
面試官說,你會堆排序嗎?會,那好手寫一個吧。
阿新 • • 發佈:2020-04-03
## 前言
最近明顯文章更新頻率降低了,那是因為我在惡補資料結構和演算法的相關知識,相當於是從零開始學習。
找了很多視訊和資料,最後發現 b 站尚矽谷的視訊教程還是相對不錯的,總共 195 集。每個小節都是按先概念、原理,然後程式碼實現的步驟講解。如果你也準備入門資料結構和演算法,我推薦可以看下這個系列教程。
昨天一天一下子肝了 40 多集,從樹的後半部分到圖的全部部分。可以看到,每一集其實時間也不算長,短的幾分鐘,長的也就半個小時。開 2 倍速看,倍兒爽。
話不多說,下面進入正題。
## 二叉堆介紹
我們知道,樹有很多種,最常用的就是二叉樹了。二叉樹又有滿二叉樹和完全二叉樹。而二叉堆,就是基於完全二叉樹的一種資料結構。它有以下兩個特性。
1. 首先它是一個完全二叉樹
2. 其次,堆中的任意一個父節點的值都大於等於(或小於)它的左右孩子節點。
因此,根據第二個特性,就把二叉堆分為大頂堆(或叫最大堆),和小頂堆(或叫最小堆)。
顧名思義,大頂堆,就是父節點大於等於左右孩子節點的堆,小頂堆就是父節點小於左右孩子節點的堆。
看一下大頂堆的示例圖,小頂堆類似,只不過是小值在上而已。
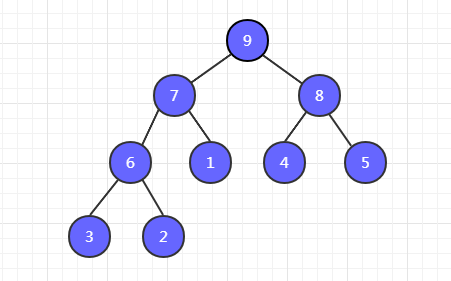
注意:大頂堆只保證父節點大於左右孩子節點的值,不需要保證左右孩子節點之間的大小順序。如圖中,7 的左子節點 6 比右子節點 1 大,而 8 的左子節點 4 卻比右子節點 5 小。(小頂堆同理)
## 構建二叉堆
二叉堆的定義我們知道了,那麼給你一個無序的完全二叉樹,怎麼把它構建成二叉堆呢?
我們以大頂堆為例。給定以下一個陣列,(完全二叉樹一般用陣列來儲存)
```
{4, 1, 9, 3, 7, 8, 5, 6, 2}
```
我們畫出它的初始狀態,然後分析怎麼一步一步構建成大頂堆。

由於大頂堆,父節點的值都大於左右孩子節點,所以樹的根節點肯定是所有節點中值最大的。因此,我們需要從樹的最後一層開始,逐漸的把大值向上調整(左右孩子節點中較大的節點和父節點交換),直到第一層。
其實,更具體的說,應該是從下面的非葉子節點開始調整。想一想,為什麼。
反向思考一下,如果從第一層開始調整的話,例如圖中就是 4 和 9 交換位置之後,你不能保證 9 就是所有節點的最大值(額,圖中的例子可能不是太好,正好是 9 最大)。如果下邊還有比 9 大的數字,你最終還是需要從下面向上遍歷調整。那麼,我還不如一開始就直接從下向上調整呢。
另外,為什麼從從最下面的非葉子節點(圖中節點 3 )開始。因為葉子節點的下面已經沒有子節點了,它只能和父節點比較,從葉子節點開始沒有意義。
第一步,以 3 為父節點開始,比較他們的子節點 6和 2 ,6最大,然後和 3 交換位置。
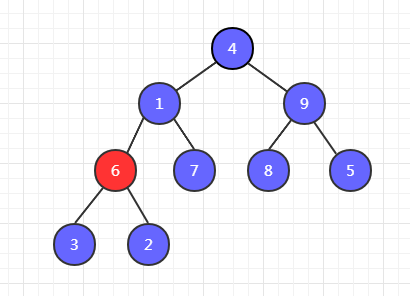
第二步,6 和 7 比較,7 最大,7 和 1 交換位置。
