
大資料篇:Hbase
大資料篇:Hbase

- Hbase是什麼
Hbase是一個分散式、可擴充套件、支援海量資料儲存的NoSQL資料庫,物理結構儲存結構(K-V)。
- 如果沒有Hbase
如何在大資料場景中,做到上億資料秒級返回。(有條件:單條資料,範圍資料)
hbase.apache.org
1 Hbase結構及資料型別
- 邏輯結構
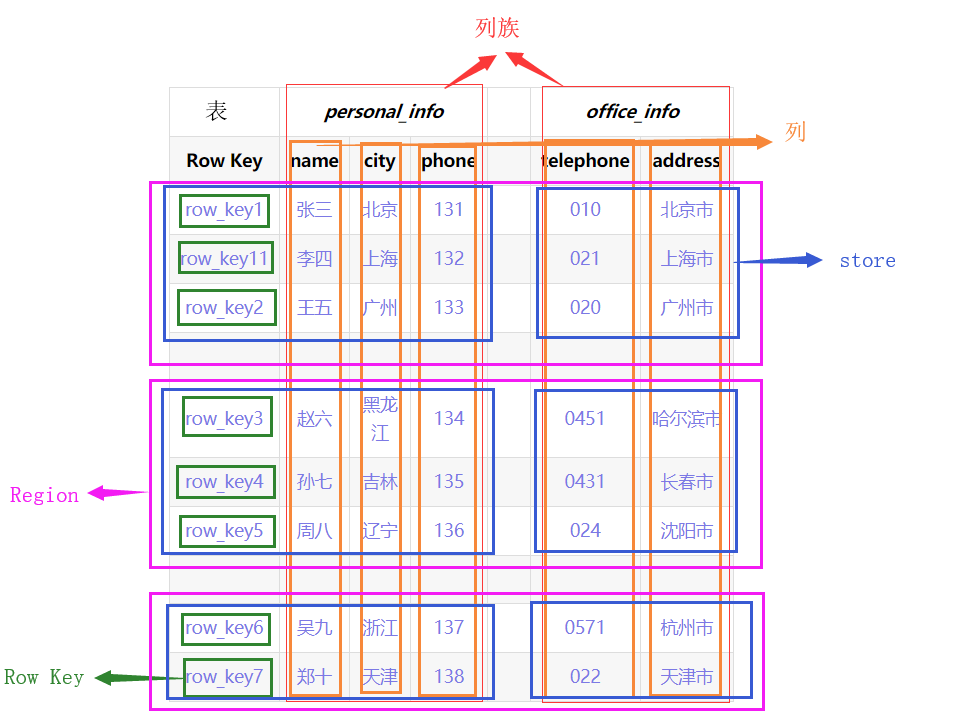
- 物理結構
整張表會按照水平方向按照Row Key切割(Region)。再按垂直方向按ColumnFamily切割(Store),
-
Name Space:名稱空間
- 類似於關係型資料庫中的database概念,每個名稱空間下可以放多個表,預設存在2個名稱空間:hbase和default,hbase存放Hbase內建的表,default表是使用者預設使用的名稱空間。(例如給order表賦予名稱空間test,可以寫為test:order)
-
Row:行
- Hbase中每行資料都由一個RowKey和多個列組成。
-
Column:列
- Hbase中的每個列都由ColumnFamily(列族)和ColumnQualifier(列限定符)進行限定,(例如:personal_info:name,personal_info:city)
-
Cell:單元
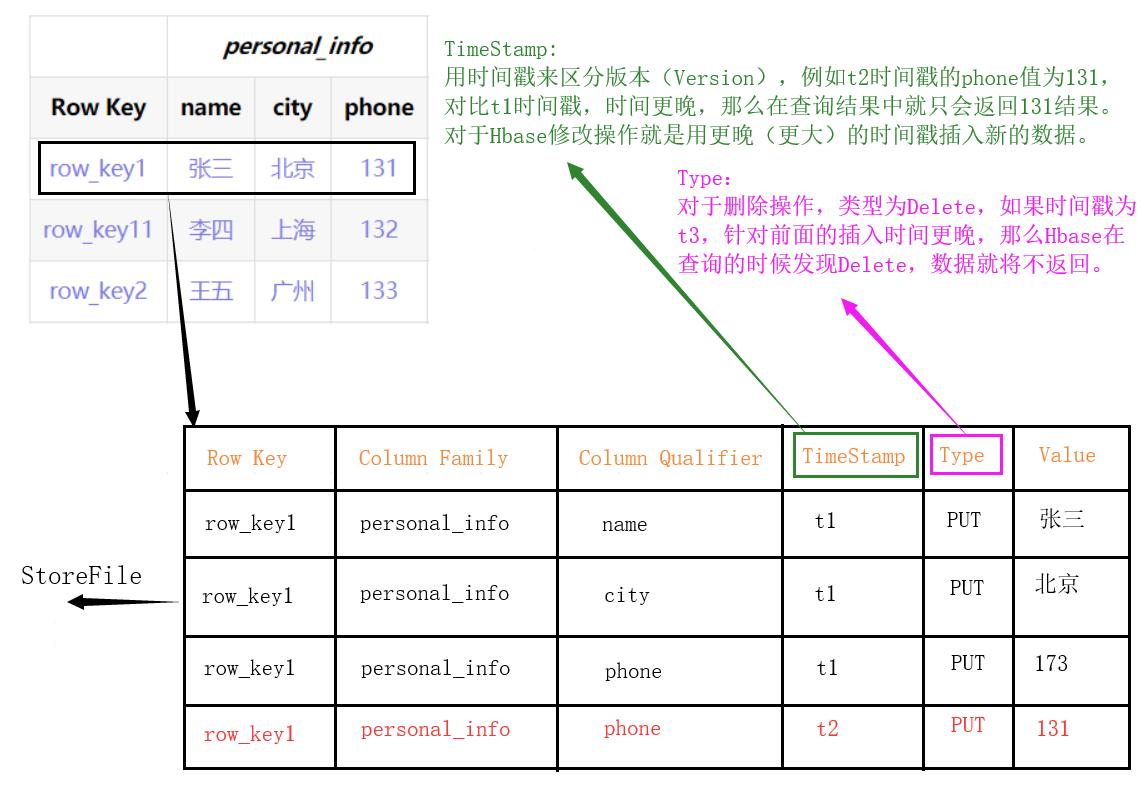
- 由{RowKey,ColumnFamily,ColumnQualifier,TimeStamp}唯一確定的單元,Cell中的資料是沒有型別的,全部為位元組碼形式儲存。
-
Row Key:行鍵
- Row Key在表中必須是唯一的而且必須存在的。
- Row Key是 按照字典序一位一位比較有序排列的(有值比沒有值大)。例如row_key11 排列在row_key1和row_ley2之間。
- 所有對錶的訪問都要通過Row Key 。(單個RowKey訪問,或RowKey範圍訪問,或全表掃描)
-
ColumnFamily:列族
- 建立Hbase表時,只需要給定CF即可,在插入資料時,列(欄位)可以動態、按需增加。
- 每個CF可以有一個或多個列成員(ColumnQualifier)。
- 不同列族放在hdfs不同資料夾中儲存。
-
