
有關 HashMap 面試會問的一切
阿新 • • 發佈:2020-06-20
## 前言
HashMap 是無論在工作還是面試中都非常常見常考的資料結構。
比如 Leetcode 第一題 Two Sum 的某種變種的最優解就是需要用到 HashMap 的,高頻考題 LRU Cache 是需要用到 LinkedHashMap 的。
HashMap 用起來很簡單,底層實現也不復雜,先來看幾道常見的面試題吧。相信大家多多少少都能回答上來一點,不清楚的地方就仔細閱讀本文啦~這篇文章帶你深挖到 HashMap 的老祖宗,保證吊打面試官
- == 和 equals() 的區別?
- 為什麼重寫 equals() 就必須要重寫 hashCode()?
- Hashtable, HashSet 和 HashMap 的區別和聯絡
- 處理 hash 衝突有哪些方法?Java 中用的哪一種?為什麼?另一種方法你在工作中用過嗎?在什麼情 況下用得多?
- 徒手實現一個 HashMap 吧
**本文分以下章節:**
- Set 和 Map 家族簡介
- HashMap 實現原理
- 關於 hashCode() 和 equals()
- 雜湊衝突詳解
- HashMap 基本操作
- 高頻面試考題分析
## Set 家族
在講 Map 之前,我們先來看看 Set。
集合的概念我們初中數學就學過了,就是裡面不能有重複元素,這裡也是一樣。
Set 在 Java 中是一個介面,可以看到它是 java.util 包中的一個集合框架類,具體的實現類有很多:
**其中比較常用的有三種:**
**HashSet**: 採用 Hashmap 的 key 來儲存元素,主要特點是無序的,基本操作都是 O(1) 的時間複雜度,很快。
**LinkedHashSet**: 這個是一個 HashSet + LinkedList 的結構,特點就是既擁有了 O(1) 的時間複雜度,又能夠保留插入的順序。
**TreeSet**: 採用紅黑樹結構,特點是可以有序,可以用自然排序或者自定義比較器來排序;缺點就是查詢速度沒有 HashSet 快。
**Map 家族**
Map 是一個鍵值對 (Key - Value pairs),其中 key 是不可以重複的,畢竟 set 中的 key 要存在這裡面。
那麼與 Set 相對應的,Map 也有這三個實現類:
**HashMap**: 與 HashSet 對應,也是無序的,O(1)。
**LinkedHashMap**: 這是一個「HashMap + 雙向連結串列」的結構,落腳點是 HashMap,所以既擁有 HashMap 的所有特性還能有順序。
**TreeMap**: 是有序的,本質是用二叉搜尋樹來實現的。
**HashMap 實現原理**
對於 HashMap 中的每個 key,首先通過 hash function 計算出一個 hash 值,這個hash值就代表了在 buckets 裡的編號,而 buckets 實際上是用陣列來實現的,所以把這個數值模上陣列的長度得到它在陣列的 index,就這樣把它放在了數組裡。
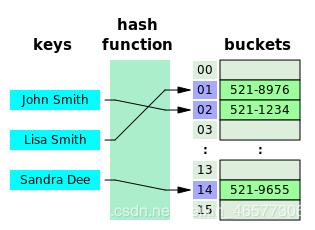
那麼這裡有幾個問題:
> 如果不同的元素算出了相同的雜湊值,那麼該怎麼存放呢?
答:這就是雜湊碰撞,即多個 key 對應了同一個桶。
> HashMap 中是如何保證元素的唯一性的呢?即相同的元素會不會算出不同的雜湊值呢?
答:通過 hashCode() 和 equals() 方法來保證元素的唯一性。
> 如果 pairs 太多,buckets 太少怎麼破?
答:Rehasing. 也就是碰撞太多的時候,會把陣列擴容至兩倍(預設)。所以這樣雖然 hash 值沒有變,但是因為陣列的長度變了,所以算出來的 index 就變了,就會被分配到不同的位置上了,就不用擠在一起了,小夥伴們我們江湖再見~
> 那什麼時候會 rehashing 呢?也就是怎麼衡量桶裡是不是足夠擁擠要擴容了呢?
答:load factor. 即用 pair 的數量除以 buckets 的數量,也就是平均每個桶裡裝幾對。Java 中預設值是 0.75f,如果超過了這個值就會 rehashing.
> 關於 hashCode() 和 equals()
如果 key 的 hashCode() 值相同,那麼有可能是要發生 hash collision 了,也有可能是真的遇到了另一個自己。那麼如何判斷呢?繼續用 equals() 來比較。
也就是說,
> hashCode() 決定了 key 放在這個桶裡的編號,也就是在數組裡的 index;
> equals() 是用來比較兩個 object 是否相同的。
那麼該如何回答這道**經典面試題**:
> 為什麼重寫 equals() 方法,一定要重寫 hashCode() 呢?
答:首先我們有一個假設:任何兩個 object 的 hashCode 都是不同的。
那麼在這個條件下,有兩個 object 是相等的,那如果不重寫 hashCode(),算出來的雜湊值都不一樣,就會去到不同的 buckets 了,就迷失在茫茫人海中了,再也無法相認,就和 equals() 條件矛盾了,證畢。
撒花~~