
傳統聲學模型之HMM和GMM
阿新 • • 發佈:2020-06-29
聲學模型是指給定聲學符號(音素)的情況下對音訊特徵建立的模型。
## 數學表達
用 $X$ 表示音訊特徵向量 (觀察向量),用 $S$ 表示音素 (隱藏/內部狀態),聲學模型表示為 $P(X|S)$。
但我們的機器是個牙牙學語的孩子,並不知道哪個音素具體的發出的聲音是怎麼樣的。我們只能通過大量的資料去教他,比如說在拼音「é」的時候對應「鵝」的發音,而這個過程就是 GMM 所做的,根據資料建立起「é」這個拼音對應的音訊特徵分佈,即 $P(x|s=é)$。孩子學會每個拼音的發音後,就可以根據拼音拼讀一個單詞 / 一個句子,但你發現他在讀某段句子的時候,聽起來好像怪怪的,你檢查發現是他把某個拼音讀錯了,導致這句話聽起來和常理不符。而這個怪怪的程度就是你聽到這個音訊特徵序列的時感覺這個音訊序列以及其背後的拼音出現的可能性的倒數,這部分則是通過 HMM 來建模的。
總結一下,GMM 用於對音素所對應的音訊特徵分佈進行建模,HMM 則用於音素轉移和音素對應輸出音訊特徵之間關係的建模。
## HMM
即為隱馬爾可夫模型(Hidden Markov model,HMM)
HMM 脫胎於馬爾可夫鏈,馬爾可夫連結串列示的是一個系統中,從一個狀態轉移到另一個狀態的所有可能性。但因為在實際應用過程中,並不是所有狀態都是可觀察的,不過我們可以通過可觀察到的狀態與隱藏狀態之間的可能性。因此就有了隱馬爾可夫模型。
HMM 要遵循的假設:
* 一階馬爾可夫假設:下一個狀態只依賴於當前的狀態。因此多階馬爾可夫鏈可簡化為
$$
P(s_{t+1} | s_1,s_2,\ldots,s_t) = P(s_{t+1} | s_t)
$$
* 輸出無關假設:每個輸出只取決於當前 (內部/隱藏) 狀態,和前一個或多個輸出無關。
聲學模型為什麼要用HMM?
因為聲學模型建立的是在給定音素序列下輸出特定音訊特徵序列的似然 $P(X|S)$,但在實際情況中,我們只知道音訊特徵序列,並不知道其對應的音素序列,所以我們需要通過 HMM 建立音訊特徵與背後的每個音素的對應關係,以及這個音素序列是怎麼由各個音素組成的。
上兩個假設可以引申出 HMM 中主要的兩種概率構成:
* 從一個內部狀態 $i$ 轉移到另一個內部狀態 $j$ 的概率稱為轉移(Transition) 概率,表示為 $a_{ij}$。
* 在給定一個內部狀態 $j$ 的情況下觀察到某個觀察值 $x_t$ 的概率稱為輸出(Emission)概率,表示為 $b_j(x_t)$。
HMM 的三個經典問題
* 評估問題 Estimation
* 解碼問題 Decoding
* 訓練問題 Learning
⚠️:後文提到的狀態即指的是內部 / 隱藏狀態。
### 評估問題
評估問題就是說,我已知模型引數 $\theta$ (輸出概率以及轉移概率),最後得到的觀察序列為某個特定序列 $X$ 的概率是多少。
在剛才的例子中,就是孩子已經知道每個拼音後面可能接什麼拼音,每個拼音怎麼讀,當他讀出了某段聲音,這段聲音的概率是多少。
因為在觀察序列固定的情況下,有多種可能的狀態序列 $S$,而評估問題就是要計算出在所有可能的狀態下得到觀察序列的概率,表示為
$$
\begin{aligned}
P(X) = \sum_S P(X | S) P(S) \\
\end{aligned}
$$
在當前的公式裡,我們暫時先忽略固定的引數 $\theta$。根據一階馬爾可夫假設,時刻 $t$ 的狀態都只取決於時刻 t-1 的狀態,因此單個狀態序列出現的概率表示為
$$
\begin{aligned}
P(S) &= P(s_1) \prod^T_{t=2} P(s_t|s_{t-1}) \\
&= \pi_k \prod^T_{t=2} a_{ij}
\end{aligned}
$$
其中, $\pi_k$ 表示時刻1下狀態為 $k$ 的概率。
根據輸出無關假設,在時刻 $t$ 觀察序列的值只取決於時刻 $t$ 的狀態,因此觀察序列關於狀態序列的似然表示為
$$
P(X|S) = \prod_{t=1}^T P(x_t|s_t) = \prod_{t=1}^T b_j(x_t)
$$
因此整個觀察序列出現的概率為
$$
\begin{aligned}
P(X) &= \sum_S P(X | S) P(S) \\
&= \sum_S \pi_k b_k(x_1) \prod^T_{t=2} a_{ij} b_j(x_t)
\end{aligned}
$$
