
大資料篇:Spark
大資料篇:Spark

- Spark是什麼
Spark是一個快速(基於記憶體),通用,可擴充套件的計算引擎,採用Scala語言編寫。2009年誕生於UC Berkeley(加州大學伯克利分校,CAL的AMP實驗室),2010年開源,2013年6月進入Apach孵化器,2014年成為Apach頂級專案,目前有1000+個活躍者。就是說用Spark就對了。
Spark支援Scala,Java,R,Python語言,並提供了幾十種(目前80+種)高效能的演算法,這些如果讓我們自己來做,幾乎不可能。
Spark得到眾多公司支援,如:阿里、騰訊、京東、攜程、百度、優酷、土豆、IBM、Cloudera、Hortonworks等。
- 如果沒有Spark
解決MapReduce慢的問題而誕生,官網解釋比同樣的MapReduce任務快100倍!
spark.apache.org
1 內建模組
機器學習(MLlib),圖計算(GraphicX),實時處理(SparkStreaming),SQL解析(SparkSql)

1.1 叢集資源管理
Spark設計為可以高效的在一個計算節點到數千個計算節點之間伸縮計算,為了實現這樣的要求,同時獲得最大靈活性,Spark支援在各種叢集資源管理器上執行,目前支援的3種如下:(上圖中下三個)
- Hadoop YARN(國內幾乎都用)
- Apach Mesos(國外使用較多)
- Standalone(Spark自帶的資源排程器,需要在叢集中的每臺節點上配置Spark)
1.2 Spark Core
實現了Spark的基本功能,包含任務排程、記憶體管理、錯誤恢復、與儲存系統互動等模組。其中還包含了對彈性分散式資料集(RDD:Resilient Distributed DataSet)的API定義
1.3 Spark SQL
是Spark用來操作結構化資料的程式包,通過Spark SQL 我們可以使用SQL或者HQL來查詢資料。且支援多種資料來源:Hive、Parquet、Json等
1.4 Spark Streaming
是Spark提供的對實時資料進行流式計算的元件
1.5 Spark MLlib
提供常見的機器學習功能和程式庫,包括分類、迴歸、聚類、協同過濾等。還提供了模型評估、資料匯入等額外的支援功能。
2 執行模式
2.1 核心概念介紹
-
Master
- Spark特有的資源排程系統Leader,掌控整個叢集資源資訊,類似於Yarn框架中的ResourceManager
- 監聽Worker,看Worker是否正常工作
- Master對Worker、Application等的管理(接收Worker的註冊並管理所有的Worker,接收Client提交的Application,排程等待Application並向Worker提交)
-
Worker
- Spark特有的資源排程Slave,有多個,每個Slave掌管著所有節點的資源資訊,類似Yarn框架中的NodeManager
- 通過RegisterWorker註冊到Master
- 定時傳送心跳給Master
- 根據Master傳送的Application配置程序環境,並啟動ExecutorBackend(執行Task所需的程序)
-
Driver
- Spark的驅動器,是執行開發程式中的main方法的執行緒
- 負責開發人員編寫SparkContext、RDD,以及進行RDD操作的程式碼執行,如果使用Spark Shell,那麼啟動時後臺自啟動了一個Spark驅動器,預載入一個叫做sc的SparkContext物件,如果驅動器終止,那麼Spark應用也就結束了。
- 4大主要職責:
- 將使用者程式轉化為作業(Job)
- 在Executor之間排程任務(Task)
- 跟蹤Executor的執行情況
- 通過UI展示查詢執行情況
-
Excutor
- Spark Executor是一個工作節點,負責在Spark作業中執行任務,任務間相互獨立。Spark應用啟動時,Executor節點被同時啟動,並且始終伴隨著整個Spark應用的生命週期而存在,如果有Executor節點發生了故障或崩潰,Spark應用也可以繼續執行,會將出錯節點上的任務排程到其他Executor節點上繼續執行
- 兩個核心功能:
- 負責執行組成Spark應用的任務,並將結果返回給驅動器(Driver)
- 它通過自身塊管理器(BlockManager)為使用者程式中要求快取的RDD提供記憶體式儲存。RDD是直接存在Executor程序內的,因此任務可以在執行時充分利用快取資料加速運算。
-
RDDs
- Resilient Distributed DataSet:彈性分散式資料集
- 一旦擁有SparkContext物件,就可以用它來建立RDD
-
通用流程圖
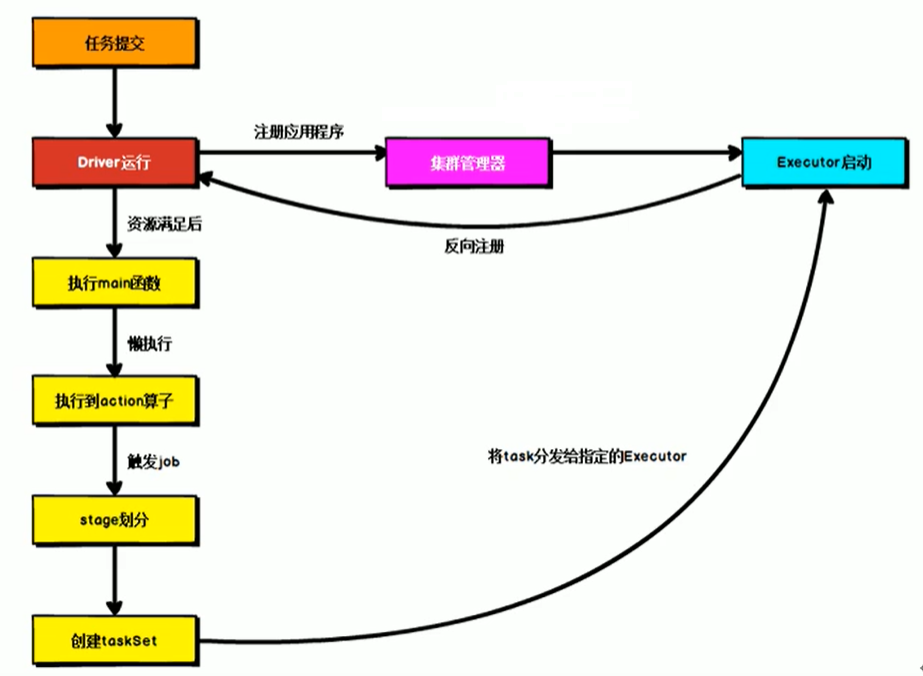
2.2 WordCount案例
- Spark Shell方式
#建立word.txt檔案
vim word.txt
#--->
hadoop hello spark
spark word
hello hadoop spark
#---<
#上傳HDFS叢集
hadoop dfs -put word.txt /
#連結客戶端
spark-shell
sc.textFile("/word.txt").flatMap(line => line.split(' ')).map((_,1)).reduceByKey(_ + _).collect

每個Spark應用程式都包含一個驅動程式,驅動程式負責把並行操作釋出到叢集上,驅動程式包含Spark應用中的主函式,定義了分散式資料集以應用在叢集中,在前面的wordcount案例中,spark-shell就是我們的驅動程式,所以我們鍵入我們任何想要的操作,然後由它負責釋出,驅動程式通過SparkContext物件來訪問Spark,SparkContext物件相當於一個到Spark叢集的連結
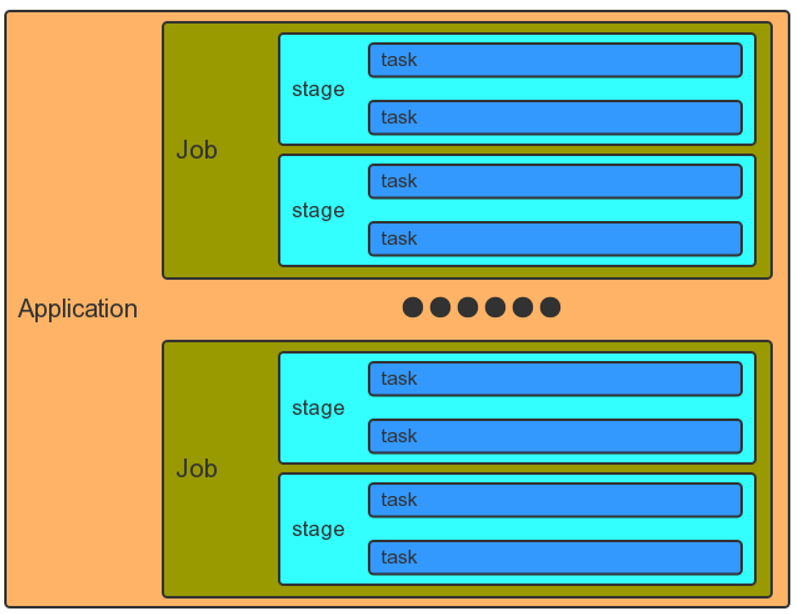
2.3 Job劃分和排程
- Application應用
- 一個SparkContext就是一個Application
- Job作業:
- 一個行動運算元(Action)就是一個Job
- Stage階段:
- 一次寬依賴(一次shuffle)就是一個Stage,劃分是從後往前劃分
- Task任務:
- 一個核心就是一個Task,體現任務的並行度,常常根據核心數的1.5倍進行設定
- 使用WordCount案例分析
一個行動運算元collect(),一個job

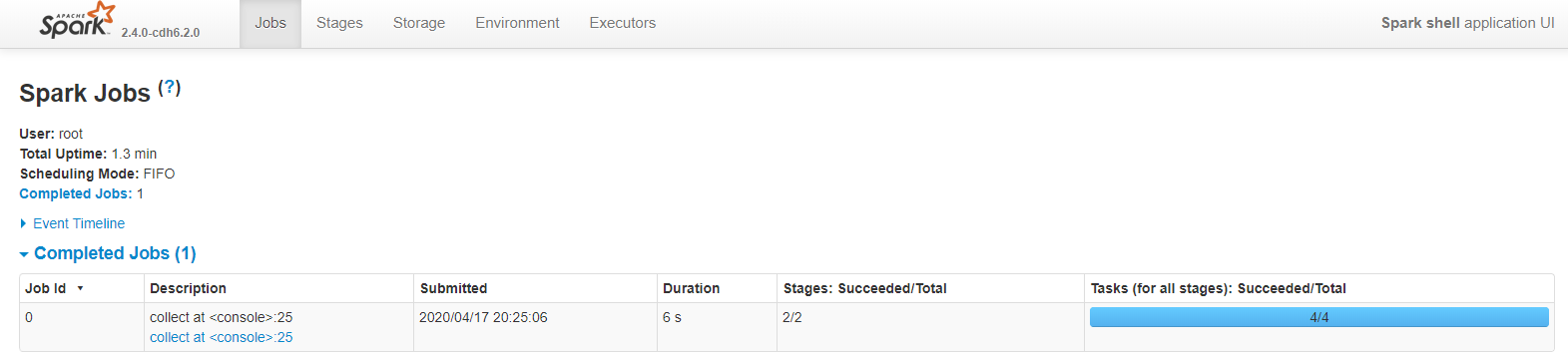
一次寬依賴shuffle運算元reduceByKey(),切分成2個Stage階段
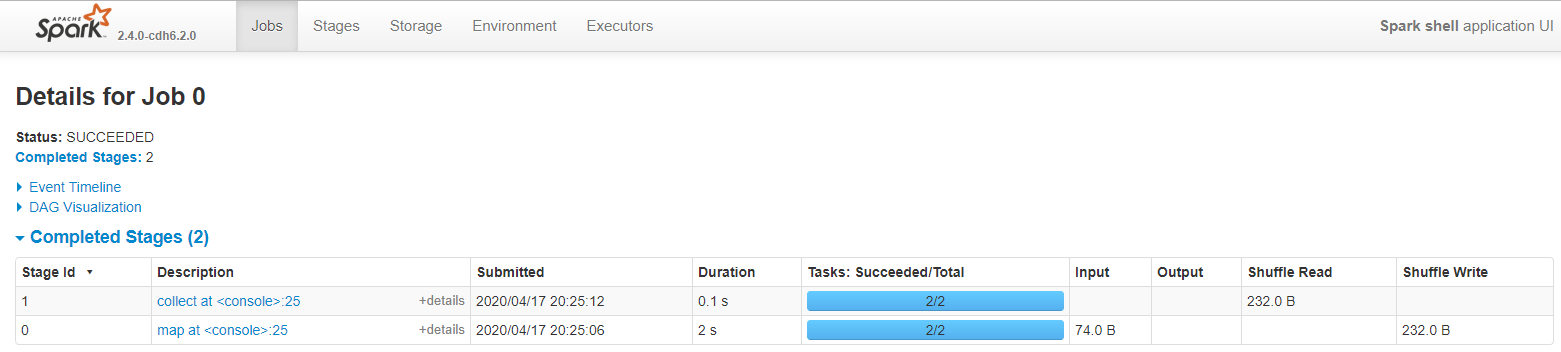
Stage階段,預設檔案被切分成2份,所以有2個task
Stage階段0
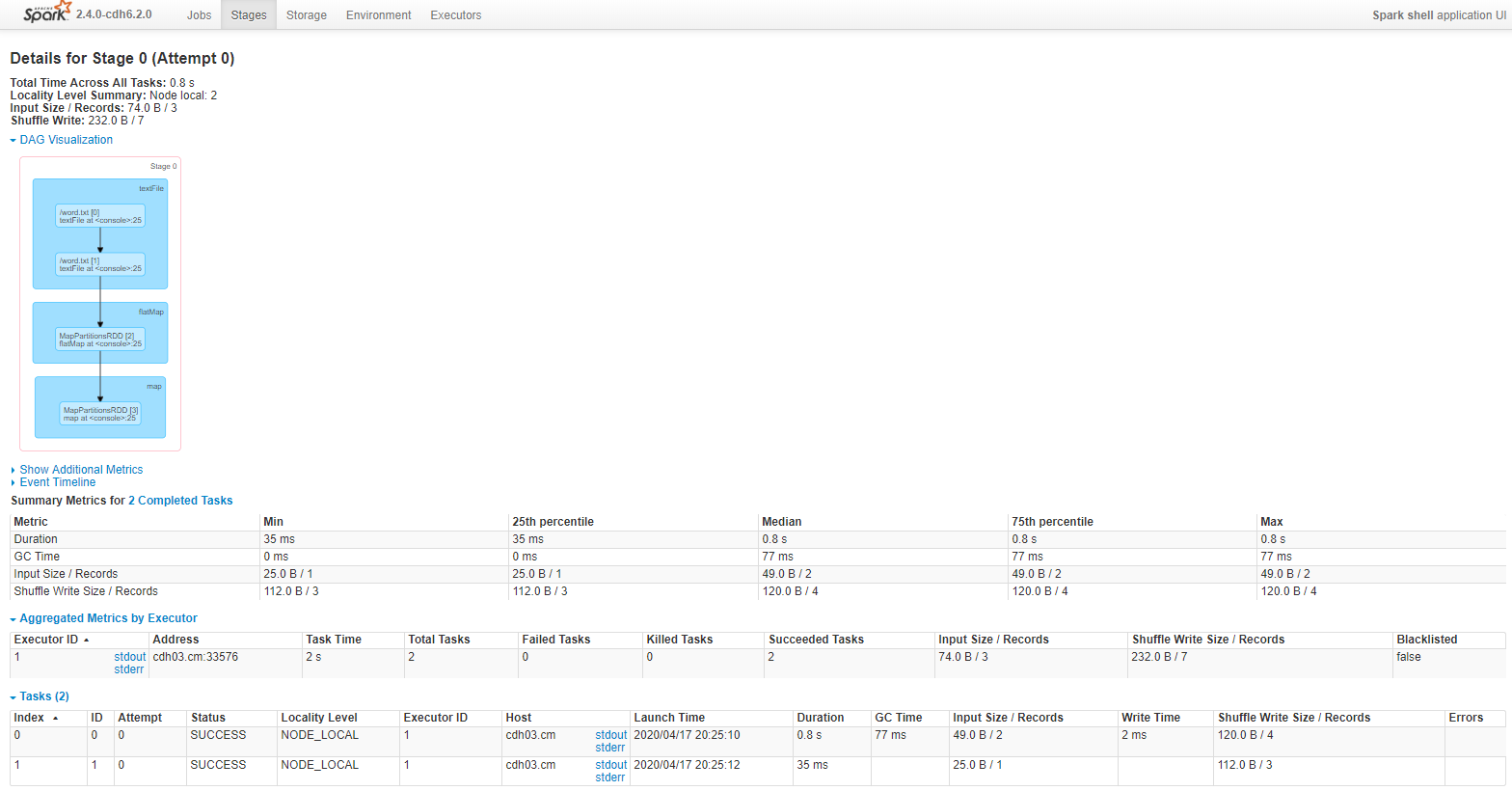
Stage階段1
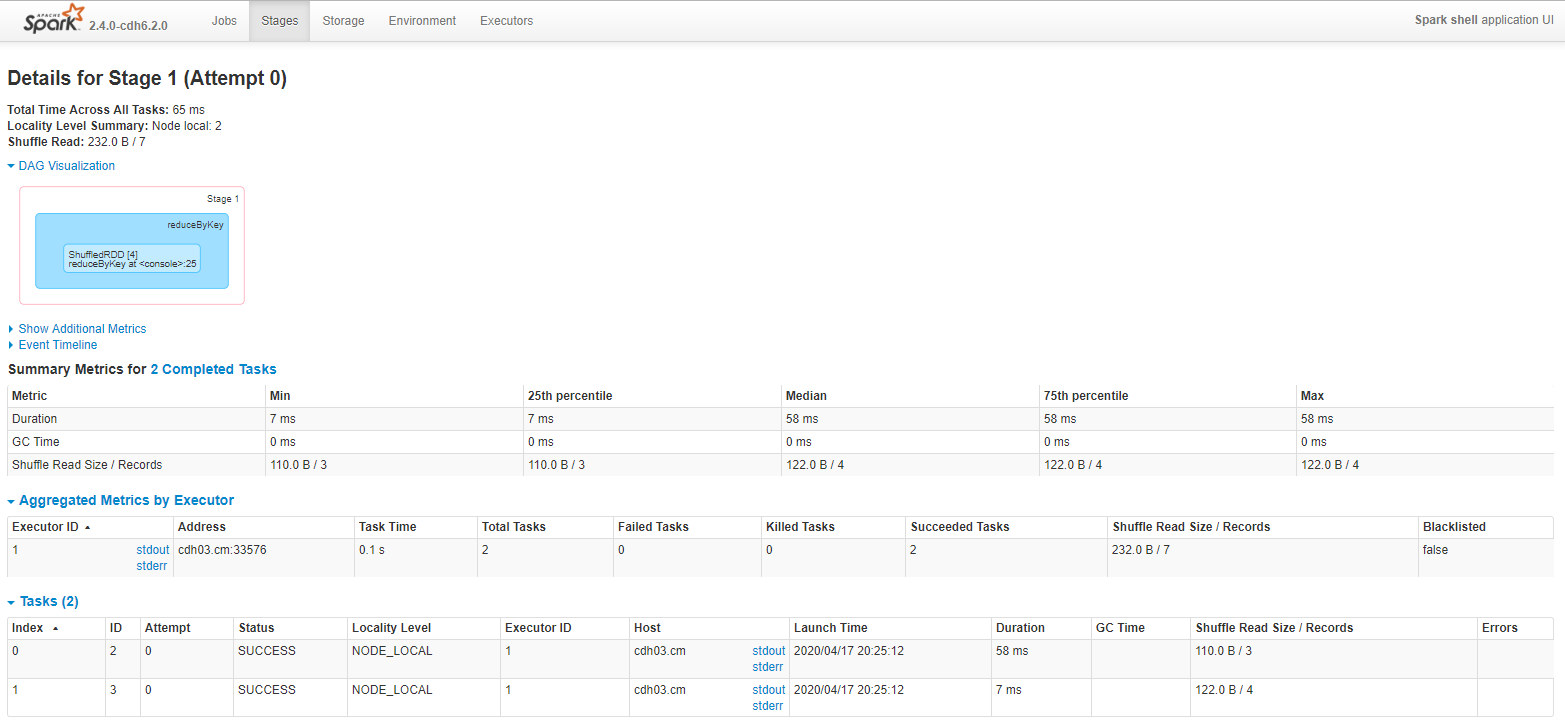
2.4 Shuffle洗牌
2.4.1 ShuffleMapStage And ResultStage
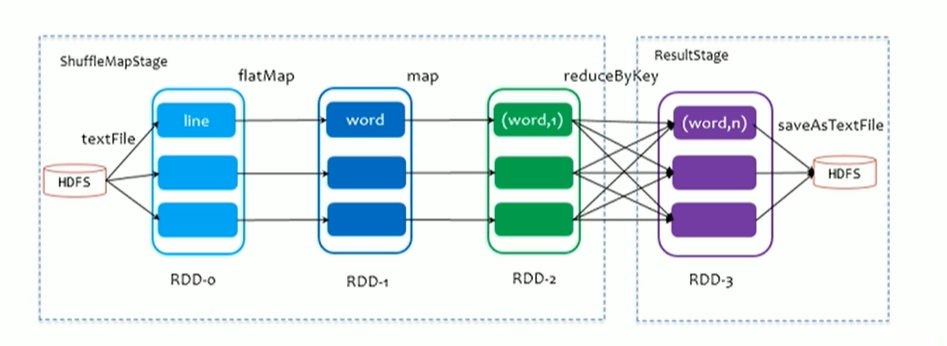
-
在劃分stage時,最後一個stage稱為FinalStage,本質上是一個ResultStage物件,前面所有的stage被稱為ShuffleMapStage
-
ShuffleMapStage 的結束伴隨著shuffle檔案寫磁碟
-
ResultStage對應程式碼中的action運算元,即將一個函式應用在RDD的各個Partition(分割槽)的資料集上,意味著一個Job執行結束
2.4.2 HashShuffle
- 未優化HashShuffle流程圖:目前已經沒有了
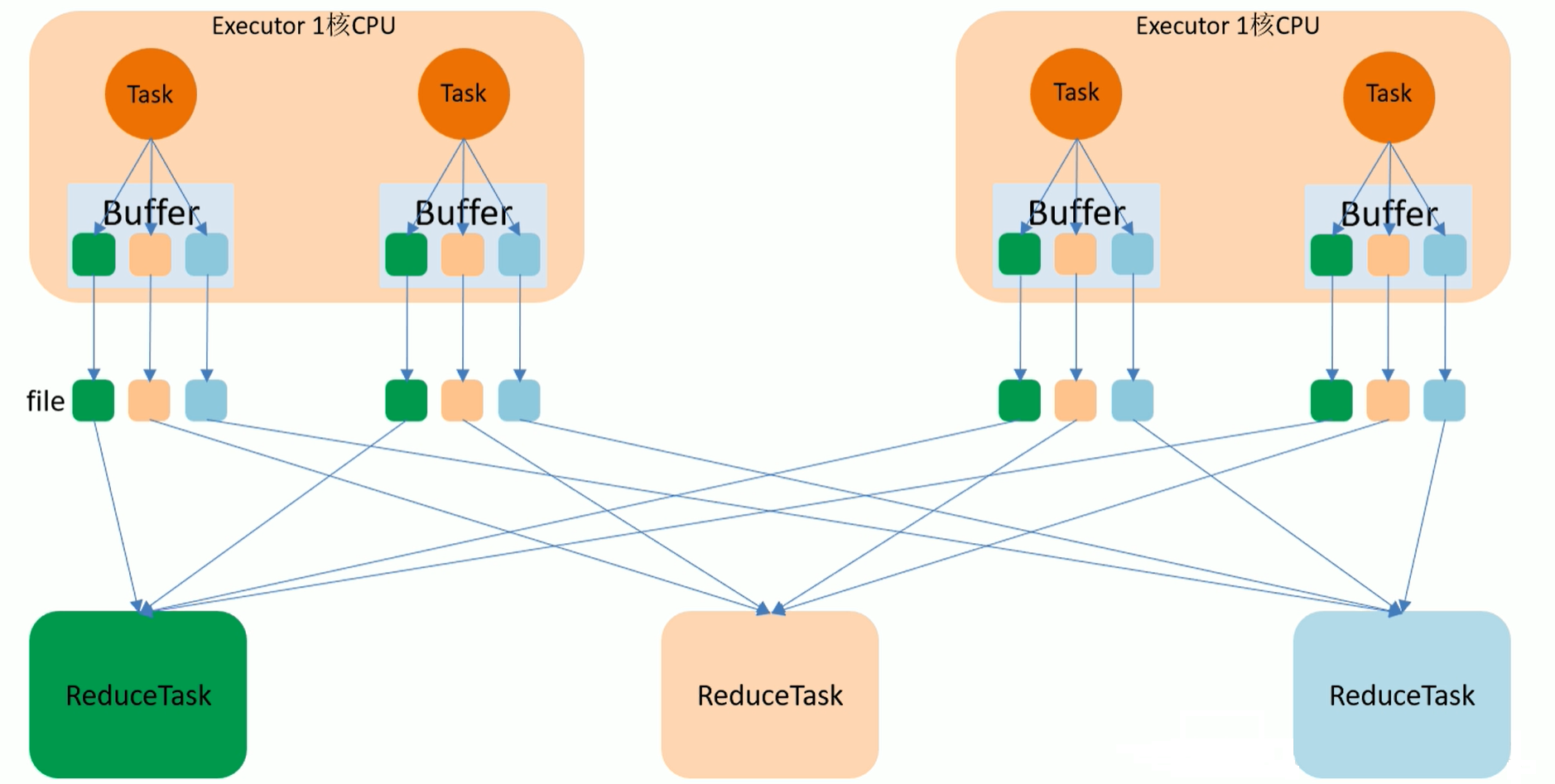
如上圖,最終結果會有12個小檔案
- 優化後HashShuffle流程圖
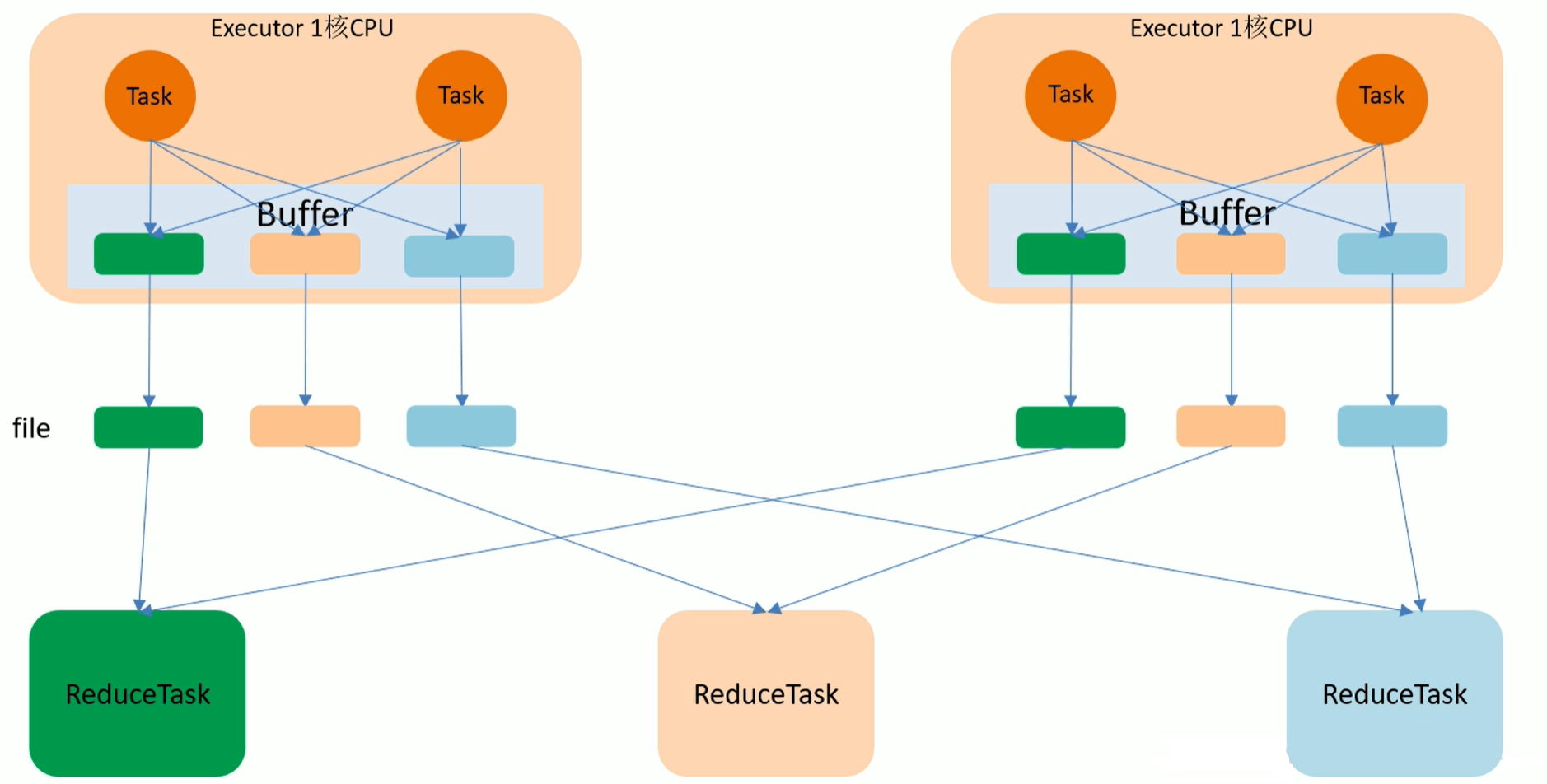
如上圖,最終結果會有6個小檔案,比未優化前少了一半
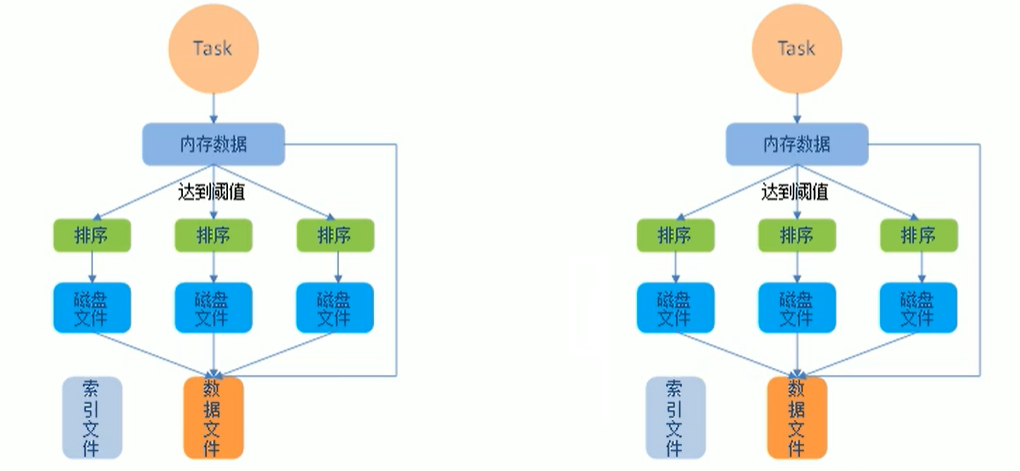