TimeStamp:時間戳
- 用於標識資料的不同版本,如果不指定時間戳,Hbase在寫入資料時會自動加上當前系統時間戳為該欄位值。
2 Hbase架構
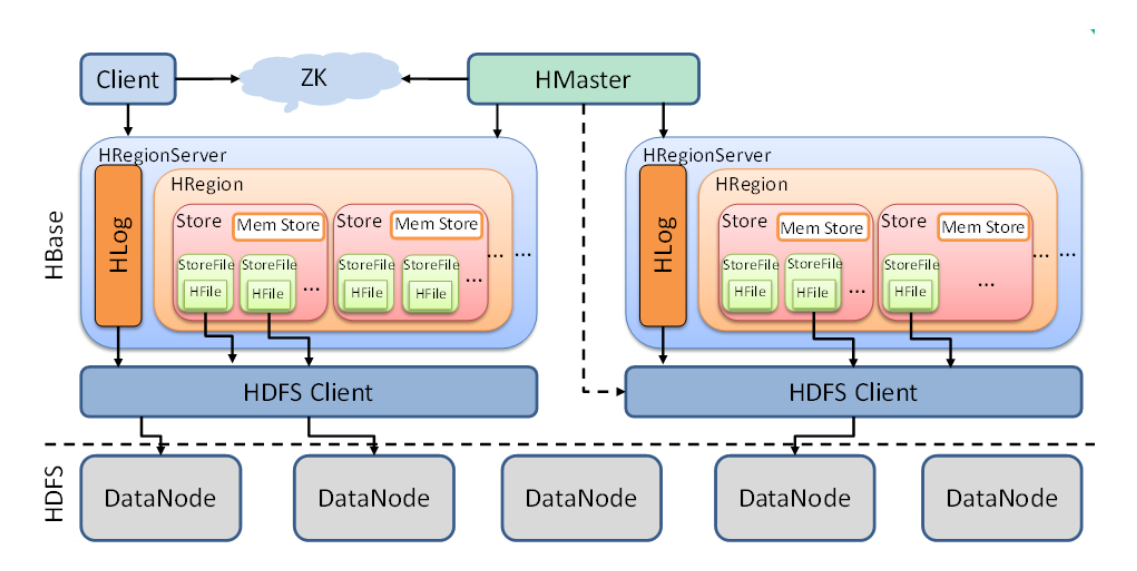
下面從小到大解釋上圖中的各元件中的功能。
-
StoreFile
- StoreFile為HBase真正儲存的檔案,最終通過HDFS客戶端存入DataNode。(也就是linux磁碟中)
-
Store
- 可以理解為一個切片Region中的一組列族。(如上圖一個Region中有多個Store)
- Store中包含Mem Store(記憶體儲存),StoreFile(由記憶體刷入的資料,數量多了會合並,資料大了會切分)
-
Region
- Region可以理解為一張表的切片,Region按照資料量大小閥值和Row key進行切分。
- HBase自動把表水平(按行)劃分成多個區域(region),每個region會儲存一個表裡面某段連續的資料。
- 每個表一開始只有一個region,隨著資料不斷插入,region不斷增大,當增大到一個閥值的時候,region就會根據Row key等分為兩個新的region,以此類推。
- Table中的行不斷增多,就會有越來越多的region,一張表資料就被儲存在多個Region 上。
-
HLog
- Hbase的預寫日誌,防止特殊情況下的資料丟失。
-
RegionServer
- 資料的操作(DML):get,put,delete
- 管理Region:SplitRegion(切分),CompactRegion(合併)
-
Master
- 表級別操作(DDL):create,delete,alter
- 管理RegionServer:監控RegionServer狀態,分配Regions到RegionServer,(如有機器rs1,rs2,rs3,資料寫入rs1,rs2上的Region,r3空閒--->這時rs1被大量寫入資料達到Region上限,rs1將Region等分後,就會通知Master將其中一份發往rs3管理。)
3 命令列操作
3.1 連結hbase
- 連結hbase
hbase shell
- 檢視幫助命令或命令詳細使用
help
help '命令'
3.2 名稱空間操作
3.2.1 查詢名稱空間
list_namespace

