
搜尋引擎中的倒排索引是什麼
阿新 • • 發佈:2020-03-11
[toc]

# 前言
我們平時在MySQL已經可以直接使用like查詢了,為啥還要一個倒排索引的東西?
我們用下面來說明下,假設有一本書,相應頁碼儲存的文章內容如下
頁碼 | 內容
-|-|
1| 生命在於運動 |
2| 運動是生命的源泉|
3| 日復一日地堅持練下去吧,只有活動適量才能保持訓練的熱情和提高運動的技能.——塞涅卡 |
4 | 活動是生活的基礎!——歌德 |
5| 人的健全,不但靠飲食,尤靠運動 |
6| 奧林匹克的格言是“更高,更快,更強” |
7| 身體的健康因靜止不動而破壞,因運動練習而長期保持.——蘇格拉底|
8| chenqionghe喜歡運動,繩命是如此的精彩,繩命是如此的輝煌|
書有N篇文章,要在一本書中找出有“運動”的文章,只能去一頁頁的翻書,看哪一頁有,書越厚,你找的時間越久(這其實也是MySQL中的全表掃描)
針對這樣的內容檢索場景,倒排索引就派上用場了
# 一、倒排索引的原理
倒排索引是怎麼提高檢索速度的,其實是相當於建立了關鍵詞目錄,記錄有哪些文件包含了某個單詞,如下
關鍵詞 | 頁碼 |
-|-|
運動| 1,2,5,8|
活動| 3,4|
生命| 1,2 |
chenqionghe|8|
當我們要搜尋找到有運動的文章時,會先去關鍵詞目錄找,找到了都在1,2,5,8這幾頁,然後直接把書翻到這些頁就能獲取到相應的內容了。
然後如果我們要搜尋“運動生命”,得先把這個內容分成運動和生命,再去目錄分別找,怎麼分詞,也是一種藝術。
# 二、倒排索引的應用
## Lucene
Lucene是目前最為流行的開放原始碼全文搜尋引擎工具包,隸屬於Apache基金會,由資深全文索引/檢索專家Doug Cutting所發起,並以其妻子的中間名作為專案的名稱。Lucene不是一個具有完整特徵的搜尋應用程式,而是一個專注於文字索引和搜尋的工具包,能夠為應用程式新增索引與搜尋能力。
## ElasticSearch
Elasticsearch是一個基於Lucene的搜尋伺服器。它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTful web介面。
## Solr
Solr是一個高效能,採用Java開發,基於Lucene的全文搜尋伺服器,封裝了很多Lucene細節,是一個有HTTP介面的基於Lucene的查詢伺服器,
## Sphinx
Sphinx是一款基於SQL的高效能全文檢索引擎,利用Sphinx我們可以完成比資料庫本身更專業的搜尋功能,而且可以有很多針對性的效能優化。
