
Apache Hudi助力nClouds加速資料交付
阿新 • • 發佈:2020-10-21
### 1. 概述
在[nClouds](https://www.nclouds.com/services/data-and-analytics-services)上,當客戶的業務決策取決於對近實時資料的訪問時,客戶通常會向我們尋求有關資料和分析平臺的解決方案。但隨著每天建立和收集的資料量都在增加,這使得使用傳統技術進行資料分析成為一項艱鉅的任務。
本文我們將討論nClouds如何幫助您應對資料延遲,資料質量,系統可靠性和資料隱私合規性方面的挑戰。
Amazon EMR上的Apache Hudi是需要構建增量資料管道、大規模近實時處理資料的理想解決方案。本篇文章將在Amazon EMR的Apache Hudi上進行原型驗證。
nClouds是具有DevOps、資料分析和遷移能力的[AWS高階諮詢合作伙伴](https://partners.amazonaws.com/partners/001E000000cFlkkIAC/nClouds) ,並且是AWS託管服務提供商(MSP)和AWS完善的合作伙伴計劃的成員。nClouds的使命是幫助您構建和管理可更快交付創新的現代基礎架構解決方案。
### 2. 解決方案概述
Apache Hudi是一個開源資料管理框架,用於簡化增量資料處理和資料管道開發。它最初於2016年在Uber開發,旨在為PB級資料分析提供更快的資料,進行低延遲、高效率的資料攝取。
Apache Hudi通常用於簡化進入資料湖和分析服務的資料管道,支援記錄級粒度的Change Data Capture(CDC),同時可通過Apache Hive和Presto之類的SQL查詢引擎對資料集進行近乎實時的分析,更多關於Hudi詳情,可訪問[hudi.apache.org](hudi.apache.org)
Amazon EMR是領先的雲大資料平臺,可使用開源工具(例如Apache Hudi,Apache Spark,Apache Hive,Apache HBase,Apache Flink和Presto)處理大量資料。當選擇Spark,Hive或Presto作為部署選項時,Apache Hudi會自動安裝在Amazon EMR叢集中。
在2019年,Amazon EMR團隊開始與Apache Hudi社群密切合作,以提供補丁和bug修復並新增對AWS Glue Data Catalog的支援。
Apache Hudi非常適合將資料快速提取到Hadoop分散式檔案系統(HDFS)或雲端儲存中,並加快ETL/Hive/ Spark作業,Hudi適用於讀繁重或寫繁重的場景,它可以管理儲存在Amazon Simple Storage Service(Amazon S3)上的資料。
#### 2.1 資料延遲
高資料延遲會影響客戶的運營能力,進一步影響新產品和服務的快速開發和交付,盈利能力以及基於事實的決策。
在上述場景下,我們建議使用Apache Hudi,它提供了DeltaStreamer實用工具程式來執行自動增量更新處理,使得關鍵業務資料管道能夠以接近實時的延遲實現高效攝取,每次查詢表時,都可以讀取這些增量檔案。
Apache Hudi通過處理對近實時資料的查詢以及增量拉取進行時間點資料分析的查詢來節省時間。
#### 2.2 資料質量
資料量不斷增長可能會對資料質量判斷造成困難。從海量、可變和複雜的資料集中提取高質量的資料非常困難,尤其是在混合了非結構化,半結構化和結構化資料的情況下。
當資料快速變化時,其質量取決於其時效性,Apache Hudi能夠處理資料結構變更,自動執行增量資料更新以及有效地提取流資料的能力,有助於提取和整合高質量資料。
Apache Hudi可與[Amazon Simple Workflow(Amazon SWF)](https://aws.amazon.com/swf/),[AWS Data Pipeline](https://aws.amazon.com/datapipeline/)和[AWS Lambda](https://aws.amazon.com/lambda/)等AWS服務整合以實現自動化實時資料湖工作流程。
#### 2.3 系統可靠性
當我們執行[AWS Well-Architected Review](https://aws.amazon.com/architecture/well-architected/)(使用AWS Well-Architected Framework的最佳實踐進行架構評估)時,我們關注的核心點之一是架構可靠性。如果通過臨時提取,轉換,載入(ETL)作業提取資料,而沒有可靠的架構通訊機制,則系統可靠性可能會受到威脅。
