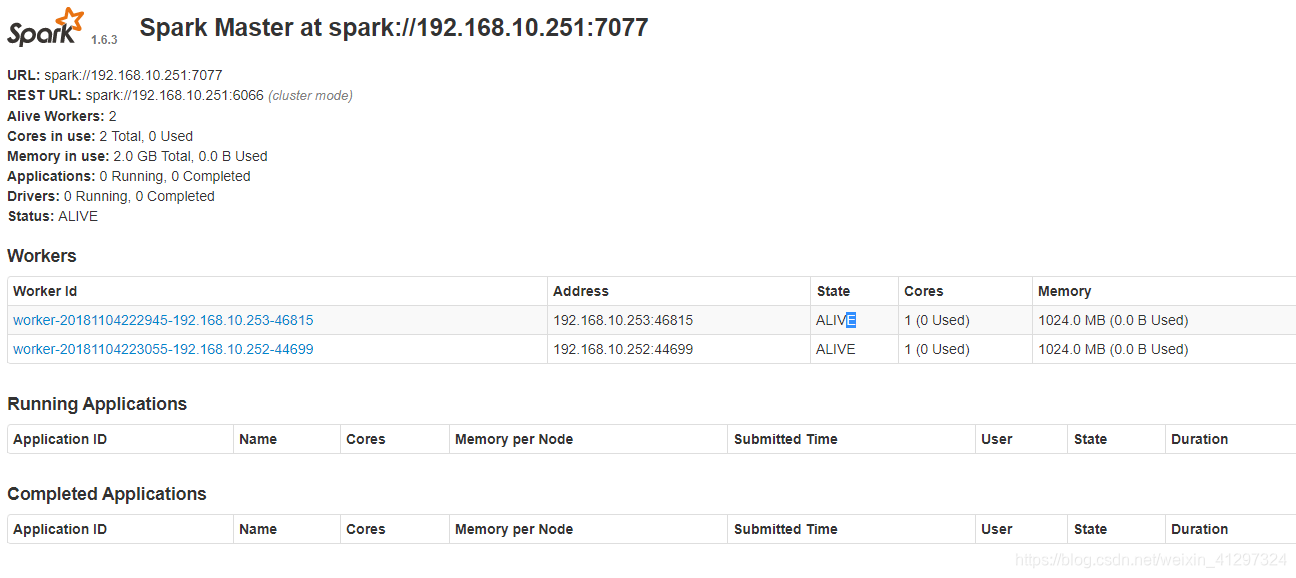
關閉Spark叢集
- 關閉Master節點
sbin/stop-master.sh- 關閉Worker節點
sbin/stop-slaves.sh- 關閉Hadoop叢集
cd /usr/local/hadoop/
sbin/stop-all.sh