由於 $i,j,k$ 都表示可能的狀態,假設有 $n$ 種狀態,那麼計算該概率的事件複雜度就為 $O(n^T)$,可謂是指數級別了。
因此,前人開動了腦筋,提出了在該問題上將時間複雜度將為多項式時間的方法。
#### 似然前向演算法
該方法採用了分治 / 動態規劃的思想,在時刻 $t$ 下的結果可以利用時刻 $t-1$ 的結果來計算。
在時刻 $t$,觀察序列的概率表示為前 $t$ 個時刻的觀察序列與時刻 $t$ 所有可能的狀態同時出現的概率和
$$
P(x_1,x_2,\ldots,x_t) = \sum_{j\in N} P(x_1,x_2,\ldots,x_t,s_t=j)
$$
其中, $N$ 表示所有可能的狀態的集合。
而連加符號的後面部分被定義為前向概率 $\alpha_t(j)$,而它可以被上一個時刻的前向概率迭代表示。
$$
\begin{aligned}
\alpha_t(j) &=P(x_1,x_2,\ldots,x_t,s_t=j) \\ &= \sum_{i\in N} P(x_1,x_2,\ldots,x_{t-1},s_{t-1}=i)P(s_t|s_{t-1}=i)P(x_t|s_{t}=j) \\
&= \sum_{i\in N}\alpha_{t-1}(i) a_{ij} b_j(x_t)
\end{aligned}
$$
通過該方法,當前時刻下某個狀態的概率只需要遍歷上一時刻所有狀態的概率 ($n$),然後當前時刻的所有狀態的概率和也只需要遍歷當前的所有狀態就可以計算得到 ($n$),考慮到觀察序列持續了 $T$ 個時刻,因此時間複雜度降為 $O(n^2T)$。
整個過程總結如下
1. 初始化:根據初始的狀態分佈,計算得到時刻1下每個狀態的前向概率 $\alpha_1(k) = \pi_k b_k(x_1)$
2. 對於每個時刻,計算該時刻下每個狀態的前向概率 $\alpha_t(j) = \sum_{i\in N}\alpha_{t-1}(i) a_{ij} b_j(x_t)$
3. 最終得到結果 $P(X) = \sum_{i\in N}\alpha_{T}(i)$
### 解碼問題
解碼問題就是說在得到 HMM 模型之後,我們如何通過觀察序列找到最有可能的狀態序列。在語音識別中,在給定的音訊片段下,找到對應的各個音素。
還是剛才的例子,我們需要猜測孩子讀出的這段聲音最有可能對應什麼樣的拼音序列,這就是解碼問題。
#### Viterbi 演算法
數學表示
給定在時間 $t$ 下的內部狀態為 $j$,區域性最優概率 $v_t(j)$ 表示的是在時刻 $t$ 觀察序列與最優內部狀態序列的聯合概率。
$$
v_{t}(j)=\max _{s_{0}, s_{1} \ldots s_{t-1}} P\left(s_{0}, s_{1}, \ldots, s_{t-1}, x_{1}, x_{2}, \ldots, x_{t}, s_{t}=j | \theta\right)
$$
同樣也可以根據時間遞迴表示為
$$
v_{t}(j)=\max_{i \in N} v_{t-1}(i) a_{i j} b_{j}\left(x_{t}\right)
$$
演算法具體流程如下
1. 初始化:根據初始的狀態分佈,計算得到時刻1下每個狀態的最優概率 $v_1(k) = \pi_k b_k(x_1)$
2. 對於每個時刻,計算該時刻下每個狀態的區域性最優概率 $v_t(j) = \max_{i\in N}v_{t-1}(i) a_{ij} b_j(x_t)$,記錄下最優區域性最優序列 $(s_1^*,s_2^*,\ldots,s_{t-2}^*) \bigcup (s_{t-1}^*)$
3. 最終得到全域性最優概率 $P(X,S^*) = \max_{i\in N} v_T(i)$
4. 得到全域性最優序列 $S^* = \arg \max_{i\in N} v_T(i), S^* = (s_1^*,s_2^*,\ldots,s_T^*)$
在表示上很類似於上面的前向演算法,只是加和變成了取最大值。具體推導流程也就不再贅述了。兩者的區別可以看下圖([來源](http://www.inf.ed.ac.uk/teaching/courses/asr/2018-19/asr03-hmmgmm-handout.pdf)) ,紅線表示解碼路徑,黑線表示評估路徑。
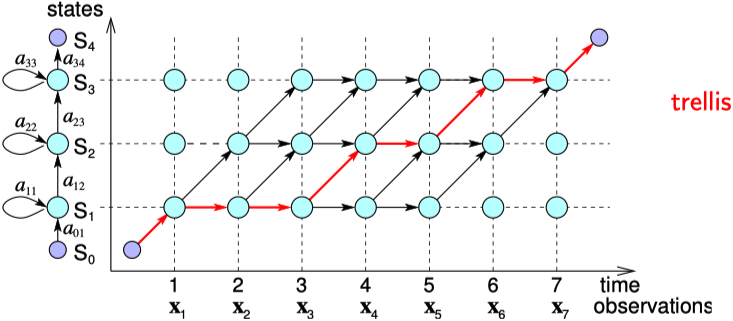
不過這張圖是簡化的狀態,即狀態序列 $S$ 是確定的情況下的狀態轉移與觀察序列之間的關係。
==