我們喜歡Apache Hudi在資料湖中控制和管理檔案佈局的功能,此功能對於維護健康的資料生態系統至關重要,因為它提高了可靠性和查詢效能。
使用Hudi,使用者無需載入新資料並使用ETL清理資料,從之前資料層攝取的資料和變更會自動更新,並在儲存新資料時觸發自動化的工作流程。
然後在AWS資料庫遷移服務(AWS DMS)註冊更新,並在Amazon Simple Storage Service(Amazon S3)的源位置中建立一個Apache Parquet檔案,它使用Apache Avro作為記錄的內部規範表示,從而在資料提取或ETL管道中提供可靠性。
#### 2.4 遵守資料隱私法規
Apache Hudi管理著資料湖中資料的所有互動,並且提供對資料的訪問的服務,同時Apache Hudi使得基於Amazon S3的資料湖能夠遵守資料隱私法,其提供了記錄級的更新和刪除,因此使用者可以選擇行使其被遺忘的權利或更改其有關如何使用其資料的同意。
### 3. 原型驗證
在nClouds,我們構建了一個非面向客戶的原型驗證(PoC)以說明如何使用Hudi的插入、更新和刪除操作來處理資料集中的更改,COVID-19的經濟影響促使我們使用與COVID-19大流行相關的資料。
TDWI最近的一項研究發現,由於大流行的影響,超過一半的資料和分析專業人員被要求回答新型別的問題,約三分之一的受訪者表示,他們需要更新模型和分析負載以通過重新訓練模型或重塑客戶群來應對不斷變化的客戶行為。
我們PoC的資料流為Amazon Relational Database Service(Amazon RDS)-> Amazon S3記錄集更改 -> Hudi資料集,以快速應用增量更改。同時我們需要一個環境來執行我們的測試,包括Amazon RDS,AWS DMS任務,Amazon EMR叢集和S3儲存桶,最後一步做資料視覺化,我們使用Amazon QuickSight展示報表。
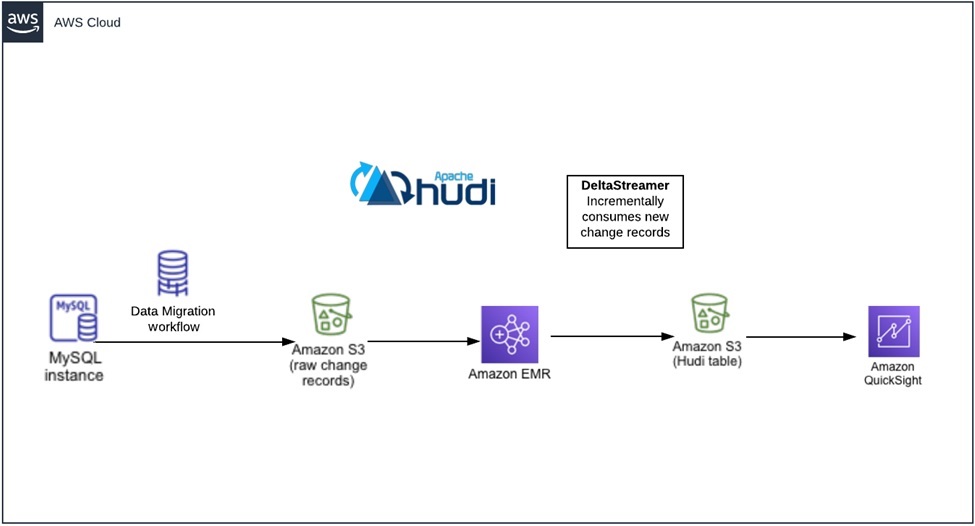
下面是PoC方案的每個具體步驟
**第一步:Amazon RDS設定**
* 在Amazon RDS儀表板中,跳轉到資料庫引數組部分,然後建立一個[新的引數組](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups.html),將binlog格式設定為ROW。
* [建立一個新的Amazon RDS例項](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_CreateDBInstance.html),確保使用設定的**DB Parameter group**並開啟自動備份;
* 建立完成後,進行連線並建立如下MySQL Schema
```sql
CREATE TABLE covid_by_state(
covid_by_state_id INTEGER NOT NULL AUTO_INCREMENT,
date TIMESTAMP DEFAULT NOW() ON UPDATE NOW(),
state VARCHAR(100),
fips INTEGER,
cases INTEGER,
deaths INTEGER,
CONSTRAINT orders_pk PRIMARY KEY(covid_by_state_id)
);
INSERT INTO covid_by_state( date , state, fips, cases, deaths) VALUES('2020-01-21','Washington',53,1,0);
INSERT INTO covid_by_state( date , state, fips, cases, deaths) VALUES('2020-01-21','Illinois',17,1,0);
```
**第二步:AWS DMS設定**
下一步需要使用[AWS DMS](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.Creating.html)將資料複製到Amazon S3中,需要一個複製例項來執行測試和複製任務
- 進入AWS DMS控制面板並建立一個新的[複製例項](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_ReplicationInstance.html)