3.2.2 查詢名稱空間下的表
list_namespace_tables '名稱空間名'

3.2.3 建立名稱空間
create_namespace '名稱空間名'

3.2.4 刪除名稱空間(需要namespace是空的)
drop_namespace '名稱空間名'
3.3 DDL操作
3.3.1 查詢所有使用者表
list
3.3.2 建立表
create '名稱空間:表', '列族1', '列族2', '列族3','列族4'...

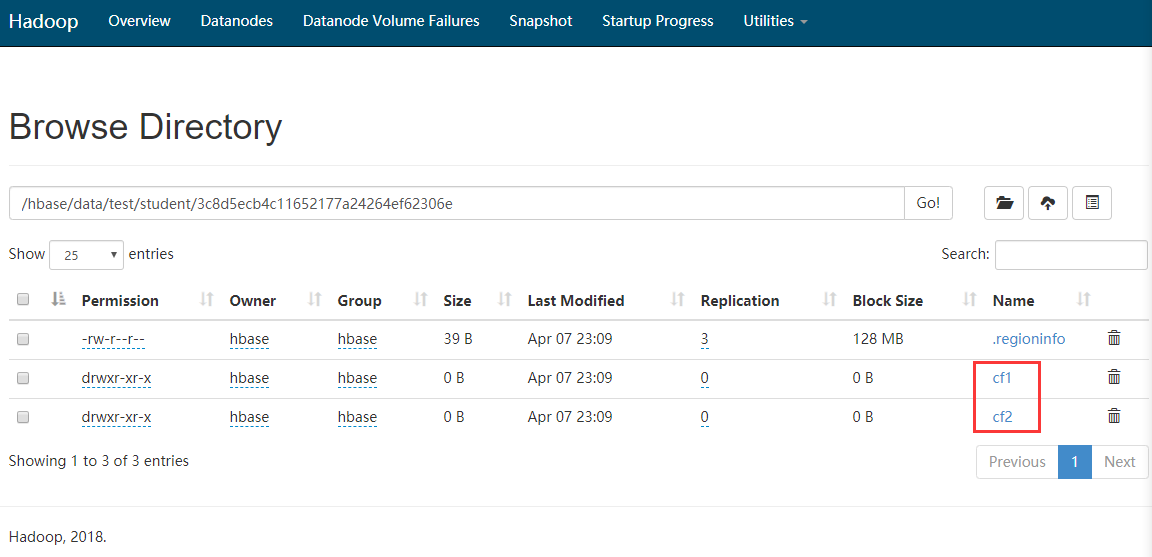
如圖發現有一串亂亂序資料夾,這串亂序就代表了Region號

3.3.3 查看錶詳情
describe '名稱空間:表'

可以看出VERSIONS為1,代表這個表只能存放一個版本的資料。
3.3.4 變更表資訊
主要用於修改表的版本儲存資訊,也可以建立表的時候指定,但是shell命令複雜,故一般使用變更命令。
alter '名稱空間:表',{NAME=>'列族名',VERSIONS=>3}
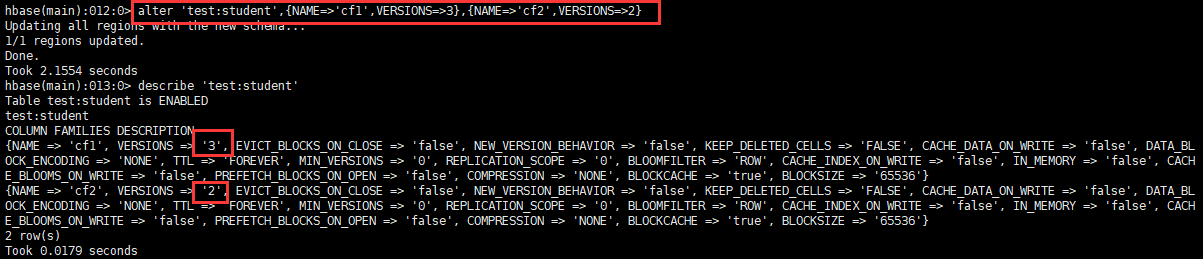

3.3.5 修改表狀態(刪除前必須失效表)
- 失效表
disable '表'
- 啟用表
enable '表'
3.3.6 刪除表
delete '表'
3.4 DML操作
3.4.1 插入資料
put '名稱空間:表','RowKey','列族:列','值'
put '名稱空間:表','RowKey','列族:列','值',時間戳(版本控制)