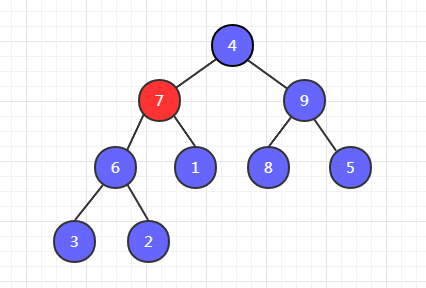
第三步,7 和 9 比較,9 最大,9 和 4 交換位置。
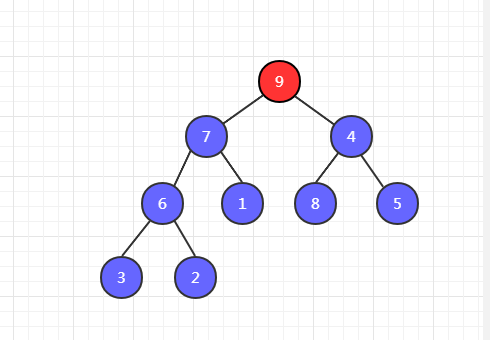
第四步,我們發現交換位置之後,4 下邊還有比它大的,因此還需要以 4 為父節點和它的左右子節點進行比較。發現 8 最大,然後 8 和 4 交換位置。
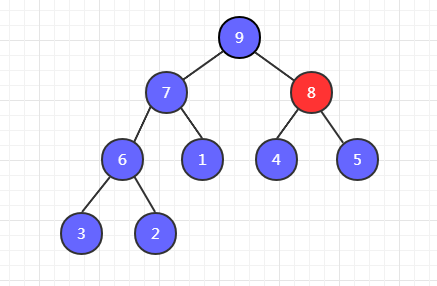
最終,實現了一個大頂堆的構建。下面以程式碼實現交換過程。
```
/**
* 調整為大頂堆
* @param arr 待調整的陣列
* @param parent 當前父節點的下標
* @param length 需要對多少個元素進行調整
*/
private static void adjustHeap(int[] arr, int parent, int length){
//臨時儲存父節點
int temp = arr[parent];
//左子節點的下標
int child = 2 * parent + 1;
//如果子節點的下標大於等於當前需要比較的元素個數,則結束迴圈
while(child < length){
//判斷左子節點和右子節點的大小,若右邊大,則把child定位到右邊
if(child + 1 < length && arr[child] < arr[child + 1]){
child ++;
}
//若child大於父節點,則交換位置,否則退出迴圈
if(arr[child] > temp){
//父子節點交換位置
arr[parent] = arr[child];
//因為交換位置之後,不能保證當前的子節點是它子樹的最大值,所以需要繼續向下比較,
//把當前子節點設定為下次迴圈的父節點,同時,找到它的左子節點,繼續下次迴圈
parent = child;
child = 2 * parent + 1;
}else{
//如果當前子節點小於等於父節點,則說明此時的父節點已經是最大值了,
//因此無需繼續迴圈
break;
}
}
//把當前節點值替換為最開始暫存的父節點值
arr[parent] = temp;
}
public static void main(String[] args) {
int[] arr = {4,1,9,3,7,8,5,6,2};
//構建一個大頂堆,從最下面的非葉子節點開始向上遍歷
for (int i = arr.length/2 - 1 ; i >= 0; i--) {
adjustHeap(arr,i,arr.length);
}
System.out.println(Arrays.toString(arr));
}
//列印結果: [9, 7, 8, 6, 1, 4, 5, 3, 2]。 和我們分析的結果一模一樣
```
