
深度對比Apache CarbonData、Hudi和Open Delta三大開源資料湖方案
摘要:今天我們就來解構資料湖的核心需求,同時深度對比Apache CarbonData、Hudi和Open Delta三大解決方案,幫助使用者更好地針對自身場景來做資料湖方案選型。
背景
我們已經看到,人們更熱衷於高效可靠的解決方案,擁有為資料湖提供應對突變和事務處理的能力。在資料湖中,使用者基於一組資料生成報告是非常常見的。隨著各種型別的資料匯入資料湖,資料的狀態不會一層不變。需要改變各種資料的用例包括隨時間變化的時序資料、延遲到達的時延資料、平衡實時可用性和回填、狀態變化的資料(如CDC)、資料快照、資料清理等,在生成報告時,這些都將被寫入/更新在同一組表。
由於Hadoop分散式檔案系統(HDFS)和物件儲存類似於檔案系統,因此它們不是為提供事務支援而設計的。在分散式處理環境中實現事務是一個具有挑戰性的問題。例如,日常考慮到鎖定對儲存系統的訪問,這會以犧牲整體吞吐量效能為代價。像Apache CarbonData、OpenDelta Lake、Apache Hudi等儲存解決方案,通過將這些事務語義和規則推送到檔案格式本身或元資料和檔案格式組合中,有效地解決了資料湖的ACID需求。
很多使用者看到這三種主要解決方案時,將陷入兩難的境地,在不同情況下不知怎麼選擇?今天我們對比了三大方案,幫助使用者更好的根據自己的場景選擇解決方案。
Apache Hudi
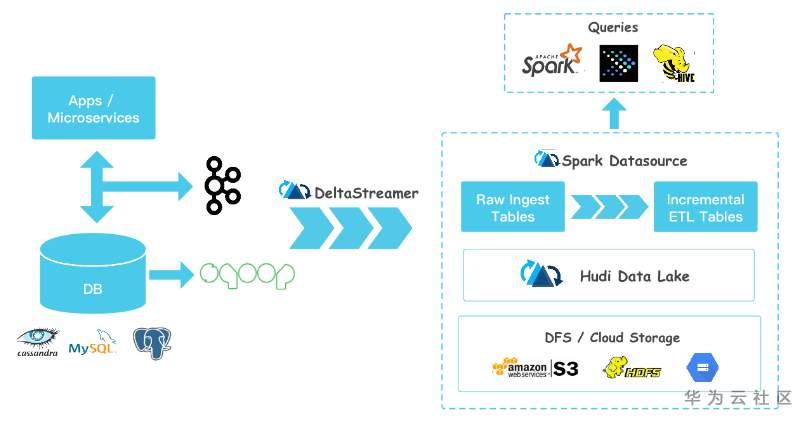
Apache Hudi是Uber為滿足內部資料分析需求而設計的專案。快速upsert/delete和compaction功能可以解決許多實時用例。該專案在Apache社群非常活躍,2020年4月取得了最高專案地位。
從Hudi的名字就能看出他的設計目標, Hadoop Upserts Deletes and Incrementals,主要支援Upserts、Deletes和增量資料處理。其關鍵特性如下:
1.檔案管理
Hudi在DFS上將表組織為basepath下的目錄結構。表被劃分為分割槽,這些分割槽是包含該分割槽的資料檔案的資料夾,類似於Hive表。
2.索引
Hudi通過索引機制將給定的HoodieKey(記錄鍵+分割槽路徑)一致地對映到檔案id,從而提供高效的upserts。
3.表型別
Hudi支援的表型別如下:
- 寫入時複製:使用專有的列檔案格式(如parquet)儲存資料。在寫入時執行同步合併,只需更新版本並重寫檔案。
- 讀取時合併:使用列(如parquet) +行(如Avro)檔案格式的組合儲存資料。更新記錄到增量檔案,並隨後壓縮以同步或非同步生成列檔案的新版本。
4.查詢型別
Hudi支援三種查詢型別:
- 快照查詢:查詢是在給定的提交或壓縮操作之後對錶進行快照的請求。利用快照查詢時,copy-on-write表型別僅公開最新檔案切片中的基/列檔案,並保證相同的列查詢效能。
- 增量查詢:對於寫入時複製表,增量查詢提供自給定提交或壓縮後寫入表的新資料,提供更改流以啟用增量資料管道。
- 讀取優化查詢:查詢檢視指定提交/壓縮操作後表的最新快照。只暴露最新檔案版本的base/columnar檔案,保證列查詢效能與非Hudi列表相同。僅在讀取表合併時支援
5.Hudi工具
Hudi由不同的工具組成,用於將不同資料來源的資料快速採集到HDFS,作為Hudi建模表,並與Hive元儲存進一步同步。工具包括:DeltaStreamer、Hoodie-Spark的Datasource API、HiveSyncTool、HiveIncremental puller。
