
golang slice 原始碼解讀
本文從原始碼角度學習 golang slice 的建立、擴容,深拷貝的實現。
內部資料結構
slice 僅有三個欄位,其中array 是儲存資料的部分,len 欄位為長度,cap 為容量。
type slice struct {
array unsafe.Pointer // 資料部分
len int // 長度
cap int // 容量
}
通過下面程式碼可以輸出空slice 的大小:
package main import "fmt" import "unsafe" func main() { data := make([]int, 0, 3) // 24 len:8, cap:8, array:8 fmt.Println(unsafe.Sizeof(data)) // 我們通過指標的方式,拿到陣列內部結構的欄位值 ptr := unsafe.Pointer(&data) opt := (*[3]int)(ptr) // addr, 0, 3 fmt.Println(opt[0], opt[1], opt[2]) data = append(data, 123) fmt.Println(unsafe.Sizeof(data)) shallowCopy := data[:1] ptr1 := unsafe.Pointer(&shallowCopy) opt1 := (*[3]int)(ptr1) fmt.Println(opt1[0]) }
建立
建立一個slice,其實就是分配記憶體。cap, len 的設定在彙編中完成。

下面的程式碼主要是做了容量大小的判斷,以及記憶體的分配。
func makeslice(et *_type, len, cap int) unsafe.Pointer { // 獲取需要申請的記憶體大小 mem, overflow := math.MulUintptr(et.size, uintptr(cap)) if overflow || mem > maxAlloc || len < 0 || len > cap { mem, overflow := math.MulUintptr(et.size, uintptr(len)) if overflow || mem > maxAlloc || len < 0 { panicmakeslicelen() } panicmakeslicecap() } // 分配記憶體 // 小物件從當前P 的cache中空閒資料中分配 // 大的物件 (size > 32KB) 直接從heap中分配 // runtime/malloc.go return mallocgc(mem, et, true) }
append
對於不需要記憶體擴容的slice,直接資料拷貝即可。
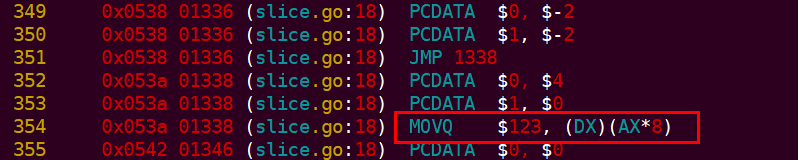
上面的DX 存放的就是array 指標,AX 是資料的偏移. 將 123 存入陣列。
而對於容量不夠的情況,就需要對slice 進行擴容。這也是slice 比較關心的地方。 (因為對於大slice,grow slice會影響到記憶體的分配和執行的效率)
func growslice(et *_type, old slice, cap int) slice { // 靜態分析, 記憶體掃描 // ... if cap < old.cap { panic(errorString("growslice: cap out of range")) } // 如果儲存的型別空間為0, 比如說 []struct{}, 資料為空,長度不為空 if et.size == 0 { return slice{unsafe.Pointer(&zerobase), old.len, cap} } newcap := old.cap doublecap := newcap + newcap if cap > doublecap { // 如果新容量大於原有容量的兩倍,則直接按照新增容量大小申請 newcap = cap } else { if old.len < 1024 { // 如果原有長度小於1024,那新容量是老容量的2倍 newcap = doublecap } else { // 按照原有容量的1/4 增加,直到滿足新容量的需要 for 0 < newcap && newcap < cap { newcap += newcap / 4 } // 通過校驗newcap 大於0檢查容量是否溢位。 if newcap <= 0 { newcap = cap } } } var overflow bool var lenmem, newlenmem, capmem uintptr // 為了加速計算(少用除法,乘法) // 對於不同的slice元素大小,選擇不同的計算方法 // 獲取需要申請的記憶體大小。 