2.4.3 SortShuffle
該模式下,資料會先寫入一個數據結果,reduceByKey寫入Map,一邊通過Map區域性聚合,一邊寫入記憶體,
Join運算元寫入ArrayList直接寫入記憶體中,然後需要判斷是否達到閥值,如果達到就會將記憶體資料寫入磁碟,釋放記憶體資源
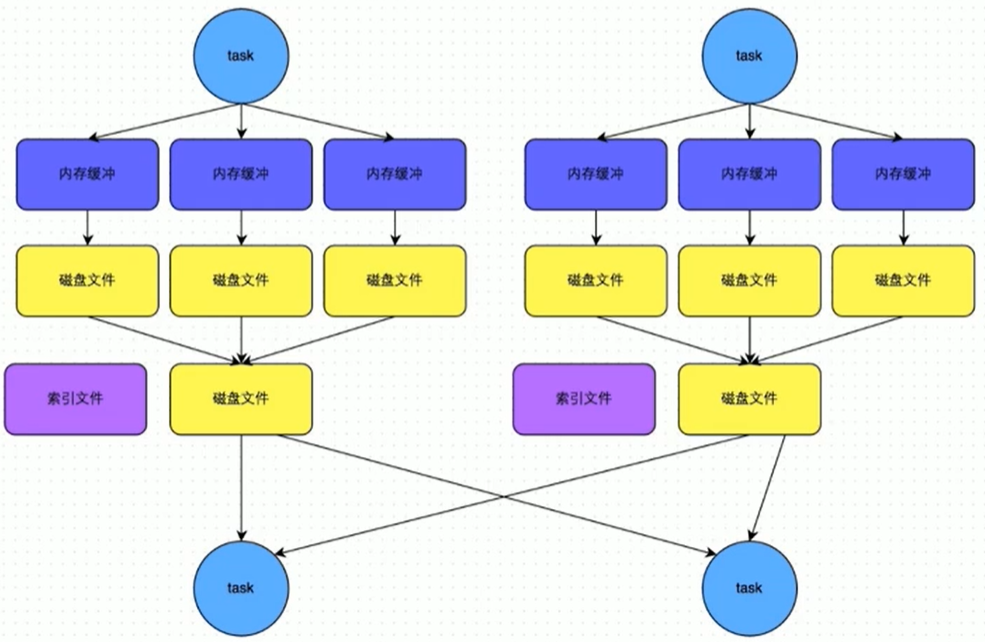
2.4.4 Bypass SortShuffle
- Bypass SortShuffle執行機制觸發條件
- shuffle map task 數量小於 spark.shuffle.sort.bypassMargeThreshold引數的值,預設為200
- 不是聚合類的shuffle運算元
2.5 Submit語法
spark-submit \
--class <main-calss> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... #其他 options
<application-jar> \
[application-arguments]
- --class:應用啟動類全類名(如:org.apache.spark.examples.SparkPi)
- --master:指定master地址,預設本機Local(本地一般使用Local[*],叢集一般使用yarn)
- --deploy-mode:是否釋出到驅動worker節點(引數:cluster),或者作為一個本地客戶端(引數:client),預設本地client
- --conf:任意Spark配置屬性,格式key=value,如包含空格,可以加引號"key=value"
- application-jar:打包好的應用程式jar,包含依賴,這個URL在叢集中全域性課件,如HDFS上的jar->hdfs://path;如linux上的jar->file://path 且所有節點路徑都需要包含這個jar
- application-arguments:給main()方法傳引數
- --executor-memory 1G:指定每個executor可用記憶體為1G
- --total-executor-cores 6:指定所有executor使用的cpu核數為6個
- --executor-cores 2:表示每個executor使用的cpu的核數2個
2.6 Local模式
Local模式就是在一臺計算機上執行Spark,通常用於開發中。(單機)
- Submit提交方式
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[*] \
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.2.0.jar 100

2.7 Standalone模式
構建一個由 Master + Slave 構成的Spark叢集,Spark執行在叢集中,只依賴Spark,不依賴別的元件(如:Yarn)。(獨立的Spark叢集)
#連結客戶端
spark-shell --master spark://cdh01.cm:7337
參考wordCount案例
- Standalone-Client流程圖
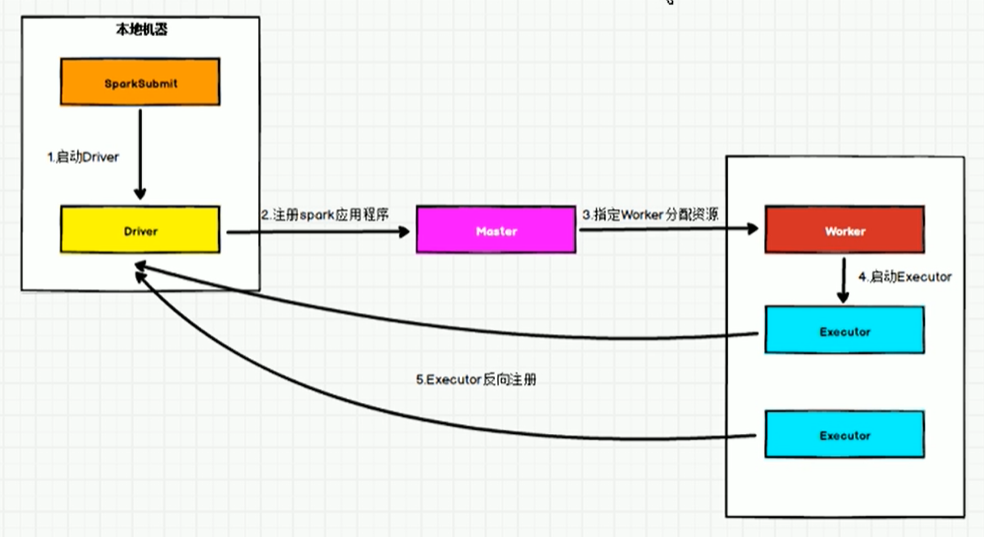
- Standalone-Cluster流程圖

2.8 Yarn模式
Spark客戶端可以直接連線Yarn,不需要構建Spark叢集。
有yarn-client和yarn-cluster兩種模式,主要區別在:Driver程式的執行節點不同。
yarn-client:Driver程式執行在客戶端,適用於互動、除錯,希望立即看見APP輸出
yarn-cluster:Driver程式執行在由ResourceManager啟動的ApplicationMaster上,適用於生產環境
- Yarn-Client流程圖

- Yarn-Cluster流程圖
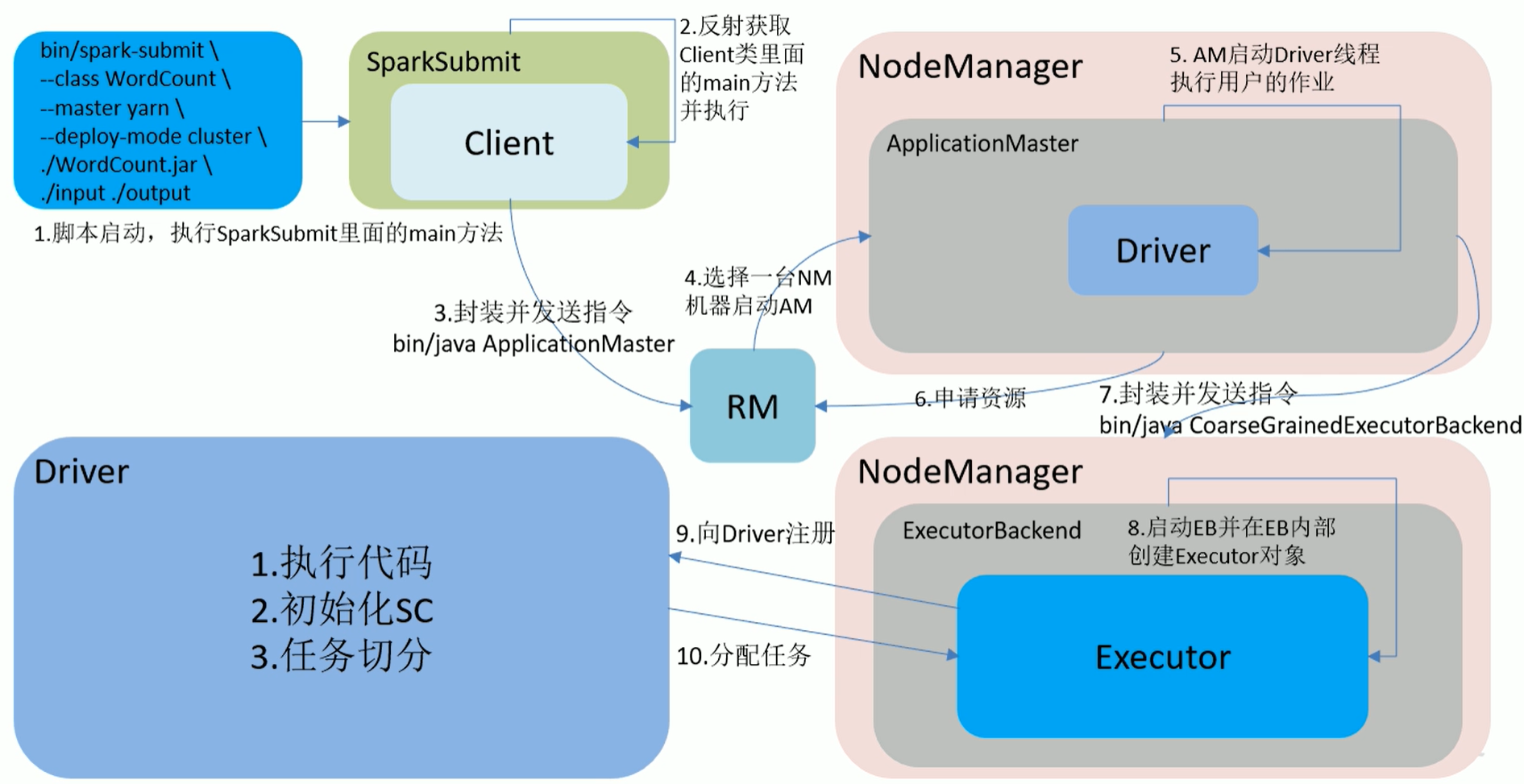
- 客戶端模式:Driver是在Client端,日誌結果可以直接在後臺看見
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.2.0.jar 100
- 叢集模式:Driver是在NodeManager端,日誌結果需要通過監控日誌檢視
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.2.0.jar 100
3 使用IDEA開發Spark
- pom.xml
<dependencies>
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<!-- Spark Core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Spark SQL -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Spark On Hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Hbase On Spark-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-spark</artifactId>
<version>2.1.0-cdh6.2.0</version>
</dependency>
<!-- Spark Streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Spark Streaming Kafka-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- Kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-tools</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-examples</artifactId>
<version>2.1.0</version>
</dependency>
<!--mysql依賴的jar包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<build>
<plugins>
<!-- 在maven專案中既有java又有scala程式碼時配置 maven-scala-plugin 外掛打包時可以將兩類程式碼一起打包 -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<!-- MAVEN 編譯使用的JDK版本 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase><!--繫結到package生命週期階段-->
<goals>
<goal>single</goal><!--只執行一次-->
</goals>
</execution>
</executions>
<configuration>
<!--<finalName></finalName><!–主類入口–>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.10</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
-
WorkCount案例
- 在resources資料夾下,新建word.csv檔案
hello,spark hello,scala,hadoop hello,hdfs hello,spark,hadoop hello- WorkCount.scala
import org.apache.spark.{SparkConf, SparkContext} object WorkCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("WorkCount").setMaster("local[*]") val sc = new SparkContext(conf) val tuples: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource("word.csv").getPath) .flatMap(_.split(",")) .map((_, 1)) .reduceByKey(_ + _) .collect() tuples.foreach(println) } }結果:
(scala,1)
(hello,5)
(spark,2)
(hadoop,2)
(hdfs,1)
4 Spark Core
4.1 什麼是RDD
Resilient Distributed DataSet:彈性分散式資料集,是Spark中最基本資料抽象,可以理解為資料集合。
在程式碼中是一個抽象類,它代表一個彈性的、不可變的、可分割槽,裡面的元素可平行計算的集合。
4.2 RDD的五個主要特性
- 分割槽性
- 多個分割槽,分割槽可以看成是資料集的基本組成單位
- 對於RDD來說,每個分割槽都會被一個計算任務處理,並決定了平行計算的粒度。
- 使用者可以在建立RDD時,指定RDD的分割槽數,如果沒有指定,那麼採用預設值(程式所分配到的CPU Coure的數目)
- 每個分配的儲存是由BlockManager實現的,每個分割槽都會被邏輯對映成BlockManager的一個Block,而這個Block會被一個Task負責計算。
- 計算每個分割槽的函式
- Spark中RDD的計算是以分割槽為單位的,每個RDD都會實現compute函式以達到這個目的
- 依賴性
- RDD的每次轉換都會生成一個新的RDD,所以RDD之間會形成類似於流水線一樣的前後依賴關係,在部分分割槽資料丟失時,Spark可以通過這個依賴關係重新計算丟失的分割槽資料,而不是對RDD的所有分割槽進行重新計算。
- 對儲存鍵值對的RDD,還有一個可選的分割槽器
- 只有對key-value的RDD,才會有Partitioner,非key-value的RDD的Rartitioner的值是None
- Partitioner不但決定了RDD的分割槽數量,也決定了parent RDD Shuffle輸出時的分割槽數量
- 預設是HashPartitioner,還有RangePartition,自定義分割槽
- 儲存每個分割槽優先位置的列表(本地計算性)
- 比如對於一個HDFS檔案來說,這個列表儲存的就是每個Partition所在檔案快的位置,按照“移動資料不如移動計算”的理念,Spark在進行任務排程的時候,會盡可能地將計算任務分配到其所要處理資料塊的儲存位置。
4.3 Transformation和Action運算元
在Spark中,Transformation運算元(也稱轉換運算元),在沒有Action運算元(也稱行動運算元)去觸發的時候,是不會執行的,可以理解為懶運算元,而Action運算元可以理解為觸發運算元,常用Action運算元如下:
- redece:通過函式聚集RDD的所有元素,先聚合分割槽內的資料,在聚合分割槽間的資料(預聚合)
- collect:以陣列的形式返回RDD中的所有元素,所有資料都會被拉到Driver端,記憶體開銷很大,所以慎用
- count:返回RDD中元素個數
- take:返回RDD中前N個元素組成的陣列
- first:返回RDD中的第一個元素,類似於tack(1)
- takeOrdered:返回排序後的前N個元素,預設升序,資料也會拉到Driver端
- aggregate:分割槽內聚合後,在分割槽間聚合
- fold:aggregate簡化操作,如果分割槽內和分割槽間演算法一樣,則可以使用
- saveAsTextFile:將資料集的元素以textFile的形式儲存到HDFS檔案系統或者其他檔案系統,對每個元素,Spark都會呼叫toString方法轉換為文字
- saveAsSequenceFile:將資料集的元素以Hadoop SquenceFile的形式儲存到指定目錄下,可以是HDFS或者其他檔案系統
- saveAsObjectFile:將RDD中的元素序列化成物件,儲存到檔案中
- countByKey:針對k-v型別RDD,返回一個Map(Key,count),可以用來檢視資料是否傾斜
- foreach:針對RDD中的每一個元素都執行一次函式,每個函式實在Executor上執行的
常用Transformation運算元如下:
- map:輸入變換函式應用於RDD中所有元素,轉換其型別
- mapPartitions:輸入變換函式應用於每個分割槽中所有元素
- mapPartitionsWithIndex:輸入變換函式應用於每個分割槽中所有元素,帶有分割槽號
- filter:過濾運算元
- flatMap:扁平化運算元
- sample:抽樣運算元
- union:並集運算元
- intersection:交集運算元
- distinct:去重運算元
- groupByKey:根據Key分組運算元
- reduceByKey:根據Key聚合運算元
- aggregateByKey:根據Key聚合運算元
- sortByKey:根據Key排序運算元
- join:連結運算元
- coalesce:壓縮分割槽運算元
- repartition:重分割槽運算元
4.4 RDD的建立
4.4.1 從集合中建立
object Demo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WorkCount").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* 通過parallelize方法傳入序列得到RDD
* 傳入分割槽數為1,結果為1 2 3 4 5 6 7 8 9 10
* 傳入分割槽數大於1,結果順序不定,因為資料被打散在2個分割槽裡
* */
val rdd: RDD[Int] = sc.parallelize(1.to(10), 1)
rdd.foreach(x => print(x + "\t"))
}
}
4.4.2 從外部儲存建立RDD
- 讀取textFile
WordCount案例介紹了此種用法
- 讀取Json檔案
在idea中,resources目錄下建立word.json檔案
{"name": "zhangsa"}
{"name": "lisi", "age": 30}
{"name": "wangwu"}
["aa","bb"]
object Demo0 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("json").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.textFile(this.getClass().getClassLoader.getResource("word.json").getPath)
val rdd2: RDD[Option[Any]] = rdd1.map(JSON.parseFull(_))
rdd2.foreach(println)
/**
* Some(Map(name -> zhangsa))
* Some(Map(name -> wangwu))
* Some(List(aa, bb))
* Some(Map(name -> lisi, age -> 30.0))
* */
}
}
- 讀取Object物件檔案
object Demo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("object").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1,2,3,4,5))
// rdd1.saveAsObjectFile("hdfs://cdh01.cm/test")
val rdd2: RDD[Nothing] = sc.objectFile("hdfs://cdh01.cm/test")
rdd2.foreach(println)
/**
* 2
* 5
* 1
* 4
* 3
* */
}
}
4.4.3 從其他RDD轉換得到新的RDD
- 根據RDD的資料型別的不同,整體分為2種RDD:Value型別,Key-Value型別(二維元組)
map()返回一個新的RDD,該RDD是由原RDD的每個元素經過函式轉換後的值組成,主要作用就是轉換結構。(不存在shuffle)
- 案例一:
object Demo2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("map").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* map運算元,一共有多少元素就會執行多少次,和分割槽數無關
**/
val rdd: RDD[Int] = sc.parallelize(1.to(10), 1)
val mapRdd: RDD[Int] = rdd.map(x => {
println("執行") //一共被執行10次
x * 2
})
val result: Array[Int] = mapRdd.collect()
result.foreach(x => print(x + "\t")) //2 4 6 8 10 12 14 16 18 20
}
}
- 案例二:
object demo3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapPartitions").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* mapPartitions運算元,一個分割槽內處理,幾個分割槽就執行幾次,優於map函式
**/
val rdd: RDD[Int] = sc.parallelize(1.to(10), 2)
val mapRdd: RDD[Int] = rdd.mapPartitions(it => {
println("執行") //分割槽2次,共列印2次
it.map(x => x * 2)
})
val result: Array[Int] = mapRdd.collect()
result.foreach(x => print(x + "\t")) //2 4 6 8 10 12 14 16 18 20
}
}
- 案例三:
object Demo4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapPartitionsWithIndex").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* mapPartitionsWithIndex運算元,一個分割槽內處理,幾個分割槽就執行幾次,返回帶有分割槽號的結果集
**/
val rdd: RDD[Int] = sc.parallelize(1.to(10), 2)
val value: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex((index, it) => it.map((index, _)))
val result: Array[(Int, Int)] = value.collect()
result.foreach(x => print(x + "\t")) //(0,1) (0,2) (0,3) (0,4) (0,5) (1,6) (1,7) (1,8) (1,9) (1,10)
}
}
4.5 flatMap
扁平化(不存在shuffle)
object Demo5 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("flatMap").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[(String, Int)] = sc.parallelize(Array(("A", 1), ("B", 2), ("C", 3)))
val map_result: RDD[String] = rdd.map(ele => ele._1 + ele._2)
val flatMap_result: RDD[Char] = rdd.flatMap(ele => ele._1 + ele._2)
/**
* C3
* A1
* B2
**/
map_result.foreach(println)
/**
* B
* A
* C
* 1
* 2
* 3
**/
flatMap_result.foreach(println)
}
}
4.6 glom
將每一個分割槽的元素合併成一個數組,形成新的RDD型別:RDD[Array[T]] (不存在shuffle)
object Demo6 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("glom").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10), 3)
val result: RDD[Array[Int]] = rdd.glom()
/**
* 1,2,3
* 7,8,9,10
* 4,5,6
* */
result.foreach(x=>{
println(x.toList.mkString(","))
})
}
}
4.7 groupBy
根據條件函式分組(存在shuffle)
object Demo7 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("groupBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10))
val result1: RDD[(Int, Iterable[Int])] = rdd.groupBy(x => x % 2)
val result2: RDD[(Boolean, Iterable[Int])] = rdd.groupBy(x => x % 2 == 0)
/**
* (0,CompactBuffer(2, 4, 6, 8, 10))
* (1,CompactBuffer(1, 3, 5, 7, 9))
**/
result1.foreach(println)
/**
* (true,CompactBuffer(2, 4, 6, 8, 10))
* (false,CompactBuffer(1, 3, 5, 7, 9))
**/
result2.foreach(println)
}
}
4.8 filter
過濾(不存在shuffle)
object Demo8 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("filter").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10))
val result: RDD[Int] = rdd.filter(x => x % 2 == 0)
result.foreach(x => print(x + "\t")) //6 10 8 4 2
}
}
4.9 sample
sample(withReplacement,fraction,seed)抽樣,常用在解決定位大key問題
- 以指定的隨機種子隨機抽樣出比例為fraction的資料(抽取到的數量是size*fraction),注意:得到的結果並不能保證準確的比例,也就是說fraction只決定了這個數被選中的比率,並不是從資料中抽出多少百分比的資料,決定的不是個數,而是比率。
- withReplacement表示抽出的資料是否放回,true為有放回抽樣,flase為無放回抽樣,放回表示資料有可能會被重複抽取到,false則不可能重複抽取到,如果為false則fraction必須在[0,1]內,是true則大於0即可。
- seed用於指定隨機數生成器種子,一般預設的,或者傳入當前的時間戳,(如果傳入定值,每次取出結果一樣)
object Demo9 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sample").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10))
/**
* 不放回抽樣
* 從結果中可以看出,抽出結果沒有重複
* */
val result1: RDD[Int] = rdd.sample(false,0.5)
result1.foreach(println)
/**
* 放回抽樣
* 從結果中可以看出,抽出結果有重複
* */
val result2: RDD[Int] = rdd.sample(true,2)
result2.foreach(println)