如圖發現並沒有資料檔案生成,因為資料在記憶體中,需要flush '表',而後就可以看見資料落地了。(flush一次就是生成一個StoreFile)
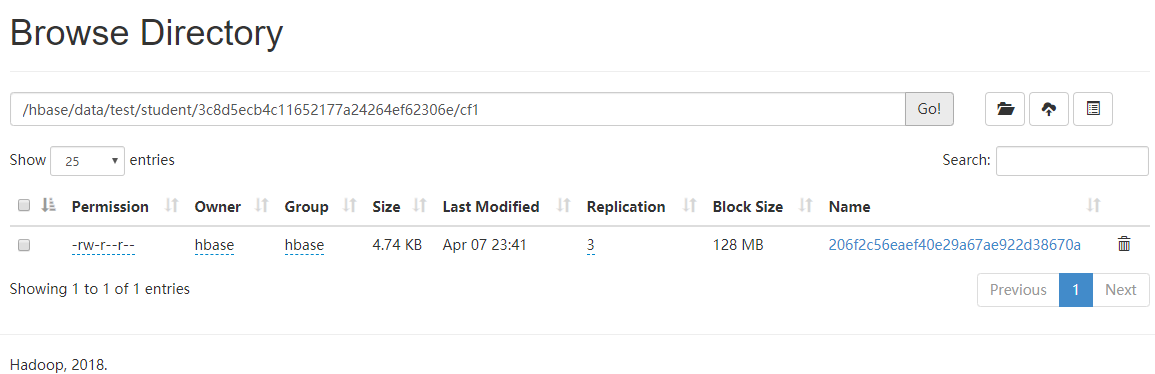
3.4.2 掃描表
#全表掃描
scan '名稱空間:表'
#範圍掃描(左閉右開)
scan '名稱空間:表',{STARTROW => 'RowKey',STOPROW=>'RowKey'}
#掃描N個版本的資料
scan '名稱空間:表',{RAW=>true,VERSIONS=>10}
3.4.3 Flush刷寫
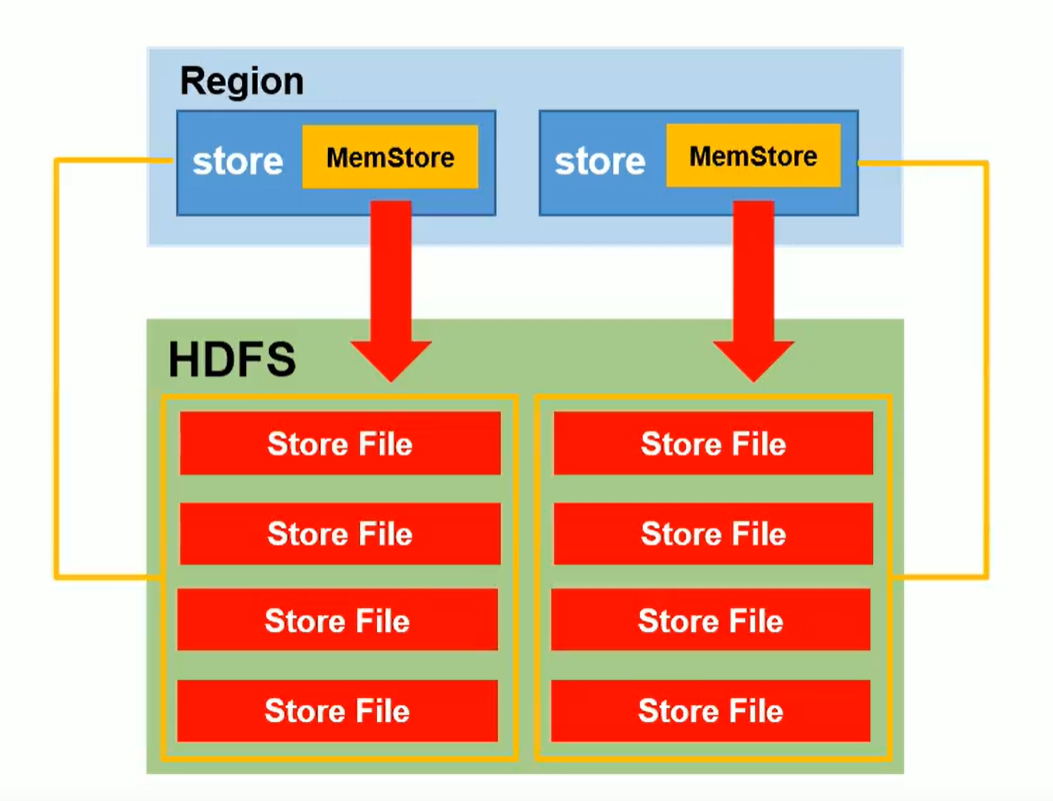
flush '名稱空間:表'
- 資料版本保留機制
從上面知道flush一次就是生成一個StoreFile,那麼資料就會根據建表保留版本個數來儲存最近個數的資料。
