
使用Apache Hudi構建大規模、事務性資料湖
阿新 • • 發佈:2020-06-28
一個近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk

關於Nishith Agarwal更詳細的介紹,主要從事資料方面的工作,包括攝取標準化,資料湖原語等。

什麼是資料湖?資料湖是一個集中式的儲存,允許以任意規模儲存結構化和非結構化資料。你可以儲存原始資料,而不需要先轉化為結構化的資料,基於資料湖之上可以執行多種型別的分析,如dashboard、大資料處理的視覺化、實時分析、機器學習等。
接著看看對於構建PB級資料湖有哪些關鍵的要求

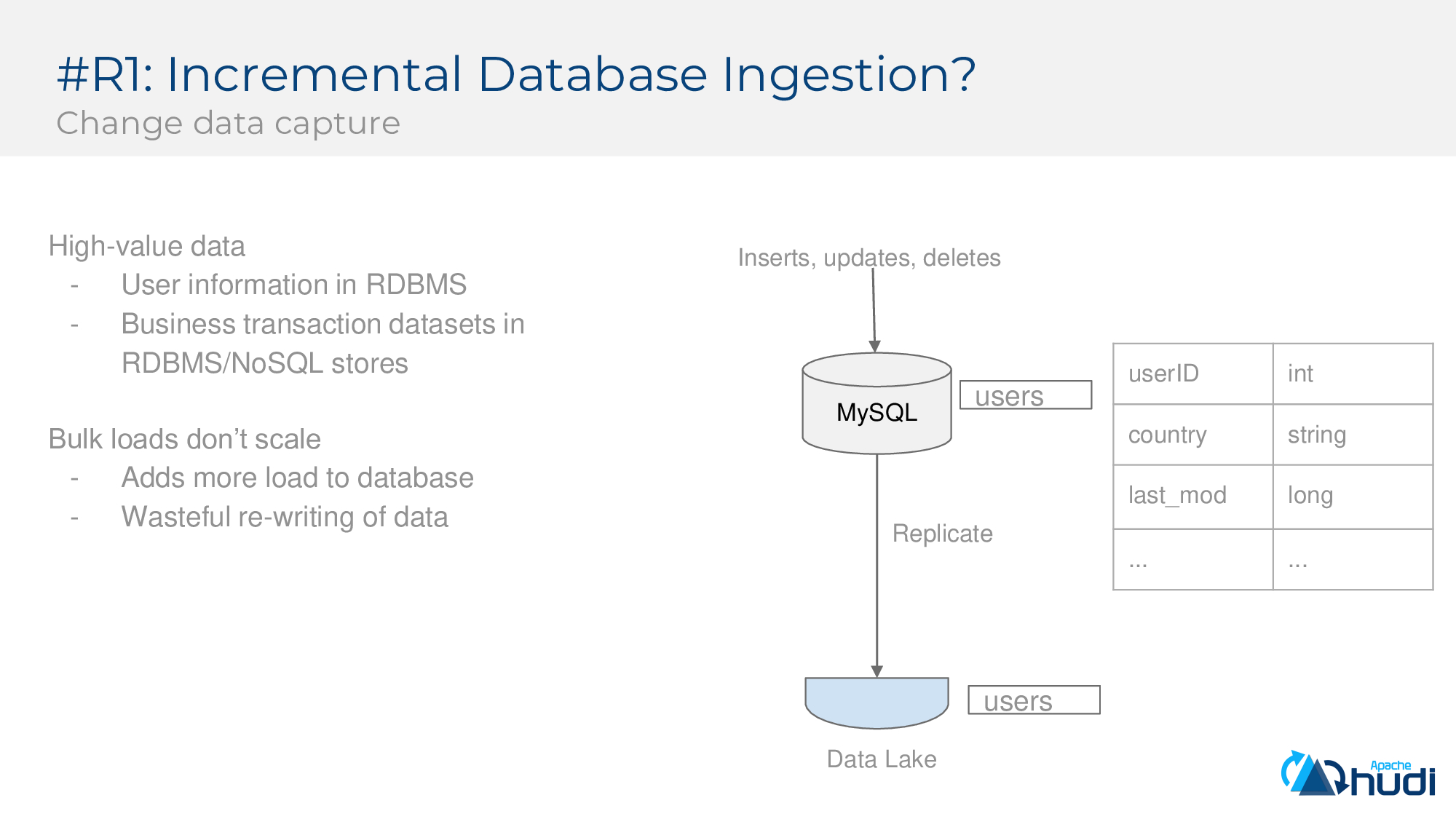
第一個要求:增量攝取(CDC)
企業中高價值的資料往往儲存在OLTP中,例如下圖中,users表包含使用者ID,國家/地區,修改時間和其他詳細資訊,但OLTP系統並未針對大批量分析進行優化,因此可能需要引入資料湖。同時一些企業採用備份線上資料庫的方式,並將其儲存到資料湖中的方法來攝取資料,但這種方式無法擴充套件,同時它給上游資料庫增加了沉重的負擔,也導致資料重寫的浪費,因此需要一種增量攝取資料的方法。