}
}
4.10 distinct
distinct([numTasks])去重,引數表示任務數量,預設值和分割槽數保持一致(不存在shuffle)
object Demo10 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("distinct").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(Array(1,2,3,4,2,3,4,3,4,5))
val result: RDD[Int] = rdd.distinct(2)
result.foreach(println)
}
}
4.11 coalesce
coalesce(numPatitions)縮減,縮減分割槽到指定數量,用於大資料集過濾後,提高小資料集的執行效率,只能減不能加。(不存在shuffle)
object Demo11 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("coalesce").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10),5)
println(rdd.partitions.length) //5
val result: RDD[Int] = rdd.coalesce(2)
println(result.partitions.length) //2
}
}
4.12 repartition
repartition(numPatitions)更改分割槽,更改分割槽到指定數量,可加可減,但是減少還是使用coalesce,將這個理解為增加。(存在shuffle)
object Demo12 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("repartition").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1.to(10),2)
println(rdd.partitions.length) //2
val result: RDD[Int] = rdd.repartition(5)
println(result.partitions.length) //5
}
}
4.13 sortBy
排序(存在shuffle)
object Demo13 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sortBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(Array(4, 2, 3, 1, 5), 1)
val result1: RDD[Int] = rdd.sortBy(x => x, false)
result1.foreach(x => print(x + "\t")) //5 4 3 2 1
val result2: RDD[Int] = rdd.sortBy(x => x, true)
result2.foreach(x => print(x + "\t")) //1 2 3 4 5
}
}
4.14 RDD與RDD互交
- 並集:union
- 差集:subtract
- 交集:intersection
- 笛卡爾積:cartesian
- 拉鍊:zip
object Demo14 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD AND RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(1.to(5))
val rdd2: RDD[Int] = sc.parallelize(3.to(8))
//並集
rdd1.union(rdd2).collect().foreach(x => print(x + "\t")) //1 2 3 4 5 3 4 5 6 7 8
//差集
rdd1.subtract(rdd2).collect().foreach(x => print(x + "\t")) //1 2
//交集
rdd1.intersection(rdd2).collect().foreach(x => print(x + "\t")) //3 4 5\
//笛卡爾積
/*(1,3) (1,4) (1,5) (1,6) (1,7) (1,8)
(2,3) (2,4) (2,5) (2,6) (2,7) (2,8)
(3,3) (3,4) (3,5) (3,6) (3,7) (3,8)
(4,3) (4,4) (4,5) (4,6) (4,7) (4,8)
(5,3) (5,4) (5,5) (5,6) (5,7) (5,8)*/
rdd1.cartesian(rdd2).collect().foreach(x => print(x + "\t"))
//拉鍊:必須保證RDD分割槽元素數量相同
val rdd3: RDD[Int] = sc.parallelize(1.to(5))
val rdd4: RDD[Int] = sc.parallelize(2.to(6))
rdd3.zip(rdd4).collect().foreach(x => print(x + "\t")) //(1,2) (2,3) (3,4) (4,5) (5,6)
}
}
4.15 k-v型別 partitionBy
大多數Spark運算元都可以用在任意型別的RDD上,但是有一些比較特殊的操作只能用在key-value型別的RDD上
使用HashPartitioner分割槽器
object Demo15 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
println(rdd2.partitions.length) //1
println(rdd2.partitioner) //None
val rdd3: RDD[(String, Int)] = rdd2.partitionBy(new HashPartitioner(2))
println(rdd3.partitions.length) //2
println(rdd3.partitioner) //Some(org.apache.spark.HashPartitioner@2)
val result: RDD[(Int, (String, Int))] = rdd3.mapPartitionsWithIndex((index, it) => {
it.map(x => (index, (x._1, x._2)))
})
result.foreach(println)
/**
* (1,(spark,1))
* (0,(hello,1))
* (0,(hadooop,1))
* (0,(hello,1))
**/
}
}
自定義分割槽器
object Demo16 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
println(rdd2.partitions.length) //1
println(rdd2.partitioner) //None
val rdd3: RDD[(String, Int)] = rdd2.partitionBy(new MyPatitioner(2))
println(rdd3.partitions.length) //2
println(rdd3.partitioner) //Some(com.test.sparkcore.MyPatitioner@769a58e5)
val result: RDD[(Int, (String, Int))] = rdd3.mapPartitionsWithIndex((index, it) => {
it.map(x => (index, (x._1, x._2)))
})
result.foreach(println)
/**
* (0,(hadooop,1))
* (1,(hello,1))
* (0,(spark,1))
* (1,(hello,1))
**/
}
}
class MyPatitioner(num: Int) extends Partitioner {
override def numPartitions: Int = num