比如:保留版本個數為2,那麼如果插入v1,v2,v3三條資料,flush後,就只剩下v2,v3兩條資料,這時再插入v4,v5,v6三條資料,flush後,剩下的為v2,v3,v5,v6四個版本的資料(此時是2個StoreFile檔案),如果發生Region合併或者分裂,那麼StoreFile檔案會被合併後在放入對應的Region中,這時資料就又會根據保留版本個數刪除,v2,v3,v5,v6,就變成了v5,v6。(如果沒有手動flush,或者到設定的自動flush時間,那麼資料不會根據版本個數刪除)(預設超過3個StoreFile檔案則會進行大合併)
- 一個列族對應一個MemStore
- 每個MemStore在刷寫到HDFS時,生成的StoreFile是獨立的
- RegionServer全域性MemStore刷寫時機:hbase.regionserver.global.memstore.size
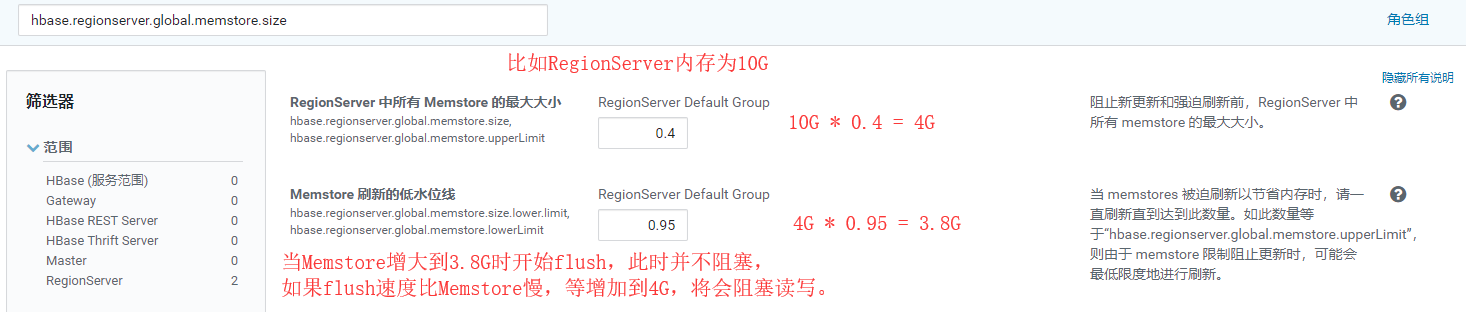
- 單個Memstore刷寫時機:hbase.hregion.memstore.flush.size