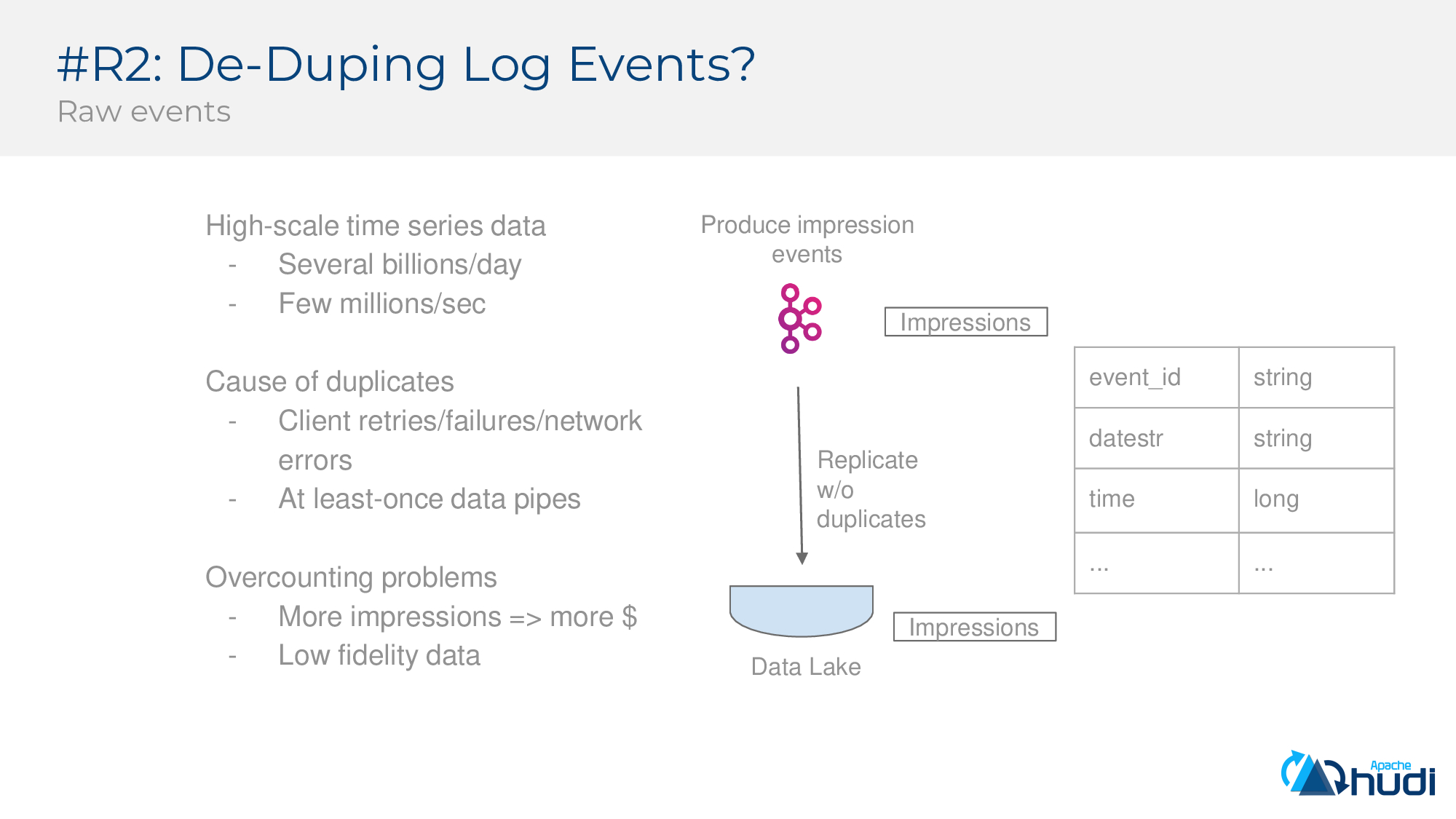
第二個要求:Log Event去重
考慮分析大規模時間序列資料的場景,這些事件被寫入資料管道,並且數量非常大,可達數十億,每秒可達百萬的量。但流中可能有重複項,可能是由於至少一次(atleast-once)保證,資料管道或客戶端失敗重試處理等傳送了重複的事件,如果不對日誌流進行重複處理,則對這些資料集進行的分析會有正確性問題。下圖是一個示例日誌事件流,其中事件ID為唯一鍵,帶有事件時間和其他有效負載。
第三個要求:儲存管理(自動管理DFS上檔案)
我們已經瞭解瞭如何攝取資料,那麼如何管理資料的儲存以擴充套件整個生態系統呢?其中小檔案是個大問題,它們會導致查詢引擎的開銷並增加檔案系統元資料的壓力。而如果寫入較大的檔案,則可能導致攝取延遲增加。一種常見的策略是先攝取小檔案,然後再進行合併,這種方法沒有標準,並且在某些情況下是非原子行為,會導致一致性問題。無論如何,當我們寫小檔案並且在合併這些檔案之前,查詢效能都會受到影響。