switch { case et.size == 1: lenmem = uintptr(old.len) newlenmem = uintptr(cap) capmem = roundupsize(uintptr(newcap)) overflow = uintptr(newcap) > maxAlloc newcap = int(capmem) case et.size == sys.PtrSize: lenmem = uintptr(old.len) * sys.PtrSize newlenmem = uintptr(cap) * sys.PtrSize capmem = roundupsize(uintptr(newcap) * sys.PtrSize) overflow = uintptr(newcap) > maxAlloc/sys.PtrSize newcap = int(capmem / sys.PtrSize) case isPowerOfTwo(et.size): // 二的倍數,用位移運算 var shift uintptr if sys.PtrSize == 8 { // Mask shift for better code generation. shift = uintptr(sys.Ctz64(uint64(et.size))) & 63 } else { shift = uintptr(sys.Ctz32(uint32(et.size))) & 31 } lenmem = uintptr(old.len) << shift newlenmem = uintptr(cap) << shift capmem = roundupsize(uintptr(newcap) << shift) overflow = uintptr(newcap) > (maxAlloc >> shift) newcap = int(capmem >> shift) default: // 其他用除法 lenmem = uintptr(old.len) * et.size newlenmem = uintptr(cap) * et.size capmem, overflow = math.MulUintptr(et.size, uintptr(newcap)) capmem = roundupsize(capmem) newcap = int(capmem / et.size) } // 判斷是否會溢位 if overflow || capmem > maxAlloc { panic(errorString("growslice: cap out of range")) } // 記憶體分配 var p unsafe.Pointer if et.kind&kindNoPointers != 0 { p = mallocgc(capmem, nil, false) // 清空不需要資料拷貝的部分記憶體 memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem) } else { // Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory. p = mallocgc(capmem, et, true) if writeBarrier.enabled { // gc 相關 // Only shade the pointers in old.array since we know the destination slice p // only contains nil pointers because it has been cleared during alloc. bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem) } } // 資料拷貝 memmove(p, old.array, lenmem) return slice{p, old.len, newcap} }
切片拷貝 (copy)
切片的淺拷貝
shallowCopy := data[:1]
ptr1 := unsafe.Pointer(&shallowCopy)
opt1 := (*[3]int)(ptr1)
fmt.Println(opt1[0])
下面是上述程式碼的彙編程式碼:
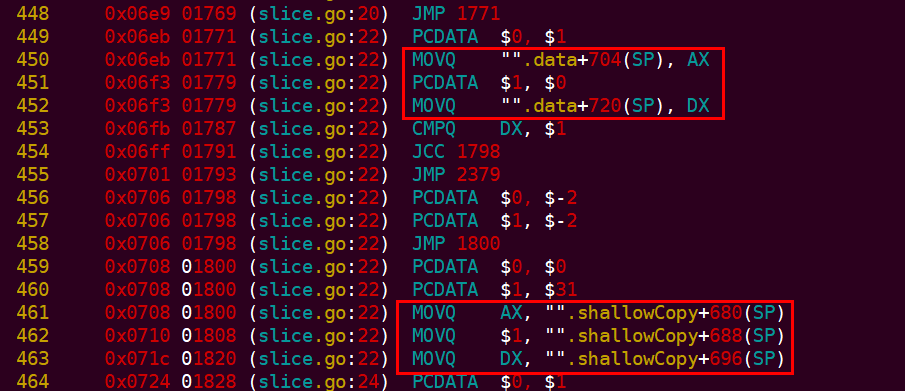
上面,先將 data 的成員資料拷貝到暫存器,然後從暫存器拷貝到shallowCopy的物件中。(注意到只是拷貝了指標而已, 所以是淺拷貝)
切片的深拷貝
深拷貝也比較簡單,只是做了一次記憶體的深拷貝。
func slicecopy(to, fm slice, width uintptr) int {
if fm.len == 0 || to.len == 0 {
return 0
}
n := fm.len
if to.len < n {
n = to.len
}
// 元素大小為0,則直接返回
if width == 0 {
return n
}
// 竟態分析和記憶體掃描
// ...