3.4.3 查詢資料
get '名稱空間:表','RowKey'
get '名稱空間:表','RowKey','列族'
get '名稱空間:表','RowKey','列族:列'
#獲取N個版本的資料
get '名稱空間:表','RowKey',{COLUMN=>'列族:列',VERSIONS=>10}

3.4.4 清空表
truncate '名稱空間:表'
3.4.5 刪除資料
#delete '名稱空間:表','RowKey','列族'(此命令列刪除有問題,但是API可以)
delete '名稱空間:表','RowKey','列族:列'
deleteall '名稱空間:表','RowKey'
4 讀寫流程
4.1 寫流程
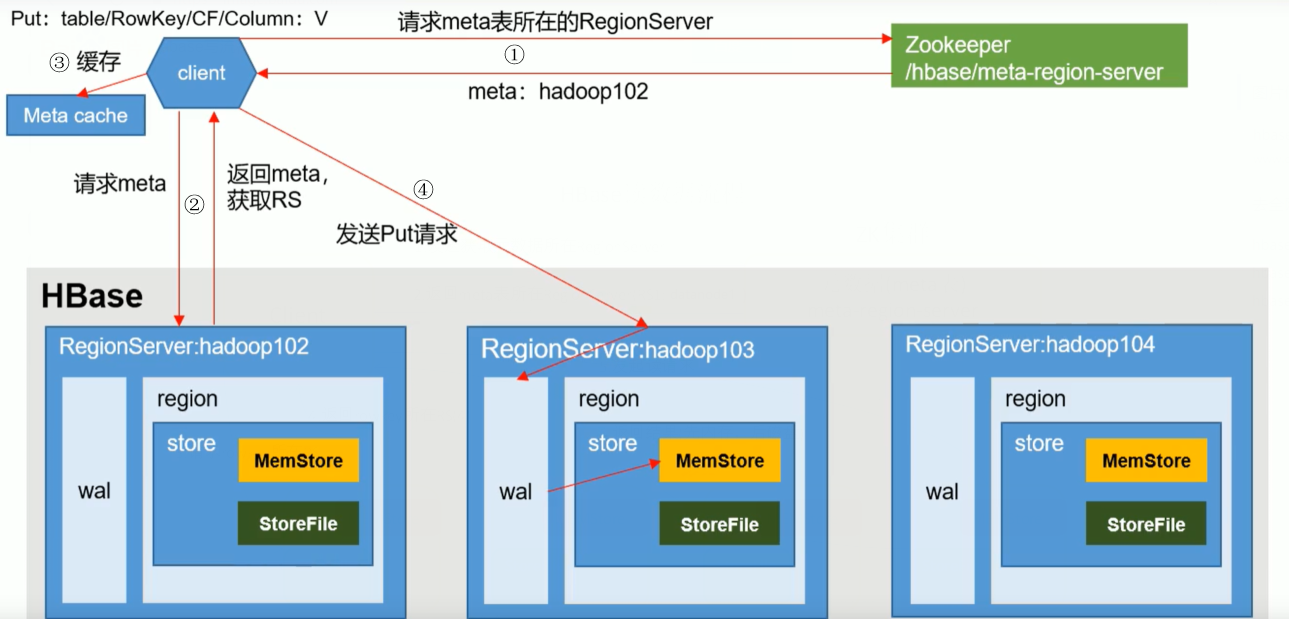
- 客戶端通過ZK查詢元資料儲存表的所在RegionServer所在位置並返回


