
【小白學PyTorch】5 torchvision預訓練模型與資料集全覽
阿新 • • 發佈:2020-09-03
文章來自:微信公眾號【機器學習煉丹術】。一個ai專業研究生的個人學習分享公眾號
文章目錄:
[TOC]
# torchvision
>官網上的介紹(FQ):The torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision.
翻譯過來就是:
torchvision包由流行的資料集、模型體系結構和通用的計算機視覺影象轉換組成。**簡單地說就是常用資料集+常見模型+常見影象增強方法**
這個torchvision中主要有包組成:
- ```torchvision.datasets```
- ```torchvision.models```
- ```torchvision.transforms```
## 1 torchvision.datssets
包含賊多的資料集,包含下面的:
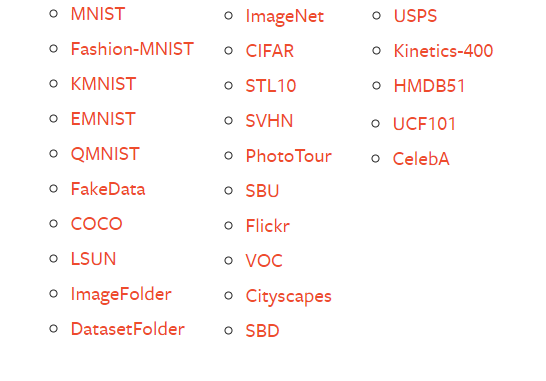
>官方說明了:All the datasets have almost similar API. They all have two common arguments: transform and target_transform to transform the input and target respectively.
翻譯過來就是:**每一個數據集的API都是基本相同的。他們都有兩個相同的引數:transform和target_transform(後面細講)**
我們就用最經典最簡單的MNIST手寫數字資料集作為例子,先看這個的API:
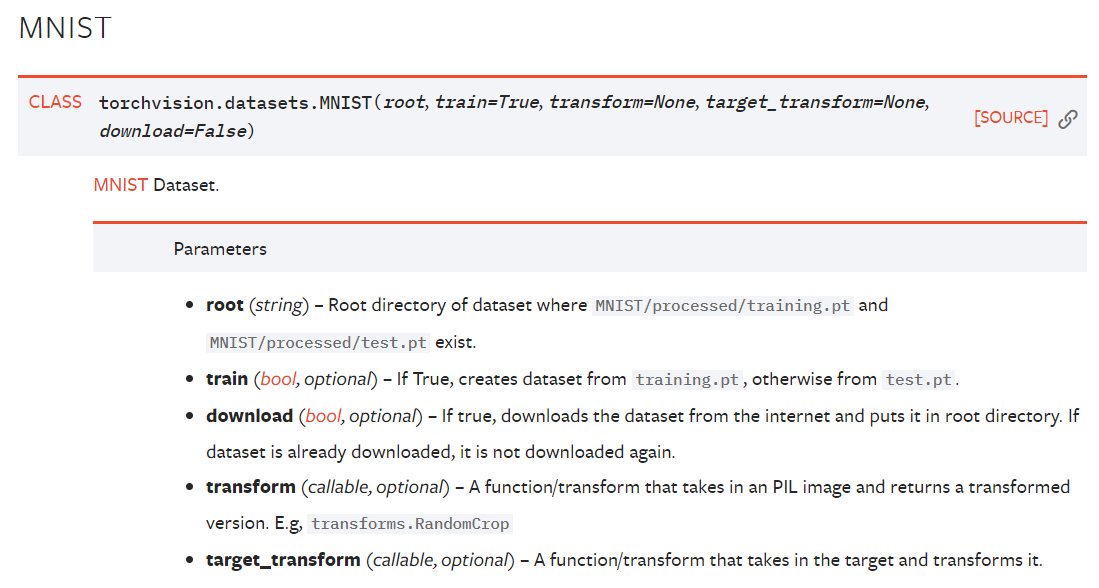
包含5個引數:
- root:就是你想要儲存MNIST資料集的位置,如果download是Flase的話,則會從目標位置讀取資料集;
- download:True的話就會自動從網上下載這個資料集,到root的位置;
- train:True的話,資料集下載的是訓練資料集;False的話則下載測試資料集(真方便,都不用自己劃分了)
- transform:這個是對影象進行處理的transform,比方說旋轉平移縮放,輸入的是PIL格式的影象(不是tensor矩陣);
- target_transform:這個是對影象標籤進行處理的函式(這個我沒用過不太確定,也許是做標籤平滑那種的處理?)