size := uintptr(n) * width
// 直接記憶體拷貝
if size == 1 { // common case worth about 2x to do here
*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
} else {
memmove(to.array, fm.array, size)
}
return n
}
// 字串slice的拷貝
func slicestringcopy(to []byte, fm string) int {
if len(fm) == 0 || len(to) == 0 {
return 0
}
n := len(fm)
if len(to) < n {
n = len(to)
}
// 竟態分析和記憶體掃描
// ...
memmove(unsafe.Pointer(&to[0]), stringStructOf(&fm).str, uintptr(n))
return n
}
其他
- 彙編的生成方法
go tool compile -N -S slice.go > slice.S
-
需要了解unsafe.Pointer 的使用
-
slice.go 位於 runtime/slice.go
-
上述程式碼使用 go1.12.5 版本
-
還有一點需要提醒, type 長度為0的物件。比如說 struct{} 型別。(所以,很多使用chan struct{} 做channel 的傳遞,節省記憶體)
package main
import "fmt"
import "unsafe"
func main() {
var data [100000]struct{}
var data1 [100000]int
// 0
fmt.Println(unsafe.Sizeof(data))
// 800000
fmt.Println(unsafe.Sizeof(data1))
}

相關推薦
golang slice 原始碼解讀
本文從原始碼角度學習 golang slice 的建立、擴容,深拷貝的實現。 內部資料結構 slice 僅有三個欄位,其中array 是儲存資料的部分,len 欄位為長度,cap 為容量。 type slice struct { array unsafe.Pointer // 資料部分 len
golang http server原始碼解讀
1. 初識 http 是典型的 C/S 架構,客戶端向服務端傳送請求(request),服務端做出應答(response)。 golang 的標準庫 net/http 提供了 http 程式設計有關的介面,封裝了內部TCP連線和報文解析的複雜瑣碎的細節,使用者只需要和
原始碼解讀 Golang 的 sync.Map 實現原理
簡介 Go 的內建 map 是不支援併發寫操作的,原因是 map 寫操作不是併發安全的,當你嘗試多個 Goroutine 操作同一個 map,會產生報錯:fatal error: concurrent map writes。 因此官方另外引入了 sync.Map 來滿足併發程式設計中的應用。 sync.Map
golang slice
end info 即使 inf clas lang ack 讀取 fmt golang 在for range一個slice時,會讀出其cap長度。在for的過程中,即使動態append該slice,最終for也會在第一次讀取的cap長度處停止。 package mai
golang bytes包解讀
int 保存 lan png ado vpd ddb true build golang中的bytes標準庫實現了對字節數組的各種操作,與strings標準庫功能基本類似。 功能列表:1、字節切片 處理函數 (1)、基本處理函數(2)、字節切片比較函數(3)、前後綴檢查函數
yolo v2 損失函式原始碼解讀
前提說明: 1, 關於 yolo 和 yolo v2 的詳細解釋請移步至如下兩個連結,或者直接看論文(我自己有想寫 yolo 的教程,但思前想後下面兩個連結中的文章質量實在是太好了_(:з」∠)_) yo
【React原始碼解讀】- 元件的實現
前言 react使用也有一段時間了,大家對這個框架褒獎有加,但是它究竟好在哪裡呢? 讓我們結合它的原始碼,探究一二!(當前原始碼為react16,讀者要對react有一定的瞭解) 回到最初 根據react官網上的例子,快速構建react專案 npx create-react-app
【1】pytorch torchvision原始碼解讀之Alexnet
