
【小白學PyTorch】3 淺談Dataset和Dataloader
阿新 • • 發佈:2020-09-01
文章目錄:
[TOC]
## 1 Dataset基類
PyTorch 讀取其他的資料,主要是通過 Dataset 類,所以先簡單瞭解一下 Dataset 類。在看很多PyTorch的程式碼的時候,也會經常看到dataset這個東西的存在。Dataset類作為所有的 datasets 的基類存在,所有的 datasets 都需要繼承它。
先看一下原始碼:

這裡有一個```__getitem__```函式,```__getitem__```函式接收一個index,然後返回圖片資料和標籤,這個index通常是指一個list的index,這個list的每個元素就包含了圖片資料的路徑和標籤資訊。**之後會舉例子來講解這個邏輯**。
其實說著了些都沒用,因為在訓練程式碼裡是感覺不到這些操作的,只會看到通過DataLoader就可以獲取一個batch的資料,這是觸發去讀取圖片這些操作的是DataLoader裡的```__iter__(self)```(後面再講)。
## 2 構建Dataset子類
下面我們構建一下Dataset的子類,叫他MyDataset類:
```python
import torch
from torch.utils.data import Dataset,DataLoader
class MyDataset(Dataset):
def __init__(self):
self.data = torch.tensor([[1,2,3],[2,3,4],[3,4,5],[4,5,6]])
self.label = torch.LongTensor([1,1,0,0])
def __getitem__(self,index):
return self.data[index],self.label[index]
def __len__(self):
return len(self.data)
```
### 2.1 __Init__
- 初始化中,一般是把資料直接儲存在這個類的屬性中。像是```self.data,self.label```
### 2.2 __getitem__
- index是一個索引,這個索引的取值範圍是要根據```__len__```這個返回值確定的,在上面的例子中,```__len__```的返回值是4,所以這個index會在0,1,2,3這個範圍內。
## 3 dataloader
從上文中,我們知道了MyDataset這個類中的```__getitem__```的返回值,應該是某一個樣本的資料和標籤(如果是測試集的dataset,那麼就只返回資料),在梯度下降的過程中,一般是需要將多個數據組成batch,這個需要我們自己來組合嗎?不需要的,所以PyTorch中存在DataLoader這個迭代器(這個名詞用的準不準確有待考究)。
繼續上面的程式碼,我們接著寫程式碼:
```python
mydataloader = DataLoader(dataset=mydataset,
batch_size=1)
```
我們現在建立了一個DataLoader的例項,並且把之前例項化的mydataset作為引數輸入進去,並且還輸入了batch_size這個引數,現在我們使用的batch_size是1.下面來用for迴圈來遍歷這個dataloader:
```python
for i,(data,label) in enumerate(mydataloader):
print(data,label)
```
輸出結果是:
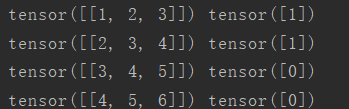
意料之中的結果,總共輸出了4個batch,每個batch都是隻有1個樣本(資料+標籤),值得注意的是,這個輸出過程是**順序的**。
我們稍微修改一下上面的DataLoader的引數:
```python
mydataloader = DataLoader(dataset=mydataset,
batch_size=2,
shuffle=True)
for i,(data,label) in enumerate(mydataloader):
print(data,label)
```
結果是:
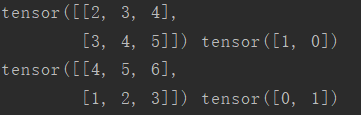
可以看到每一個batch內出現了2個樣本。假如我們再執行一遍上面的程式碼,得到:
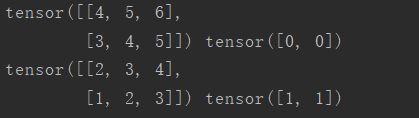
兩次結果不同,這是因為```shuffle=True```,dataset中的index不再是按照順序從0到3了,而是亂序,可能是[0,1,2,3],也可能是[2,3,1,0]。
**【個人感想】**
Dataloader和Dataset兩個類是非常方便的,因為這個可以快速的做出來batch資料,修改batch_size和亂序都非常地方便。有下面兩個希望注意的地方:
1. 一般標籤值應該是Long整數的,所以標籤的tensor可以用```torch.LongTensor(資料)```或者用```.long()```來轉化成Long整數的形式。
2. 如果要使用PyTorch的GPU訓練的話,一般是先判斷cuda是否可用,然後把資料標籤都用```to()```放到GPU視訊記憶體上進行GPU加速。
```python
device = 'cuda' if torch.cuda.is_available() else 'cpu'
for i,(data,label) in enumerate(mydataloader):
data = data.to(device)
label = label.to(device)
print(data,label)
```
看一下輸出:
![](https://p1-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/b16357c79a4d4d5d8daa1c0e1f0cd4ea~tplv-k3u1fbpfcp-zoom-1