- [建立兩個端點](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Endpoints.Creating.html),一個使用Amazon RDS作為資料來源,另一個使用S3作為目的地
- 檢查狀態,開始執行
- 使用如下策略建立[AWS Identity and Access Management](https://aws.amazon.com/iam/)角色
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:DeleteObjectTagging",
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectTagging",
"s3:PutObjectTagging",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::bigdatablueprint-role/*"
}
]
}
```
- 建立[Amazon S3目的地](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Target.S3.html),使用如下設定來確保使用Apache Parquet檔案格式
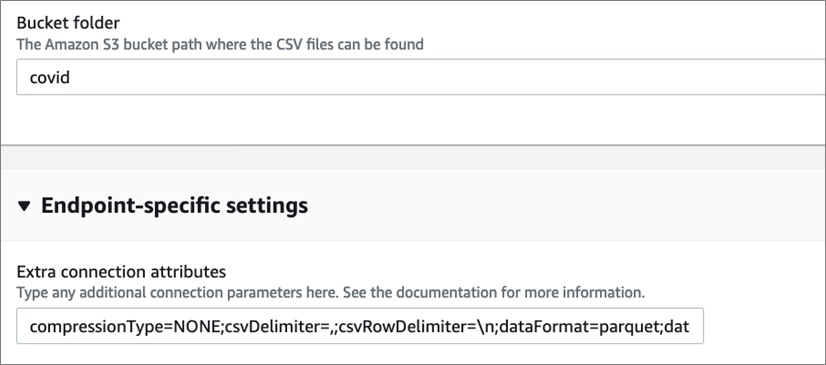
- 檢查是否正常工作,下圖展示了AWS DMS成功執行的結果

**第三步:AWS DMS任務設定**
- 現在可以[建立和執行任務](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.Creating.html),確保你現在正確的Schema,如果沒有顯示,你需要[進行表對映](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.CustomizingTasks.TableMapping.html).
- 點選**Create task**並等待其開始複製資料
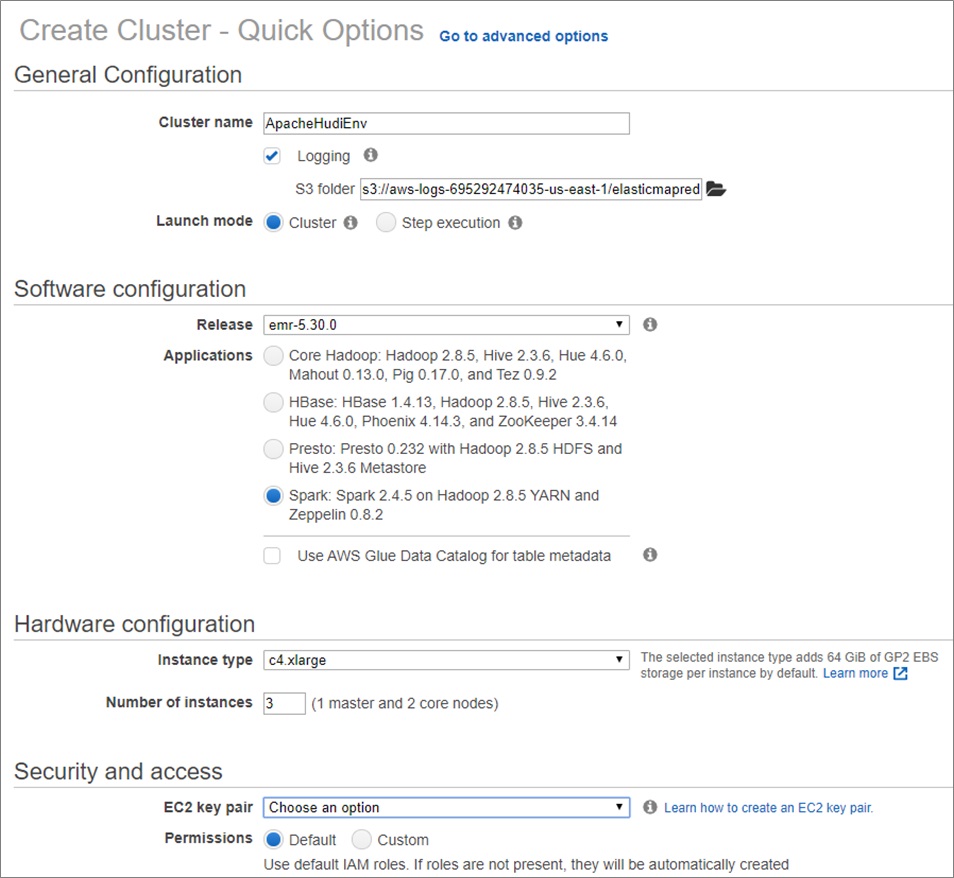
**第四步:Amazon EMR叢集設定**
安裝Apache Spark,Apache Hive或Presto時,Amazon EMR(發行版5.28.0及更高版本)會預設安裝Apache Hudi元件。
Apache Spark或Apache Hudi DeltaStreamer實用程式可以建立或更新Apache Hudi資料集。Apache Hive,Apache Spark或Presto可以互動式查詢Apache Hudi資料集,或使用增量拉取(僅拉取兩次操作之間更改的資料)來構建資料處理管道。
以下是有關如何使用Apache Hudi執行新的Amazon EMR叢集和處理資料的教程。
- 進入Amazon EMR控制面板
- 填寫如下配置
- 叢集執行後,執行以下指令碼來設定資料庫。執行Apache Spark命令以檢視兩行初始插入的當前資料庫狀態。
```scala
scala>scala> spark.read.parquet("s3://bigdatablueprint-raw/covid/hudi_dms/covid_by_state/*").sort("updated_at").show
+----+--------+---------+-------------+-------------------+-------------------+
+----+-----------------+-------------------+----------+----+-----+------+
| Op|covid_by_state_id| date| state|fips|cases|deaths|
+----+-----------------+-------------------+----------+----+-----+------+
|null| 1|2020-01-21 00:00:00|Washington| 53| 1| 0|
|null| 2|2020-01-21 00:00:00| Illinois| 17| 1| 0|
```