最近開始學習一個新的深度學習框架PyTorch。 框架中有一個非常重要且好用的包:torchvision,顧名思義這個包主要是關於計算機視覺cv的。這個包主要由3個子包組成,分別是:torchvision.datasets、torchvision.models、torchvision.trans
Set介面_HashSet常用方法_JDK原始碼解讀
Set 介面繼承自 Collection ,Set 沒有新增方法,方法和 Collection 保持一致, Set 容器的特點:無序,不可重複,無序指Set 中的元素沒有索引,我們只能遍歷查詢,不重複指不允許加入重複的元素,更確切的說,新元素如果和Set 中某個元素通過 equals() 方
vux之x-input使用以及原始碼解讀
前言 近期專案中使用的vux中的input,以及使用自定義校驗規則和動態匹配錯誤提示,有時間記錄下自己的使用經歷和原始碼分析。希望大家多多指正,留言區發表自己寶貴的建議。 詳解 列舉官方文件中常用的幾個屬性的使用方法,程式碼如下 <group ref="group">
react-redux connect原始碼解讀
今天看了下react-redux的原始碼,主要來看下connect的方法 首先找到connect的入口檔案。在src/index.js下找到。對應connect資料夾下的connect.js檔案。 大致說下原始碼connect流程 connect.js對外暴露是通過ex
java原始碼解讀之HashMap
1:首先下載openjdk(http://pan.baidu.com/s/1dFMZXg1),把原始碼匯入eclipse,以便看到jdk原始碼 Windows-Prefe
以太坊原始碼解讀(5)BlockChain類的解析及NewBlockChain()分析
一、blockchain的資料結構 type BlockChain struct { chainConfig *params.ChainConfig // 初始化配置 cacheConfig *CacheConfig // 快取配置 db ethdb.Databas
以太坊原始碼解讀(4)Block類及其儲存
一、Block類 type Block struct { /******header*******/ header *Header /******header*******/ /******body*********/ uncle
Hystrix之@EnableCircuitBreaker原始碼解讀
Hystrix是一個供分散式系統使用,提供延遲和容錯功能,保證複雜的分佈系統在面臨不可避免的失敗時,仍能有其彈性。 比如系統中有很多服務,當某些服務不穩定的時候,使用這些服務的使用者執行緒將會阻塞,如果沒有隔離機制,系統隨時就有可能會掛掉,從而帶來很大的風險。 SpringCloud使用Hy
String的valueOf方法原始碼解讀
valueOf 中的祕密 String中的valueOf方法大致可以分為三種: String.valueOf(Object)、String.valueOf(char[])、String.valueOf(基本資料型別) 案例: Integer arg = null; St
nodejs---require() 原始碼解讀
2009年,Node.js 專案誕生,所有模組一律為 CommonJS 格式。 時至今日,Node.js 的模組倉庫 npmjs.com ,已經存放了15萬個模組,其中絕大部分都是 CommonJS 格式。 這種格式的核心就是 require
【go原始碼分析】go原始碼之slice原始碼分析
Go 語言切片是對陣列的抽象。 Go 陣列的長度不可改變,與陣列相比切片的長度是不固定的,可以追加元素,在追加時可能使切片的容量增大。 len() 和 cap() 函式 切片是可索引的,並且可以由 len() 方法獲取長度。
深度學習之---yolo,kmeans計算anchor框原始碼解讀
k-means原理 K-means演算法是很典型的基於距離的聚類演算法,採用距離作為相似性的評價指標,即認為兩個物件的距離越近,其相似度就越大。該演算法認為簇是由距離靠近的物件組成的,因此把得到緊湊且獨立的簇作為最終目標。 問題 K-Means演算法主要解決的問題如下圖所示。我們可以看到
以太坊原始碼解讀(6)blockchain區塊插入和校驗分析
以太坊blockchain的管理事務: 1、blockchain模組初始化 2、blockchain模組插入校驗分析 3、blockchain模組區塊鏈分叉處理 4、blockchian模組規範鏈更新 上一節分析了blockchain的初始化,這一節來分析blockchain區塊的插入和校驗