第四個要求:事務寫(ACID能力)
傳統資料湖在資料寫入時的事務性方面做得不太好,但隨著越來越多的業務關鍵處理流程移至資料湖,情況也在發生變化,我們需要一種機制來原子地釋出一批資料,即僅儲存有效資料,部分失敗必須回滾而不會損壞已有資料集。同時查詢的結果必須是可重複的,查詢端看不到任何部分提取的資料,任何提交的資料都必須可靠地寫入。Hudi提供了強大的ACID能力。

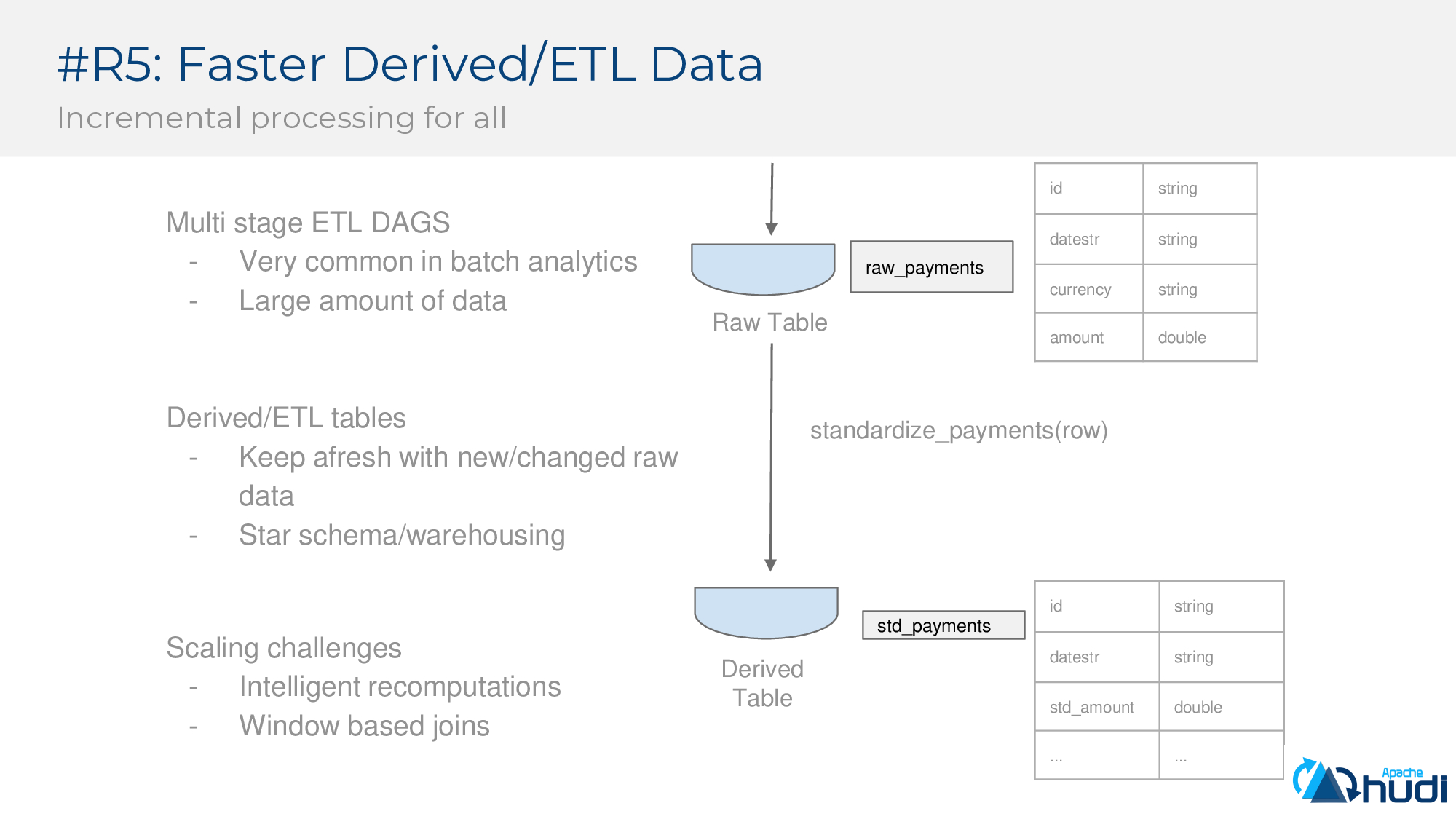
第五個要求:更快地派生/ETL資料(增量處理)
僅僅能快速攝取資料還不夠,我們還需要具有計算派生資料的能力,沒有這個能力,資料工程師通常會繞過原始表來構建其派生/ETL並最終破壞整個體系結構。下面示例中,我們看到原始付款表(貨幣未標準化)和發生貨幣轉換的派生表。
擴充套件此類資料管道時很有挑戰,如僅對變更進行計算,或者基於視窗的Join的挑戰。對基礎資料集進行大規模重新處理不太可能,這會浪費計算資源。需要在資料湖上進行抽象以支援對上游表中已更改的行(資料)進行智慧計算。
第六個要求:法律合規/資料刪除(更新&刪除)
近年來隨著新的資料保護法規生效,對資料保留有了嚴格的規定,需要刪除原始記錄,修復資料的正確性等,當需要在PB級資料湖中高效執行合規性時非常困難,如同大海撈針一般,需要高效的刪除,如進行索引,對掃描進行優化,將刪除記錄有效地傳播到下游表的機制。

要求回顧(彙總)
* 支援增量資料庫變更日誌攝取。
* 從日誌事件中刪除所有重複項。
* Data Lake必須為其資料集提供有效的儲存管理
* 支援事務寫入
* 必須提供嚴格的SLA,以確保原始表和派生表的資料新鮮度
* 任何資料合規性需求都需要得到有效的支援
* 支援唯一鍵約束
* 有效處理遲到的資料