override def getPartition(key: Any): Int = {
System.identityHashCode(key) % num.abs
}
}
4.16 k-v型別 reduceByKey
reduceByKey(V , V)=>V 根據key進行聚合,在shuffle之前會有combine(預聚合)操作
object Demo17 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("reduceByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.reduceByKey(_ + _)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.17 k-v型別 groupByKey
根據key進行分組,直接shuffle
object Demo18 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("groupByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Iterable[Int])] = rdd2.groupByKey()
result.foreach(x => print(x + "\t")) //(spark,CompactBuffer(1)) (hadooop,CompactBuffer(1)) (hello,CompactBuffer(1, 1))
result.map(x=>(x._1,x._2.size)).foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.18 k-v型別 aggrateByKey
aggrateByKey(zero : U)(( U , V )=>U , (U , U)=>U)
基於Key分組然後去聚合的操作,耗費資源太多,這時可以使用reduceByKey或aggrateByKey運算元去提高效能
aggrateByKey分割槽內聚合,後在進行shuffle聚合。
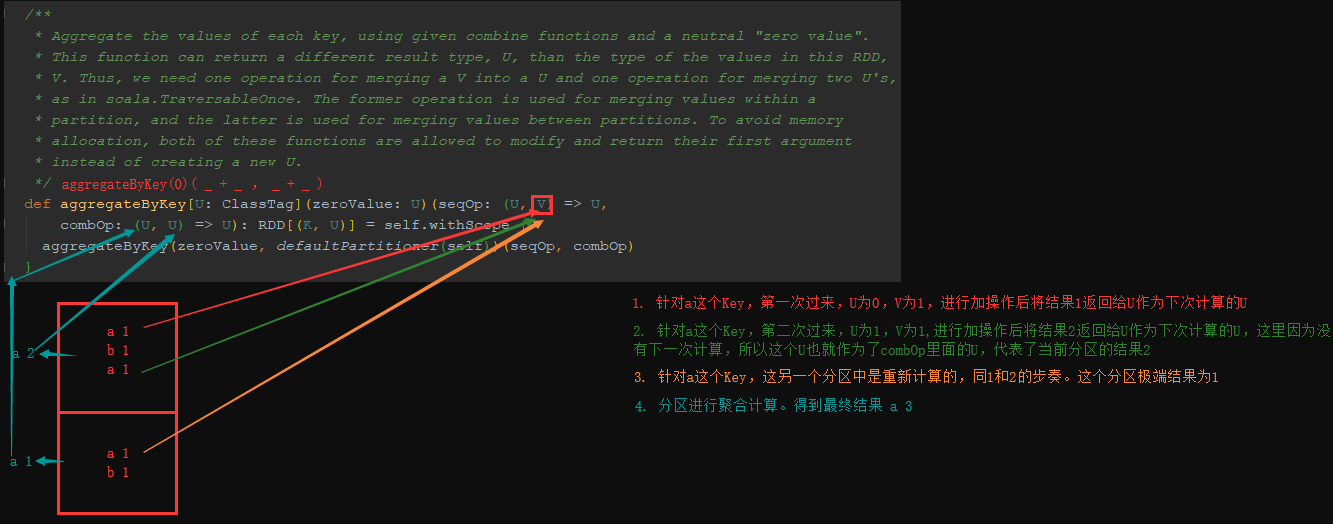
object Demo19 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("aggregateByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.aggregateByKey(0)(_ + _, _ + _)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.19 k-v型別 foldByKey
foldByKey(zero : V)((V , V)=>V) 摺疊計算,沒有aggrateByKey靈活,如果分割槽內和分割槽外聚合計算不一樣,則不行
object Demo20 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("foldByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.foldByKey(0)(_+_)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.20 k-v型別 combineByKey
combineByKey(V=>U,(U , V)=>U , (U , U)=>U) 根據Key組合計算
object Demo21 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("combineByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.combineByKey(v => v, (c: Int, v: Int) => c + v, (c1: Int, c2: Int) => c1 + c2)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
4.21 k-v型別 sortByKey
根據Key排序
object Demo22 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sortByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("ahello", "bhadooop", "chello", "dspark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
rdd2.sortByKey(false).foreach(x => print(x + "\t")) //(dspark,1) (chello,1) (bhadooop,1) (ahello,1)
}
}
4.22 k-v型別 mapValues
只對value操作的map轉換操作
object Demo23 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapValues").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
rdd2.mapValues(x => x + 1).foreach(x => print(x + "\t")) //(hello,2) (hadooop,2) (hello,2) (spark,2)
}
}
4.23 k-v型別 join
object Demo24 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("join").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(Array(("a",10),("b",10),("a",20),("d",10)))
val rdd2: RDD[(String, Int)] = sc.parallelize(Array(("a",30),("b",20),("c",10)))
//內連線 (a,(10,30)) (b,(10,20)) (a,(20,30))
rdd1.join(rdd2).foreach(x => print(x + "\t"))
//左連結(b,(10,Some(20))) (d,(10,None)) (a,(10,Some(30))) (a,(20,Some(30)))
rdd1.leftOuterJoin(rdd2).foreach(x => print(x + "\t"))
//右連結(c,(None,10)) (a,(Some(10),30)) (b,(Some(10),20)) (a,(Some(20),30))
rdd1.rightOuterJoin(rdd2).foreach(x => print(x + "\t"))
//全連結(b,(Some(10),Some(20))) (c,(None,Some(10))) (d,(Some(10),None)) (a,(Some(10),Some(30))) (a,(Some(20),Some(30)))
rdd1.fullOuterJoin(rdd2).foreach(x => print(x + "\t"))
}
}
4.24 k-v型別 cogroup
根據Key聚合RDD
object Demo25 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("cogroup").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(Array(("a",10),("b",10),("a",20),("d",10)))
val rdd2: RDD[(String, Int)] = sc.parallelize(Array(("a",30),("b",20),("c",10)))
/**
* (c,(CompactBuffer(),CompactBuffer(10)))
* (b,(CompactBuffer(10),CompactBuffer(20)))