- 查詢元資料,返回需要表的RegionServer

-
客戶端快取資訊,方便下次使用
-
傳送PUT請求到RegionServer,寫操作日誌(WAL),再寫入記憶體,然後同步wal到HDFS,則結束。(此步驟由事務回滾保證日誌、記憶體都寫入成功)
4.2 讀流程

在讀取資料時候,MemStore和StoreFile一起讀取,將StoreFile中的資料放入BlockCache,然後在將記憶體資料和BlockCache比較時間戳做Merge,取最新的資料返回。
5 合併切分
- 合併Compaction
由於Memstore每次刷寫都會生成一個新的HFile,且同一個欄位的不同版本和不同型別有可能會分佈在不同的HFile中,因此查詢時需要遍歷所有的HFile。為了減少HFile的個數,以及清理掉過期和刪除的資料,會進行StoreFile合併。
Compaction分為Minor Compaction和Major Compaction。
Minor Compaction會將臨近的若干個較小的HFile合併成一個較大的HFile,但不會清理過期和刪除的資料。
Major Compaction會將一個Store下的所有HFile合併成一個大的HFile,並且會清理掉過期和刪除的資料。
引數設定:
hbase.hregion.majorcompaction=0
hbase.hregion.majorcompaction.jitter=0
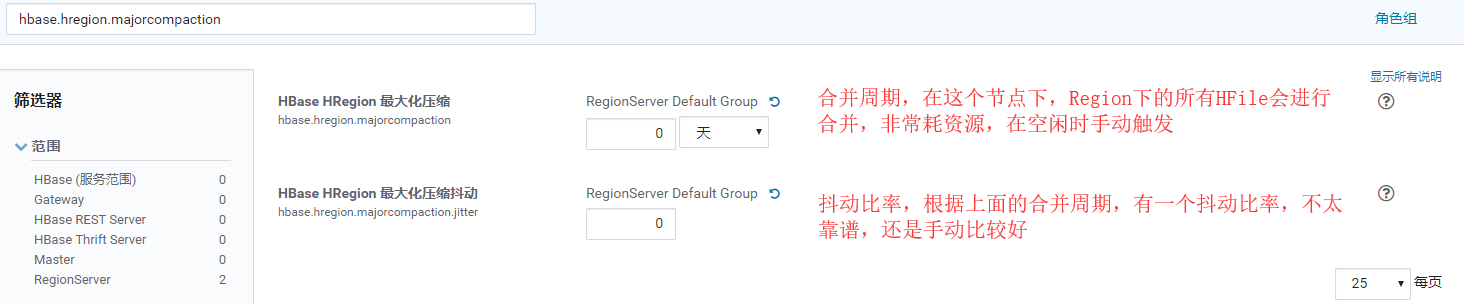
hbase.hstore.compactionThreshold=3