有沒有能滿足上面所有需求的系統呢?接下來我們引入Apache Hudi,HUDI代表Hadoop Upserts Deletes and Incrementals。從高層次講,HUDI允許消費資料庫和kafa事件中的變更事件,也可以增量消費其他HUDI資料集中的變更事件,並將其提取到儲存在Hadoop相容,如HDFS和雲端儲存中。在讀取方面,它提供3種不同的檢視:增量檢視,快照檢視和實時檢視。
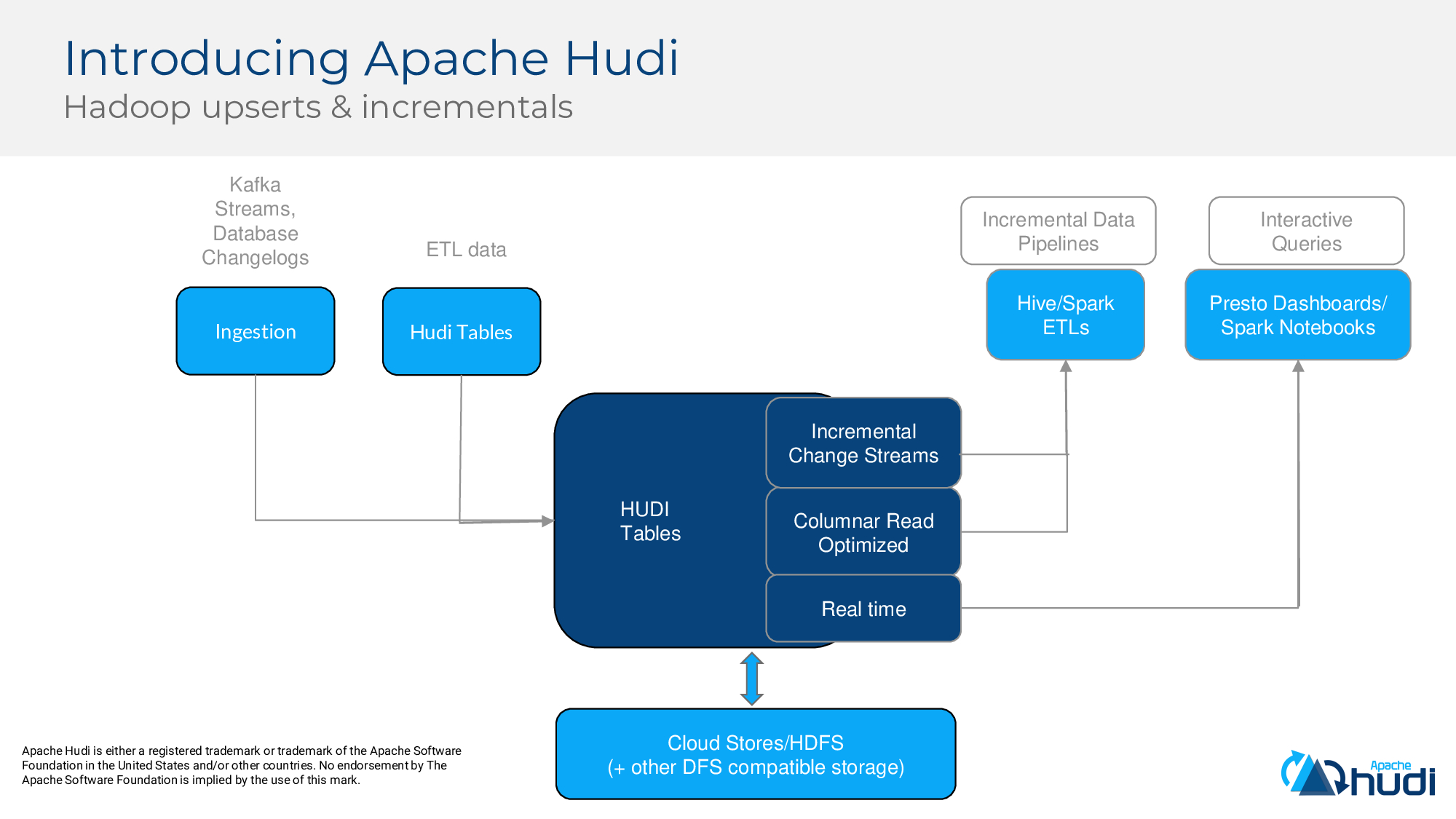
HUDI支援2種儲存格式:“寫時複製”和“讀時合併”。
首先來看看寫時複製。如下圖所示,HUDI管理了資料集,並嘗試將一批資料寫入資料湖,HUDI維護稱為“提交時間軸(commit timeline)”的內容,以跟蹤HUDI管理的資料集上發生的操作/更改,它在提交時間軸上標記了一個“inflight”檔案,表示操作已開始,HUDI會寫2個parquet檔案,然後將“inflight”檔案標記為已完成,這從原子上使該新資料寫入HUDI管理的資料集中,並可用於查詢。正如我們提到的,RO檢視優化查詢效能,並提供parquet的基本原始列存效能,無需增加任何額外成本。
現在假設需要更新另一批資料,HUDI在提交時間軸上標記了一個“inflight”檔案,並開始合併這些更新並重寫Parquet File1。此時,由於提交仍在進行中,因此使用者看不到正在寫入任何這些更新(這就是我們稱為“快照隔離”)。最終以原子方式釋出提交後,就可以查詢版本為C2的新合併的parquet檔案。
COW已經在Uber投入執行多年,大多數資料集都位於COW儲存型別上。

儘管COW服務於我們的大多數用例,但仍有一些因素值得我們關注。以Uber的行程表為例,可以想象這可能是一個很大的表,它在旅程的整個生命週期中獲取大量更新。每隔30分鐘,我們就會獲得一組新旅行以及對舊旅行的一些更新,在Hive上的旅行資料是按天劃分分割槽的,因此新旅行最終會在最新分割槽中寫入新檔案,而某些更新會在舊分割槽中寫入檔案。使用COW,我們只能重寫那些更新所涉及的檔案,並且能夠高效地更新。由於COW最終會重寫某些檔案,因此可以像合併和重寫該資料一樣快。在該用例中通常大於15分鐘。再來看另外一種情況,由於某些業務用例(例如GDPR),必須更新大量歷史行程,這些更新涉及過去幾個月資料,從而導致很高的寫入延遲,並一遍又一遍地重寫大量資料,寫放大也會導致大量的IO。若為工作負載分配的資源不足,可能就會嚴重損害攝取延遲。