Apache CarbonData
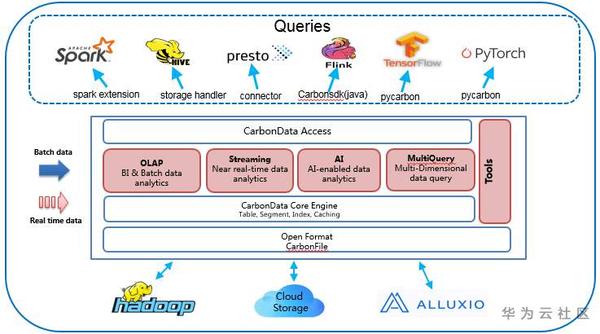
Apache CarbonData是三個產品中最早的,由華為貢獻給社群,助力華為雲產品的資料平臺和資料湖解決方案應對PB級負載。這是一個雄心勃勃的專案,將許多能力都集中在一個專案中。除了支援更新、刪除、合併操作、流式採集外,它還擁有大量高階功能,如時間序列、物化檢視的資料對映、二級索引,並且還被整合到多個AI平臺,如Tensorflow。
CarbonData沒有HoodieKey設計,不強調主鍵。更新/刪除/合併等操作通過優化的粒度連線實現。CarbonData與Spark緊密整合,在CarbonData層中有很多優化,比如資料跳躍、下推等。在查詢方面,CarbonData支援Spark、Hive、Flink、TensorFlow、pyTorch和Presto。一些關鍵特性包括:
1.查詢加速
諸如多級索引、壓縮和編碼技術等優化旨在提高分析查詢的效能,這些查詢可能包括過濾器、聚合和使用者期望PB級資料的點查詢響應時間亞秒級。高階下推優化與Spark深度整合,確保計算在靠近資料處執行,以最小化資料讀取、處理、轉換和傳輸的數量。
2.ACID:資料一致性
沒有關於故障的中間資料,按快照隔離工作,分離讀取和寫入。對資料(查詢、IUD【插入更新刪除】、索引、資料對映、流式處理)的每個操作均符合ACID標準。支援使用基於列和行的格式進行近實時分析,以平衡分析效能和流式採集以及自動切換。
3.一份資料
通過整合Spark、Hive、Presto、Flink、Tensorflow、Pytorch等多種引擎。資料湖解決方案現在可以保留一個數據副本。
4.各種優化指標
其他索引,如二級索引、Bloom、Lucene、Geo-Spatial、實體化檢視,可以加速點、文字、聚合、時間序列和Geo空間查詢。通過Polygon UDF,CarbonData支援地理空間資料模型。
5.更新和刪除
支援合併、更新和刪除操作,以啟用諸如更改-資料-捕獲、緩慢更改-維(SCD-2)操作等複雜用例。
6.高擴充套件性
Scale儲存和處理分離,也適用於雲架構。分散式索引伺服器可以與查詢引擎(如spark, presto)一起啟動,以避免跨執行重新載入索引,並實現更快和可擴充套件的查詢。
Delta【開源】
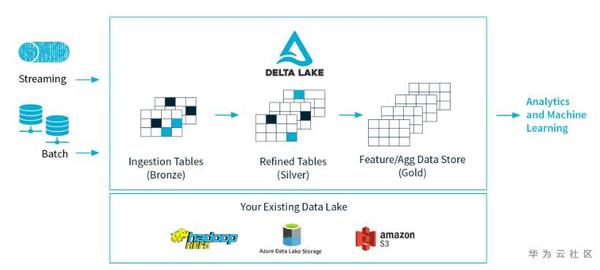
Delta Lake專案於2019年通過Apache License開放原始碼,是Databricks解決方案的重要組成部分。Delta定位為資料湖儲存層,整合流式和批處理,支援更新/刪除/合併。為Apache Spark和大資料工作負載提供ACID事務能力。一些關鍵特性包括:
1.ACID事務:
Delta Lake將ACID事務帶到您的資料湖中。Delta Lake儲存一個事務日誌,以跟蹤對錶目錄所做的所有提交,以提供ACID事務。它提供可序列化的隔離級別,確保資料在多個使用者之間的一致性。
2.方案管理與執行
Delta Lake利用Spark分散式處理能力處理所有元資料,通過提供指定模式和幫助實施模式的能力,避免不良資料進入資料湖。它通過提供合理的錯誤訊息來防止不良資料進入系統,甚至在資料被整合到資料湖之前就進入系統,從而防止資料損壞。
3.資料版本控制和時間旅行
將對資料湖中的資料進行版本控制,並提供快照,以便您可以像該快照是系統當前狀態一樣查詢它們。這有助於我們恢復到舊版本的資料湖中進行審計、回滾和類似的操作。
