
GraphX 在圖資料庫 Nebula Graph 的圖計算實踐
阿新 • • 發佈:2020-11-11
不同來源的異構資料間存在著千絲萬縷的關聯,這種資料之間隱藏的關聯關係和網路結構特性對於資料分析至關重要,圖計算就是以圖作為資料模型來表達問題並予以解決的過程。

## 一、背景
隨著網路資訊科技的飛速發展,資料逐漸向多源異構化方向發展,且不同來源的異構資料之間也存在的千絲萬縷的關聯,這種資料之間隱藏的關聯關係和網路結構特性對於資料分析至關重要。但傳統關係型資料庫在分析大規模資料關聯特性時存在效能缺陷、表達有限等問題,因此有著更強大表達能力的圖資料受到業界極大重視,圖計算就是以圖作為資料模型來表達問題並予以解決的過程。圖可以融合多源多型別的資料,除了可以展示資料靜態基礎特性之外,還可通過圖計算展示隱藏在資料之間的圖結構特性和點對關聯關係,成為社交網路、推薦系統、知識圖譜、金融風控、網路安全、文字檢索等領域重要的分析手段。
## 二、演算法應用
為了支撐大規模圖計算的業務需求,[Nebula Graph](https://github.com/vesoft-inc/nebula) 基於 [GraphX](https://github.com/apache/spark/tree/master/graphx) 提供了 [PageRank](https://en.wikipedia.org/wiki/PageRank) 和 [Louvain](https://en.wikipedia.org/wiki/Louvain_method) 社群發現的圖計算演算法,允許使用者通過提交 Spark 任務的形式執行演算法應用。此外,使用者也可以通過 Spark Connector 編寫 Spark 程式呼叫 GraphX 自帶的其他圖演算法,如 LabelPropagation、ConnectedComponent 等。
### PageRank
PageRank 是谷歌提出的用於解決連結分析中網頁排名問題的演算法,目的是為了對網際網路中數以億計的網頁進行排名。
#### PageRank 簡介
美國斯坦福大學的 Larry Page 和 Sergey Brin 在研究網頁排序問題時採用學術界評判論文重要性的方法,即看論文的引用量以及引用該論文的論文質量,對應於網頁的重要性有兩個假設:
1. 數量假設:如果一個網頁 A 被很多其他網頁連結到,則該網頁比較重要;
1. 質量假設:如果一個很重要的網頁連結到網頁 A,則該網頁的重要性會被提高。
並基於這兩個假設提出 PageRank 演算法。
#### PageRank 應用場景
##### 社交應用的相似度內容推薦
在對微博、微信等社交平臺進行社交網路分析時,可以基於 PageRank 演算法根據使用者通常瀏覽的資訊以及停留時間實現基於使用者的相似度的內容推薦;
##### 分析使用者社交影響力
在社交網路分析時根據使用者的 PageRank 值進行使用者影響力分析;
##### 文獻重要性研究
根據文獻的 PageRank 值評判該文獻的質量,PageRank 演算法就是基於評判文獻質量的想法來實現設計。
此外 PageRank 在資料分析和挖掘中也有很多的應用。
#### 演算法思路
GraphX 的 PageRank 演算法是基於 Pregel 計算模型的,該演算法流程包括 3 步驟:
1. 為圖中每個節點(網頁)設定一個同樣的初始 PageRank 值;
1. 第一次迭代:沿邊傳送訊息,每個節點收到所有關聯邊上對點的資訊,得到一個新的 PageRank 值;
1. 第二次迭代:用這組新的 PageRank 按不同演算法模式對應的公式形成節點自己新的 PageRank。
### Louvain 社群發現
Louvain 是用來進行社會網路挖掘的社群發現演算法,屬於圖的聚類演算法。
#### Louvain 演算法介紹
Louvain 是基於模組度(Modularity)的社群發現演算法,通過模組度來衡量一個社群的緊密程度。如果一個節點加入到某一社群中會使得該社群的模組度相比其他社群有最大程度的增加,則該節點就應當屬於該社群。如果加入其它社群後沒有使其模組度增加,則留在自己當前社群中。
##### 模組度
**模組度公式**
模組度 Q 的物理意義:社群內節點的連邊數與隨機情況下的邊數之差,定義函式如下:
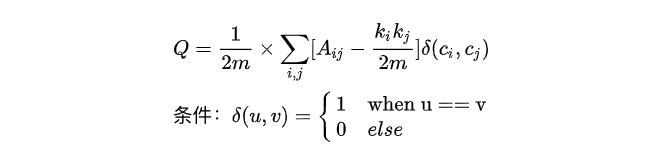
其中
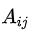:節點 i 和節點 j 之間邊的權重
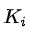:所有與節點 i 相連的邊的權重之和
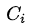:節點 i 所屬的社群
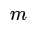: 圖中所有邊的權重之和
**模組度公式變形**
在此公式中,只有節點 i 和節點 j 屬於同一社群,公式才有意義,所以該公式是衡量的某一社群內的緊密度。對於該公式的簡化變形如下:
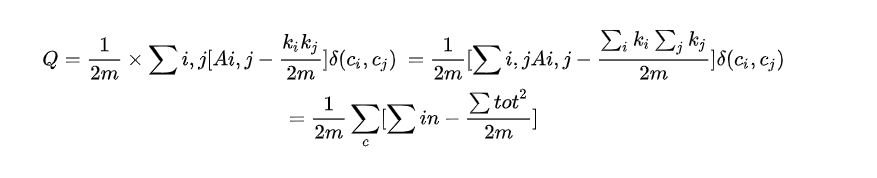
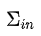表示: 社群 c 內的邊的權重之和
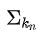 表示: 所有與社群 c 內節點相連的邊的權重之和(因為 i 屬於社群 c)包括社群內節點與節點 i 的邊和社群外節點與節點 i 的邊。
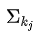 表示: 所有與社群 c 內節點相連的邊的權重之和(因為 j 屬於社群 c)包括社群內節點與節點 j 的邊和社群外節點與節點 j 的邊。