* (a,(CompactBuffer(10, 20),CompactBuffer(30)))
* (d,(CompactBuffer(10),CompactBuffer()))
*/
rdd1.cogroup(rdd2).foreach(println)
}
}
4.25 keyo序列化
在分散式應用中,經常會進行IO操作,傳遞物件,而網路傳輸過程中就必須要序列化。
Java序列化可以序列化任何類,比較靈活,但是相當慢,並且序列化後物件的提交也比較大。
Spark出於效能考慮,在2.0以後,開始支援kryo序列化機制,速度是Serializable的10倍以上,當RDD在Shuffle資料的時候,簡單資料型別,簡單資料型別陣列,字串型別已經使用kryo來序列化。
object Demo26 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("keyo")
.setMaster("local[*]")
//替換預設序列化機制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//註冊需要使用的kryo序列化自定義類
.registerKryoClasses(Array(classOf[MySearcher]))
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hadoop yarn", "hadoop hdfs", "c"))
val rdd2: RDD[String] = MySearcher("hadoop").getMathcRddByQuery(rdd1)
rdd2.foreach(println)
}
}
case class MySearcher(val query: String) {
def getMathcRddByQuery(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}
4.26 依賴
-
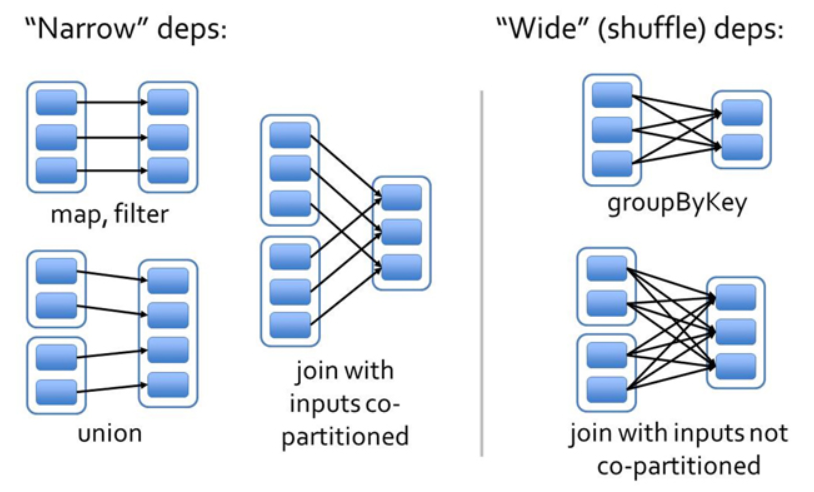
窄依賴:(不會shuffle)
- 如果RDD2由RDD1計算得到,則RDD2就是子RDD,RDD1就是父RDD
- 如果依賴關係在設計的時候就可以確定,而不需要考慮父RDD分割槽中的記錄,並且父RDD中的每個分割槽最多隻有一個子分割槽,這就叫窄依賴
- 父RDD的每個分割槽中的資料最多被一個子RDD的分割槽使用
-
寬依賴:(會shuffle)
- 寬依賴往往對應著shuffle操作,需要在執行過程中將同一個父RDD的分割槽傳入到不同的子RDD分割槽中。
- 對於寬依賴,重算的父RDD分割槽對應多個子RDD分割槽,這樣實際上父RDD 中只有一部分的資料是被用於恢復這個丟失的子RDD分割槽的,另一部分對應子RDD的其它未丟失分割槽,這就造成了多餘的計算;
- 寬依賴中子RDD分割槽通常來自多個父RDD分割槽,極端情況下,所有的父RDD分割槽都要進行重新計算。
4.27 持久化
object Demo27 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("cache").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("a", "b", "c"))
val rdd2: RDD[String] = rdd1.flatMap(x => {
println("執行flatMap操作")
x.split("")
})
val rdd3: RDD[(String, Int)] = rdd2.map((_, 1))
/** 持久化到記憶體 */
//rdd3.cache() //持久化到記憶體
/**
* 持久化到磁碟
* DISK_ONLY:持久化到磁碟
* DISK_ONLY_2:持久化到磁碟並且存一個副本(2個檔案)
* MEMORY_ONLY:持久化到記憶體
* MEMORY_ONLY_2:持久化到記憶體並且存一個副本(2個檔案)
* MEMORY_ONLY_SER:持久化到記憶體,並且序列化
* MEMORY_ONLY_SER_2:持久化到記憶體,並且序列化,還要存一個副本(2個檔案)
* MEMORY_AND_DISK:持久化到記憶體和磁碟
* MEMORY_AND_DISK_2:持久化到記憶體和磁碟並且存一個副本(2個檔案)
* MEMORY_AND_DISK_SER:持久化到記憶體和磁碟,並且序列化
* MEMORY_AND_DISK_SER_2:持久化到記憶體和磁碟,並且序列化,還要存一個副本(2個檔案)
* OFF_HEAP:持久化在堆外記憶體中,Spark自己管理的記憶體
* */
rdd3.persist(StorageLevel.DISK_ONLY) //持久化到磁碟
rdd3.collect.foreach(x => print(x + "\t"))
println("------------")
//輸出語句不會執行
rdd3.collect.foreach(x => print(x + "\t"))
}
}
4.28 checkpoint
持久化只是將資料儲存在BlockManager中,而RDD的Lineage是不變的,但是checkpoint執行完後,RDD已經沒有之前所謂的依賴了,而只是一個強行為其設定的checkpointRDD,RDD的Lineage改變了。
持久化的資料丟失可能性更大,磁碟、記憶體都有可能會存在資料丟失情況。但是checkpoint的資料通常是儲存在如HDFS等容錯、高可用的檔案系統,資料丟失可能性較小。
預設情況下,如果某個RDD沒有持久化,但是設定了checkpoint Job想要將RDD的資料寫入檔案系統,需要全部重新計算一次,再將計算出來的RDD資料checkpoint到檔案系統,所以,建議對checkpoint的RDD使用十九畫,這樣RDD只需要計算一次就可以了。
object Demo28 {
def main(args: Array[String]): Unit = {
//設定當前使用者
System.setProperty("HADOOP_USER_NAME", "Heaton")
val conf = new SparkConf().setAppName("checkpoint").setMaster("local[*]")
val sc = new SparkContext(conf)
//設定checkpoint目錄
sc.setCheckpointDir("hdfs://cdh01.cm:8020/test")
val rdd1: RDD[String] = sc.parallelize(Array("abc"))
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
/**
* 標記RDD2的checkpoint
* RDD2會被儲存到檔案中,並且會切斷到父RDD的引用,該持久化操作,必須在job執行之前呼叫
* 如果不進行持久化操作,那麼在儲存到檔案的時候需要重新計算
**/
rdd2.cache()
rdd2.collect.foreach(x => print(x + "\t"))
rdd2.collect.foreach(x => print(x + "\t"))
}
}
4.29 累加器
4.29.1 累加器問題丟擲
object Demo29 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
var a = 1
rdd1.foreach(x => {
a += 1
println("rdd: "+a)
})
println("-----")
println("main: "+a)
/**
* rdd: 2
* rdd: 2
* rdd: 3
* rdd: 3
* rdd: 4
* -----
* main: 1
* */
}
}
從上面可以看出,2個問題:
- 變數是在RDD分割槽中進行累加,並且2個RDD分割槽中的變數不同
- 最後並沒有main方法中的變數值改變
考慮到main方法中的a變數是在Driver端,而RDD分割槽又是在Excutor端進行計算,所以只是拿了一個Driver端的映象,而且不同步回Driver端
在實際開發中,我們需要進行這種累加,這時就用到了累加器