在真實場景中,會將ETL連結在一起來構建資料管道,問題會變得更加複雜。
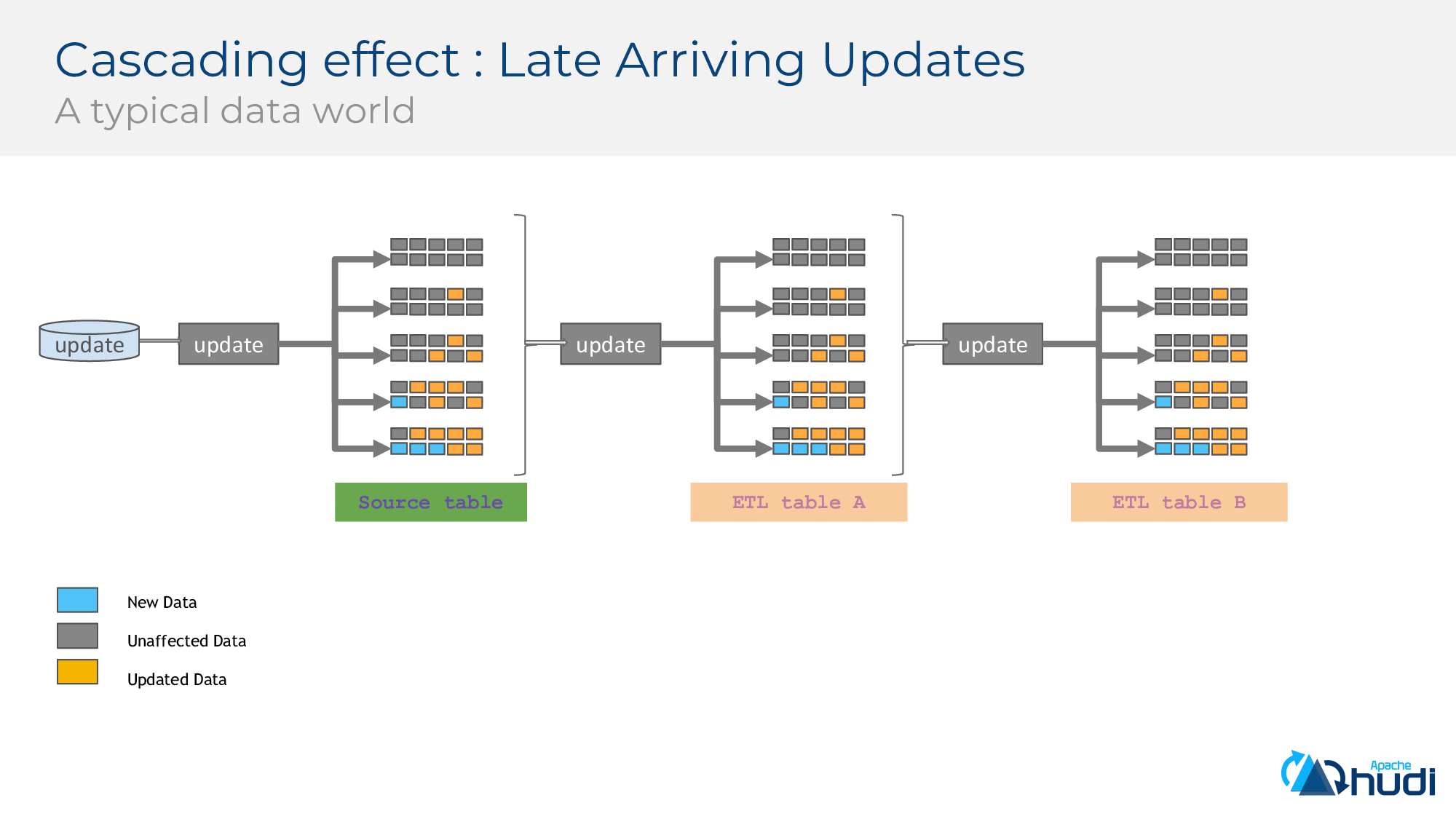
對問題進行總結如下:在COW中,太多的更新(尤其是雜亂的跨分割槽/檔案)會嚴重影響提取延遲(由於作業執行時間較長且無法追趕上入流量),同時還會引起巨大的寫放大,從而影響HDFS(相同檔案的48個版本+過多的IO)。合併更新和重寫parquet檔案會限制我們的資料的新鮮度,因為完成此類工作需要時間 = (重寫parquet檔案所花費的時間*parquet檔案的數量)/(並行性)。
在COW中,我們實際上並沒有太大的parquet檔案,因為即使只有一行更新也可能要重寫整個檔案,因為Hudi會選擇寫入小於預期大小的檔案。
MergeOnRead將所有這些更新分組到一個檔案中,然後在稍後的時刻建立一個新版本。對於重更新的表,重寫大檔案會導致開銷變大。

如何解決上述寫放大問題呢?除了將更新合併並重寫parquet檔案之外,我們將更新寫入增量檔案中,這可以幫助我們降低攝取延遲並獲得更好的新鮮度。
將更新寫入增量檔案將需要在讀取端做額外的工作以便能夠讀取增量檔案中記錄,這意味著我們需要構建更智慧,更智慧的讀取端。