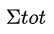 代替  和 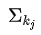。(即社群 c 內邊權重和 + 社群 c 與其他社群連邊的權重和)
**求解模組度變化**
在 Louvain 演算法中不需要求每個社群具體的模組度,只需要比較社群中加入某個節點之後的模組度變化,所以需要求解 △Q。
將節點 i 分配到某一社群中,社群的模組度變化為:
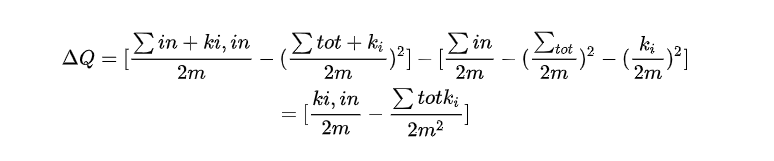
其中
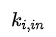: 社群內所有節點與節點 i 連邊權重之和(對應新社群的實際內部權重和乘以 2,因為 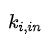 對於社群內所有的頂點 i,每條邊其實被計算了兩次)
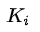: 所有與節點 i 相連的邊的權重之和
故實現演算法時只需求 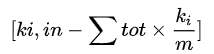 即可。
#### Louvain 應用場景
- 金融風控
在金融風控場景中,可以根據使用者行為特徵進行團伙識別;
- 社交網路
可以基於網路關係中點對之間關聯的廣度和強度進行社交網路劃分;對複雜網路分析、電話網路分析人群之間的聯絡密切度;
- 推薦系統
基於使用者興趣愛好的社群發現,可以根據社群並結合協同過濾等推薦演算法進行更精確有效的個性化推薦。
#### Louvain 演算法思路
Louvain 演算法包括兩個階段,其流程就是這兩個階段的迭代過程。
**階段一**:不斷地遍歷網路圖中的節點,通過比較節點給每個鄰居社群帶來的模組度的變化,將單個節點加入到能夠使 Modularity 模組度有最大增量的社群中。
(比如節點 v 分別加入到社群 A、B、C 中,使得三個社群的模組度增量為-1, 1, 2, 則節點 v 最終應該加入到社群 C 中)
**階段二**:對第一階段進行處理,將屬於同一社群的頂點合併為一個大的超點重新構造網路圖,即一個社群作為圖的一個新的節點。此時兩個超點之間邊的權重是兩個超點內所有原始頂點之間相連的邊權重之和,即兩個社群之間的邊權重之和。
下面是對第一二階段的例項介紹。
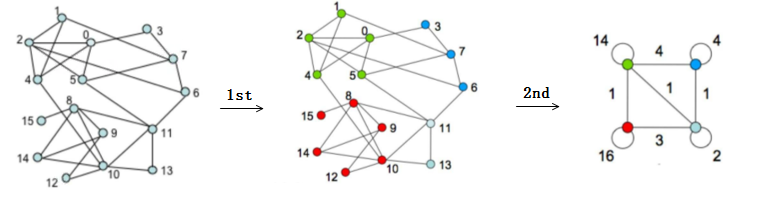
第一階段遍歷圖中節點加入到其所屬社群中,得到中間的圖,形成四個社群;
第二節點對社群內的節點進行合併成一個超級節點,社群節點有自連邊,其權重為社群內部所有節點間相連的邊的權重之和的 2 倍,社群之間的邊為兩個社群間頂點跨社群相連的邊的權重之和,如紅色社群和淺綠色社群之間通過(8,11)、(10,11)、(10,13)相連,所以兩個社群之間邊的權重為 3。
_注:社群內的權重為所有內部結點之間邊權重的兩倍,因為 Kin 的概念是社群內所有節點與節點 i 的連邊和,在計算某一社群的 Kin 時,實際上每條邊都被其兩端的頂點計算了一次,一共被計算了兩次。_
整個 Louvain 演算法就是不斷迭代第一階段和第二階段,直到演算法穩定(圖的模組度不再變化)或者到達最大迭代次數。
## 三、演算法實踐
### 演示環境
- 三臺虛擬機器,環境如下:
- Cpu name:Intel(R) Xeon(R) Platinum 8260M CPU @ 2.30GHz
- Processors:32
- CPU Cores:16
- Memory Size:128G
- 軟體環境
- Spark:spark-2.4.6-bin-hadoop2.7 三個節點叢集
- yarn V2.10.0:三個節點叢集
- Nebula Graph V1.1.0:分散式部署,預設配置
### 測試資料
1. 建立圖空間
```shell
CREATE SPACE algoTest(partition_num=100, replica_factor=1);
```
2. 建立點邊 Schema
```shell
CREATE TAG PERSON()
CREATE EDGE FRIEND(likeness double);
```
3. 匯入資料
利用 Exchange 工具將資料離線匯入 Nebula Graph。
4. 測試結果
Spark 任務的資源分配為 `--driver-memory=20G --executor-memory=100G --executor-cores=3`
- PageRank 在一億資料集上的執行時間為 21min(PageRank 演算法執行時間)
- Louvain 在一億資料集上的執行時間為 1.3h(Reader + Louvain 演算法執行時間)
### 如何使用 Nebula Graph 的演算法
1. 下載 nebula-algorithm 專案並打成 jar 包
```shell
$ git clone [email protected]:vesoft-inc/nebula-java.git
$ cd nebula-java/tools/nebula-algorithm
$ mvn package -DskipTests
```
2. 配置專案中的 `src/main/resources/application.conf`
```xml
{
# Spark relation config
spark: {
app: {
# not required, default name is the algorithm that you are going to execute.
name: PageRank