4.29.2 累加器案例
Spark提供了一些常用累加器,主要針對值型別
object Demo30 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc: util.LongAccumulator = sc.longAccumulator("acc")
rdd1.foreach(x => {
acc.add(1)
println("rdd: "+acc.value)
})
println("-----")
println("main: "+acc.count)
/**
* rdd: 1
* rdd: 1
* rdd: 2
* rdd: 2
* rdd: 3
* -----
* main: 5
* */
}
}
如上程式碼,我們發現累加器是分割槽內先累加,再分割槽間累加
4.29.3 自定義累加器
- 案例一:自定義Int累加器
object Demo31 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc = new MyAccumulator
//註冊累加器
sc.register(acc)
rdd1.foreach(x => {
acc.add(1)
println("rdd: " + acc.value)
})
println("-----")
println("main: " + acc.value)
/**
* rdd: 1
* rdd: 1
* rdd: 2
* rdd: 3
* rdd: 2
* -----
* main: 5
**/
}
}
class MyAccumulator extends AccumulatorV2[Int, Int] {
var sum: Int = 0
//判斷累加的值是不是空
override def isZero: Boolean = sum == 0
//如何把累加器copy到Executor
override def copy(): AccumulatorV2[Int, Int] = {
val accumulator = new MyAccumulator
accumulator.sum = sum
accumulator
}
//重置值
override def reset(): Unit = {
sum = 0
}
//分割槽內的累加
override def add(v: Int): Unit = {
sum += v
}
//分割槽間的累加,累加器最終的值
override def merge(other: AccumulatorV2[Int, Int]): Unit = {
other match {
case o: MyAccumulator => this.sum += o.sum
case _ =>
}
}
override def value: Int = this.sum
}
- 案例二:自定義map平均值累加器
object Demo32 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc = new MyAccumulator
//註冊累加器
sc.register(acc)
rdd1.foreach(x => {
acc.add(x)
})
println("main: " + acc.value)
/**main: Map(sum -> 15.0, count -> 17.0, avg -> 0.8823529411764706) */
}
}
class MyAccumulator extends AccumulatorV2[Int, Map[String, Double]] {
var map: Map[String, Double] = Map[String, Double]()
//判斷累加的值是不是空
override def isZero: Boolean = map.isEmpty
//如何把累加器copy到Executor
override def copy(): AccumulatorV2[Int, Map[String, Double]] = {
val accumulator = new MyAccumulator
accumulator.map ++= map
accumulator
}
//重置值
override def reset(): Unit = {
map = Map[String, Double]()
}
//分割槽內的累加
override def add(v: Int): Unit = {
map += "sum" -> (map.getOrElse("sum", 0d) + v)
map += "count" -> (map.getOrElse("sum", 0d) + 1)
}
//分割槽間的累加,累加器最終的值
override def merge(other: AccumulatorV2[Int, Map[String, Double]]): Unit = {
other match {
case o: MyAccumulator =>
this.map += "sum" -> (map.getOrElse("sum", 0d) + o.map.getOrElse("sum", 0d))
this.map += "count" -> (map.getOrElse("count", 0d) + o.map.getOrElse("count", 0d))
case _ =>
}
}
override def value: Map[String, Double] = {
map += "avg" -> map.getOrElse("sum", 0d) / map.getOrElse("count", 1d)
map
}
}
4.30 廣播變數
廣播變數在每個節點上儲存一個只讀的變數的快取,而不用給每個task來傳送一個copy
object Demo33 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.parallelize(Array("a", "b"))
val broadArr: Broadcast[Array[Int]] = sc.broadcast(Array(1, 2))
rdd.foreach(x => {
val value: Array[Int] = broadArr.value
println(value.toList)
})
/**
* List(1, 2)
* List(1, 2)
* */
}
}
5 Spark SQL
Spark SQL是Spark用於結構化資料處理的Spark模組。如:Mysql,Hbase,Hive
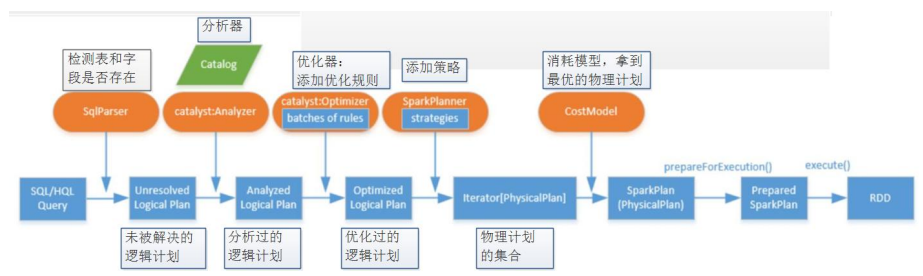
Spark SQL將SQL轉換成RDD,然後提交到叢集執行,執行效率非常快,而且使只會寫SQL的同學可以直接開發
Spark SQL提供了2個程式設計抽象,等同於Spark Core中的RDD,分別是:DataFrame,DataSet
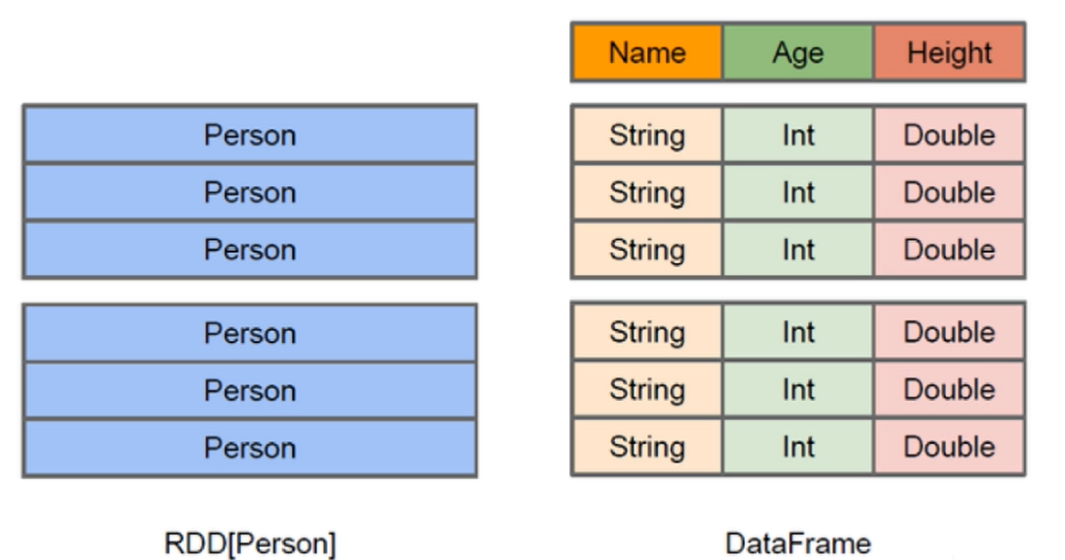
5.1 DataFrame
與RDD類似,DataFrame是一個分散式的資料容器
DataFrame更像是傳統資料庫的二維表格,除了資料以外,還記錄了資料的結構資訊(Schema)
與Hive類似,DataFrame也支援巢狀資料型別(Struct、Array、Map)
- 底層架構
- Predicate Pushdown 機制
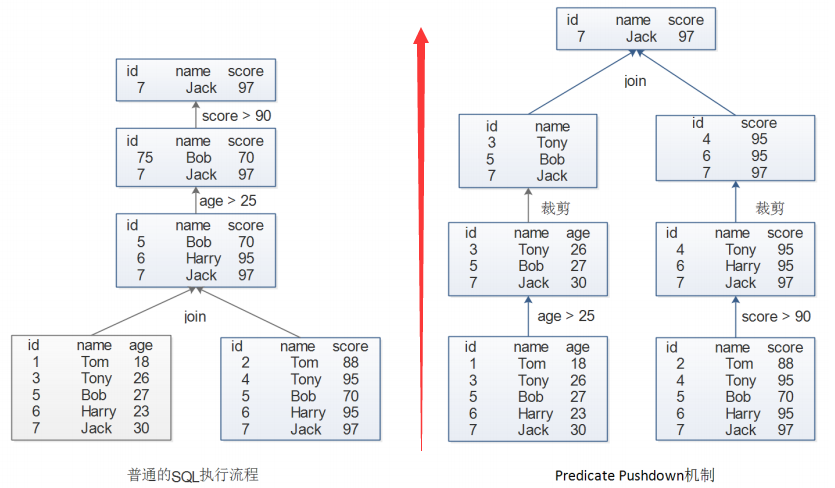
5.2 DataSet
DataSet是DataFrame的一個擴充套件,是SparkSQL1.6後新增的資料抽象,API友好
scala樣例類支援非常好,用樣例類在DataSet中定義資料結構資訊,樣例類中每個屬性的沒成直接對映到DataSet中的欄位名稱。
DataFrame是DataSet的特例,DataFrame=DataSet[Row],可以通過as方法將DataFrame轉換成DataSet,Row是一個型別,可以是Person、Animal,所有的表結構資訊都用Row來表示
DataFrame只知道欄位,不知道欄位型別,而DataSet不僅知道欄位,還知道型別。
DataSet具有強型別的資料集合,需要提供對應