首先來看看寫時複製。如下圖所示,HUDI管理了資料集,並嘗試將一批資料寫入資料湖,HUDI維護稱為“提交時間軸(commit timeline)”的內容,以跟蹤HUDI管理的資料集上發生的操作/更改,它在提交時間軸上標記了一個“inflight”檔案,表示操作已開始,HUDI會寫2個parquet檔案,然後將“inflight”檔案標記為已完成,這從原子上使該新資料寫入HUDI管理的資料集中,並可用於查詢。正如我們提到的,RO檢視優化查詢效能,並提供parquet的基本原始列存效能,無需增加任何額外成本。
現在需要進行第二次更新,與合併和重寫新的parquet檔案(如在COW中一樣)不同,這些更新被寫到與基礎parquet檔案對應的增量檔案中。RO檢視繼續查詢parquet檔案(過時的資料),而RealTime View(Snapshot query)會合並了parquet中的資料和增量檔案中的更新,以提供最新資料的檢視。可以看到,MOR是在查詢執行時間與較低攝取延遲之間的一個權衡。

那麼,為什麼我們要非同步執行壓縮?我們實現了MERGE_ON_READ來提高資料攝取速度,我們希望儘快攝取較新的資料。而合併更新和建立列式檔案是Hudi資料攝取的主要耗時部分。
因此我們引入了非同步Compaction步驟,該步驟可以與資料攝取同時執行,減少資料攝取延遲。

Hudi將事務引入到了大規模資料處理中,實際上,我們是最早這樣做的系統之一,最近,它已通過其他專案的類似方法獲得了社群認可。
Hudi支援多行多分割槽的原子性提交,Hudi維護一個特殊的資料夾.hoodie,在該資料夾中記錄以單調遞增的時間戳表示的操作,Hudi使用此資料夾以原子方式公開已提交的操作;發生的部分故障會透明地回滾,並且不會影響讀者和後面的寫入;Hudi使用MVCC模型將讀取與併發攝取和壓縮隔離開來;Hudi提交協議和DFS儲存保證了資料的持久寫入。