4.開放格式
Delta Lake中的所有資料都以Apache Parquet格式儲存,使得Delta Lake能夠利用Parquet本地的高效壓縮和編碼方案。
5.統一的批量流式sink
近似實時分析。Delta Lake中的表既是一個批處理表,也是流源和sink,為Lambda架構提供了一個解決方案,但又向前邁進了一步,因為批處理和實時資料都下沉在同一個sink中。
與CarbonData類似,Delta不強調主鍵,因此更新/刪除/合併都是基於spark的連線函式實現的。在資料寫入方面,Delta和Spark是強繫結關係。與Spark的深度整合可能是最好的特性,事實上,它是唯一一個具有Spark SQL特定命令(例如:MERGE),它還引入了有用的DML,如直接在Spark中更新WHERE或DELETE WHERE。Delta Lake不支援真正的資料血緣關係(即跟蹤資料何時以及如何在Delta Lake中複製資料的能力),但是有審計和版本控制(在元資料中儲存舊模式)。
最後
Hudi在IUD效能和讀取合併等功能方面具有競爭優勢。例如,如果您想知道是否要與Flink流一起使用,那麼它目前不是為這樣的用例設計的。Hudi Delta Streamer支援流式資料採集。這裡的“流式處理”實際上是一個連續的批處理週期。但從本質上講,這仍不是一種存粹的流式的採集。該社群由Uber提供,並已開放其所有功能。
Delta的主要優勢之一是它能夠與Spark整合,特別是其流批一體化設計。Delta擁有良好的使用者API和文件。該社群由Databricks提供,它擁有一個具有附加功能的商用版本。
CarbonData是市場上最早的產品,由於物化檢視、二級索引等先進的索引,它具有一定的競爭優勢,並被整合到各種流/AI引擎中,如Flink、TensorFlow,以及Spark、Presto和Hive。社群由華為提供,所有特性均已開源。
隨著新版的釋出,這三個都在不斷填補他們缺失的能力,並可能在未來相互融合或競爭。當然,也可以把重點放在自己的情景上,構建自身優勢的門檻。對這些解決方案進行效能比較有助於更好地瞭解它們的產品。因此,勝負仍是未知之數。
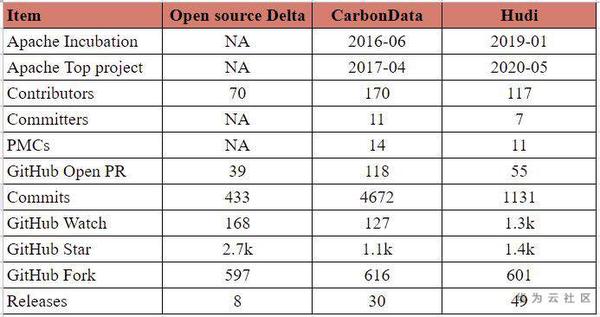
下表從多個維度總結了這三者。需要注意的是,本表所列能力僅突出2020年8月底的能力。
特性對比表
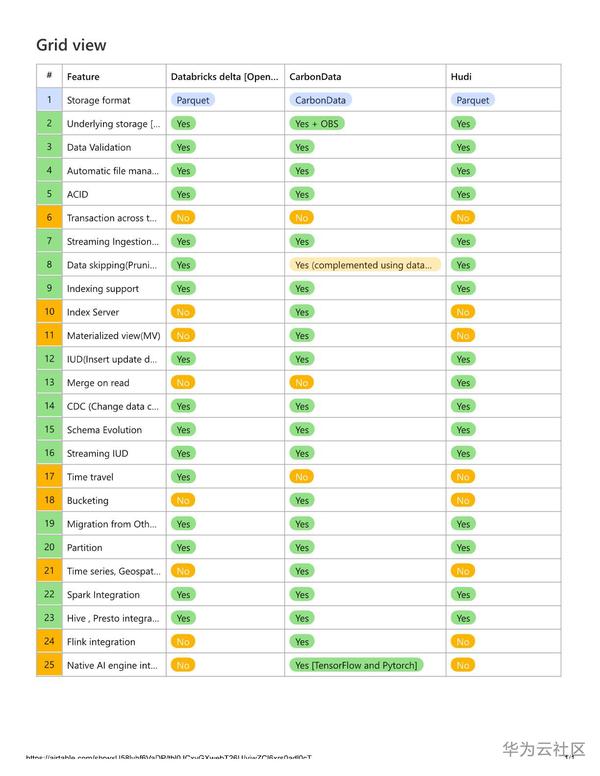
社群現狀(截至2020年8月)
參考資訊
1. https://github.com/apache/carbondata
2. https://github.com/delta-io/delta
3. https://github.com/apache/hudi
4. https://cwiki.apache.org/confluence/display/CARBONDATA/
5. https://cwiki.apache.org/confluence/display/HUDI
6. https://hudi.apache.org/
7. https://carbondata.apache.org/
8. https://delta.io/
免責宣告:基於對各種參考連結的研究和個人分析,歡迎讀者反饋和改進!
翻譯自 https://medium.com/@brijoobopanna/comparative-study-of-apache-carbondata-hudi-and-open-delta-49e6e45a2526
點選關注,第一時間瞭解華為雲新鮮技術~