# not required
partitionNum: 12
}
master: local
# not required
conf: {
driver-memory: 8g
executor-memory: 8g
executor-cores: 1g
cores-max:6
}
}
# Nebula Graph relation config
nebula: {
# metadata server address
addresses: "127.0.0.1:45500"
user: root
pswd: nebula
space: algoTest
# partition specified while creating nebula space, if you didn't specified the partition, then it's 100.
partitionNumber: 100
# nebula edge type
labels: ["FRIEND"]
hasWeight: true
# if hasWeight is true,then weightCols is required, and weghtCols' order must be corresponding with labels.
# Noted: the graph algorithm only supports isomorphic graphs,
# so the data type of each col in weightCols must be consistent and all numeric types.
weightCols: [“likeness”]
}
algorithm: {
# the algorithm that you are going to execute,pick one from [pagerank, louvain]
executeAlgo: louvain
# algorithm result path
path: /tmp
# pagerank parameter
pagerank: {
maxIter: 20
resetProb: 0.15 # default 0.15
}
# louvain parameter
louvain: {
maxIter: 20
internalIter: 10
tol: 0.5
}
}
}
```
3. 確保使用者環境已安裝 Spark 並啟動 Spark 服務
4. 提交 nebula-algorithm 應用程式:
```shell
spark-submit --master xxx --class com.vesoft.nebula.tools.algorithm.Main /your-jar-path/nebula-algorithm-1.0.1.jar -p /your-application.conf-path/application.conf
```
如果你對上述內容感興趣,歡迎用 nebula-algorithm 試試^^
## References
- Nebula Graph:[https://github.com/vesoft-inc/nebula](https://github.com/vesoft-inc/nebula)
- GraphX:[https://github.com/apache/spark/tree/master/graphx](https://github.com/apache/spark/tree/master/graphx)
- Spark-connector:[https://github.com/vesoft-inc/nebula-java/tree/master/tools/nebula-spark](https://github.com/vesoft-inc/nebula-java/tree/master/tools/nebula-spark)
- Exchange:[https://github.com/vesoft-inc/nebula-java/blob/master/doc/tools/exchange/ex-ug-toc.md](https://github.com/vesoft-inc/nebula-java/blob/master/doc/tools/exchange/ex-ug-toc.md)
- nebula-algorithm:[https://github.com/vesoft-inc/nebula-java/tree/master/tools/nebula-algorithm](https://github.com/vesoft-inc/nebula-java/tree/master/tools/nebula-algorithm)
> 作者有話說:Hi,我是安祺,Nebula Graph 研發工程師,如果你對本文有任何疑問,歡迎來論壇和我交流:[https://discuss.nebula-graph.com.cn/](https://discuss.nebula-graph.com.cn/)
## 推薦閱讀
- [用圖機器學習探索 A 股個股相關性變化](https://nebula-graph.com.cn/posts/stock-interrelation-analysis-jgrapht-nebula-graph/)
- [用 NetworkX + Gephi + Nebula Graph 分析<權力的遊戲>人物關係(上篇)](https://nebula-graph.com.cn/posts/game-of-thrones-relationship-networkx-gephi-nebula-