**第五步:使用Apache Hudi DeltaStreamer處理變更日誌**
* 要開始使用更改日誌,請在工作流時間表上使用以Apache Spark作業執行的Apache Hudi DeltaStreamer。 例如,按如下所示啟動Apache Spark Shell:
```shell
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --packages org.apache.spark:spark-avro_2.11:2.4.4 --master yarn --deploy-mode client hudi-utilities-bundle_2.11-0.5.2-incubating.jar --table-type
COPY_ON_WRITE --source-ordering-field cases --source-class org.apache.hudi.utilities.sources.ParquetDFSSource --target-base-path s3://bigdatablueprint-final/hudi_covid --target-table cover --transformer-class org.apache.hudi.utilities.transform.AWSDmsTrans
```
* 這是Apache Hudi表,具有與上游表相同的記錄(也包含所有_hoodie欄位):
```shell
scala> spark.read.parquet("s3://bigdatablueprint-final/hudi_covid/*/*.parquet").sort("cases").show
+-------------------+--------------------+------------------+----------------------+--------------------+-----------------+-------------------+----------+----+-----+------+---+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|covid_by_state_id| date| state|fips|cases|deaths| Op|
+-------------------+--------------------+------------------+----------------------+--------------------+-----------------+-------------------+----------+----+-----+------+---+
| 20200812061302| 20200812061302_0_1| 1| default|0a292b18-5194-45d...| 1|2020-01-21 00:00:00|Washington| 53| 1| 0| |
| 20200812061302| 20200812061302_0_2| 2| default|0a292b18-5194-45d...| 2|2020-01-21 00:00:00| Illinois| 17| 1| 0| |
```
* 進行資料庫更改以檢視其他行和更新的值。
* 一旦在源Amazon S3儲存桶更新後,AWS DMS將立即將攝取,然後重新執行相同的Apache Hudi作業,從而將新的Apache Parquet檔案新增到AWS DMS輸出資料夾。
```scala
scala> spark.read.parquet("s3://bigdatablueprint-raw/covid/hudi_dms/covid_by_state/*").sort("cases").show
+----+-----------------+-------------------+----------+----+-----+------+
| Op|covid_by_state_id| date| state|fips|cases|deaths|
+----+-----------------+-------------------+----------+----+-----+------+
| I| 4|2020-01-21 00:00:00| Arizona| 4| 1| 0|
|null| 1|2020-01-21 00:00:00|Washington| 53| 1| 0|