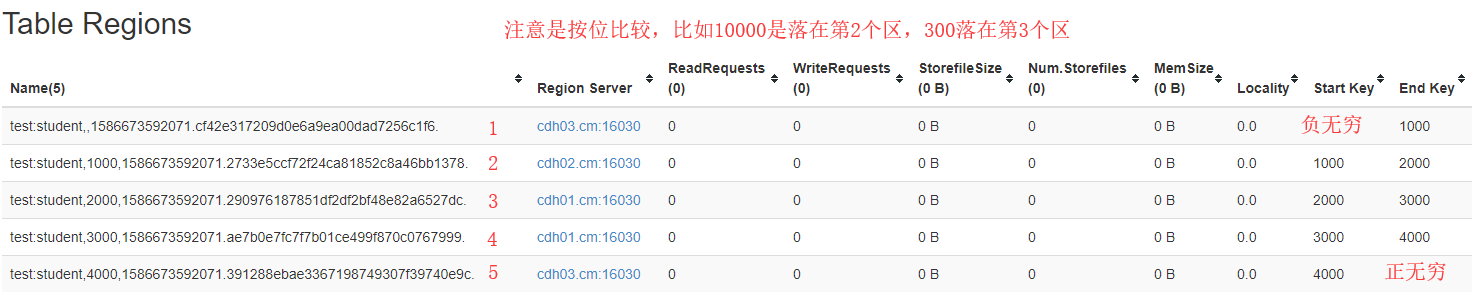
- 切分
預設情況下,每個Table起初只有一個Region,隨著資料的不斷寫入,Region會自動進行拆分,剛拆分時,兩個子Region都位於當前Region Server,但處於負載均衡的考慮,HMaster有可能會將某個Region轉移給其他的Region Server。
引數設定:
hbase.hregion.max.filesize=5G (如下公式中為Max1)(可以減小該值,提高併發)
hbase.hregion.memstore.flush.size=258M (如下公式中為Max2)
每次切分將會比較Max1和Max2的值,取小的。[min(Max1,Max2 * Region個數 * 2)],其中Region個數為當前Region Server中資料該Table的Region個數。
由於自動切分無法避免熱點問題,所以在生產中我們常常使用預分割槽和設計RowKey避免出現熱點問題


6 優化
6.1 儘量不要使用多個列族
為了避免flush時產生多個小檔案。
6.2 記憶體優化

主要作用來快取Table資料,但是flush時會GC,不要太大,根據叢集資源,一般分配整個Hbase叢集記憶體的70%,16->48G就可以了
6.3 允許在HDFS中追加內容
dfs.support.append=true (hdfs-site.xml、hbase-site.xml)
6.4 優化DataNode允許最大檔案開啟數
dfs.datanode.max.transfer.threads=4096 (HDFS配置)
在Region Server級別的合併操作中,Region Server不可用,可以根據叢集資源調整該值,增加併發。
6.5 調高RPC監聽數量
hbase.regionserver.handler.count=30
根據叢集情況,可以適當增加該值,主要決定是客戶端的請求數。
6.6 優化客戶端快取
hbase.client.write.buffer=100M (寫快取)
調高該值,可以減少RPC呼叫次數,單數會消耗更多記憶體,根據叢集資源情況設定。
6.7 合併切分優化
參考5合併切分
6.8 預分割槽
- 建立表時候加入引數SPLITS
create '名稱空間:表', '列族1', '列族2', '列族3','列族4'...,SPLITS=>['分割槽號','分割槽號','分割槽號','分割槽號']

根據資料量預估半年到一年的資料量,和Region最大值來選擇預分割槽數。
6.9 RowKey
- 雜湊性:均勻分部到不同的Region裡
- 唯一性:不會重複
- 長度:70-100位
方案一:隨機數,hash值,但是這種不能範圍查詢,沒有資料的集中性。
方案二:字串反轉,比如時間戳反轉後就達到了雜湊性,但是在檢視的時候集中性只是優於第一種。
- 生產方案推薦:
#設計預分割槽鍵(如比如200個區) | ASCLL碼為124只有 } 和 ~ 比它大,那麼不管以後的RowKey使用什麼字元,都是小於這個字元的,所以可以有效的得到RowKey規律
000|
001|
......
199|
# 1 設計RowKey鍵_ASCLL碼為95
000_
001_
......
199_
# 2 根據業務唯一標識(如使用者ID,手機號,身份證)和時間維度(比如按月:202004)計算後根據分割槽數取餘(13408657784^202004)%199=分割槽號
# 想以什麼時間進行查詢就把什麼往前提,如下資料需要查1月資料範圍就是 000_13408657784_2020-04 -> 000_13408657784_2020-04|
000_13408657784_2020-04-01 12:12:12
......
199_13408657784_2020-04-01 24:12:12