另外其實MySQL的的全文索引也是基於倒排索引的,可以參考[從零開始學習MySQL全文索引](https://www.cnblogs.com/chenqionghe/p/12364524.html)
# 三、倒排索引和大資料“三駕馬車”的故事
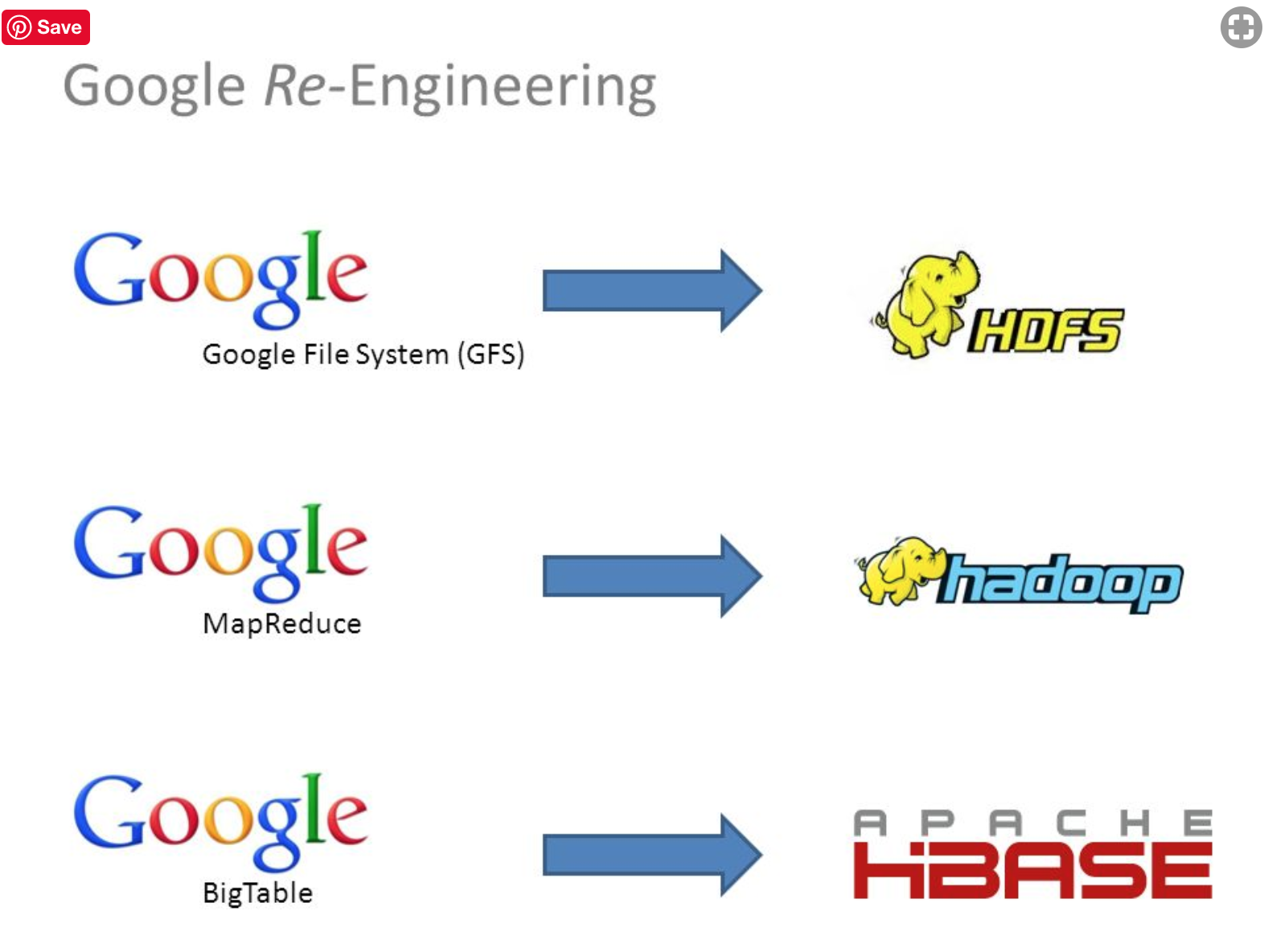
倒排索引是對網際網路內容的一種索引方法,例如我們使用百度或者谷歌,就是使用搜索詞搜尋到對應的網際網路文件。
說到大資料,我們想到的是“三駕馬車”,而這“三駕馬車”最早提出是在2003年。
## 1.海量內容儲存
為了構建倒排索引,谷歌需要儲存整個網際網路的內容,並存儲構建倒排索引所需要的內容,在以前的技術條件,世界上沒有現成的產品可以實現這種規模的倒排索引。所以,谷歌發明了谷歌檔案系統,基於大量的廉價計算機構建的海量儲存系統,對應“三駕馬車”的分散式儲存系統GFS。
## 2.海量資料計算框架
為了從這個GFS中讀取資料,需要一個牛逼的計算框架,這就是“三駕馬車”中的MapReduce。
## 3.超級大表
雖然兩駕馬車已經可以實現儲存網際網路這種海量資料,但是網際網路的內容變化太快,這種系統沒辦法做到增量更新。
這時候,第三駕馬車BigTable出來了,一個Key-Value儲存系統,可以儲存多個版本的值,對應的開源產品是HBase。
通過這“三駕馬車”,谷歌具備了儲存和分析海量資料的能力,再通過個性化廣告系統不斷地吸金,走在了時代的前沿。當時還沒有任何一個公司能在大資料這個領域趕上谷歌,谷歌這個技術也沒有開源。
這“三駕馬車”也是雲端計算機的重要的一大組成。
後來Hadoop出現了,出現了“三駕馬車”的開源產品,HDFS、MapReduce、HBase。各個公司開始基於Hadoop生態構建出了自己的大資料平臺,谷歌漸漸失去了在大資料時代的先發優勢。
# 四、倒排索引和排序演算法PageRank

有了倒排索引,我們可以快速得到了搜尋結果,但是怎麼決定搜尋的優先順序?這時候就用到了一種叫PageRank的演算法,計算機網頁的權重,按照權重進行排序,權重越高排得越靠前
關於PageRank的原理可以參考[從小白視角理解<資料探勘十大演算法>](https://www.cnblogs.com/chenqionghe/p/12301905.html#%E4%B8%80pagerank)
資料的搜尋與查詢是計算機軟體的核心演算法,對海量文件進行快速檢索,主要使用的就是倒排索引技術,大道至簡,就是這麼簡單,驚不驚喜,意不