**【下面用程式碼進一步理解】**
```python
import torchvision
mydataset = torchvision.datasets.MNIST(root='./',
train=True,
transform=None,
target_transform=None,
download=True)
```
執行結果如下,表示下載完畢(我不太確定這個下載資料集是否需要FQ,**我會把這次需要用的程式碼和資料集放到公眾號,後臺回覆【torchvision】獲取**,下載出現問題請務必私戳我)
之後我們需要用到上一節課講到的dataloader的內容:
```python
from torch.utils.data import Dataset,DataLoader
myloader = DataLoader(dataset=mydataset,
batch_size=16)
for i,(data,label) in enumerate(myloader):
print(data.shape)
print(label.shape)
break
```
這時候會丟擲一個錯誤:

大致看一看,就是pytorch的這個dataloader不是可以把資料集分成batch嘛,這個dataloder只能把tensor或者numpy這樣的組合成batch,而現在的資料集的格式是PIL格式。**這裡驗證了之前說到的,transform這個輸入是PIL格式的圖片,解決方法是:transform不能是None,我們需要將PIL轉化成tensor才可以**
所以我們把上面的transform稍作修改:
```python
mydataset = torchvision.datasets.MNIST(root='./',
train=True,
transform=torchvision.transforms.ToTensor(),
target_transform=None,
 download=True)
```
重新執行的時候可以得到結果:

結果中,16表示一個batch有16個樣本,1表示這是單通道的灰度圖片,28表示MNIST資料集圖片是$28\times 28$的大小,然後每一個圖片有一個label。
想要獲取其他的資料集也是一樣的,不過這裡就用MNIST作為舉例,其他的相同。
## 2 torchvision.models
預訓練模型中torchvision提供了很多種,大體分成下面四類:

分別是分類模型,語義模型,目標檢測模型和視訊分類模型。這裡呢因為分類模型比較常見也比較基礎,就主要介紹這個好啦。
在torch1.6.0版本中(應該是比較近的版本),主要包含下面的預訓練模型:

構建模型可以通過下面的程式碼:
```python
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet = models.mobilenet_v2()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0()
```
這樣構建的模型的權重值是隨機的,只有結構是儲存的。**想要獲取預訓練的模型,則需要設定引數pretrained**:
```python
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet = models.mobilenet_v2(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
```
我看官網的英文講解,提到了一點:**似乎這些模型的預訓練資料集都是ImageNet的那個資料集,輸入圖片都是3通道的,並且要求輸入圖片的寬高不小於224畫素,並且要求輸入圖片畫素值的範圍在0到1之間,然後做一個normalization標準化。**
不知道各位在看一些案例的時候,有沒有看到這個標準化:```mean = [0.485, 0.456, 0.406]``` 和 ```std = [0.229, 0.224, 0.225]```,這個應該是ImageNet的圖片的標準化的引數。
這些預訓練的模型引數不確定能不能直接下載,我也就把這些模型存起來一併放在了公眾號的後臺,依然是回覆【torchvision】獲取。
得到了.pth檔案之後使用```torch.load```來載入即可。
```python
# torch.save(model, 'model.pth')
model = torch.load('model.pth')
```
## 模型比較
最後呢,torchvision官方提供了一個不同模型在Imagenet 1-crop 的一個錯誤率的比較。可以一起來看看到底哪個模型比較好使。這裡我放了一些常見的模型。。像是Wide ResNet這種變種我就不放了。
| 網路 | Top-1 error | Top-5 error |
| ---- | ---- | ---- |
| AlexNet | 43.45 | 20.91 |
| VGG-11 | 30.98 | 11.37 |
| VGG-13 | 30.07 | 10.75 |
| VGG-16 | 28.41 | 9.62 |
| VGG-19 | 27.62 | 9.12 |
| VGG-13 with BN | 28.45| 9.63 |
| VGG-19 with BN | 25.76 | 8.15 |
| Resnet-18 | 30.24 | 10.92 |
| Resnet-34 | 26.70 | 8.58 |
| Resnet-50 | 23.85 | 7.13 |
| Resnet-101 | 22.63 | 6.44 |
| Resnet-152 | 21.69 | 5.94 |
| SqueezeNet 1.1 | 41.81 | 19.38 |
| Densenet-161 | 22.35 | 6.2 |
整體來看,還是Resnet殘差網路效果好。不過EfficientNet效果更好,不過Torchvision中沒有預訓練,在之後會講解EfficientNet的預訓練模型的程式碼方便使用(先挖