|null| 2|2020-01-21 00:00:00| Illinois| 17| 1| 0|
| U| 1|2020-08-12 06:25:04|Washington| 53| 60| 0|
+----+-----------------+-------------------+----------+----+-----+------+
```
* 重新執行Apache Hudi DeltaStreamer命令時,它將把Apache Parquet檔案變更成Apache Hudi表。
* 這是執行Apache Spark作業後的Apache Hudi結果:
```scala
scala> spark.read.parquet("s3://bigdatablueprint-final/hudi_covid/*/*.parquet").sort("cases").show
+-------------------+--------------------+------------------+----------------------+--------------------+-----------------+-------------------+----------+----+-----+------+---+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|covid_by_state_id| date| state|fips|cases|deaths| Op|
+-------------------+--------------------+------------------+----------------------+--------------------+-----------------+-------------------+----------+----+-----+------+---+
| 20200812061302| 20200812061302_0_1| 1| default|0a292b18-5194-45d...| 1|2020-01-21 00:00:00|Washington| 53| 1| 0| |
| 20200812061302| 20200812061302_0_2| 2| default|0a292b18-5194-45d...| 2|2020-01-21 00:00:00| Illinois| 17| 1| 0| |
| 20200812063216| 20200812063216_0_1| 4| default|0a292b18-5194-45d...| 4|2020-01-21 00:00:00| Arizona| 4| 1| 0| I|
| 20200812062710| 20200812062710_0_1| 1| default|0a292b18-5194-45d...| 1|2020-08-12 06:25:04|Washington| 53| 60| 0| U|
```
* 將資料轉化為CSV格式以便可以通過Amazon QuickSight讀取
```scala
var df = spark.read.parquet("s3://bigdatablueprint-final/hudi_covid/*/*.parquet").sort("cases")
df.write.option("header","true").csv("covid.csv")
```
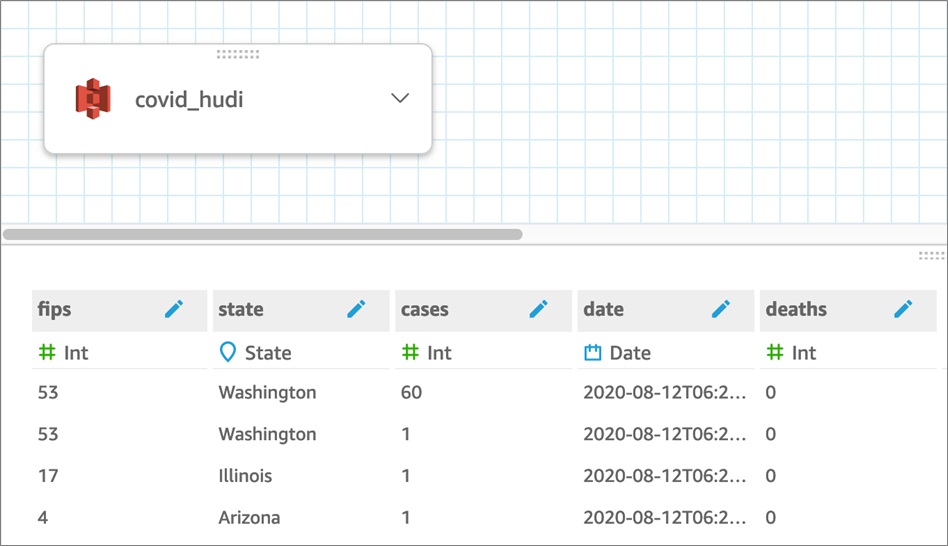
使用上述命令將資料轉換為.csv後,它是一種便於Amazon QuickSight檢視的資料格式,可以將其視覺化。下圖顯示了來自QuickSight中原始(.csv)源的資料的一種表示形式。
這種資料檢視按狀態細分了特定日期的案例數。隨著Hudi使用新資料(可以直接流式傳輸)更新表時,將啟用通過QuickSight進行近實時或實時報告。
### 4. 總結
在本文中,我們逐步介紹了我們的非面向客戶的PoC解決方案,以在Amazon EMR和其他託管服務(包括用於資料視覺化的Amazon QuickSight)上使用Apache Hudi建立新的資料和分析平臺。
如果您的業務決策取決於對近實時資料的訪問,並且您面臨資料延遲,高資料質量,系統可靠性以及對資料隱私法規的遵從性等挑戰,我們建議從nClouds實施此解決方案,它旨在加速需要增量資料管道和處理的大規模和近實時應用程式中的資料