下面介紹Hudi在Uber的使用情況
Hudi管理了超過150PB資料湖,超過10000張表,每天攝入5000億條記錄。
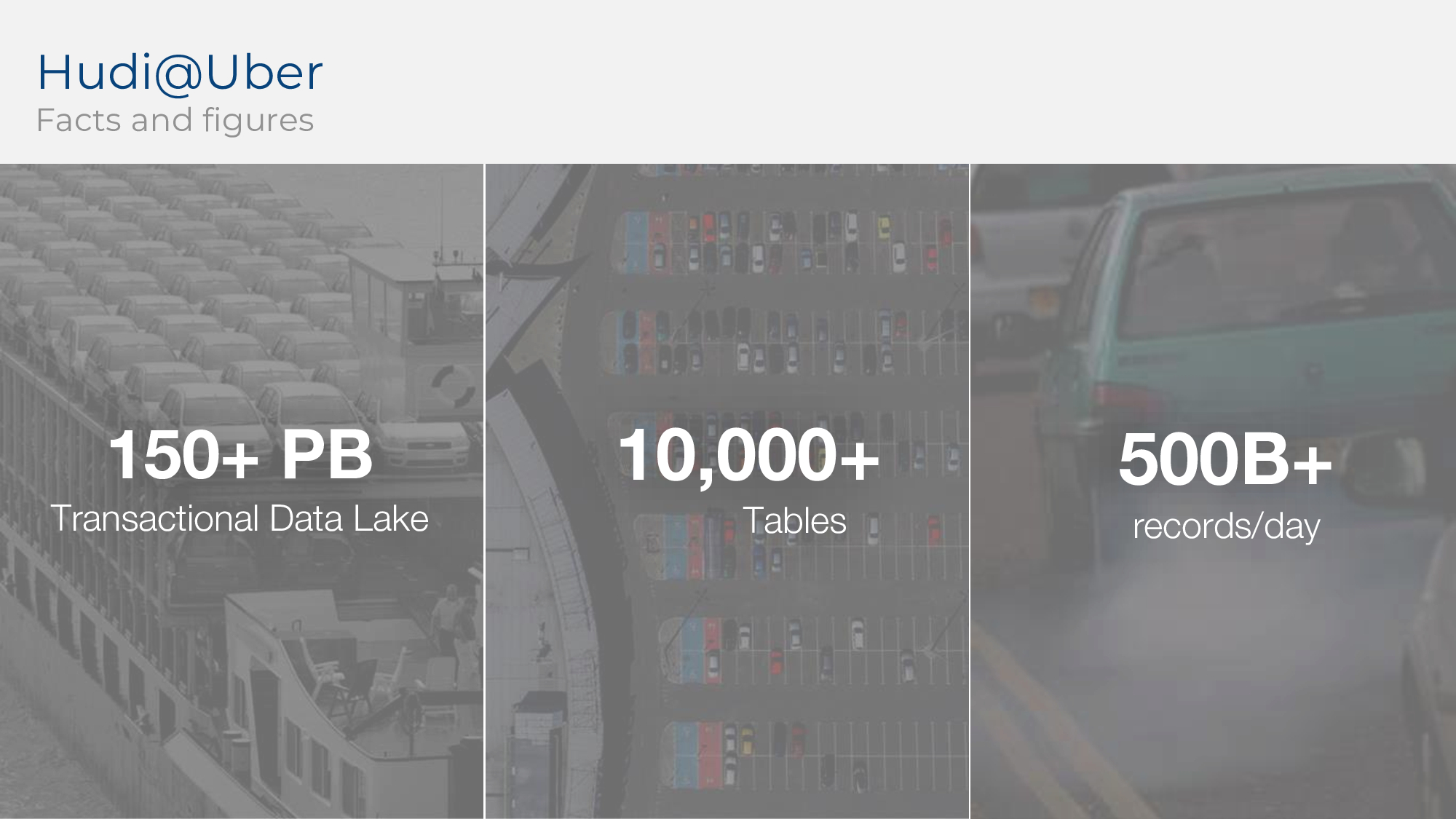
接著看看Hudi如何替代分析架構。利用Hudi的upsert原語,可以在攝取到資料湖中時實現<5分鐘的新鮮度,並且能繼續獲得列式資料的原始效能(parquet格式),同時使用Hudi還可以獲得實時檢視,以5-10分鐘的延遲提供dashboard,此外HUDI支援的增量檢視有助於長尾效應對資料集的突變。
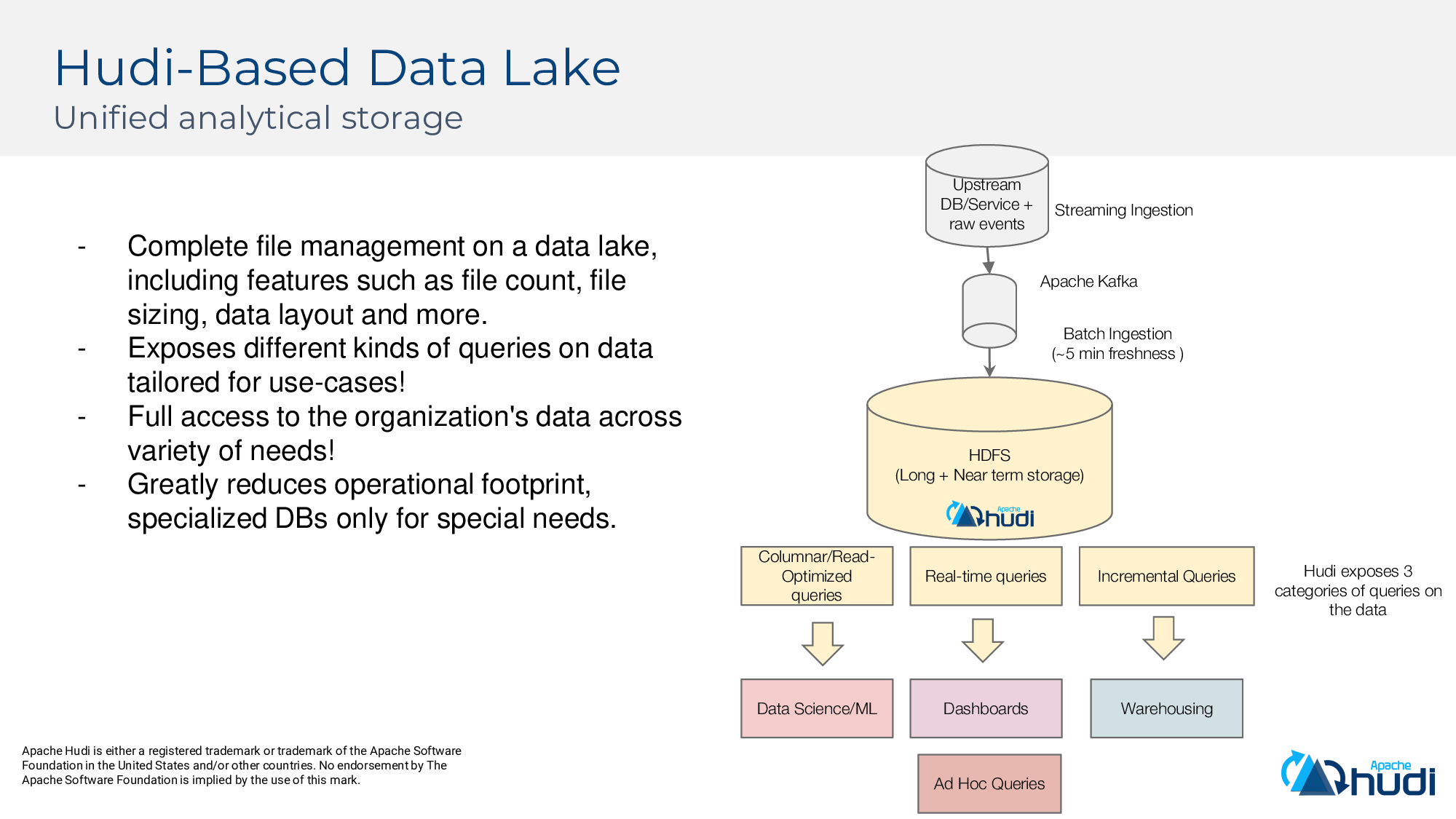
為方便使用者能快速使用Hudi,Hudi提供了一些開箱即用的工具,如HoodieDeltaStreamer,在Uber內部,HoodieDeltaStreamer用來對全球網路進行近實時分析,可用來消費DFS/Kafka中的資料。