在 while 迴圈中,if(arr[child] > temp) else的邏輯, 對應的就是圖中的第三步和第四步。即需要確保,交換後的子節點要比它下邊的孩子節點都大,不然需要繼續迴圈,調整位置。
## 堆排序
堆排序就是利用大頂堆或者小頂堆的特性來進行排序的。
它的基本思想就是:
1. 把當前陣列構建成一個大頂堆。
2. 此時,根節點肯定是所有節點中最大的值,讓它和末尾元素交換位置,則最後一個元素就是最大值。
3. 把剩餘的 n - 1個元素重新構建成一個大頂堆,就會得到 n-1 個元素中的最大值。重複執行此動作,就會把所有的元素調整為有序了。
**步驟:**
還是以上邊的陣列為例,看一下堆排序的過程。
一共有九個元素,把它調整為大頂堆,然後把堆頂元素 9 和末尾元素 2 交換位置。
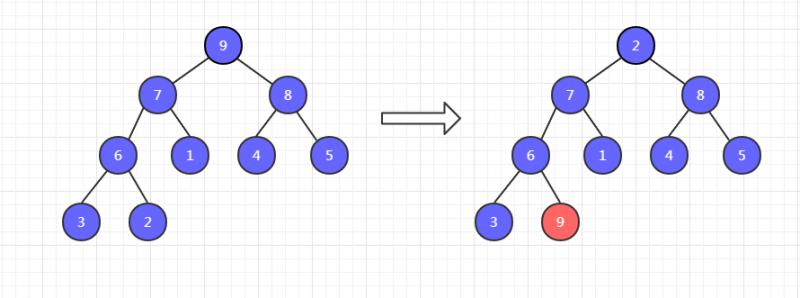
此時,9已經有序了,不需要調整。然後把剩餘八個元素調整為大頂堆,再把這八個元素的堆頂元素和末尾元素交換位置,如下,8 和 3 交換位置。
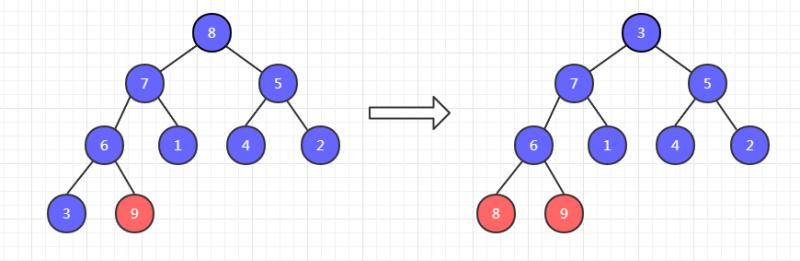
此時,8和 9 已經有序了,不需要調整。然後把剩餘七個元素調整為大頂堆,再把這七個元素的堆頂元素和末尾元素交換位置。如下, 7 和 2 交換位置。

以此類推,經過 n - 1 次迴圈調整,到了最後只剩下一個元素的時候,就不需要再比較了,因為它已經是最小值了。
看起來好像過程很複雜,但其實是非常高效的。沒有增刪,直接在原來的陣列上修改就可以。因為我們知道陣列的增刪是比較慢的,每次刪除,插入元素,都要移動陣列後邊的 n 個元素。此外,也不佔用額外的空間。
程式碼實現:
```
//堆排序,大頂堆,升序
private static void heapSort(int[] arr){
//構建一個大頂堆,從最下面的非葉子節點開始向上遍歷
for (int i = arr.length/2 - 1 ; i >= 0; i--) {
adjustHeap(arr,i,arr.length);
}
System.out.println(Arrays.toString(arr));
//迴圈執行以下操作:1.交換堆頂元素和末尾元素 2.重新調整為大頂堆
for (int i = arr.length - 1; i > 0; i--) {
//將堆頂最大的元素與末尾元素互換,則陣列中最後的元素變為最大值
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
//從堆頂開始重新調整結構,使之成為大頂堆
// i代表當前陣列需要調整的元素個數,是逐漸遞減的
adjustHeap(arr,0,i);
}
}
```
**時間複雜度和空間複雜度:**
堆排序,每次調整為大頂堆的時間複雜度為 O(logn),而 n 個元素,總共需要迴圈調整 n-1 次 ,所以堆排序的時間複雜度就是 O(nlogn)。它的數學推導比較複雜,感興趣的同學可以自己檢視相關資料。
由於沒有佔用額外的記憶體空間,因此,堆排序的空間複雜度為