除了DeltaStreamer,Hudi還集成了Spark Datasource,也提供了開箱即用的能力,基於Spark,可以快速構建ETL管道,同時也可無縫使用Hudi + PySpark。
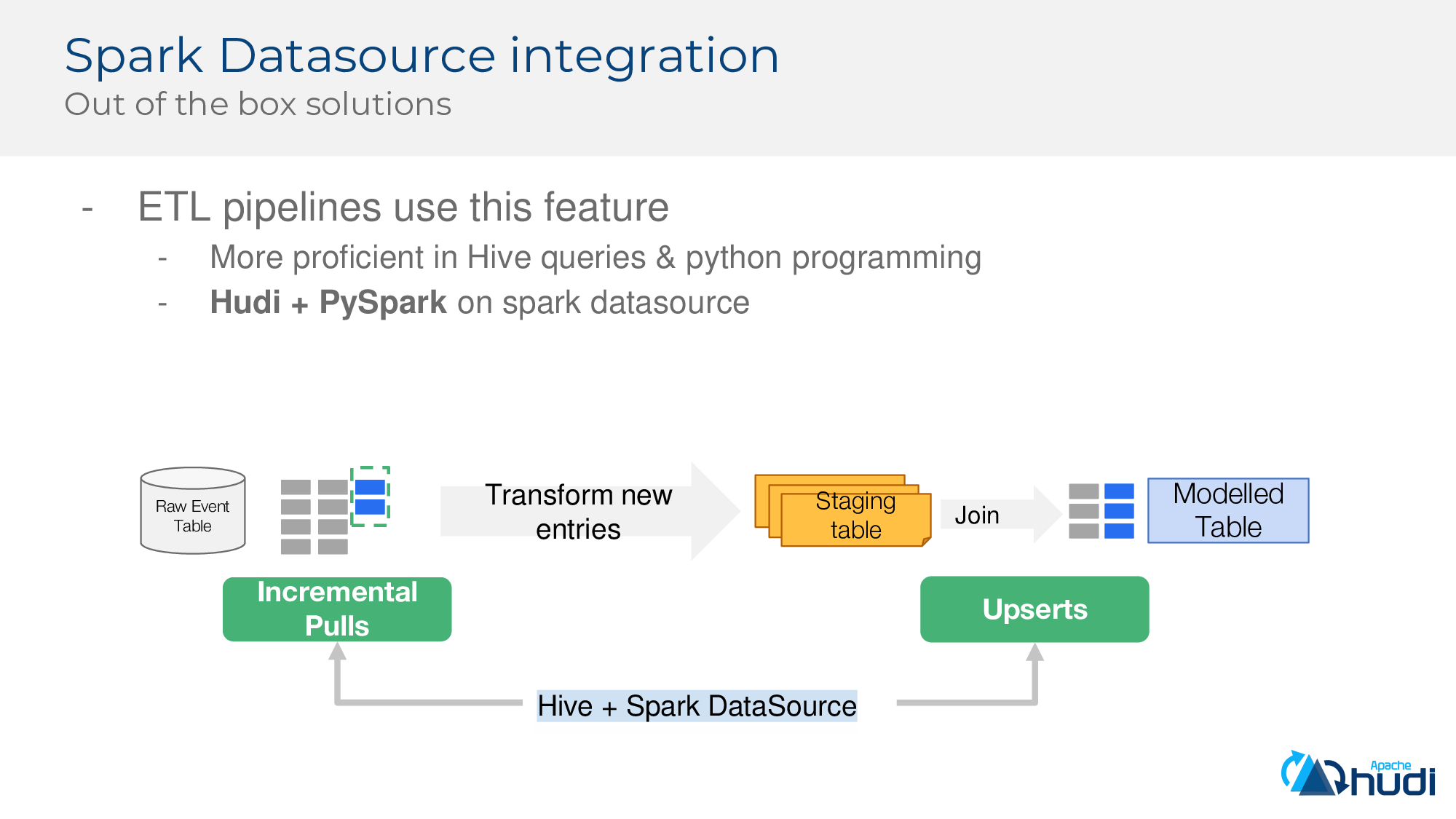
接著介紹更高階的原語和特性。

如何從損壞的資料中恢復?例如線上由於bug導致寫入了不正確的資料,或者上游系統將某一列的值標記為null,Hudi也可以很好的處理上述場景,可以將表恢復到最近的一次正確時間,如Hudi提供的savepoint就可以將不同的commit儲存起來,用於後續恢復,注意MoR表暫時不支援savepoint;Hudi還提供了檔案的版本號,即可以儲存多個版本的檔案,這對於CoW和MoR表都適用,但是會佔用一些儲存空間。

Hudi還提供便於增量ETL的高階特性,通過Spark/Spark便可以輕鬆增量拉取Hudi表的變更。

除了增量拉取,Hudi也提供了時間旅行特性,同樣通過Spark/Hive便可以輕鬆查詢指定版本的資料,其中對於Hive查詢中指定`hoodie.table_name.consume.end.timestamp`也馬上會得到支援。

下面看看對於線上的Hudi Spark作業如何調優。

下面列舉了幾個調優手段,設定Kryo序列化器,使用Shuffle Service,利用開源的profiler來進行記憶體調優,當然Hudi也提供了Hudi生產環境的調優配置,可參考【調優 | Apache Hudi應用調優指南】

下面介紹社群正在進行的工作,敬請期待。

即將釋出的0.6.0版本,將企業中存量的parquet表高效匯入Hudi中,與傳統通過Spark讀取Parquet表然後再寫入Hudi方案相比,佔用的資源和耗時都將大幅降低。以及對於查詢計劃的O(1)時間複雜度的處理,新增列索引及統一元資料管理以消除對DFS的檔案list操作。

還有一些值得關注的特性,比如支援行級別的索引,該功能將極大降低upsert的延遲;非同步資料clustering以優化儲存和查詢效能;支援Presto對MoR表的快照查詢;Hudi整合Flink,通過Flink可將資料寫入Hudi資料湖。

整個分享就介紹到這裡,歡迎觀看。
![](https://img2020.cnblogs.com/blog/616953/202006/616953-20200627212930267-17962368